NNCF を使用した OpenAI CLIP モデルのトレーニング後の量子化¶
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

このチュートリアルは、NNCF (Neural Network Compression Framework) から 8 ビットのトレーニング後の量子化を適用してモデルを高速化し、OpenVINO™ ツールキットを介して量子化されたモデルを推論する方法を示します。最適化プロセスには次の手順が含まれます。
ノートブックから変換された OpenVINO モデルを NNCF で量子化します。
ノートブックから同じ入力データを使用してモデルの結果を確認します。
変換および量子化されたモデルのモデルサイズを比較します。
変換および量子化されたモデルのパフォーマンスを比較します。
注: 最初に 228-clip-zero-shot-convert ノートブックを実行して、量子化に使用される OpenVINO IR モデルを生成する必要があります。
目次¶
必要条件¶
%pip install -q datasets
%pip install -q "nncf>=2.6.0"
量子化の作成と初期化¶
NNCF は、モデルグラフに量子化レイヤーを追加し、トレーニング・データセットのサブセットを使用してこれらの追加の量子化レイヤーのパラメーターを初期化することで、トレーニング後の量子化を可能にします。このフレームワークは、元のトレーニング・コードへの変更が最小限になるように設計されています。量子化は最も単純なシナリオであり、いくつかの変更が必要です。
最適化プロセスには次の手順が含まれます。
量子化用のデータセットを作成します。
nncf.quantizeを実行して、量子化されたモデルを取得します。openvino.runtime.serialize関数を使用してINT8モデルをシリアル化します。
データセットの準備¶
キャプションのアノテーションが付けられた約 330 万個の画像で構成される Conceptual Captions データセットは、モデルの量子化に使用されます。
import os
fp16_model_path = 'clip-vit-base-patch16.xml'
if not os.path.exists(fp16_model_path):
raise RuntimeError('This notebook should be run after 228-clip-zero-shot-convert.ipynb.')
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch16")
max_length = model.config.text_config.max_position_embeddings
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch16")
/home/ea/work/ov_venv/lib/python3.8/site-packages/torch/cuda/__init__.py:138: UserWarning: CUDA initialization: The NVIDIA driver on your system is too old (found version 11080). Please update your GPU driver by downloading and installing a new version from the URL: http://www.nvidia.com/Download/index.aspx Alternatively, go to: https://pytorch.org to install a PyTorch version that has been compiled with your version of the CUDA driver. (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:108.) return torch._C._cuda_getDeviceCount() > 0 2023-10-26 16:44:33.809201: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0. 2023-10-26 16:44:33.845253: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags. 2023-10-26 16:44:34.564478: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
import requests
from io import BytesIO
import numpy as np
from PIL import Image
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
def check_text_data(data):
"""
Check if the given data is text-based.
"""
if isinstance(data, str):
return True
if isinstance(data, list):
return all(isinstance(x, str) for x in data)
return False
def get_pil_from_url(url):
"""
Downloads and converts an image from a URL to a PIL Image object.
"""
response = requests.get(url, verify=False, timeout=20)
image = Image.open(BytesIO(response.content))
return image.convert("RGB")
def collate_fn(example, image_column="image_url", text_column="caption"):
"""
Preprocesses an example by loading and transforming image and text data.
Checks if the text data in the example is valid by calling the `check_text_data` function.
Downloads the image specified by the URL in the image_column by calling the `get_pil_from_url` function.
If there is any error during the download process, returns None.
Returns the preprocessed inputs with transformed image and text data.
"""
assert len(example) == 1
example = example[0]
if not check_text_data(example[text_column]):
raise ValueError("Text data is not valid")
url = example[image_column]
try:
image = get_pil_from_url(url)
h, w = image.size
if h == 1 or w == 1:
return None
except Exception:
return None
inputs = processor(text=example[text_column], images=[image], return_tensors="pt", padding=True)
if inputs['input_ids'].shape[1] > max_length:
return None
return inputs
import torch
from datasets import load_dataset
from tqdm.notebook import tqdm
def prepare_calibration_data(dataloader, init_steps):
"""
This function prepares calibration data from a dataloader for a specified number of initialization steps.
It iterates over the dataloader, fetching batches and storing the relevant data.
"""
data = []
print(f"Fetching {init_steps} samples for the initialization...")
with tqdm(total=init_steps) as pbar:
for batch in dataloader:
if len(data) == init_steps:
break
if batch:
pbar.update(1)
with torch.no_grad():
data.append(
{
"pixel_values": batch["pixel_values"].to("cpu"),
"input_ids": batch["input_ids"].to("cpu"),
"attention_mask": batch["attention_mask"].to("cpu")
}
)
return data
def prepare_dataset(opt_init_steps=300, max_train_samples=1000):
"""
Prepares a vision-text dataset for quantization.
"""
dataset = load_dataset("conceptual_captions", streaming=True)
train_dataset = dataset["train"].shuffle(seed=42, buffer_size=max_train_samples)
dataloader = torch.utils.data.DataLoader(train_dataset, collate_fn=collate_fn, batch_size=1)
calibration_data = prepare_calibration_data(dataloader, opt_init_steps)
return calibration_data
事前トレーニングされた FP16 モデルから量子化モデルを作成します。
注: 量子化は時間とメモリーを消費する操作です。以下の量子化コードを実行すると、時間がかかる場合があります。
import logging
import nncf
from openvino.runtime import Core, serialize
core = Core()
nncf.set_log_level(logging.ERROR)
int8_model_path = 'clip-vit-base-patch16_int8.xml'
calibration_data = prepare_dataset()
ov_model = core.read_model(fp16_model_path)
INFO:nncf:NNCF initialized successfully. Supported frameworks detected: torch, tensorflow, onnx, openvino
Fetching 300 for the initialization...
0it [00:00, ?it/s]
if len(calibration_data) == 0:
raise RuntimeError(
'Calibration dataset is empty. Please check internet connection and try to download images manually.'
)
calibration_dataset = nncf.Dataset(calibration_data)
quantized_model = nncf.quantize(
model=ov_model,
calibration_dataset=calibration_dataset,
model_type=nncf.ModelType.TRANSFORMER,
# Smooth Quant algorithm reduces activation quantization error; optimal alpha value was obtained through grid search
advanced_parameters=nncf.AdvancedQuantizationParameters(smooth_quant_alpha=0.6)
)
serialize(quantized_model, int8_model_path)
Statistics collection: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 300/300 [00:15<00:00, 19.75it/s]
Applying Smooth Quant: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 98/98 [00:03<00:00, 26.89it/s]
Statistics collection: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 300/300 [00:49<00:00, 6.01it/s]
Applying Fast Bias correction: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 144/144 [00:11<00:00, 12.27it/s]
NNCF は、量子化対応トレーニングや量子化以外のアルゴリズムもサポートしています。詳細については、NNCF リポジトリーの NNCF ドキュメントを参照してください。
量子化された OpenVINO モデルを実行¶
量子化された OpenVINO CLIP モデルを使用して予測を行う手順は、PyTorch モデルと似ています。1 番目のノートブックと同じ入力データを使用してモデルの結果を確認してみましょう。
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='AUTO',
description='Device:',
disabled=False,
)
device
Dropdown(description='Device:', index=2, options=('CPU', 'GPU', 'AUTO'), value='AUTO')
from pathlib import Path
from scipy.special import softmax
from openvino.runtime import compile_model
from visualize import visualize_result
from urllib.request import urlretrieve
sample_path = Path("data/coco.jpg")
sample_path.parent.mkdir(parents=True, exist_ok=True)
urlretrieve(
"https://storage.openvinotoolkit.org/repositories/openvino_notebooks/data/data/image/coco.jpg",
sample_path,
)
image = Image.open(sample_path)
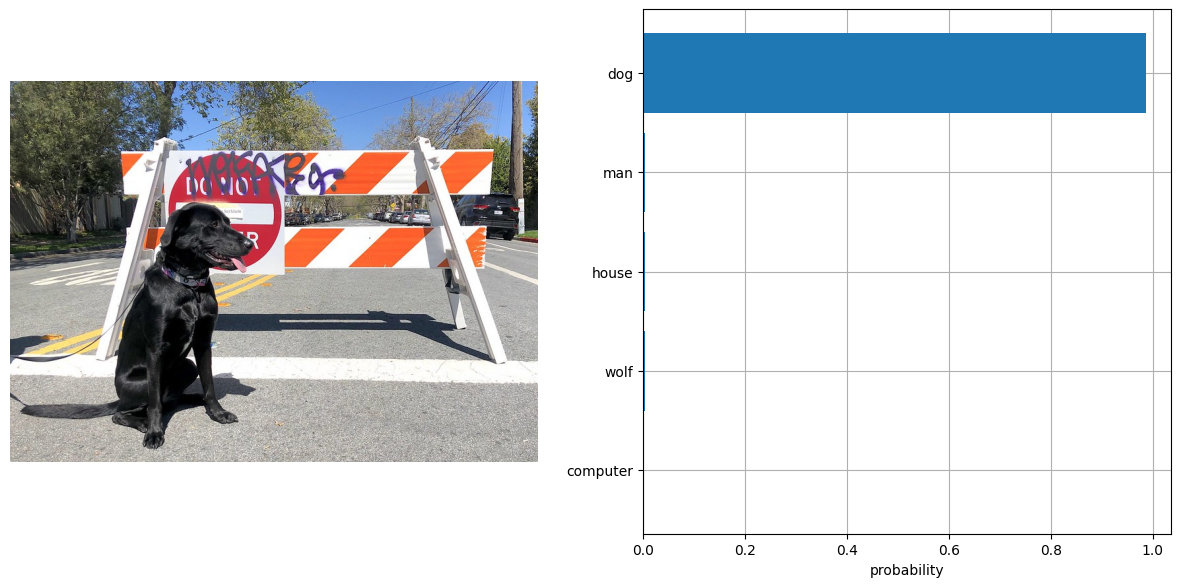
input_labels = ['cat', 'dog', 'wolf', 'tiger', 'man', 'horse', 'frog', 'tree', 'house', 'computer']
text_descriptions = [f"This is a photo of a {label}" for label in input_labels]
inputs = processor(text=text_descriptions, images=[image], return_tensors="pt", padding=True)
compiled_model = compile_model(int8_model_path)
logits_per_image_out = compiled_model.output(0)
ov_logits_per_image = compiled_model(dict(inputs))[logits_per_image_out]
probs = softmax(ov_logits_per_image, axis=1)
visualize_result(image, input_labels, probs[0])
ファイルサイズの比較¶
from pathlib import Path
fp16_ir_model_size = Path(fp16_model_path).with_suffix(".bin").stat().st_size / 1024 / 1024
quantized_model_size = Path(int8_model_path).with_suffix(".bin").stat().st_size / 1024 / 1024
print(f"FP16 IR model size: {fp16_ir_model_size:.2f} MB")
print(f"INT8 model size: {quantized_model_size:.2f} MB")
print(f"Model compression rate: {fp16_ir_model_size / quantized_model_size:.3f}")
FP16 IR model size: 285.38 MB
INT8 model size: 144.17 MB
Model compression rate: 1.979
FP16 IR と量子化モデルの推論時間を比較¶
FP16 と INT8 モデルの推論パフォーマンスを測定するには、キャリブレーション・データセットの推論時間の中央値を使用します。したがって、動的量子化モデルの速度向上を見積もることができます。
注: 最も正確なパフォーマンス推定を行うには、他のアプリケーションを閉じた後、ターミナル/コマンドプロンプトで
benchmark_appを実行することを推奨します。
import time
from openvino.runtime import compile_model
def calculate_inference_time(model_path, calibration_data):
model = compile_model(model_path)
output_layer = model.output(0)
inference_time = []
for batch in calibration_data:
start = time.perf_counter()
_ = model(batch)[output_layer]
end = time.perf_counter()
delta = end - start
inference_time.append(delta)
return np.median(inference_time)
fp16_latency = calculate_inference_time(fp16_model_path, calibration_data)
int8_latency = calculate_inference_time(int8_model_path, calibration_data)
print(f"Performance speed up: {fp16_latency / int8_latency:.3f}")
Performance speed up: 1.548