BLIP と OpenVINO を使用した視覚的な質疑応答と画像キャプション¶
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

人間は視覚と言語を通じて世界を認識します。AI の長年の目標は、視覚と言語入力を通じて世界を理解し、自然言語を通じて人間と対話できる知的なエージェントを構築することです。この目標を達成するため、視覚言語事前トレーニングが効果的なアプローチとして登場しました。これは、大規模な画像テキスト・データセットでディープ・ニューラル・ネットワーク・モデルを事前トレーニングし、画像テキスト検索、画像キャプション作成、視覚的な質問への回答などの下流の視覚言語タスクのパフォーマンスを向上させるものです。
BLIP は、統合された視覚と言語の理解と生成のための言語と画像の事前トレーニング・フレームワークです。BLIP は、幅広い視覚言語タスクで最先端の結果を実現します。このチュートリアルでは、視覚的な質問回答と画像キャプションの作成に BLIP を使用する方法を説明します。
チュートリアルは以下で構成されています。
BLIP モデルをインスタンス化します。
BLIP モデルを OpenVINO IR に変換します。
OpenVINO を使用して、視覚的な質疑応答と画像キャプションを実行します。
目次¶
背景¶
視覚言語処理は、コンピューターが画像とその内容をより正確に理解できるように設計されたアルゴリズムに重点を置いた人工知能の分野です。
次のタスクが良く利用されます。
テキストからの画像検索 - 与えられたテキストの説明に最も関連性の高い画像を見つけることを目的としたセマンティック・タスク。
画像キャプション - 画像コンテンツにテキストによる説明を提供することを目的としたセマンティック・タスク。
視覚的な質問回答 - 画像コンテンツに基づいて質問に答えることを目的としたセマンティック・タスク。
下の図に示すように、これら 3 つのタスクは AI システムに提供される入力が異なります。テキストから画像への検索では、検索用に事前定義された画像ギャラリーと、ユーザーが要求したテキストの記述 (クエリー) があります。画像キャプションは、視覚的な質問応答の特殊なケースとして表すことができます。ここでは、“画像には何がありますか?” という事前定義された質問と、ユーザーが提供するさまざまな画像があります。視覚的な質問応答の場合、テキストベースの質問と画像のコンテキストの両方がユーザーによって要求される変数です。

このノートブックはテキストから画像への検索に焦点を当てていません。代わりに、画像キャプションと視覚的な質問回答を考慮します。
画像のキャプション¶
画像キャプションとは、画像の内容を言葉で説明する作業です。このタスクは、コンピューター・ビジョンと自然言語処理の交差点にあります。ほとんどの画像キャプション・システムでは、エンコーダー/デコーダー・フレームワークが使用されています。このフレームワークでは、入力画像が画像内の情報の中間表現にエンコードされ、その後、説明的なテキストシーケンスにデコードされます。
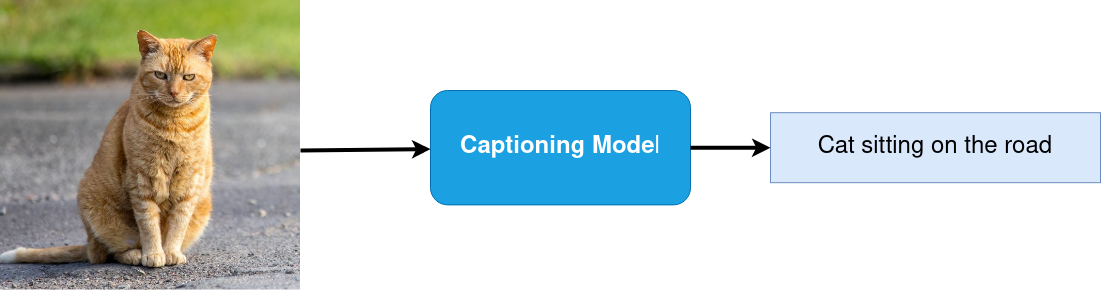
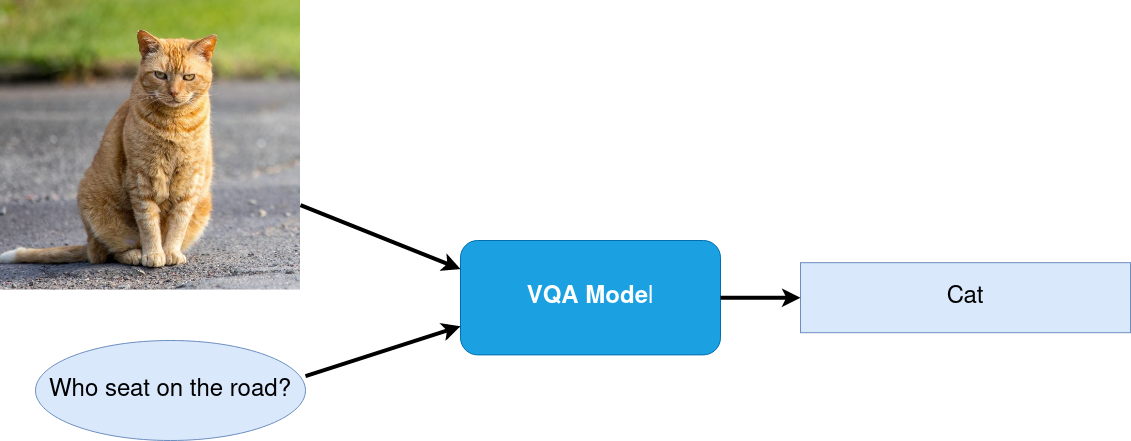
視覚的な質問への回答¶
Visual Question Answering (VQA) は、画像コンテンツに関するテキストベースの質問に答えるタスクです。
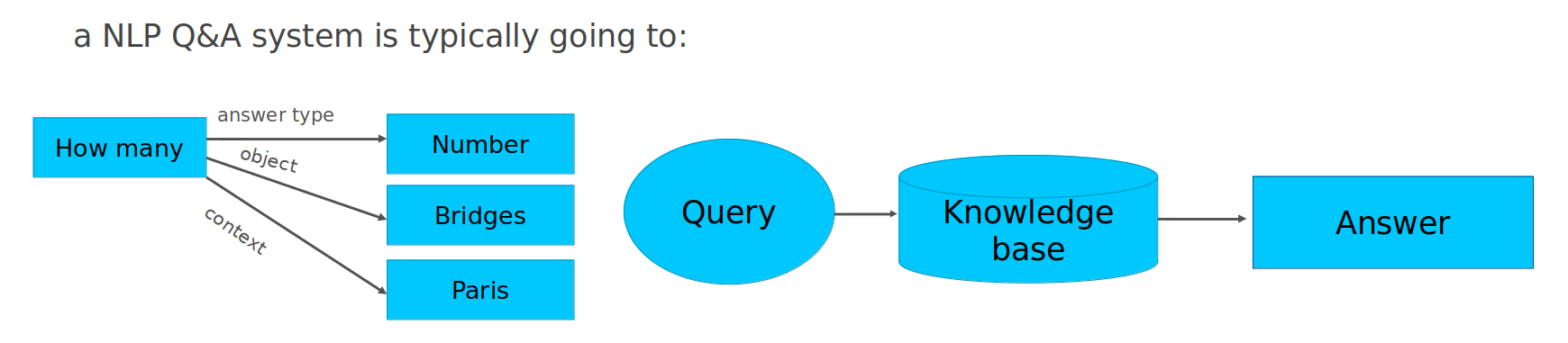
VQA の仕組みをより理解するために、与えられたテキスト入力から質問に対する回答を取得することを目的とする、質問応答などの従来の NLP タスクを考えてみましょう。通常、質問応答パイプラインは次の 3 つのステップで構成されます。

-
質問分析 - 質問内のオブジェクトと追加のコンテキストを理解するため、自然言語形式で提供された質問を分析します。例えば、“パリには橋がいくつありますか?” という質問の場合、“いくつ” という疑問語は答えが数字である可能性が高いというヒントを与え、“橋” は質問の対象オブジェクトであり、”パリには” は検索の追加コンテキストとして機能します。
検索用のクエリーを構築します - 分析された結果を使用して、最も関連性の高い情報を見つけるためのクエリーを形式化します。
ナレッジベースで検索を実行します。クエリーをナレッジベースに送信します。通常、テキスト・ドキュメントまたはデータベースが知識のソースとして提供されます。
テキストベースの質問応答とビジュアル質問応答の違いは、画像がコンテキストと知識ベースとして使用されることです。
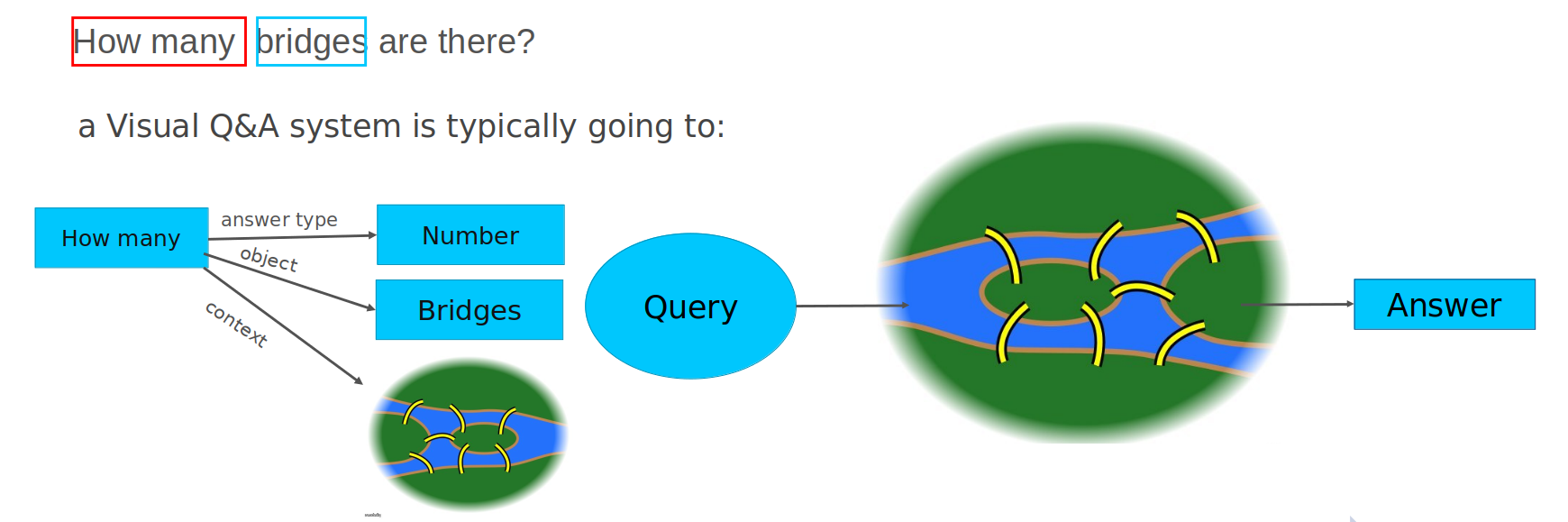
画像に関する任意の質問に答えることは、多くのコンピューター・ビジョンのサブタスクを必要とするため、複雑な問題です。以下の表に、質問の例と、回答を見つけるために必要なコンピューター・ビジョンのスキルを示します。
コンピューター・ビジョン・タスク |
質問例 |
|---|---|
物体認識 |
写真に何が写っていますか? それは何ですか? |
物体検出 |
画像内に何か物体 (犬、男性、本) はありますか? どこに位置していますか? |
物体と画像の属性認識 |
傘は何色ですか? この男性は眼鏡をかけていますか? 画像に色はありますか? |
シーン認識 |
雨ですか? 描かれているのはどんなお祝いですか? |
物体カウント |
サッカー場には何人の選手がいますか? 階段は何段ありますか? |
アクティビティー認識 |
赤ちゃんは泣いていますか? その女性は何を料理していますか? 彼らは何をしていますか? |
物体間の空間関係 |
ソファとアームチェアの間には何がありますか? 左下隅には何がありますか? |
常識的な推論 |
彼女の視力は100%ですか? この人には子供がいますか? |
知識ベースの推論 |
ベジタリアン向けのピザですか? |
テキスト認識 |
その本のタイトルは何ですか? 画面には何が映っていますか? |
視覚的な質問回答には多くのアプリケーションがあります。
視覚障害者の支援: VQA モデルは、視覚障害者がウェブや現実世界から画像に関する情報を取得できるようにすることで、視覚障害者の障壁を軽減するのに使用できます。
教育: VQA モデルを使用すると、観察者が興味のある質問を直接できるようにすることで博物館での訪問者の体験を向上させたり、特定の知識を習得することに興味のある子供たちのために教科書の対話性を高めたりすることができます。
E コマース: VQA モデルは、オンラインストアの写真を使用して製品に関する情報を取得できます。
独立した専門家による評価: VQA モデルは、スポーツ競技、医療診断、法医学的検査において客観的な評価を提供できます。
モデルのインスタンス化¶
BLIP モデルは、BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation という論文で提案されました。

blip.gif¶
理解と生成の両方の機能を備えた統合視覚言語モデルを事前トレーニングするため、BLIP は、次の 3 つのモードのいずれかで動作できるエンコーダーとデコーダーのマルチモーダル混合とマルチタスク・モデルを導入します。
画像とテキストを別々にエンコードするユニモーダル・エンコーダー。画像エンコーダーはビジョン・トランスフォーマーです。テキスト・エンコーダーは BERT と同じです。
Image-grounded テキスト・エンコーダーは、テキスト・エンコーダーの各トランスフォーマー・ブロックの自己注意層とフィードフォワード・ネットワークの間にクロス注意レイヤーを挿入することで視覚情報を注入します。
Image-grounded テキスト・デコーダーは、テキスト・エンコーダーの双方向自己注意レイヤーを因果自己注意レイヤーに置き換えます。
モデルの詳細については、研究論文、Salesforce ブログ、GitHub リポジトリー、Hugging Face モデルのドキュメントをご覧ください。
このチュートリアルでは、Hugging Face からダウンロードできる blip-vqa-base モデルを使用します。同じアクションは、BLIP ファミリーの他の同様なモデルにも適用できます。このモデルクラスは質問への回答を実行するように設計されていますが、そのコンポーネントは画像のキャプション作成にも再利用できます。
モデルの操作を開始するには、from_pretrained メソッドを使用して BlipForQuestionAnswering クラスをインスタンス化する必要があります。BlipProcessor は、テキストとビジョンの両方のモダリティーの入力データを準備し、生成結果を後処理するためのヘルパークラスです。
%pip install -q --extra-index-url https://download.pytorch.org/whl/cpu torch torchvision "transformers>=4.26.0" gradio "openvino>=2023.1.0" matplotlib
import sys
import time
from PIL import Image
from transformers import BlipProcessor, BlipForQuestionAnswering
sys.path.append("../utils")
from notebook_utils import download_file
# get model and processor
processor = BlipProcessor.from_pretrained("Salesforce/blip-vqa-base")
model = BlipForQuestionAnswering.from_pretrained("Salesforce/blip-vqa-base")
# setup test input: download and read image, prepare question
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
download_file(img_url, "demo.jpg")
raw_image = Image.open("demo.jpg").convert('RGB')
question = "how many dogs are in the picture?"
# preprocess input data
inputs = processor(raw_image, question, return_tensors="pt")
start = time.perf_counter()
# perform generation
out = model.generate(**inputs)
end = time.perf_counter() - start
# postprocess result
answer = processor.decode(out[0], skip_special_tokens=True)
2023-10-27 13:39:08.110243: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0. 2023-10-27 13:39:08.267533: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags. 2023-10-27 13:39:09.184395: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT /home/ea/work/ov_venv/lib/python3.8/site-packages/torch/cuda/__init__.py:138: UserWarning: CUDA initialization: The NVIDIA driver on your system is too old (found version 11080). Please update your GPU driver by downloading and installing a new version from the URL: http://www.nvidia.com/Download/index.aspx Alternatively, go to: https://pytorch.org to install a PyTorch version that has been compiled with your version of the CUDA driver. (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:108.) return torch._C._cuda_getDeviceCount() > 0
'demo.jpg' already exists.
/home/ea/work/ov_venv/lib/python3.8/site-packages/transformers/generation/utils.py:1260: UserWarning: Using the model-agnostic default max_length (=20) to control the generation length. We recommend setting max_new_tokens to control the maximum length of the generation. warnings.warn(
print(f"Processing time: {end:.4f} s")
Processing time: 0.5272 s
from utils import visualize_results
fig = visualize_results(raw_image, answer, question)

モデルを OpenVINO IR に変換¶
OpenVINO 2023.0 リリース以降、OpenVINO は、高度な OpenVINO 最適化ツールと機能を活用できるように、PyTorch モデルを OpenVINO 中間表現 (IR) 形式に直接変換することをサポートしています。OpenVINO モデル変換 API にモデル・オブジェクトとモデルトレースの入力データを提供する必要があります。ov.convert_model 関数は、PyTorch モデル・インスタンスを、デバイス上でコンパイルするために使用したり、ov.save_model を使用して FP16 形式に圧縮してディスクに保存できる ov.Model オブジェクトに変換します。
モデルは 3 つのパーツで構成されます。
vision_model - 画像表現用のエンコーダー。
text_encoder - 入力クエリ用のエンコーダー。質問への回答とテキストから画像への検索にのみ使用されます。
text_decoder - 出力回答用のデコーダー。
同じモデル・コンポーネントを使用して複数のタスクを実行できるようにするには、各パーツを個別に変換する必要があります。
ビジョンモデル¶
ビジョンモデルは、[0,1] の範囲で正規化された RGB 画像ピクセル値を含む、[1,3,384,384] 形状の浮動小数点入力テンソルを受け入れます。
import torch
from pathlib import Path
import openvino as ov
VISION_MODEL_OV = Path("blip_vision_model.xml")
vision_model = model.vision_model
vision_model.eval()
# check that model works and save it outputs for reusage as text encoder input
with torch.no_grad():
vision_outputs = vision_model(inputs["pixel_values"])
# if openvino model does not exist, convert it to IR
if not VISION_MODEL_OV.exists():
# export pytorch model to ov.Model
with torch.no_grad():
ov_vision_model = ov.convert_model(vision_model, example_input=inputs["pixel_values"])
# save model on disk for next usages
ov.save_model(ov_vision_model, VISION_MODEL_OV)
print(f"Vision model successfuly converted and saved to {VISION_MODEL_OV}")
else:
print(f"Vision model will be loaded from {VISION_MODEL_OV}")
Vision model will be loaded from blip_vision_model.xml
テキスト・エンコーダー¶
テキスト・エンコーダーは、視覚的な質問応答タスクによって質問埋め込み表現を構築するために使用されます。トークン化された質問を含む input_ids を受け取り、ビジョンモデルから取得された画像埋め込みとそれらの注意マスクを出力します。
TEXT_ENCODER_OV = Path("blip_text_encoder.xml")
text_encoder = model.text_encoder
text_encoder.eval()
# if openvino model does not exist, convert it to IR
if not TEXT_ENCODER_OV.exists():
# prepare example inputs
image_embeds = vision_outputs[0]
image_attention_mask = torch.ones(image_embeds.size()[:-1], dtype=torch.long)
input_dict = {"input_ids": inputs["input_ids"], "attention_mask": inputs["attention_mask"], "encoder_hidden_states": image_embeds, "encoder_attention_mask": image_attention_mask}
# export PyTorch model
with torch.no_grad():
ov_text_encoder = ov.convert_model(text_encoder, example_input=input_dict)
# save model on disk for next usages
ov.save_model(ov_text_encoder, TEXT_ENCODER_OV)
print(f"Text encoder successfuly converted and saved to {TEXT_ENCODER_OV}")
else:
print(f"Text encoder will be loaded from {TEXT_ENCODER_OV}")
Text encoder will be loaded from blip_text_encoder.xml
テキストデコーダー¶
テキストデコーダーは、画像 (および必要に応じて質問) 表現を使用して、モデル出力 (質問への回答またはキャプション) を表すトークンのシーケンスを生成する役割を担います。生成アプローチは、単語シーケンスの確率分布を条件付きの次の単語分布の積に分解できるという仮定に基づいています。言い換えると、モデルは、停止条件 (最大長の生成されたシーケンスまたは文字列トークンの終了が取得される) に達するまで、以前に生成されたトークンに基づいてループ内の次のトークンを予測します。予測される確率に基づいて次のトークンが選択される方法は、選択されたデコード方法によって決まります。最も一般的なデコード方法の詳細については、このブログをご覧ください。Hugging Face Transformers ライブラリーのモデル生成プロセスのエントリー・ポイントは、generate メソッドです。パラメーターと構成の詳細については、ドキュメントを参照してください。選択デコード方法論の柔軟性を維持するため、1 つのステップでモデル推論のみを変換します。
生成プロセスを最適化し、メモリーをより効率的に使用するには、use_cache=True オプションを有効にします。出力側は自動回帰であるため、出力トークンの非表示状態は、その後の生成ステップごとに計算されると同じままになります。したがって、新しいトークンを生成するたびに再計算するのは無駄であるように思えます。キャッシュを使用すると、モデルは計算後に非表示の状態を保存します。モデルは各タイムステップで最後に生成された出力トークンのみを計算し、保存された出力トークンを非表示のトークンに再利用します。これにより、変圧器モデルの生成の複雑さが O(n^3) から O(n^2) に軽減されます。仕組みの詳細については、この記事を参照してください。このオプションを使用すると、モデルは前のステップの非表示状態を入力として取得し、さらに現在のステップの非表示状態を出力として提供します。最初は、前のステップの隠し状態がないため、最初のステップでは隠し状態を提供する必要はありませんが、デフォルト値で初期化する必要があります。PyTorch では、過去の隠し状態の出力は、モデル内の各トランスフォーマー・レイヤーのペアのリスト (キーの隠し状態、値の隠し状態) として表現されます。OpenVINO モデルはネストされた出力をサポートしていないため、出力はフラット化されます。
text_encoder と同様に、text_decoder はさまざまな長さの入力シーケンスを処理でき、動的な入力形状を保持する必要があります。
text_decoder = model.text_decoder
text_decoder.eval()
TEXT_DECODER_OV = Path("blip_text_decoder_with_past.xml")
# prepare example inputs
input_ids = torch.tensor([[30522]]) # begin of sequence token id
attention_mask = torch.tensor([[1]]) # attention mask for input_ids
encoder_hidden_states = torch.rand((1, 10, 768)) # encoder last hidden state from text_encoder
encoder_attention_mask = torch.ones((1, 10), dtype=torch.long) # attention mask for encoder hidden states
input_dict = {"input_ids": input_ids, "attention_mask": attention_mask, "encoder_hidden_states": encoder_hidden_states, "encoder_attention_mask": encoder_attention_mask}
text_decoder_outs = text_decoder(**input_dict)
# extend input dictionary with hidden states from previous step
input_dict["past_key_values"] = text_decoder_outs["past_key_values"]
text_decoder.config.torchscript = True
if not TEXT_DECODER_OV.exists():
# export PyTorch model
with torch.no_grad():
ov_text_decoder = ov.convert_model(text_decoder, example_input=input_dict)
# save model on disk for next usages
ov.save_model(ov_text_decoder, TEXT_DECODER_OV)
print(f"Text decoder successfuly converted and saved to {TEXT_DECODER_OV}")
else:
print(f"Text decoder will be loaded from {TEXT_DECODER_OV}")
Text decoder will be loaded from blip_text_decoder_with_past.xml
OpenVINO モデルの実行¶
推論パイプラインの準備¶
前述したように、このモデルは、さまざまなタスクのパイプラインを構築するのに再利用できる複数のブロックで構成されています。下の図で、画像キャプションの仕組みが分かります。
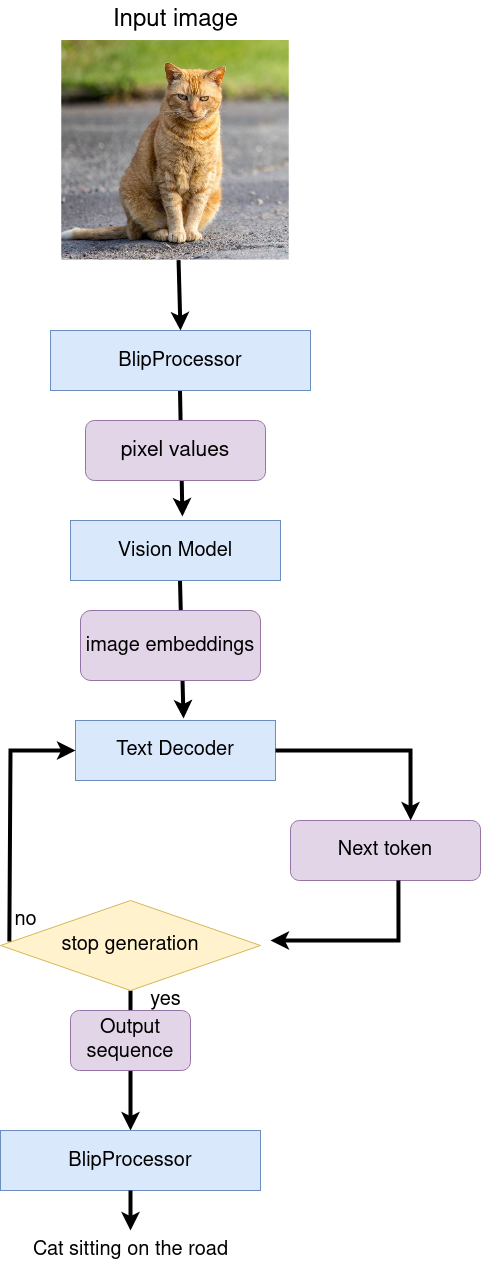
ビジュアルモデルは、BlipProcessor によって前処理された画像を入力として受け入れ、画像埋め込みを生成します。この画像埋め込みは、キャプション・トークンを生成するためテキストデコーダーに直接渡されます。生成が完了すると、トークンの出力シーケンスが BlipProcessor に提供され、トークナイザーを使用してテキストにデコードされます。
質疑応答のパイプラインは似ていますが、質問処理が追加されています。この場合、BlipProcessor によってトークン化された画像埋め込みと質問がテキスト・エンコーダーに提供され、次にマルチモーダル質問埋め込みがテキストデコーダーに渡されて回答の生成が行われます。
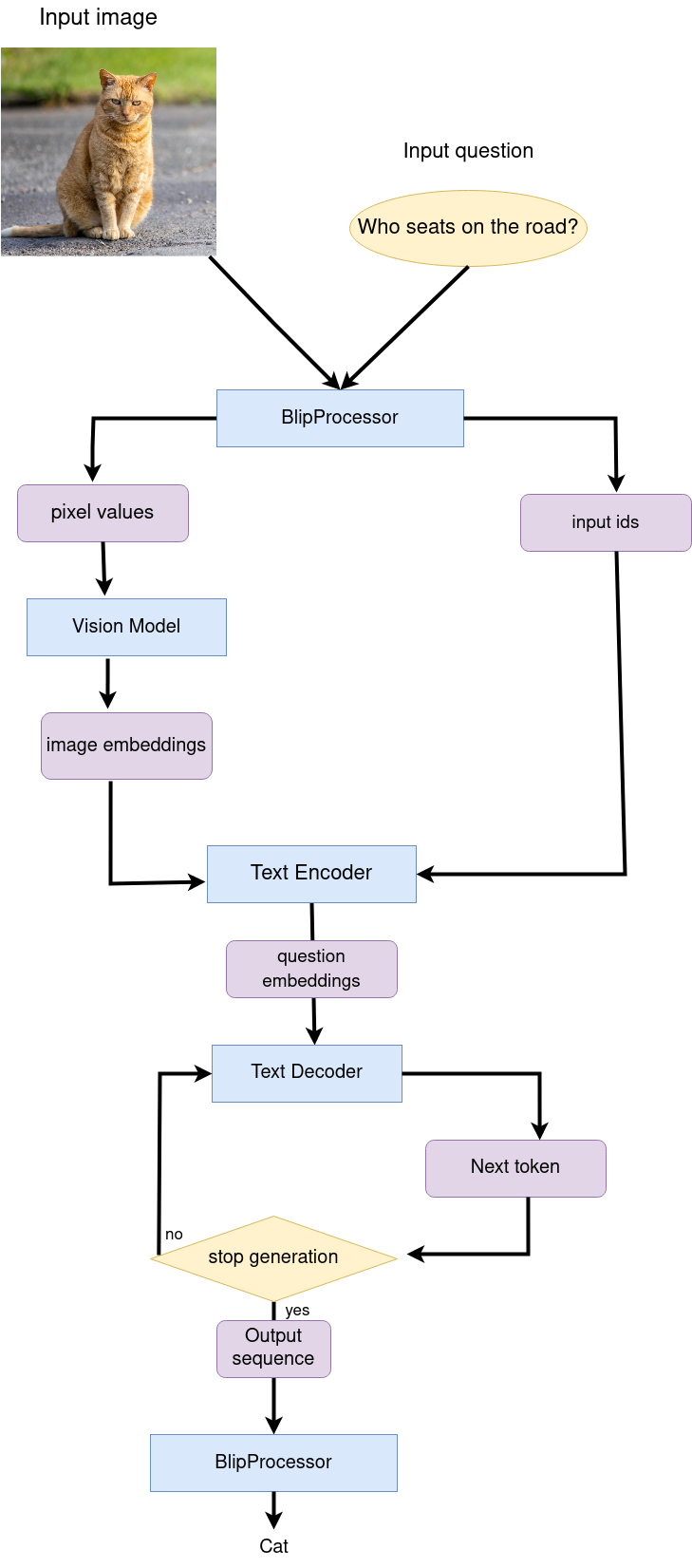
次のステップは、OpenVINO モデルを使用して両方のパイプラインを実装することです。
# create OpenVINO Core object instance
core = ov.Core()
推論デバイスの選択¶
OpenVINO を使用して推論を実行するためにドロップダウン・リストからデバイスを選択します。
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='AUTO',
description='Device:',
disabled=False,
)
device
Dropdown(description='Device:', index=2, options=('CPU', 'GPU', 'AUTO'), value='AUTO')
# load models on device
ov_vision_model = core.compile_model(VISION_MODEL_OV, device.value)
ov_text_encoder = core.compile_model(TEXT_ENCODER_OV, device.value)
ov_text_decoder_with_past = core.compile_model(TEXT_DECODER_OV, device.value)
from functools import partial
from blip_model import text_decoder_forward
text_decoder.forward = partial(text_decoder_forward, ov_text_decoder_with_past=ov_text_decoder_with_past)
モデルのヘルパークラスには、生成用の 2 つのメソッドがあります。
- generate_answer - 視覚的な質問回答に使用。
- generate_caption - キャプション生成に使用。初期化では、モデルクラスは、テキスト・エンコーダー、ビジョンモデル、テキストデコーダー用のコンパイル済み OpenVINO モデルを受け入れ、デコーダー作業用の生成および初期トークンの構成も受け入れます。
from blip_model import OVBlipModel
ov_model = OVBlipModel(model.config, model.decoder_start_token_id, ov_vision_model, ov_text_encoder, text_decoder)
out = ov_model.generate_answer(**inputs, max_length=20)
これで、モデルを生成する準備が整いました。
画像のキャプション¶
out = ov_model.generate_caption(inputs["pixel_values"], max_length=20)
caption = processor.decode(out[0], skip_special_tokens=True)
fig = visualize_results(raw_image, caption)

質問への回答¶
start = time.perf_counter()
out = ov_model.generate_answer(**inputs, max_length=20)
end = time.perf_counter() - start
answer = processor.decode(out[0], skip_special_tokens=True)
fig = visualize_results(raw_image, answer, question)

print(f"Processing time: {end:.4f}")
Processing time: 0.1617
インタラクティブなデモ¶
import gradio as gr
def generate_answer(img, question):
if img is None:
raise gr.Error("Please upload an image or choose one from the examples list")
start = time.perf_counter()
inputs = processor(img, question, return_tensors="pt")
output = (
ov_model.generate_answer(**inputs, max_length=20)
if len(question)
else ov_model.generate_caption(inputs["pixel_values"], max_length=20)
)
answer = processor.decode(output[0], skip_special_tokens=True)
elapsed = time.perf_counter() - start
html = f"<p>Processing time: {elapsed:.4f}</p>"
return answer, html
demo = gr.Interface(
generate_answer,
[
gr.Image(label="Image"),
gr.Textbox(
label="Question",
info="If this field is empty, an image caption will be generated",
),
],
[gr.Text(label="Answer"), gr.HTML()],
examples=[["demo.jpg", ""], ["demo.jpg", question]],
allow_flagging="never"
)
try:
demo.launch(debug=False)
except Exception:
demo.launch(share=True, debug=False)
# if you are launching remotely, specify server_name and server_port
# demo.launch(server_name='your server name', server_port='server port in int')
# Read more in the docs: https://gradio.app/docs/
次のステップ¶
233-blip-optimize ノートブックを開き、NNCF のトレーニング後量子化 API を使用してビジョンおよびテキスト・エンコーダー・モデルを量子化し、テキスト・デコーダーの重みを圧縮します。次に、変換および最適化された OpenVINO モデルを比較します。