EfficientSAM と OpenVINO によるオブジェクトのセグメント化¶
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

セグメント・エニシング・モデル (SAM) は、数多くのビジョン・アプリケーション向けの強力なツールとして登場しました。ゼロショット転送と高い汎用性を実現する優れたパフォーマンスを実現する重要なコンポーネントは、広範囲にわたる高品質の SA-1B データセットでトレーニングされた超大規模トランスフォーマー・モデルです。SAM モデルは有益ではあるものの、計算コストが膨大であるため、その応用範囲は実世界のより広範なアプリケーションに限定されています。この制限に対処するため、複雑さを大幅に削減しながら適切なパフォーマンスを発揮する軽量 SAM モデルである EfficientSAM が提案されました。EfficientSAM のアイデアは、効果的な視覚表現学習のために SAM 画像エンコーダーから特徴を再構築することを学習するマスクされた画像の事前トレーニング (SAMI) を活用することに基づいています。
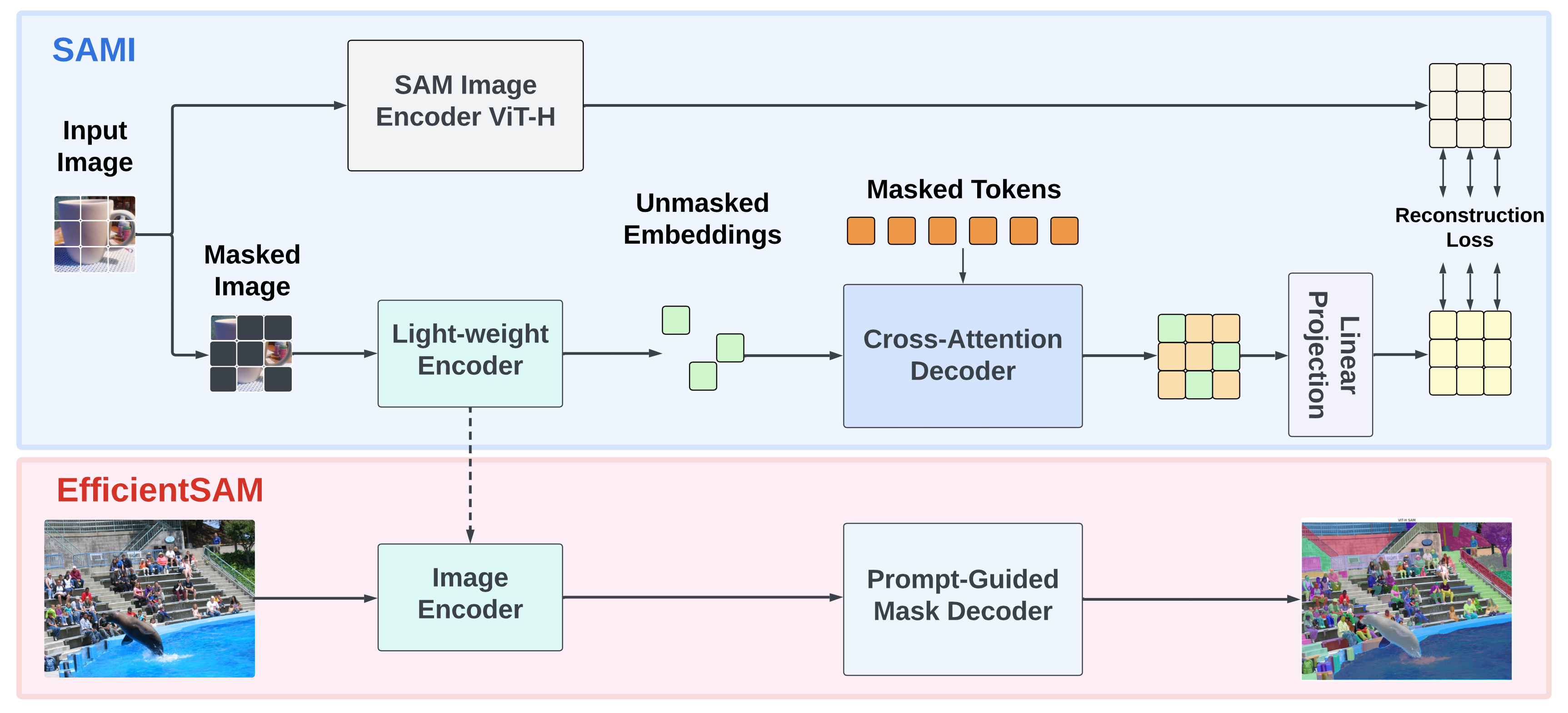
overview.png¶
モデルの詳細については、論文、モデルのウェブページ、元のリポジトリーを参照してください。
このチュートリアルでは、OpenVINO を使用して EfficientSAM を変換して実行する方法について説明します。また、NNCF を使用してモデルを量子化する方法も示します。
目次¶
必要条件¶
%pip install -q "openvino>=2023.3.0" "nncf>=2.7" opencv-python matplotlib "gradio>=4.13" torch torchvision --extra-index-url https://download.pytorch.org/whl/cpu
DEPRECATION: pytorch-lightning 1.6.5 has a non-standard dependency specifier torch>=1.8.*. pip 24.1 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of pytorch-lightning or contact the author to suggest that they release a version with a conforming dependency specifiers. Discussion can be found at https://github.com/pypa/pip/issues/12063
Note: you may need to restart the kernel to use updated packages.
from pathlib import Path
repo_dir = Path("EfficientSAM")
if not repo_dir.exists():
!git clone https://github.com/yformer/EfficientSAM.git
%cd $repo_dir
Cloning into 'EfficientSAM'...
remote: Enumerating objects: 424, done.[K
remote: Counting objects: 0% (1/140)[K
remote: Counting objects: 1% (2/140)[K
remote: Counting objects: 2% (3/140)[K
remote: Counting objects: 3% (5/140)[K
remote: Counting objects: 4% (6/140)[K
remote: Counting objects: 5% (7/140)[K
remote: Counting objects: 6% (9/140)[K
remote: Counting objects: 7% (10/140)[K
remote: Counting objects: 8% (12/140)[K
remote: Counting objects: 9% (13/140)[K
remote: Counting objects: 10% (14/140)[K
remote: Counting objects: 11% (16/140)[K
remote: Counting objects: 12% (17/140)[K
remote: Counting objects: 13% (19/140)[K
remote: Counting objects: 14% (20/140)[K
remote: Counting objects: 15% (21/140)[K
remote: Counting objects: 16% (23/140)[K
remote: Counting objects: 17% (24/140)[K
remote: Counting objects: 18% (26/140)[K
remote: Counting objects: 19% (27/140)[K
remote: Counting objects: 20% (28/140)[K
remote: Counting objects: 21% (30/140)[K
remote: Counting objects: 22% (31/140)[K
remote: Counting objects: 23% (33/140)[K
remote: Counting objects: 24% (34/140)[K
remote: Counting objects: 25% (35/140)[K
remote: Counting objects: 26% (37/140)[K
remote: Counting objects: 27% (38/140)[K
remote: Counting objects: 28% (40/140)[K
remote: Counting objects: 29% (41/140)[K
remote: Counting objects: 30% (42/140)[K
remote: Counting objects: 31% (44/140)[K
remote: Counting objects: 32% (45/140)[K
remote: Counting objects: 33% (47/140)[K
remote: Counting objects: 34% (48/140)[K
remote: Counting objects: 35% (49/140)[K
remote: Counting objects: 36% (51/140)[K
remote: Counting objects: 37% (52/140)[K
remote: Counting objects: 38% (54/140)[K
remote: Counting objects: 39% (55/140)[K
remote: Counting objects: 40% (56/140)[K
remote: Counting objects: 41% (58/140)[K
remote: Counting objects: 42% (59/140)[K
remote: Counting objects: 43% (61/140)[K
remote: Counting objects: 44% (62/140)[K
remote: Counting objects: 45% (63/140)[K
remote: Counting objects: 46% (65/140)[K
remote: Counting objects: 47% (66/140)[K
remote: Counting objects: 48% (68/140)[K
remote: Counting objects: 49% (69/140)[K
remote: Counting objects: 50% (70/140)[K
remote: Counting objects: 51% (72/140)[K
remote: Counting objects: 52% (73/140)[K
remote: Counting objects: 53% (75/140)[K
remote: Counting objects: 54% (76/140)[K
remote: Counting objects: 55% (77/140)[K
remote: Counting objects: 56% (79/140)[K
remote: Counting objects: 57% (80/140)[K
remote: Counting objects: 58% (82/140)[K
remote: Counting objects: 59% (83/140)[K
remote: Counting objects: 60% (84/140)[K
remote: Counting objects: 61% (86/140)[K
remote: Counting objects: 62% (87/140)[K
remote: Counting objects: 63% (89/140)[K
remote: Counting objects: 64% (90/140)[K
remote: Counting objects: 65% (91/140)[K
remote: Counting objects: 66% (93/140)[K
remote: Counting objects: 67% (94/140)[K
remote: Counting objects: 68% (96/140)[K
remote: Counting objects: 69% (97/140)[K
remote: Counting objects: 70% (98/140)[K
remote: Counting objects: 71% (100/140)[K
remote: Counting objects: 72% (101/140)[K
remote: Counting objects: 73% (103/140)[K
remote: Counting objects: 74% (104/140)[K
remote: Counting objects: 75% (105/140)[K
remote: Counting objects: 76% (107/140)[K
remote: Counting objects: 77% (108/140)[K
remote: Counting objects: 78% (110/140)[K
remote: Counting objects: 79% (111/140)[K
remote: Counting objects: 80% (112/140)[K
remote: Counting objects: 81% (114/140)[K
remote: Counting objects: 82% (115/140)[K
remote: Counting objects: 83% (117/140)[K
remote: Counting objects: 84% (118/140)[K
remote: Counting objects: 85% (119/140)[K
remote: Counting objects: 86% (121/140)[K
remote: Counting objects: 87% (122/140)[K
remote: Counting objects: 88% (124/140)[K
remote: Counting objects: 89% (125/140)[K
remote: Counting objects: 90% (126/140)[K
remote: Counting objects: 91% (128/140)[K
remote: Counting objects: 92% (129/140)[K
remote: Counting objects: 93% (131/140)[K
remote: Counting objects: 94% (132/140)[K
remote: Counting objects: 95% (133/140)[K
remote: Counting objects: 96% (135/140)[K
remote: Counting objects: 97% (136/140)[K
remote: Counting objects: 98% (138/140)[K
remote: Counting objects: 99% (139/140)[K
remote: Counting objects: 100% (140/140)[K
remote: Counting objects: 100% (140/140), done.[K
remote: Compressing objects: 1% (1/85)[K
remote: Compressing objects: 2% (2/85)[K
remote: Compressing objects: 3% (3/85)[K
remote: Compressing objects: 4% (4/85)[K
remote: Compressing objects: 5% (5/85)[K
remote: Compressing objects: 7% (6/85)[K
remote: Compressing objects: 8% (7/85)[K
remote: Compressing objects: 9% (8/85)[K
remote: Compressing objects: 10% (9/85)[K
remote: Compressing objects: 11% (10/85)[K
remote: Compressing objects: 12% (11/85)[K
remote: Compressing objects: 14% (12/85)[K
remote: Compressing objects: 15% (13/85)[K
remote: Compressing objects: 16% (14/85)[K
remote: Compressing objects: 17% (15/85)[K
remote: Compressing objects: 18% (16/85)[K
remote: Compressing objects: 20% (17/85)[K
remote: Compressing objects: 21% (18/85)[K
remote: Compressing objects: 22% (19/85)[K
remote: Compressing objects: 23% (20/85)[K
remote: Compressing objects: 24% (21/85)[K
remote: Compressing objects: 25% (22/85)[K
remote: Compressing objects: 27% (23/85)[K
remote: Compressing objects: 28% (24/85)[K
remote: Compressing objects: 29% (25/85)[K
remote: Compressing objects: 30% (26/85)[K
remote: Compressing objects: 31% (27/85)[K
remote: Compressing objects: 32% (28/85)[K
remote: Compressing objects: 34% (29/85)[K
remote: Compressing objects: 35% (30/85)[K
remote: Compressing objects: 36% (31/85)[K
remote: Compressing objects: 37% (32/85)[K
remote: Compressing objects: 38% (33/85)[K
remote: Compressing objects: 40% (34/85)[K
remote: Compressing objects: 41% (35/85)[K
remote: Compressing objects: 42% (36/85)[K
remote: Compressing objects: 43% (37/85)[K
remote: Compressing objects: 44% (38/85)[K
remote: Compressing objects: 45% (39/85)[K
remote: Compressing objects: 47% (40/85)[K
remote: Compressing objects: 48% (41/85)[K
remote: Compressing objects: 49% (42/85)[K
remote: Compressing objects: 50% (43/85)[K
remote: Compressing objects: 51% (44/85)[K
remote: Compressing objects: 52% (45/85)[K
remote: Compressing objects: 54% (46/85)[K
remote: Compressing objects: 55% (47/85)[K
remote: Compressing objects: 56% (48/85)[K
remote: Compressing objects: 57% (49/85)[K
remote: Compressing objects: 58% (50/85)[K
remote: Compressing objects: 60% (51/85)[K
remote: Compressing objects: 61% (52/85)[K
remote: Compressing objects: 62% (53/85)[K
remote: Compressing objects: 63% (54/85)[K
remote: Compressing objects: 64% (55/85)[K
remote: Compressing objects: 65% (56/85)[K
remote: Compressing objects: 67% (57/85)[K
remote: Compressing objects: 68% (58/85)[K
remote: Compressing objects: 69% (59/85)[K
remote: Compressing objects: 70% (60/85)[K
remote: Compressing objects: 71% (61/85)[K
remote: Compressing objects: 72% (62/85)[K
remote: Compressing objects: 74% (63/85)[K
remote: Compressing objects: 75% (64/85)[K
remote: Compressing objects: 76% (65/85)[K
remote: Compressing objects: 77% (66/85)[K
remote: Compressing objects: 78% (67/85)[K
remote: Compressing objects: 80% (68/85)[K
remote: Compressing objects: 81% (69/85)[K
remote: Compressing objects: 82% (70/85)[K
remote: Compressing objects: 83% (71/85)[K
remote: Compressing objects: 84% (72/85)[K
remote: Compressing objects: 85% (73/85)[K
remote: Compressing objects: 87% (74/85)[K
remote: Compressing objects: 88% (75/85)[K
remote: Compressing objects: 89% (76/85)[K
remote: Compressing objects: 90% (77/85)[K
remote: Compressing objects: 91% (78/85)[K
remote: Compressing objects: 92% (79/85)[K
remote: Compressing objects: 94% (80/85)[K
remote: Compressing objects: 95% (81/85)[K
remote: Compressing objects: 96% (82/85)[K
remote: Compressing objects: 97% (83/85)[K
remote: Compressing objects: 98% (84/85)[K
remote: Compressing objects: 100% (85/85)[K
remote: Compressing objects: 100% (85/85), done.[K
Receiving objects: 0% (1/424)
Receiving objects: 1% (5/424)
Receiving objects: 2% (9/424)
Receiving objects: 3% (13/424)
Receiving objects: 4% (17/424)
Receiving objects: 5% (22/424)
Receiving objects: 6% (26/424)
Receiving objects: 6% (26/424), 3.20 MiB | 3.16 MiB/s
Receiving objects: 6% (26/424), 6.62 MiB | 3.26 MiB/s
Receiving objects: 6% (26/424), 10.04 MiB | 3.29 MiB/s
Receiving objects: 6% (26/424), 13.46 MiB | 3.31 MiB/s
Receiving objects: 6% (26/424), 16.88 MiB | 3.35 MiB/s
Receiving objects: 6% (26/424), 20.31 MiB | 3.35 MiB/s
Receiving objects: 6% (26/424), 23.73 MiB | 3.35 MiB/s
Receiving objects: 6% (26/424), 27.15 MiB | 3.35 MiB/s
Receiving objects: 6% (26/424), 30.57 MiB | 3.35 MiB/s
Receiving objects: 6% (26/424), 33.99 MiB | 3.35 MiB/s
Receiving objects: 6% (27/424), 35.70 MiB | 3.35 MiB/s
Receiving objects: 6% (29/424), 40.83 MiB | 3.35 MiB/s
Receiving objects: 6% (29/424), 44.21 MiB | 3.34 MiB/s
Receiving objects: 6% (29/424), 47.68 MiB | 3.35 MiB/s
Receiving objects: 6% (29/424), 51.09 MiB | 3.35 MiB/s
Receiving objects: 6% (29/424), 54.51 MiB | 3.35 MiB/s
Receiving objects: 6% (29/424), 57.93 MiB | 3.35 MiB/s
Receiving objects: 6% (29/424), 61.29 MiB | 3.34 MiB/s
Receiving objects: 6% (29/424), 64.71 MiB | 3.35 MiB/s
Receiving objects: 6% (29/424), 68.14 MiB | 3.35 MiB/s
Receiving objects: 6% (29/424), 71.57 MiB | 3.35 MiB/s
Receiving objects: 7% (30/424), 71.57 MiB | 3.35 MiB/s
Receiving objects: 8% (34/424), 71.57 MiB | 3.35 MiB/s
Receiving objects: 9% (39/424), 71.57 MiB | 3.35 MiB/s
Receiving objects: 10% (43/424), 71.57 MiB | 3.35 MiB/s
Receiving objects: 11% (47/424), 71.57 MiB | 3.35 MiB/s
Receiving objects: 11% (50/424), 74.99 MiB | 3.35 MiB/s
Receiving objects: 12% (51/424), 76.69 MiB | 3.36 MiB/s
Receiving objects: 13% (56/424), 76.69 MiB | 3.36 MiB/s
Receiving objects: 14% (60/424), 76.69 MiB | 3.36 MiB/s
Receiving objects: 15% (64/424), 76.69 MiB | 3.36 MiB/s
Receiving objects: 16% (68/424), 76.69 MiB | 3.36 MiB/s
Receiving objects: 17% (73/424), 76.69 MiB | 3.36 MiB/s
Receiving objects: 18% (77/424), 76.69 MiB | 3.36 MiB/s
Receiving objects: 19% (81/424), 76.69 MiB | 3.36 MiB/s
Receiving objects: 20% (85/424), 76.69 MiB | 3.36 MiB/s
Receiving objects: 21% (90/424), 76.69 MiB | 3.36 MiB/s
Receiving objects: 22% (94/424), 76.69 MiB | 3.36 MiB/s
Receiving objects: 23% (98/424), 76.69 MiB | 3.36 MiB/s
Receiving objects: 24% (102/424), 76.69 MiB | 3.36 MiB/s
Receiving objects: 25% (106/424), 76.69 MiB | 3.36 MiB/s
Receiving objects: 26% (111/424), 76.69 MiB | 3.36 MiB/s
Receiving objects: 27% (115/424), 76.69 MiB | 3.36 MiB/s
Receiving objects: 27% (115/424), 81.82 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 83.54 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 86.96 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 90.43 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 93.86 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 97.28 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 100.64 MiB | 3.34 MiB/s
Receiving objects: 27% (115/424), 104.12 MiB | 3.36 MiB/s
Receiving objects: 27% (115/424), 107.54 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 110.96 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 114.38 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 117.80 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 121.22 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 124.64 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 128.05 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 131.48 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 134.90 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 138.32 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 141.75 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 145.17 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 148.59 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 152.01 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 155.44 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 158.86 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 160.57 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 164.00 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 167.41 MiB | 3.35 MiB/s
Receiving objects: 27% (115/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 28% (119/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 29% (123/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 30% (128/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 31% (132/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 32% (136/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 33% (140/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 34% (145/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 35% (149/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 36% (153/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 37% (157/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 38% (162/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 39% (166/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 40% (170/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 41% (174/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 42% (179/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 43% (183/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 44% (187/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 45% (191/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 46% (196/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 47% (200/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 48% (204/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 49% (208/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 50% (212/424), 170.83 MiB | 3.35 MiB/s
Receiving objects: 51% (217/424), 172.54 MiB | 3.35 MiB/s
Receiving objects: 52% (221/424), 172.54 MiB | 3.35 MiB/s
Receiving objects: 53% (225/424), 172.54 MiB | 3.35 MiB/s
Receiving objects: 54% (229/424), 172.54 MiB | 3.35 MiB/s
Receiving objects: 55% (234/424), 172.54 MiB | 3.35 MiB/s
Receiving objects: 56% (238/424), 172.54 MiB | 3.35 MiB/s
Receiving objects: 56% (240/424), 174.25 MiB | 3.35 MiB/s
Receiving objects: 56% (240/424), 177.68 MiB | 3.35 MiB/s
Receiving objects: 56% (240/424), 181.10 MiB | 3.35 MiB/s
Receiving objects: 56% (240/424), 184.52 MiB | 3.35 MiB/s
Receiving objects: 56% (240/424), 187.94 MiB | 3.35 MiB/s
Receiving objects: 56% (240/424), 191.36 MiB | 3.35 MiB/s
Receiving objects: 56% (240/424), 194.79 MiB | 3.35 MiB/s
Receiving objects: 56% (240/424), 198.21 MiB | 3.35 MiB/s
Receiving objects: 56% (240/424), 201.63 MiB | 3.35 MiB/s
Receiving objects: 56% (240/424), 205.06 MiB | 3.35 MiB/s
Receiving objects: 56% (240/424), 208.47 MiB | 3.35 MiB/s
Receiving objects: 57% (242/424), 208.47 MiB | 3.35 MiB/s
Receiving objects: 58% (246/424), 208.47 MiB | 3.35 MiB/s
Receiving objects: 59% (251/424), 208.47 MiB | 3.35 MiB/s
Receiving objects: 60% (255/424), 208.47 MiB | 3.35 MiB/s
Receiving objects: 61% (259/424), 208.47 MiB | 3.35 MiB/s
Receiving objects: 61% (262/424), 211.89 MiB | 3.35 MiB/s
Receiving objects: 62% (263/424), 211.89 MiB | 3.35 MiB/s
Receiving objects: 62% (263/424), 215.32 MiB | 3.35 MiB/s
Receiving objects: 62% (264/424), 218.74 MiB | 3.35 MiB/s
Receiving objects: 62% (265/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 63% (268/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 64% (272/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 65% (276/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 66% (280/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 67% (285/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 68% (289/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 69% (293/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 70% (297/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 71% (302/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 72% (306/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 73% (310/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 74% (314/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 75% (318/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 76% (323/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 77% (327/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 78% (331/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 79% (335/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 80% (340/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 81% (344/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 82% (348/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 83% (352/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 84% (357/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 85% (361/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 86% (365/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 87% (369/424), 222.15 MiB | 3.35 MiB/s
Receiving objects: 87% (370/424), 225.57 MiB | 3.35 MiB/s
Receiving objects: 87% (370/424), 228.99 MiB | 3.35 MiB/s
Receiving objects: 87% (370/424), 232.41 MiB | 3.35 MiB/s
Receiving objects: 87% (370/424), 235.83 MiB | 3.35 MiB/s
Receiving objects: 87% (370/424), 239.25 MiB | 3.36 MiB/s
Receiving objects: 87% (370/424), 240.97 MiB | 3.35 MiB/s
Receiving objects: 87% (370/424), 244.39 MiB | 3.35 MiB/s
Receiving objects: 87% (370/424), 247.81 MiB | 3.35 MiB/s
Receiving objects: 87% (370/424), 251.23 MiB | 3.35 MiB/s
Receiving objects: 87% (370/424), 254.65 MiB | 3.35 MiB/s
Receiving objects: 87% (370/424), 258.08 MiB | 3.35 MiB/s
Receiving objects: 87% (371/424), 261.50 MiB | 3.35 MiB/s
Receiving objects: 87% (371/424), 264.93 MiB | 3.36 MiB/s
Receiving objects: 87% (371/424), 268.34 MiB | 3.35 MiB/s
Receiving objects: 87% (371/424), 271.76 MiB | 3.35 MiB/s
Receiving objects: 87% (371/424), 275.18 MiB | 3.35 MiB/s
Receiving objects: 87% (371/424), 278.60 MiB | 3.35 MiB/s
Receiving objects: 87% (371/424), 282.02 MiB | 3.35 MiB/s
Receiving objects: 87% (371/424), 285.44 MiB | 3.35 MiB/s
Receiving objects: 87% (371/424), 288.86 MiB | 3.35 MiB/s
Receiving objects: 87% (371/424), 292.29 MiB | 3.36 MiB/s
Receiving objects: 87% (372/424), 294.00 MiB | 3.35 MiB/s
Receiving objects: 88% (374/424), 295.71 MiB | 3.35 MiB/s
Receiving objects: 89% (378/424), 295.71 MiB | 3.35 MiB/s
Receiving objects: 90% (382/424), 295.71 MiB | 3.35 MiB/s
Receiving objects: 91% (386/424), 295.71 MiB | 3.35 MiB/s
Receiving objects: 92% (391/424), 295.71 MiB | 3.35 MiB/s
Receiving objects: 93% (395/424), 295.71 MiB | 3.35 MiB/s
Receiving objects: 94% (399/424), 295.71 MiB | 3.35 MiB/s
Receiving objects: 95% (403/424), 295.71 MiB | 3.35 MiB/s
Receiving objects: 95% (407/424), 299.14 MiB | 3.35 MiB/s
Receiving objects: 95% (407/424), 302.56 MiB | 3.35 MiB/s
Receiving objects: 95% (407/424), 305.99 MiB | 3.35 MiB/s
Receiving objects: 95% (407/424), 309.40 MiB | 3.35 MiB/s
Receiving objects: 95% (407/424), 312.82 MiB | 3.35 MiB/s
Receiving objects: 95% (407/424), 316.24 MiB | 3.35 MiB/s
Receiving objects: 95% (407/424), 317.95 MiB | 3.35 MiB/s
Receiving objects: 95% (407/424), 321.36 MiB | 3.35 MiB/s
Receiving objects: 95% (407/424), 324.79 MiB | 3.35 MiB/s
Receiving objects: 95% (407/424), 328.18 MiB | 3.34 MiB/s
Receiving objects: 95% (407/424), 331.63 MiB | 3.35 MiB/s
Receiving objects: 96% (408/424), 333.34 MiB | 3.35 MiB/s
Receiving objects: 97% (412/424), 333.34 MiB | 3.35 MiB/s
Receiving objects: 98% (416/424), 333.34 MiB | 3.35 MiB/s
Receiving objects: 99% (420/424), 333.34 MiB | 3.35 MiB/s
remote: Total 424 (delta 84), reused 99 (delta 55), pack-reused 284[K
Receiving objects: 100% (424/424), 333.34 MiB | 3.35 MiB/s
Receiving objects: 100% (424/424), 334.57 MiB | 3.35 MiB/s, done.
Resolving deltas: 0% (0/226)
Resolving deltas: 4% (11/226)
Resolving deltas: 7% (17/226)
Resolving deltas: 9% (22/226)
Resolving deltas: 15% (35/226)
Resolving deltas: 17% (40/226)
Resolving deltas: 19% (44/226)
Resolving deltas: 23% (52/226)
Resolving deltas: 26% (59/226)
Resolving deltas: 28% (65/226)
Resolving deltas: 35% (81/226)
Resolving deltas: 36% (83/226)
Resolving deltas: 39% (89/226)
Resolving deltas: 42% (95/226)
Resolving deltas: 46% (104/226)
Resolving deltas: 50% (114/226)
Resolving deltas: 51% (116/226)
Resolving deltas: 55% (125/226)
Resolving deltas: 58% (133/226)
Resolving deltas: 59% (135/226)
Resolving deltas: 60% (136/226)
Resolving deltas: 61% (138/226)
Resolving deltas: 69% (158/226)
Resolving deltas: 83% (188/226)
Resolving deltas: 92% (208/226)
Resolving deltas: 94% (213/226)
Resolving deltas: 95% (215/226)
Resolving deltas: 96% (217/226)
Resolving deltas: 97% (220/226)
Resolving deltas: 98% (222/226)
Resolving deltas: 99% (224/226)
Resolving deltas: 100% (226/226)
Resolving deltas: 100% (226/226), done.
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/notebooks/274-efficient-sam/EfficientSAM
PyTorch モデルのロード¶
リポジトリーにはいくつかのモデルが用意されています。
efficient-sam-vitt - 画像エンコーダーとして Vision Transformer Tiny (VIT-T) を搭載した EfficientSAM。EfficientSAM ファミリーの最小かつ最速のモデル。
efficient-sam-vits - 画像エンコーダーとして Vision Transformer Small (VIT-S) を搭載した EfficientSAM。Efficiency-sam-vitt よりも重いですが、より正確なモデルです。
EfficientSAM は、モデルとの対話のための統一されたインターフェースを提供します。つまり、ノートブックで提供されるモデルの変換と実行のすべての手順は、すべてのモデルで同じになります。以下では、例としてそのうちの 1 つを選択できます。
from efficient_sam.build_efficient_sam import build_efficient_sam_vitt, build_efficient_sam_vits
import zipfile
MODELS_LIST = {"efficient-sam-vitt": build_efficient_sam_vitt, "efficient-sam-vits": build_efficient_sam_vits}
# Since EfficientSAM-S checkpoint file is >100MB, we store the zip file.
with zipfile.ZipFile("weights/efficient_sam_vits.pt.zip", 'r') as zip_ref:
zip_ref.extractall("weights")
サポートされるモデルから 1 つ選択してください。
import ipywidgets as widgets
model_ids = list(MODELS_LIST)
model_id = widgets.Dropdown(
options=model_ids,
value=model_ids[0],
description="Model:",
disabled=False,
)
model_id
Dropdown(description='Model:', options=('efficient-sam-vitt', 'efficient-sam-vits'), value='efficient-sam-vitt…
PyTorch モデルのビルド
pt_model = MODELS_LIST[model_id.value]()
pt_model.eval();
PyTorch モデル推論を実行¶
PyTorchモデルを選択してロードすると、その結果を確認できます。
入力データを準備¶
まず、モデルの入力データを準備する必要があります。モデルには 3 つの入力があります。
- 画像テンソル - 正規化された入力画像を持つテンソル。
- 入力ポイント - ユーザーが指定したポイントを持つテンソル。これは、画像上の特定のポイント (画面上でのユーザーのクリックによって提供されるものなど) である場合もあれば、左上の角度ポイントと右下の角度ポイントの形式の境界ボックス座標である場合もあります。
- 入力ラベル - 指定された各ポイントのポイントタイプの定義を含むテンソル。
- 通常のポイント
- 境界ボックスの左上のポイント
- 境界ボックスの右下のポイント
from PIL import Image
image_path = "figs/examples/dogs.jpg"
image = Image.open(image_path)
image

入力および出力処理のヘルパーを定義¶
以下のコードは、モデル入力と後処理推論結果を準備するためのヘルパーを定義します。入力形式は、上記のモデルで受け入れられます。モデルは、画像上の各ピクセルのマスクロジットと、各領域の交差と結合のスコア、指定されたポイントにどれだけ近いかを予測します。結果の視覚化のためのヘルパー関数もいくつか用意しました。
import torch
import matplotlib.pyplot as plt
import numpy as np
def prepare_input(input_image, points, labels, torch_tensor=True):
img_tensor = np.ascontiguousarray(input_image)[None, ...].astype(np.float32) / 255
img_tensor = np.transpose(img_tensor, (0, 3, 1, 2))
pts_sampled = np.reshape(np.ascontiguousarray(points), [1, 1, -1, 2])
pts_labels = np.reshape(np.ascontiguousarray(labels), [1, 1, -1])
if torch_tensor:
img_tensor = torch.from_numpy(img_tensor)
pts_sampled = torch.from_numpy(pts_sampled)
pts_labels = torch.from_numpy(pts_labels)
return img_tensor, pts_sampled, pts_labels
def postprocess_results(predicted_iou, predicted_logits):
sorted_ids = np.argsort(-predicted_iou, axis=-1)
predicted_iou = np.take_along_axis(predicted_iou, sorted_ids, axis=2)
predicted_logits = np.take_along_axis(
predicted_logits, sorted_ids[..., None, None], axis=2
)
return predicted_logits[0, 0, 0, :, :] >= 0
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels == 1]
neg_points = coords[labels == 0]
ax.scatter(
pos_points[:, 0],
pos_points[:, 1],
color="green",
marker="*",
s=marker_size,
edgecolor="white",
linewidth=1.25,
)
ax.scatter(
neg_points[:, 0],
neg_points[:, 1],
color="red",
marker="*",
s=marker_size,
edgecolor="white",
linewidth=1.25,
)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(
plt.Rectangle((x0, y0), w, h, edgecolor="yellow", facecolor=(0, 0, 0, 0), lw=5)
)
def show_anns(mask, ax):
ax.set_autoscale_on(False)
img = np.ones((mask.shape[0], mask.shape[1], 4))
img[:, :, 3] = 0
# for ann in mask:
# m = ann
color_mask = np.concatenate([np.random.random(3), [0.5]])
img[mask] = color_mask
ax.imshow(img)
完全なモデル推論の例を以下に示します。
input_points = [[580, 350], [650, 350]]
input_labels = [1, 1]
example_input = prepare_input(image, input_points, input_labels)
predicted_logits, predicted_iou = pt_model(*example_input)
predicted_mask = postprocess_results(predicted_iou.detach().numpy(), predicted_logits.detach().numpy())
image = Image.open(image_path)
plt.figure(figsize=(20, 20))
plt.axis("off")
plt.imshow(image)
show_points(np.array(input_points), np.array(input_labels), plt.gca())
plt.figure(figsize=(20, 20))
plt.axis("off")
plt.imshow(image)
show_anns(predicted_mask, plt.gca())
plt.title(f"PyTorch {model_id.value}", fontsize=18)
plt.show()


モデルを OpenVINO IR 形式に変換¶
OpenVINO は、OpenVINO モデル変換 API を使用して中間表現 (IR) 形式に変換することにより、PyTorch モデルをサポートします。openvino.convert_model 関数は、PyTorch モデルのインスタンスとサンプル入力 (正しいモデル操作のトレースと形状の推論に役立ちます) を受け入れ、OpenVINO フレームワークでモデルを表す openvino.Model オブジェクトを返します。この openvino.Model は、ov.Core.compile_model を使用してデバイスに読み込む準備ができており、openvino.save_model を使用してディスクに保存することもできます。
import openvino as ov
core = ov.Core()
ov_model_path = Path(f'{model_id.value}.xml')
if not ov_model_path.exists():
ov_model = ov.convert_model(pt_model, example_input=example_input)
ov.save_model(ov_model, ov_model_path)
else:
ov_model = core.read_model(ov_model_path)
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/notebooks/274-efficient-sam/EfficientSAM/efficient_sam/efficient_sam.py:220: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if (
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/notebooks/274-efficient-sam/EfficientSAM/efficient_sam/efficient_sam_encoder.py:241: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert (
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/notebooks/274-efficient-sam/EfficientSAM/efficient_sam/efficient_sam_encoder.py:163: TracerWarning: Converting a tensor to a Python float might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
size = int(math.sqrt(xy_num))
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/notebooks/274-efficient-sam/EfficientSAM/efficient_sam/efficient_sam_encoder.py:164: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert size * size == xy_num
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/notebooks/274-efficient-sam/EfficientSAM/efficient_sam/efficient_sam_encoder.py:166: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if size != h or size != w:
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/notebooks/274-efficient-sam/EfficientSAM/efficient_sam/efficient_sam_encoder.py:251: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert x.shape[2] == num_patches
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/notebooks/274-efficient-sam/EfficientSAM/efficient_sam/efficient_sam.py:85: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if num_pts > self.decoder_max_num_input_points:
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/notebooks/274-efficient-sam/EfficientSAM/efficient_sam/efficient_sam.py:92: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
elif num_pts < self.decoder_max_num_input_points:
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/notebooks/274-efficient-sam/EfficientSAM/efficient_sam/efficient_sam.py:126: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if output_w > 0 and output_h > 0:
OpenVINO モデル推論を実行¶
ドロップダウン・リストから推論デバイスを選択¶
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value="AUTO",
description="Device:",
disabled=False,
)
device
Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')
OpenVINO モデルをコンパイル¶
compiled_model = core.compile_model(ov_model, device.value)
推論と結果の視覚化¶
OpenVINO モデルの予測を見てみましょう。
example_input = prepare_input(image, input_points, input_labels, torch_tensor=False)
result = compiled_model(example_input)
predicted_logits, predicted_iou = result[0], result[1]
predicted_mask = postprocess_results(predicted_iou, predicted_logits)
plt.figure(figsize=(20, 20))
plt.axis("off")
plt.imshow(image)
show_points(np.array(input_points), np.array(input_labels), plt.gca())
plt.figure(figsize=(20, 20))
plt.axis("off")
plt.imshow(image)
show_anns(predicted_mask, plt.gca())
plt.title(f"OpenVINO {model_id.value}", fontsize=18)
plt.show()


量子化¶
NNCF は、モデルグラフに量子化レイヤーを追加し、トレーニング・データセットのサブセットを使用してこれらの追加の量子化レイヤーのパラメーターを初期化することで、トレーニング後の量子化を可能にします。このフレームワークは、元のトレーニング・コードへの変更が最小限になるように設計されています。
最適化プロセスには次の手順が含まれます。
量子化用のキャリブレーション・データセットを作成します。
nncf.quantizeを実行して、量子化されたエンコーダーおよびデコーダーモデルを取得します。openvino.save_model関数を使用してINT8モデルをシリアル化します。
注: 量子化は時間とメモリーを消費する操作です。以下の量子化コードの実行には時間がかかる場合があります。
EfficientSAM 量子化を実行するかどうかを以下から選択してください。
to_quantize = widgets.Checkbox(
value=True,
description='Quantization',
disabled=False,
)
to_quantize
Checkbox(value=True, description='Quantization')
import urllib.request
urllib.request.urlretrieve(
url='https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/main/notebooks/utils/skip_kernel_extension.py',
filename='skip_kernel_extension.py'
)
%load_ext skip_kernel_extension
キャリブレーション・データセットの準備¶
最初のステップは、量子化のキャリブレーション・データセットを準備することです。量子化には coco128 データセットを使用します。通常、このデータセットはオブジェクト検出タスクを解決するために使用され、そのアノテーションは画像のボックス座標を提供します。この場合、ボックス座標はオブジェクト・セグメント化の入力ポイントとして機能し、以下のコードはデータセットをダウンロードし、EfficientSAM モデルの入力を準備する DataLoader を作成します。
%%skip not $to_quantize.value
from zipfile import ZipFile
urllib.request.urlretrieve(
url='https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/main/notebooks/utils/notebook_utils.py',
filename='notebook_utils.py'
)
from notebook_utils import download_file
DATA_URL = "https://ultralytics.com/assets/coco128.zip"
OUT_DIR = Path('.')
download_file(DATA_URL, directory=OUT_DIR, show_progress=True)
if not (OUT_DIR / "coco128/images/train2017").exists():
with ZipFile('coco128.zip' , "r") as zip_ref:
zip_ref.extractall(OUT_DIR)
coco128.zip: 0%| | 0.00/6.66M [00:00<?, ?B/s]
%%skip not $to_quantize.value
import torch.utils.data as data
class COCOLoader(data.Dataset):
def __init__(self, images_path):
self.images = list(Path(images_path).iterdir())
self.labels_dir = images_path.parents[1] / 'labels' / images_path.name
def get_points(self, image_path, image_width, image_height):
file_name = image_path.name.replace('.jpg', '.txt')
label_file = self.labels_dir / file_name
if not label_file.exists():
x1, x2 = np.random.randint(low=0, high=image_width, size=(2, ))
y1, y2 = np.random.randint(low=0, high=image_height, size=(2, ))
else:
with label_file.open("r") as f:
box_line = f.readline()
_, x1, y1, x2, y2 = box_line.split()
x1 = int(float(x1) * image_width)
y1 = int(float(y1) * image_height)
x2 = int(float(x2) * image_width)
y2 = int(float(y2) * image_height)
return [[x1, y1], [x2, y2]]
def __getitem__(self, index):
image_path = self.images[index]
image = Image.open(image_path)
image = image.convert('RGB')
w, h = image.size
points = self.get_points(image_path, w, h)
labels = [1, 1] if index % 2 == 0 else [2, 3]
batched_images, batched_points, batched_point_labels = prepare_input(image, points, labels, torch_tensor=False)
return {'batched_images': np.ascontiguousarray(batched_images)[0], 'batched_points': np.ascontiguousarray(batched_points)[0], 'batched_point_labels': np.ascontiguousarray(batched_point_labels)[0]}
def __len__(self):
return len(self.images)
%%skip not $to_quantize.value
coco_dataset = COCOLoader(OUT_DIR / 'coco128/images/train2017')
calibration_loader = torch.utils.data.DataLoader(coco_dataset)
モデル量子化の実行¶
nncf.quantize 関数は、モデルの量子化のインターフェイスを提供します。OpenVINO モデルのインスタンスと量子化データセットが必要です。オプションで、量子化プロセスの追加パラメーター (量子化のサンプル数、プリセット、無視される範囲など) を提供できます。EfficientSAM には、活性化の非対称量子化を必要とする非 ReLU 活性化関数が含まれています。さらに良い結果を得るため、mixed 量子化プリセットを使用します。モデル・エンコーダー部分はビジョン・トランスフォーマー・アーキテクチャーに基づいており、このアーキテクチャー・タイプに特別な最適化を有効にするには、model_type で transformer を指定する必要があります。
%%skip not $to_quantize.value
import nncf
calibration_dataset = nncf.Dataset(calibration_loader)
model = core.read_model(ov_model_path)
quantized_model = nncf.quantize(model,
calibration_dataset,
model_type=nncf.parameters.ModelType.TRANSFORMER,
preset=nncf.common.quantization.structs.QuantizationPreset.MIXED, subset_size=128)
print("model quantization finished")
INFO:nncf:NNCF initialized successfully. Supported frameworks detected: torch, tensorflow, onnx, openvino
2024-02-10 00:36:45.274123: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0. 2024-02-10 00:36:45.306722: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-02-10 00:36:45.919421: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
Output()
INFO:nncf:57 ignored nodes were found by name in the NNCFGraph
INFO:nncf:88 ignored nodes were found by name in the NNCFGraph
Output()
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/nncf/experimental/tensor/tensor.py:84: RuntimeWarning: invalid value encountered in multiply
return Tensor(self.data * unwrap_tensor_data(other))
Output()
model quantization finished
量子化モデル推論の検証¶
%%skip not $to_quantize.value
compiled_model = core.compile_model(quantized_model, device.value)
result = compiled_model(example_input)
predicted_logits, predicted_iou = result[0], result[1]
predicted_mask = postprocess_results(predicted_iou, predicted_logits)
plt.figure(figsize=(20, 20))
plt.axis("off")
plt.imshow(image)
show_points(np.array(input_points), np.array(input_labels), plt.gca())
plt.figure(figsize=(20, 20))
plt.axis("off")
plt.imshow(image)
show_anns(predicted_mask, plt.gca())
plt.title(f"OpenVINO INT8 {model_id.value}", fontsize=18)
plt.show()


量子化モデルをディスクに保存¶
%%skip not $to_quantize.value
quantized_model_path = Path(f"{model_id.value}_int8.xml")
ov.save_model(quantized_model, quantized_model_path)
量子化モデルのサイズを比較¶
%%skip not $to_quantize.value
fp16_weights = ov_model_path.with_suffix('.bin')
quantized_weights = quantized_model_path.with_suffix('.bin')
print(f"Size of FP16 model is {fp16_weights.stat().st_size / 1024 / 1024:.2f} MB")
print(f"Size of INT8 quantized model is {quantized_weights.stat().st_size / 1024 / 1024:.2f} MB")
print(f"Compression rate for INT8 model: {fp16_weights.stat().st_size / quantized_weights.stat().st_size:.3f}")
Size of FP16 model is 21.50 MB
Size of INT8 quantized model is 10.96 MB
Compression rate for INT8 model: 1.962
FP16 モデルと INT8 モデルの推論時間を比較¶
FP16 モデルと INT8 モデルの推論パフォーマンスを測定するには、bencmark_app を使用します。
注: 最も正確なパフォーマンス推定を行うには、他のアプリケーションを閉じた後、ターミナル/コマンドプロンプトで
benchmark_appを実行することを推奨します。
!benchmark_app -m $ov_model_path -d $device.value -data_shape "batched_images[1,3,512,512],batched_points[1,1,2,2],batched_point_labels[1,1,2]" -t 15
[Step 1/11] Parsing and validating input arguments
[ INFO ] Parsing input parameters
[Step 2/11] Loading OpenVINO Runtime
[ INFO ] OpenVINO:
[ INFO ] Build ................................. 2023.3.0-13775-ceeafaf64f3-releases/2023/3
[ INFO ]
[ INFO ] Device info:
[ INFO ] AUTO
[ INFO ] Build ................................. 2023.3.0-13775-ceeafaf64f3-releases/2023/3
[ INFO ]
[ INFO ]
[Step 3/11] Setting device configuration
[ WARNING ] Performance hint was not explicitly specified in command line. Device(AUTO) performance hint will be set to PerformanceMode.THROUGHPUT.
[Step 4/11] Reading model files
[ INFO ] Loading model files
[ INFO ] Read model took 42.80 ms
[ INFO ] Original model I/O parameters:
[ INFO ] Model inputs:
[ INFO ] batched_images (node: batched_images) : f32 / [...] / [?,?,?,?]
[ INFO ] batched_points (node: batched_points) : i64 / [...] / [?,?,?,?]
[ INFO ] batched_point_labels (node: batched_point_labels) : i64 / [...] / [?,?,?]
[ INFO ] Model outputs:
[ INFO ] 133 (node: aten::reshape/Reshape_3) : f32 / [...] / [?,?,?,?,?]
[ INFO ] 135 (node: aten::reshape/Reshape_2) : f32 / [...] / [?,?,?]
[Step 5/11] Resizing model to match image sizes and given batch
[ INFO ] Model batch size: 1
[Step 6/11] Configuring input of the model
[ INFO ] Model inputs:
[ INFO ] batched_images (node: batched_images) : f32 / [...] / [?,?,?,?]
[ INFO ] batched_points (node: batched_points) : i64 / [...] / [?,?,?,?]
[ INFO ] batched_point_labels (node: batched_point_labels) : i64 / [...] / [?,?,?]
[ INFO ] Model outputs:
[ INFO ] 133 (node: aten::reshape/Reshape_3) : f32 / [...] / [?,?,?,?,?]
[ INFO ] 135 (node: aten::reshape/Reshape_2) : f32 / [...] / [?,?,?]
[Step 7/11] Loading the model to the device
[ INFO ] Compile model took 1174.09 ms
[Step 8/11] Querying optimal runtime parameters
[ INFO ] Model:
[ INFO ] NETWORK_NAME: Model0
[ INFO ] EXECUTION_DEVICES: ['CPU']
[ INFO ] PERFORMANCE_HINT: PerformanceMode.THROUGHPUT
[ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 6
[ INFO ] MULTI_DEVICE_PRIORITIES: CPU
[ INFO ] CPU:
[ INFO ] AFFINITY: Affinity.CORE
[ INFO ] CPU_DENORMALS_OPTIMIZATION: False
[ INFO ] CPU_SPARSE_WEIGHTS_DECOMPRESSION_RATE: 1.0
[ INFO ] ENABLE_CPU_PINNING: True
[ INFO ] ENABLE_HYPER_THREADING: True
[ INFO ] EXECUTION_DEVICES: ['CPU']
[ INFO ] EXECUTION_MODE_HINT: ExecutionMode.PERFORMANCE
[ INFO ] INFERENCE_NUM_THREADS: 24
[ INFO ] INFERENCE_PRECISION_HINT: <Type: 'float32'>
[ INFO ] NETWORK_NAME: Model0
[ INFO ] NUM_STREAMS: 6
[ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 6
[ INFO ] PERFORMANCE_HINT: THROUGHPUT
[ INFO ] PERFORMANCE_HINT_NUM_REQUESTS: 0
[ INFO ] PERF_COUNT: NO
[ INFO ] SCHEDULING_CORE_TYPE: SchedulingCoreType.ANY_CORE
[ INFO ] MODEL_PRIORITY: Priority.MEDIUM
[ INFO ] LOADED_FROM_CACHE: False
[Step 9/11] Creating infer requests and preparing input tensors
[ WARNING ] No input files were given for input 'batched_images'!. This input will be filled with random values!
[ WARNING ] No input files were given for input 'batched_points'!. This input will be filled with random values!
[ WARNING ] No input files were given for input 'batched_point_labels'!. This input will be filled with random values!
[ INFO ] Fill input 'batched_images' with random values
[ INFO ] Fill input 'batched_points' with random values
[ INFO ] Fill input 'batched_point_labels' with random values
[Step 10/11] Measuring performance (Start inference asynchronously, 6 inference requests, limits: 15000 ms duration)
[ INFO ] Benchmarking in full mode (inputs filling are included in measurement loop).
[ INFO ] First inference took 644.38 ms
[Step 11/11] Dumping statistics report
[ INFO ] Execution Devices:['CPU']
[ INFO ] Count: 50 iterations
[ INFO ] Duration: 16093.09 ms
[ INFO ] Latency:
[ INFO ] Median: 1872.68 ms
[ INFO ] Average: 1848.02 ms
[ INFO ] Min: 1047.31 ms
[ INFO ] Max: 1952.79 ms
[ INFO ] Throughput: 3.11 FPS
if to_quantize.value:
!benchmark_app -m $quantized_model_path -d $device.value -data_shape "batched_images[1,3,512,512],batched_points[1,1,2,2],batched_point_labels[1,1,2]" -t 15
[Step 1/11] Parsing and validating input arguments
[ INFO ] Parsing input parameters
[Step 2/11] Loading OpenVINO Runtime
[ INFO ] OpenVINO:
[ INFO ] Build ................................. 2023.3.0-13775-ceeafaf64f3-releases/2023/3
[ INFO ]
[ INFO ] Device info:
[ INFO ] AUTO
[ INFO ] Build ................................. 2023.3.0-13775-ceeafaf64f3-releases/2023/3
[ INFO ]
[ INFO ]
[Step 3/11] Setting device configuration
[ WARNING ] Performance hint was not explicitly specified in command line. Device(AUTO) performance hint will be set to PerformanceMode.THROUGHPUT.
[Step 4/11] Reading model files
[ INFO ] Loading model files
[ INFO ] Read model took 65.77 ms
[ INFO ] Original model I/O parameters:
[ INFO ] Model inputs:
[ INFO ] batched_images (node: batched_images) : f32 / [...] / [?,?,?,?]
[ INFO ] batched_points (node: batched_points) : i64 / [...] / [?,?,?,?]
[ INFO ] batched_point_labels (node: batched_point_labels) : i64 / [...] / [?,?,?]
[ INFO ] Model outputs:
[ INFO ] 133 (node: aten::reshape/Reshape_3) : f32 / [...] / [?,?,?,?,?]
[ INFO ] 135 (node: aten::reshape/Reshape_2) : f32 / [...] / [?,?,?]
[Step 5/11] Resizing model to match image sizes and given batch
[ INFO ] Model batch size: 1
[Step 6/11] Configuring input of the model
[ INFO ] Model inputs:
[ INFO ] batched_images (node: batched_images) : f32 / [...] / [?,?,?,?]
[ INFO ] batched_points (node: batched_points) : i64 / [...] / [?,?,?,?]
[ INFO ] batched_point_labels (node: batched_point_labels) : i64 / [...] / [?,?,?]
[ INFO ] Model outputs:
[ INFO ] 133 (node: aten::reshape/Reshape_3) : f32 / [...] / [?,?,?,?,?]
[ INFO ] 135 (node: aten::reshape/Reshape_2) : f32 / [...] / [?,?,?]
[Step 7/11] Loading the model to the device
[ INFO ] Compile model took 1539.94 ms
[Step 8/11] Querying optimal runtime parameters
[ INFO ] Model:
[ INFO ] NETWORK_NAME: Model0
[ INFO ] EXECUTION_DEVICES: ['CPU']
[ INFO ] PERFORMANCE_HINT: PerformanceMode.THROUGHPUT
[ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 6
[ INFO ] MULTI_DEVICE_PRIORITIES: CPU
[ INFO ] CPU:
[ INFO ] AFFINITY: Affinity.CORE
[ INFO ] CPU_DENORMALS_OPTIMIZATION: False
[ INFO ] CPU_SPARSE_WEIGHTS_DECOMPRESSION_RATE: 1.0
[ INFO ] ENABLE_CPU_PINNING: True
[ INFO ] ENABLE_HYPER_THREADING: True
[ INFO ] EXECUTION_DEVICES: ['CPU']
[ INFO ] EXECUTION_MODE_HINT: ExecutionMode.PERFORMANCE
[ INFO ] INFERENCE_NUM_THREADS: 24
[ INFO ] INFERENCE_PRECISION_HINT: <Type: 'float32'>
[ INFO ] NETWORK_NAME: Model0
[ INFO ] NUM_STREAMS: 6
[ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 6
[ INFO ] PERFORMANCE_HINT: THROUGHPUT
[ INFO ] PERFORMANCE_HINT_NUM_REQUESTS: 0
[ INFO ] PERF_COUNT: NO
[ INFO ] SCHEDULING_CORE_TYPE: SchedulingCoreType.ANY_CORE
[ INFO ] MODEL_PRIORITY: Priority.MEDIUM
[ INFO ] LOADED_FROM_CACHE: False
[Step 9/11] Creating infer requests and preparing input tensors
[ WARNING ] No input files were given for input 'batched_images'!. This input will be filled with random values!
[ WARNING ] No input files were given for input 'batched_points'!. This input will be filled with random values!
[ WARNING ] No input files were given for input 'batched_point_labels'!. This input will be filled with random values!
[ INFO ] Fill input 'batched_images' with random values
[ INFO ] Fill input 'batched_points' with random values
[ INFO ] Fill input 'batched_point_labels' with random values
[Step 10/11] Measuring performance (Start inference asynchronously, 6 inference requests, limits: 15000 ms duration)
[ INFO ] Benchmarking in full mode (inputs filling are included in measurement loop).
[ INFO ] First inference took 578.80 ms
[Step 11/11] Dumping statistics report
[ INFO ] Execution Devices:['CPU']
[ INFO ] Count: 55 iterations
[ INFO ] Duration: 16094.50 ms
[ INFO ] Latency:
[ INFO ] Median: 1735.52 ms
[ INFO ] Average: 1715.26 ms
[ INFO ] Min: 507.00 ms
[ INFO ] Max: 1794.23 ms
[ INFO ] Throughput: 3.42 FPS
インタラクティブなセグメント化のデモ¶
import copy
import gradio as gr
import numpy as np
from PIL import ImageDraw, Image
import cv2
import matplotlib.pyplot as plt
example_images = [
"https://github.com/openvinotoolkit/openvino_notebooks/assets/29454499/b8083dd5-1ce7-43bf-8b09-a2ebc280c86e",
"https://github.com/openvinotoolkit/openvino_notebooks/assets/29454499/9a90595d-70e7-469b-bdaf-469ef4f56fa2",
"https://github.com/openvinotoolkit/openvino_notebooks/assets/29454499/b626c123-9fa2-4aa6-9929-30565991bf0c",
]
examples_dir = Path("examples")
examples_dir.mkdir(exist_ok=True)
for img_id, image_url in enumerate(example_images):
urllib.request.urlretrieve(image_url, examples_dir / f"example_{img_id}.jpg")
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def clear():
return None, None, [], []
def format_results(masks, scores, logits, filter=0):
annotations = []
n = len(scores)
for i in range(n):
annotation = {}
mask = masks[i]
tmp = np.where(mask != 0)
if np.sum(mask) < filter:
continue
annotation["id"] = i
annotation["segmentation"] = mask
annotation["bbox"] = [np.min(tmp[0]), np.min(tmp[1]), np.max(tmp[1]), np.max(tmp[0])]
annotation["score"] = scores[i]
annotation["area"] = annotation["segmentation"].sum()
annotations.append(annotation)
return annotations
def point_prompt(masks, points, point_label, target_height, target_width): # numpy
h = masks[0]["segmentation"].shape[0]
w = masks[0]["segmentation"].shape[1]
if h != target_height or w != target_width:
points = [
[int(point[0] * w / target_width), int(point[1] * h / target_height)]
for point in points
]
onemask = np.zeros((h, w))
for i, annotation in enumerate(masks):
if isinstance(annotation, dict):
mask = annotation["segmentation"]
else:
mask = annotation
for i, point in enumerate(points):
if point[1] < mask.shape[0] and point[0] < mask.shape[1]:
if mask[point[1], point[0]] == 1 and point_label[i] == 1:
onemask += mask
if mask[point[1], point[0]] == 1 and point_label[i] == 0:
onemask -= mask
onemask = onemask >= 1
return onemask, 0
def show_mask(
annotation,
ax,
random_color=False,
bbox=None,
retinamask=True,
target_height=960,
target_width=960,
):
mask_sum = annotation.shape[0]
height = annotation.shape[1]
weight = annotation.shape[2]
# annotation is sorted by area
areas = np.sum(annotation, axis=(1, 2))
sorted_indices = np.argsort(areas)[::1]
annotation = annotation[sorted_indices]
index = (annotation != 0).argmax(axis=0)
if random_color:
color = np.random.random((mask_sum, 1, 1, 3))
else:
color = np.ones((mask_sum, 1, 1, 3)) * np.array([30 / 255, 144 / 255, 255 / 255])
transparency = np.ones((mask_sum, 1, 1, 1)) * 0.6
visual = np.concatenate([color, transparency], axis=-1)
mask_image = np.expand_dims(annotation, -1) * visual
mask = np.zeros((height, weight, 4))
h_indices, w_indices = np.meshgrid(
np.arange(height), np.arange(weight), indexing="ij"
)
indices = (index[h_indices, w_indices], h_indices, w_indices, slice(None))
mask[h_indices, w_indices, :] = mask_image[indices]
if bbox is not None:
x1, y1, x2, y2 = bbox
ax.add_patch(plt.Rectangle((x1, y1), x2 - x1, y2 - y1, fill=False, edgecolor="b", linewidth=1))
if not retinamask:
mask = cv2.resize(mask, (target_width, target_height), interpolation=cv2.INTER_NEAREST)
return mask
def process(
annotations,
image,
scale,
better_quality=False,
mask_random_color=True,
bbox=None,
points=None,
use_retina=True,
withContours=True,
):
if isinstance(annotations[0], dict):
annotations = [annotation["segmentation"] for annotation in annotations]
original_h = image.height
original_w = image.width
if better_quality:
if isinstance(annotations[0], torch.Tensor):
annotations = np.array(annotations)
for i, mask in enumerate(annotations):
mask = cv2.morphologyEx(mask.astype(np.uint8), cv2.MORPH_CLOSE, np.ones((3, 3), np.uint8))
annotations[i] = cv2.morphologyEx(mask.astype(np.uint8), cv2.MORPH_OPEN, np.ones((8, 8), np.uint8))
annotations = np.array(annotations)
inner_mask = show_mask(
annotations,
plt.gca(),
random_color=mask_random_color,
bbox=bbox,
retinamask=use_retina,
target_height=original_h,
target_width=original_w,
)
if isinstance(annotations, torch.Tensor):
annotations = annotations.cpu().numpy()
if withContours:
contour_all = []
temp = np.zeros((original_h, original_w, 1))
for i, mask in enumerate(annotations):
if isinstance(mask, dict):
mask = mask["segmentation"]
annotation = mask.astype(np.uint8)
if not use_retina:
annotation = cv2.resize(
annotation,
(original_w, original_h),
interpolation=cv2.INTER_NEAREST,
)
contours, _ = cv2.findContours(
annotation, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE
)
for contour in contours:
contour_all.append(contour)
cv2.drawContours(temp, contour_all, -1, (255, 255, 255), 2 // scale)
color = np.array([0 / 255, 0 / 255, 255 / 255, 0.9])
contour_mask = temp / 255 * color.reshape(1, 1, -1)
image = image.convert("RGBA")
overlay_inner = Image.fromarray((inner_mask * 255).astype(np.uint8), "RGBA")
image.paste(overlay_inner, (0, 0), overlay_inner)
if withContours:
overlay_contour = Image.fromarray((contour_mask * 255).astype(np.uint8), "RGBA")
image.paste(overlay_contour, (0, 0), overlay_contour)
return image
# Description
title = "<center><strong><font size='8'>Efficient Segment Anything with OpenVINO and EfficientSAM <font></strong></center>"
description_p = """# Interactive Instance Segmentation
- Point-prompt instruction
<ol>
<li> Click on the left image (point input), visualizing the point on the right image </li>
<li> Click the button of Segment with Point Prompt </li>
</ol>
- Box-prompt instruction
<ol>
<li> Click on the left image (one point input), visualizing the point on the right image </li>
<li> Click on the left image (another point input), visualizing the point and the box on the right image</li>
<li> Click the button of Segment with Box Prompt </li>
</ol>
"""
# examples
examples = [[img] for img in examples_dir.glob("*.jpg")]
default_example = examples[0]
css = "h1 { text-align: center } .about { text-align: justify; padding-left: 10%; padding-right: 10%; }"
def segment_with_boxs(
image,
seg_image,
global_points,
global_point_label,
input_size=1024,
better_quality=False,
withContours=True,
use_retina=True,
mask_random_color=True,
):
if global_points is None or len(global_points) < 2 or global_points[0] is None:
return image, global_points, global_point_label
input_size = int(input_size)
w, h = image.size
scale = input_size / max(w, h)
new_w = int(w * scale)
new_h = int(h * scale)
image = image.resize((new_w, new_h))
scaled_points = np.array([[int(x * scale) for x in point] for point in global_points])
scaled_points = scaled_points[:2]
scaled_point_label = np.array(global_point_label)[:2]
if scaled_points.size == 0 and scaled_point_label.size == 0:
return image, global_points, global_point_label
nd_image = np.array(image)
img_tensor = nd_image.astype(np.float32) / 255
img_tensor = np.transpose(img_tensor, (2, 0, 1))
pts_sampled = np.reshape(scaled_points, [1, 1, -1, 2])
pts_sampled = pts_sampled[:, :, :2, :]
pts_labels = np.reshape(np.array([2, 3]), [1, 1, 2])
results = compiled_model([img_tensor[None, ...], pts_sampled, pts_labels])
predicted_logits = results[0]
predicted_iou = results[1]
all_masks = sigmoid(predicted_logits[0, 0, :, :, :]) >= 0.5
predicted_iou = predicted_iou[0, 0, ...]
max_predicted_iou = -1
selected_mask_using_predicted_iou = None
selected_predicted_iou = None
for m in range(all_masks.shape[0]):
curr_predicted_iou = predicted_iou[m]
if curr_predicted_iou > max_predicted_iou or selected_mask_using_predicted_iou is None:
max_predicted_iou = curr_predicted_iou
selected_mask_using_predicted_iou = all_masks[m:m + 1]
selected_predicted_iou = predicted_iou[m:m + 1]
results = format_results(selected_mask_using_predicted_iou, selected_predicted_iou, predicted_logits, 0)
annotations = results[0]["segmentation"]
annotations = np.array([annotations])
fig = process(
annotations=annotations,
image=image,
scale=(1024 // input_size),
better_quality=better_quality,
mask_random_color=mask_random_color,
use_retina=use_retina,
bbox=scaled_points.reshape([4]),
withContours=withContours,
)
global_points = []
global_point_label = []
return fig, global_points, global_point_label
def segment_with_points(
image,
global_points,
global_point_label,
input_size=1024,
better_quality=False,
withContours=True,
use_retina=True,
mask_random_color=True,
):
input_size = int(input_size)
w, h = image.size
scale = input_size / max(w, h)
new_w = int(w * scale)
new_h = int(h * scale)
image = image.resize((new_w, new_h))
if global_points is None or len(global_points) < 1 or global_points[0] is None:
return image, global_points, global_point_label
scaled_points = np.array([[int(x * scale) for x in point] for point in global_points])
scaled_point_label = np.array(global_point_label)
if scaled_points.size == 0 and scaled_point_label.size == 0:
return image, global_points, global_point_label
nd_image = np.array(image)
img_tensor = (nd_image).astype(np.float32) / 255
img_tensor = np.transpose(img_tensor, (2, 0, 1))
pts_sampled = np.reshape(scaled_points, [1, 1, -1, 2])
pts_labels = np.reshape(np.array(global_point_label), [1, 1, -1])
results = compiled_model([img_tensor[None, ...], pts_sampled, pts_labels])
predicted_logits = results[0]
predicted_iou = results[1]
all_masks = sigmoid(predicted_logits[0, 0, :, :, :]) >= 0.5
predicted_iou = predicted_iou[0, 0, ...]
results = format_results(all_masks, predicted_iou, predicted_logits, 0)
annotations, _ = point_prompt(results, scaled_points, scaled_point_label, new_h, new_w)
annotations = np.array([annotations])
fig = process(
annotations=annotations,
image=image,
scale=(1024 // input_size),
better_quality=better_quality,
mask_random_color=mask_random_color,
points=scaled_points,
bbox=None,
use_retina=use_retina,
withContours=withContours,
)
global_points = []
global_point_label = []
# return fig, None
return fig, global_points, global_point_label
def get_points_with_draw(image, cond_image, global_points, global_point_label, evt: gr.SelectData):
print(global_points)
if len(global_points) == 0:
image = copy.deepcopy(cond_image)
x, y = evt.index[0], evt.index[1]
label = "Add Mask"
point_radius, point_color = 15, (255, 255, 0) if label == "Add Mask" else (255, 0, 255)
global_points.append([x, y])
global_point_label.append(1 if label == "Add Mask" else 0)
if image is not None:
draw = ImageDraw.Draw(image)
draw.ellipse([(x - point_radius, y - point_radius), (x + point_radius, y + point_radius)], fill=point_color)
return image, global_points, global_point_label
def get_points_with_draw_(image, cond_image, global_points, global_point_label, evt: gr.SelectData):
if len(global_points) == 0:
image = copy.deepcopy(cond_image)
if len(global_points) > 2:
return image, global_points, global_point_label
x, y = evt.index[0], evt.index[1]
label = "Add Mask"
point_radius, point_color = 15, (255, 255, 0) if label == "Add Mask" else (255, 0, 255)
global_points.append([x, y])
global_point_label.append(1 if label == "Add Mask" else 0)
if image is not None:
draw = ImageDraw.Draw(image)
draw.ellipse([(x - point_radius, y - point_radius), (x + point_radius, y + point_radius)], fill=point_color)
if len(global_points) == 2:
x1, y1 = global_points[0]
x2, y2 = global_points[1]
if x1 < x2 and y1 < y2:
draw.rectangle([x1, y1, x2, y2], outline="red", width=5)
elif x1 < x2 and y1 >= y2:
draw.rectangle([x1, y2, x2, y1], outline="red", width=5)
global_points[0][0] = x1
global_points[0][1] = y2
global_points[1][0] = x2
global_points[1][1] = y1
elif x1 >= x2 and y1 < y2:
draw.rectangle([x2, y1, x1, y2], outline="red", width=5)
global_points[0][0] = x2
global_points[0][1] = y1
global_points[1][0] = x1
global_points[1][1] = y2
elif x1 >= x2 and y1 >= y2:
draw.rectangle([x2, y2, x1, y1], outline="red", width=5)
global_points[0][0] = x2
global_points[0][1] = y2
global_points[1][0] = x1
global_points[1][1] = y1
return image, global_points, global_point_label
cond_img_p = gr.Image(label="Input with Point", value=default_example[0], type="pil")
cond_img_b = gr.Image(label="Input with Box", value=default_example[0], type="pil")
segm_img_p = gr.Image(label="Segmented Image with Point-Prompt", interactive=False, type="pil")
segm_img_b = gr.Image(label="Segmented Image with Box-Prompt", interactive=False, type="pil")
with gr.Blocks(css=css, title="Efficient SAM") as demo:
global_points = gr.State([])
global_point_label = gr.State([])
with gr.Row():
with gr.Column(scale=1):
# Title
gr.Markdown(title)
with gr.Tab("Point mode"):
# Images
with gr.Row(variant="panel"):
with gr.Column(scale=1):
cond_img_p.render()
with gr.Column(scale=1):
segm_img_p.render()
# Submit & Clear
# ###
with gr.Row():
with gr.Column():
with gr.Column():
segment_btn_p = gr.Button(
"Segment with Point Prompt", variant="primary"
)
clear_btn_p = gr.Button("Clear", variant="secondary")
gr.Markdown("Try some of the examples below ⬇️")
gr.Examples(
examples=examples,
inputs=[cond_img_p],
examples_per_page=4,
)
with gr.Column():
# Description
gr.Markdown(description_p)
with gr.Tab("Box mode"):
# Images
with gr.Row(variant="panel"):
with gr.Column(scale=1):
cond_img_b.render()
with gr.Column(scale=1):
segm_img_b.render()
# Submit & Clear
with gr.Row():
with gr.Column():
with gr.Column():
segment_btn_b = gr.Button(
"Segment with Box Prompt", variant="primary"
)
clear_btn_b = gr.Button("Clear", variant="secondary")
gr.Markdown("Try some of the examples below ⬇️")
gr.Examples(
examples=examples,
inputs=[cond_img_b],
examples_per_page=4,
)
with gr.Column():
# Description
gr.Markdown(description_p)
cond_img_p.select(get_points_with_draw, inputs=[segm_img_p, cond_img_p, global_points, global_point_label], outputs=[segm_img_p, global_points, global_point_label])
cond_img_b.select(get_points_with_draw_, [segm_img_b, cond_img_b, global_points, global_point_label], [segm_img_b, global_points, global_point_label])
segment_btn_p.click(
segment_with_points, inputs=[cond_img_p, global_points, global_point_label], outputs=[segm_img_p, global_points, global_point_label]
)
segment_btn_b.click(
segment_with_boxs, inputs=[cond_img_b, segm_img_b, global_points, global_point_label], outputs=[segm_img_b, global_points, global_point_label]
)
clear_btn_p.click(clear, outputs=[cond_img_p, segm_img_p, global_points, global_point_label])
clear_btn_b.click(clear, outputs=[cond_img_b, segm_img_b, global_points, global_point_label])
demo.queue()
try:
demo.launch(debug=False)
except Exception:
demo.launch(share=True, debug=False)
# if you are launching remotely, specify server_name and server_port
# demo.launch(server_name='your server name', server_port='server port in int')
# Read more in the docs: https://gradio.app/docs/
Running on local URL: http://127.0.0.1:7860 To create a public link, set share=True in launch().