メトリック#
はじめに
このドキュメントでは、OpenVINO モデルサーバーでメトリック・エンドポイントを使用する方法について説明します。以下に適用できます:
モニタリングとベンチマークを目的としたパフォーマンスと使用率の統計の提供
アプリケーション関連のメトリックに基づいた、Kubernetes および OpenShift のモデル・サーバー・インスタンスの自動スケーリング
ビルトインメトリックにより、クライアントで追加のロジックを使用したり、ロードバランサーやリバースプロキシーなどのネットワーク・トラフィック監視ツールを使用することなく、パフォーマンスを追跡できます。
また、ネットワーク・トラフィックに関連しないメトリックも公開します。
例えば、推論実行キューの統計、モデルの実行時パラメーターなどです。また、モデルのバージョン、API タイプ、または要求されたエンドポイント・メソッドに基づいて使用状況を追跡することもできます。
OpenVINO モデルサーバーのメトリックは Prometheus 標準と互換性があります
これらは /metrics エンドポイントで公開されます。
利用可能なメトリックファミリー#
デフォルトリストのメトリックは、metrics_enable フラグまたは json 設定で有効になります。
ただし、metric_list フラグまたは json 設定で有効にするメトリックをリストすることで、追加のメトリックも有効にすることができます。
デフォルトメトリック
タイプ |
名前 |
ラベル |
説明 |
|---|---|---|---|
ゲージ |
ovms_streams |
名前、バージョン |
OpenVINO 実行ストリームの数 |
ゲージ |
ovms_current_requests |
名前、バージョン |
モデルサーバーによって現在処理されている要求の数 |
カウンター |
ovms_requests_success |
API、インターフェイス、メソッド、名前、バージョン |
モデルまたは DAG への成功した要求の数。 |
カウンター |
ovms_requests_fail |
API、インターフェイス、メソッド、名前、バージョン |
モデルまたは DAG への失敗した要求の数。 |
ヒストグラム |
ovms_request_time_us |
インターフェイス、名前、バージョン |
モデルまたは DAG への要求の処理時間。 |
ヒストグラム |
ovms_inference_time_us |
名前、バージョン |
OpenVINO バックエンドでの推論実行時間。 |
ヒストグラム |
ovms_wait_for_infer_req_time_us |
名前、バージョン |
スケジューリング・キュー内の要求の待ち時間。必要なリソースが要求に割り当てられるまでに要求が待機する時間を示します。 |
オプションのメトリック
タイプ |
名前 |
ラベル |
説明 |
|---|---|---|---|
ゲージ |
ovms_infer_req_queue_size |
名前、バージョン |
推論要求キューのサイズ (nireq)。 |
ゲージ |
ovms_infer_req_active |
名前、バージョン |
処理キューから消費されて、データのロードまたは推論プロセスのいずれかにある推論要求の数。 |
注:
ovms_current_requestsとovms_infer_req_activeはどちらも要求の処理にどれだけのリソースが費やされているか示しますが、これらは全く異なります。要求は、サーバーによって受信されるとすぐにovms_current_requestsメトリックでカウントされ、応答がユーザーに返されるまで残ります。ovms_infer_req_activeカウンターは、ユーザー要求にバインドされており、データをロードしているか、すでに推論を実行している OpenVINO 推論要求の数を示します。
ラベルの説明
名前 |
値 |
説明 |
|---|---|---|
api |
KServe、TensorFlowServing |
サービス API の名前。 |
インターフェイス |
REST、gRPC |
サービス・インターフェイスの名前。 |
メソッド |
ModelMetadata、ModelReady、ModelInfer、Predict、GetModelStatus、GetModelMetadata |
インターフェイス・メソッド。 |
バージョン |
1、2、…、n |
モデルバージョン。GetModelStatus と ModelReady にはバージョンラベルがないことに注意してください。 |
名前 |
モデルサーバー構成の定義を継承 |
モデル名または DAG 名。 |
メトリックを有効にする#
デフォルトでは、メトリック機能は無効になっています。
メトリック・エンドポイントは、モデルの照会を行うため REST インターフェイスと同じポートを使用します。
-rest_port パラメーターを設定して、モデルサーバーで REST を有効にする必要があります。
デフォルトのメトリックセットを有効にするには、metrics_enable フラグまたは json 設定を指定する必要があります。
オプション 1: CLI#
wget -N https://storage.openvinotoolkit.org/repositories/open_model_zoo/2022.1/models_bin/2/resnet50-binary-0001/FP32-INT1/resnet50-binary-0001.{xml,bin} -P models/resnet50/1
docker run -d -u $(id -u) -v $(pwd)/models:/models -p 9000:9000 -p 8000:8000 openvino/model_server:latest \
--model_name resnet --model_path /models/resnet50 --port 9000 \
--rest_port 8000 \
--metrics_enableオプション 2: 設定ファイル#
mkdir workspace
wget -N https://storage.openvinotoolkit.org/repositories/open_model_zoo/2022.1/models_bin/2/resnet50-binary-0001/FP32-INT1/resnet50-binary-0001.{xml,bin} -P workspace/models/resnet50/1
echo '{
"model_config_list": [
{
"config": {
"name": "resnet",
"base_path": "/workspace/models/resnet50"
}
}
],
"monitoring":
{
"metrics":
{
"enable" : true
}
}
}' >> workspace/config.json設定ファイルから始める#
docker run -d -u $(id -u) -v ${PWD}/workspace:/workspace -p 9000:9000 -p 8000:8000 openvino/model_server:latest \
--config_path /workspace/config.json \
--port 9000 --rest_port 8000メトリックのデフォルトリストを変更#
使用可能なメトリックを 1 つから最大すべてまで一度に有効にすることができます。
特定のメトリックのセットを有効にするには、metrics_list フラグまたは json 設定を指定します:
オプション 1: CLI#
wget -N https://storage.openvinotoolkit.org/repositories/open_model_zoo/2022.1/models_bin/2/resnet50-binary-0001/FP32-INT1/resnet50-binary-0001.{xml,bin} -P models/resnet50/1
docker run -d -u $(id -u) -v $(pwd)/models:/models -p 9000:9000 -p 8000:8000 openvino/model_server:latest \
--model_name resnet --model_path /models/resnet50 --port 9000 \
--rest_port 8000 \
--metrics_enable \
--metrics_list ovms_requests_success,ovms_infer_req_queue_sizeオプション 2: 設定ファイル#
wget -N https://storage.openvinotoolkit.org/repositories/open_model_zoo/2022.1/models_bin/2/resnet50-binary-0001/FP32-INT1/resnet50-binary-0001.{xml,bin} -P models/resnet50/1
echo '{
"model_config_list": [
{
"config": {
"name": "resnet",
"base_path": "/workspace/models/resnet50"
}
}
],
"monitoring":
{
"metrics":
{
"enable" : true,
"metrics_list": ["ovms_requests_success", "ovms_infer_req_queue_size"]
}
}
}' > workspace/config.json設定ファイルから始める#
docker run -d -u $(id -u) -v ${PWD}/workspace:/workspace -p 9000:9000 -p 8000:8000 openvino/model_server:latest \
--config_path /workspace/config.json \
--port 9000 --rest_port 8000すべてのメトリックが有効な構成ファイル#
echo '{
"model_config_list": [
{
"config": {
"name": "resnet",
"base_path": "/workspace/models/resnet50"
}
}
],
"monitoring":
{
"metrics":
{
"enable" : true,
"metrics_list":
[ "ovms_requests_success",
"ovms_requests_fail",
"ovms_inference_time_us",
"ovms_wait_for_infer_req_time_us",
"ovms_request_time_us",
"ovms_current_requests",
"ovms_infer_req_active",
"ovms_streams",
"ovms_infer_req_queue_size"]
}
}
}' > workspace/config.json上記の設定ファイルから始める#
docker run -d -u $(id -u) -v ${PWD}/workspace:/workspace -p 9000:9000 -p 8000:8000 openvino/model_server:latest \
--config_path /workspace/config.json \
--port 9000 --rest_port 8000メトリック・エンドポイントからの応答の例#
メトリック・エンドポイントのデータを使用するには、curl コマンドを使用できます:
curl http://localhost:8000/metricsパフォーマンスに関する考察#
メトリックの収集は、平均的なサイズと複雑なモデルで使用する場合、パフォーマンスのオーバーヘッドは無視できます。ただし、推論時間が短い軽量で高速なモデルで使用すると、メトリックの増加が処理時間のかなりの部分を占める可能性があります。このようなモデルのメトリックを有効にするには、それを考慮してください。
DAG パイプラインのメトリック実装#
DAG パイプラインの実行には、以下にリストする 3 つの関連メトリックがあります。これらはパイプライン全体の実行を追跡し、すべてのパイプライン・ノードから情報を収集します。
DAG メトリック
タイプ |
名前 |
説明 |
|---|---|---|
カウンター |
ovms_requests_success |
モデルまたは DAG への成功した要求の数。 |
カウンター |
ovms_requests_fail |
モデルまたは DAG への失敗した要求の数。 |
ヒストグラム |
ovms_request_time_us |
モデルまたは DAG への要求の処理時間。 |
残りのメトリックは、パイプライン内の個々のモデルの実行を個別に追跡します。これは、DAG パイプラインへの各要求により、実行ノードとして使用されるすべての個々のモデルのメトリックも更新されることを意味します。
MediaPipe グラフのメトリック実装#
MediaPipe グラフ のメトリック・エンドポイントはサポートされていません。
Grafana で視覚化#
Prometheus によってサーバーメトリックが収集されるため、Grafana を統合してダッシュボードでそれらを視覚化できます。データソースとして Prometheus を使用して Grafana を構成したら、独自のダッシュボードを作成するか、ダッシュボードをインポートできます。
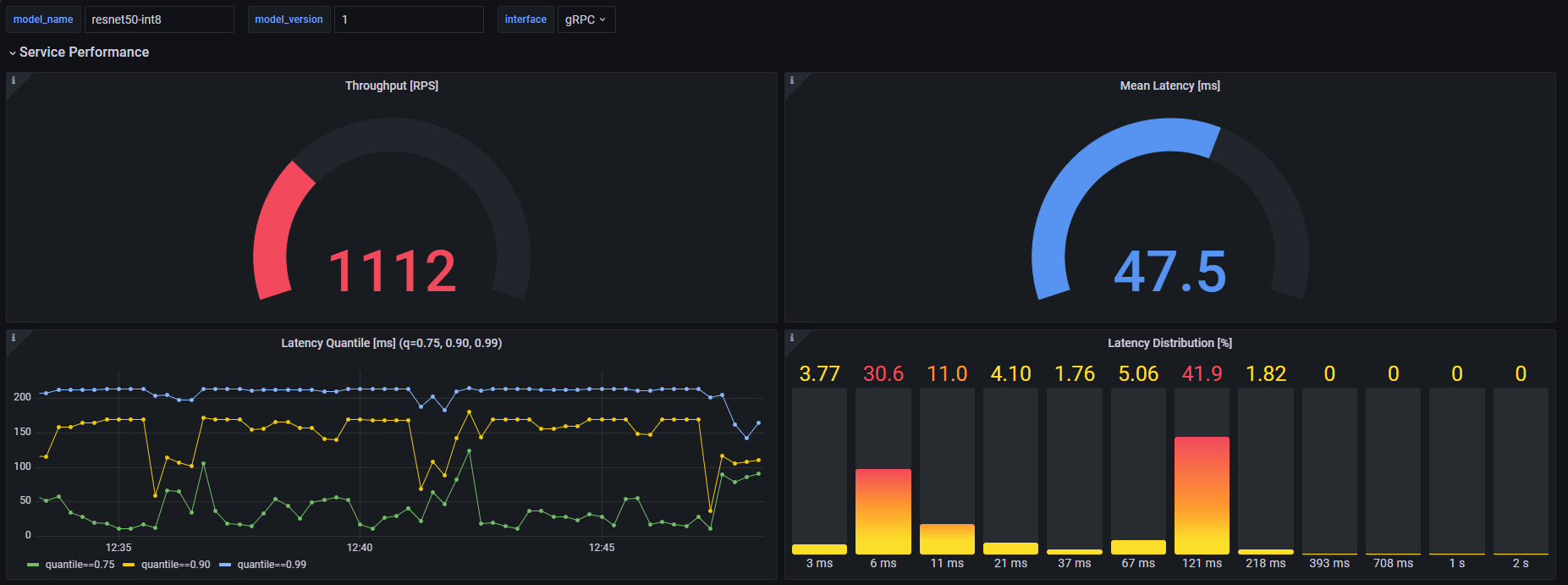
OpenVINO モデルサーバーのリポジトリーには、次のようなモデルごとのメトリックの視覚化に使用できる grafana_dashboard.json ファイルがあります。
スループット [RPS] - モデルによって 1 秒あたりに処理される要求の数。
平均レイテンシー [ミリ秒] - 特定の時間枠内にモデルによって処理されたすべての要求の平均レイテンシー。
レイテンシー分位数 [ミリ秒] - 分位数のレイテンシーの値 [0.75、0.90、0.99]。要求の 75%、90%、および 99% が超過していないレイテンシーを意味します。
レイテンシー分布 [%] - バケット全体のレイテンシーの分布。
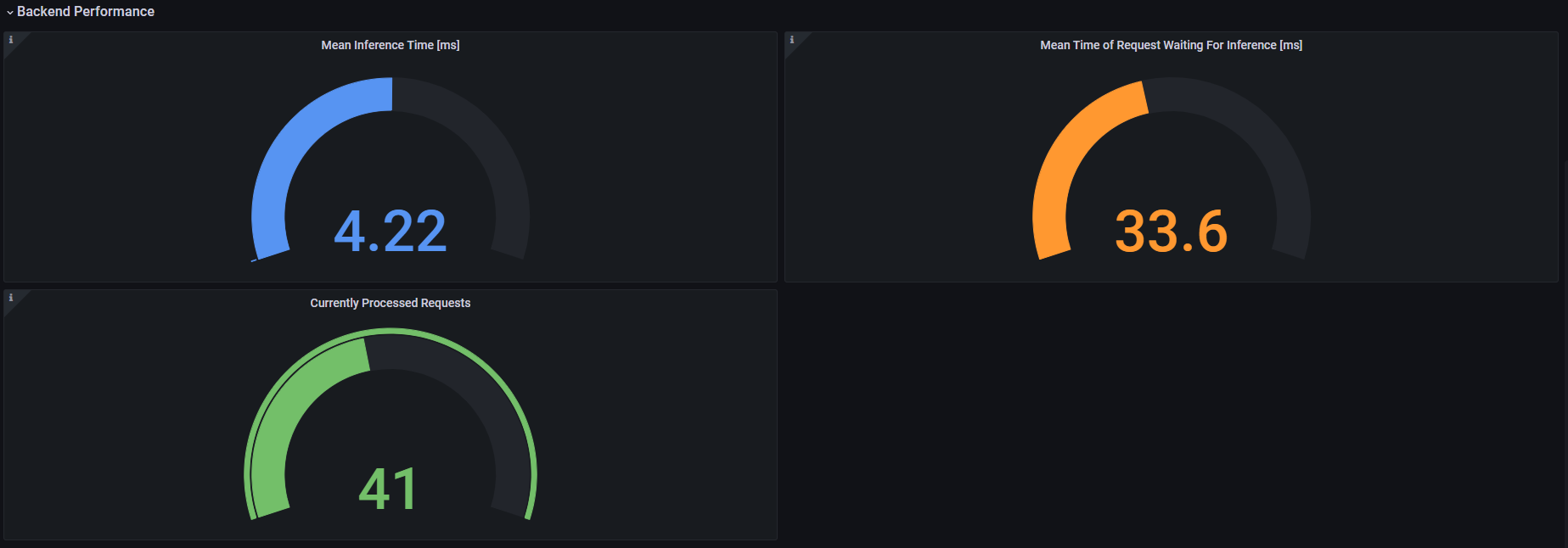
平均推論時間 [ミリ秒] - 特定の時間枠内にモデルによって処理されたすべての要求の平均化された推論実行時間。
推論を待機する要求の平均時間 [ミリ秒] - 推論の実行を待機する要求の時間。特定の時間枠内でモデルによって処理されたすべての要求の平均です。
現在処理されている要求 - モデルサーバーによって現在処理されている要求の数。
ダッシュボードは、対象のモデル・インスタンスとインターフェイス (gRPC または REST) を決定する、model_name、model_version および interface の 3 つの変数を使用して機能します。平均推論時間、平均推論待機時間、現在処理されている要求のパネルでは、バックエンドのパフォーマンスのみに関係してインターフェイスに依存しないため、interface 値は無視されます。