Whisper と OpenVINO™ を使用したビデオ字幕の生成¶
この Jupyter ノートブックはオンラインで起動でき、ブラウザーのウィンドウで対話型環境を開きます。ローカルにインストールすることもできます。次のオプションのいずれかを選択します。


Whisper は、ウェブから収集された 680,000 時間の多言語およびマルチタスクの監視データに基づいてトレーニングされた自動音声認識 (ASR) システムです。多言語音声認識に加え、音声翻訳や言語識別も実行できるマルチタスク・モデルです。

asr-training-data-desktop.svg¶
このモデルの詳細については、研究論文、OpenAI ブログ、モデルカード、GitHub リポジトリーをご覧ください。
このノートブックでは、Whisper と OpenVINO を使用して、サンプルビデオの字幕を生成します。これには次の手順が含まれます。
モデルをダウンロードします。
PyTorch モデル・パイプラインをインスタンス化します。
モデル変換 API を使用して、モデルを OpenVINO IR に変換します。
OpenVINO モデルを使用して Whisper パイプラインを実行します。
目次¶
必要条件¶
依存関係をインストールします。
%pip install -q "openvino>=2023.1.0"
%pip install -q "python-ffmpeg<=1.0.16" moviepy transformers --extra-index-url https://download.pytorch.org/whl/cpu
%pip install -q "git+https://github.com/garywu007/pytube.git"
%pip install -q gradio
%pip install -q "openai-whisper==20231117" --extra-index-url https://download.pytorch.org/whl/cpu
モデルのインスタンス化¶
Whisper は、トランスフォーマー・ベースのエンコーダー/デコーダーモデルであり、シーケンスツーシーケンス・モデルとも呼ばれます。オーディオ・スペクトログラム機能のシーケンスをテキストトークンのシーケンスにマッピングします。まず、生のオーディオ入力は、特徴抽出器の動作によって log-Mel スペクトログラムに変換されます。次に、トランスフォーマー・エンコーダーはスペクトログラムをエンコードして、エンコーダーの隠し状態のシーケンスを形成します。最後に、デコーダーは、以前のトークンとエンコーダーの隠れ状態の両方を条件として、テキストトークンを自己回帰的に予測します。
下の図でモデルのアーキテクチャーを確認できます。

whisper_architecture.svg¶
モデルの作成者によってトレーニングされた、さまざまなサイズと機能のモデルがあります。このチュートリアルでは base モデルを使用しますが、同じアクションは Whisper ファミリーの他のモデルにも適用できます。
from whisper import _MODELS
import ipywidgets as widgets
model_id = widgets.Dropdown(
options=list(_MODELS),
value='large-v2',
description='Model:',
disabled=False,
)
model_id
Dropdown(description='Model:', index=9, options=('tiny.en', 'tiny', 'base.en', 'base', 'small.en', 'small', 'm…
import whisper
model = whisper.load_model(model_id.value, "cpu")
model.eval()
pass
モデルを OpenVINO 中間表現 (IR) 形式に変換¶
OpenVINO で最良の結果を得るには、モデルを OpenVINO IR 形式に変換することを推奨します。形状推論のため、初期化されたモデル・オブジェクトと入力の例を提供する必要があります。モデルを変換するには、ov.convert_model 機能を使用します。ov.convert_model Python 関数は、デバイスにロードして予測を開始する準備が整った OpenVINO モデルを返します。ov.save_model を使用して、次回使用するためディスクに保存できます。
Whisper エンコーダーを OpenVINO IR に変換¶
from pathlib import Path
WHISPER_ENCODER_OV = Path(f"whisper_{model_id.value}_encoder.xml")
WHISPER_DECODER_OV = Path(f"whisper_{model_id.value}_decoder.xml")
import torch
import openvino as ov
mel = torch.zeros((1, 80 if 'v3' not in model_id.value else 128, 3000))
audio_features = model.encoder(mel)
if not WHISPER_ENCODER_OV.exists():
encoder_model = ov.convert_model(model.encoder, example_input=mel)
ov.save_model(encoder_model, WHISPER_ENCODER_OV)
Whisper デコーダーを OpenVINO IR に変換¶
計算の複雑さを軽減するために、デコーダーは前のステップのアテンション・モジュールでキャッシュされたキー/値の投影を使用します。正しくトレースするには、このプロセスを変更する必要があります。
import torch
from typing import Optional, Tuple
from functools import partial
def attention_forward(
attention_module,
x: torch.Tensor,
xa: Optional[torch.Tensor] = None,
mask: Optional[torch.Tensor] = None,
kv_cache: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
):
"""
Override for forward method of decoder attention module with storing cache values explicitly.
Parameters:
attention_module: current attention module
x: input token ids.
xa: input audio features (Optional).
mask: mask for applying attention (Optional).
kv_cache: dictionary with cached key values for attention modules.
idx: idx for search in kv_cache.
Returns:
attention module output tensor
updated kv_cache
"""
q = attention_module.query(x)
if xa is None:
# hooks, if installed (i.e. kv_cache is not None), will prepend the cached kv tensors;
# otherwise, perform key/value projections for self- or cross-attention as usual.
k = attention_module.key(x)
v = attention_module.value(x)
if kv_cache is not None:
k = torch.cat((kv_cache[0], k), dim=1)
v = torch.cat((kv_cache[1], v), dim=1)
kv_cache_new = (k, v)
else:
# for cross-attention, calculate keys and values once and reuse in subsequent calls.
k = attention_module.key(xa)
v = attention_module.value(xa)
kv_cache_new = (None, None)
wv, qk = attention_module.qkv_attention(q, k, v, mask)
return attention_module.out(wv), kv_cache_new
def block_forward(
residual_block,
x: torch.Tensor,
xa: Optional[torch.Tensor] = None,
mask: Optional[torch.Tensor] = None,
kv_cache: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
):
"""
Override for residual block forward method for providing kv_cache to attention module.
Parameters:
residual_block: current residual block.
x: input token_ids.
xa: input audio features (Optional).
mask: attention mask (Optional).
kv_cache: cache for storing attention key values.
Returns:
x: residual block output
kv_cache: updated kv_cache
"""
x0, kv_cache = residual_block.attn(residual_block.attn_ln(
x), mask=mask, kv_cache=kv_cache)
x = x + x0
if residual_block.cross_attn:
x1, _ = residual_block.cross_attn(
residual_block.cross_attn_ln(x), xa)
x = x + x1
x = x + residual_block.mlp(residual_block.mlp_ln(x))
return x, kv_cache
# update forward functions
for idx, block in enumerate(model.decoder.blocks):
block.forward = partial(block_forward, block)
block.attn.forward = partial(attention_forward, block.attn)
if block.cross_attn:
block.cross_attn.forward = partial(attention_forward, block.cross_attn)
def decoder_forward(decoder, x: torch.Tensor, xa: torch.Tensor, kv_cache: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor]]] = None):
"""
Override for decoder forward method.
Parameters:
x: torch.LongTensor, shape = (batch_size, <= n_ctx) the text tokens
xa: torch.Tensor, shape = (batch_size, n_mels, n_audio_ctx)
the encoded audio features to be attended on
kv_cache: Dict[str, torch.Tensor], attention modules hidden states cache from previous steps
"""
if kv_cache is not None:
offset = kv_cache[0][0].shape[1]
else:
offset = 0
kv_cache = [None for _ in range(len(decoder.blocks))]
x = decoder.token_embedding(
x) + decoder.positional_embedding[offset: offset + x.shape[-1]]
x = x.to(xa.dtype)
kv_cache_upd = []
for block, kv_block_cache in zip(decoder.blocks, kv_cache):
x, kv_block_cache_upd = block(x, xa, mask=decoder.mask, kv_cache=kv_block_cache)
kv_cache_upd.append(tuple(kv_block_cache_upd))
x = decoder.ln(x)
logits = (
x @ torch.transpose(decoder.token_embedding.weight.to(x.dtype), 1, 0)).float()
return logits, tuple(kv_cache_upd)
# override decoder forward
model.decoder.forward = partial(decoder_forward, model.decoder)
tokens = torch.ones((5, 3), dtype=torch.int64)
logits, kv_cache = model.decoder(tokens, audio_features, kv_cache=None)
tokens = torch.ones((5, 1), dtype=torch.int64)
if not WHISPER_DECODER_OV.exists():
decoder_model = ov.convert_model(model.decoder, example_input=(tokens, audio_features, kv_cache))
ov.save_model(decoder_model, WHISPER_DECODER_OV)
デコーダーモデルは、エンコーダーの隠れ状態と以前に予測されたシーケンスに基づいて、次のトークンを自己回帰的に予測します。これは、前のステップ (前のステップからのトークンと注目する隠れ状態の入力) に依存する入力の形状が動的であることを意味します。メモリーを効率的に利用するため、動的入力形状の上限を定義します。
推論パイプラインの準備¶
下の画像は、Whisper モデルを使用したビデオの文字起こしパイプラインを示しています。
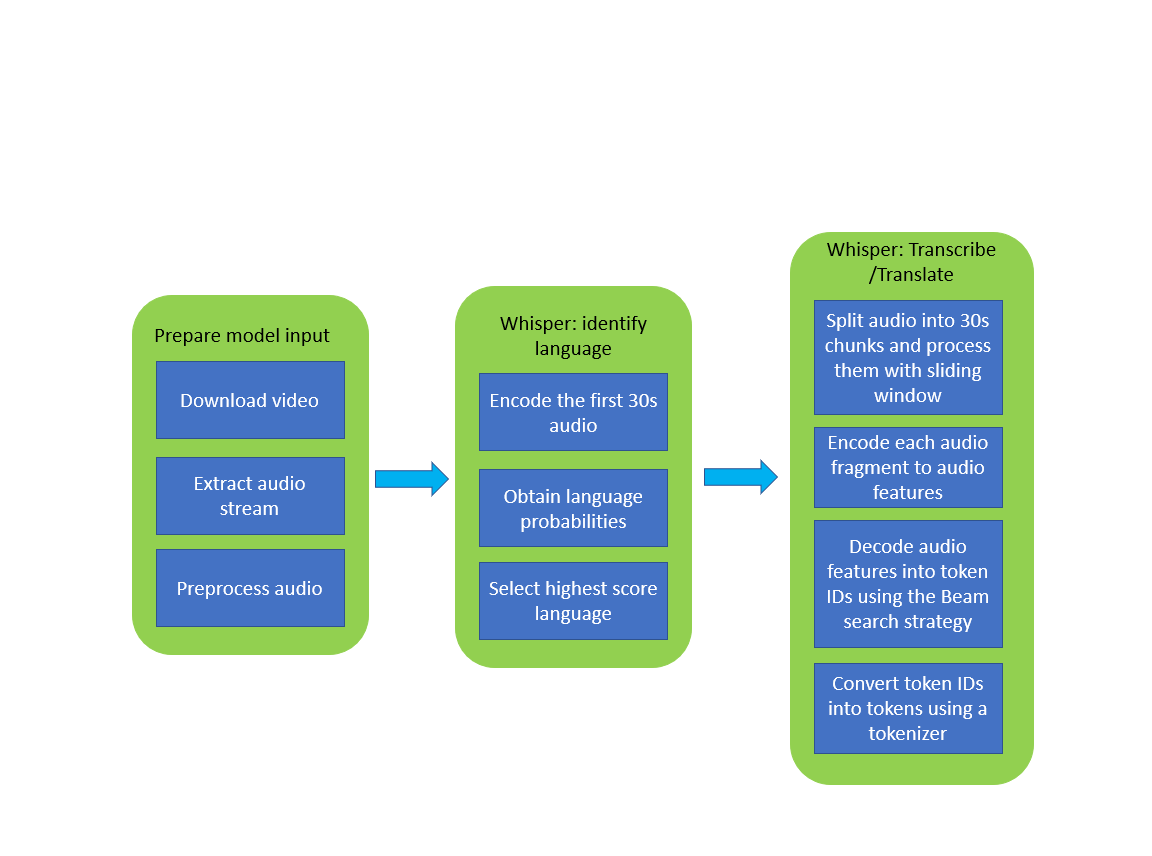
whisper_pipeline.png¶
PyTorch Whisper モデルを実行するには、model.transcribe(audio, **parameters) 関数を呼び出すだけです。元のモデルを OpenVINO IR バージョンに置き換えた後、音声転写に元のモデル・パイプラインを再利用してみます。
### 推論デバイスの選択
OpenVINO を使用して推論を実行するためにドロップダウン・リストからデバイスを選択します。
core = ov.Core()
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='AUTO',
description='Device:',
disabled=False,
)
device
Dropdown(description='Device:', index=2, options=('CPU', 'GPU', 'AUTO'), value='AUTO')
from utils import patch_whisper_for_ov_inference, OpenVINOAudioEncoder, OpenVINOTextDecoder
patch_whisper_for_ov_inference(model)
model.encoder = OpenVINOAudioEncoder(core, WHISPER_ENCODER_OV, device=device.value)
model.decoder = OpenVINOTextDecoder(core, WHISPER_DECODER_OV, device=device.value)
ビデオの文字起こしパイプラインを実行¶
これで、転写を始める準備が整いました。文字起こししたい YouTube 動画を選択します。ビデオのダウンロードには時間がかかる場合があります。
import ipywidgets as widgets
VIDEO_LINK = "https://youtu.be/kgL5LBM-hFI"
link = widgets.Text(
value=VIDEO_LINK,
placeholder="Type link for video",
description="Video:",
disabled=False
)
link
Text(value='https://youtu.be/kgL5LBM-hFI', description='Video:', placeholder='Type link for video')
from pytube import YouTube
print(f"Downloading video {link.value} started")
output_file = Path("downloaded_video.mp4")
yt = YouTube(link.value)
yt.streams.get_highest_resolution().download(filename=output_file)
print(f"Video saved to {output_file}")
Downloading video https://youtu.be/kgL5LBM-hFI started
Video saved to downloaded_video.mp4
from utils import get_audio
audio, duration = get_audio(output_file)
モデルのタスクを選択します。
転写 - ソース言語で音声転写を生成します (自動的に検出されます)。
翻訳 - 英語へ翻訳付きの音声文字起こしを生成します。
task = widgets.Select(
options=["transcribe", "translate"],
value="translate",
description="Select task:",
disabled=False
)
task
Select(description='Select task:', index=1, options=('transcribe', 'translate'), value='translate')
transcription = model.transcribe(audio, task=task.value)
結果は downloaded_video.srt ファイルに保存されます。SRT は字幕を保存する最も一般的な形式の 1 つであり、多くの最新のビデオプレーヤーと互換性があります。このファイルを使用すると、再生中にビデオにトランスクリプションを埋め込んだり、ffmpeg を使用してビデオファイルに直接挿入したりできます。
from utils import prepare_srt
srt_lines = prepare_srt(transcription, filter_duration=duration)
# save transcription
with output_file.with_suffix(".srt").open("w") as f:
f.writelines(srt_lines)
それでは結果を確認します。
widgets.Video.from_file(output_file, loop=False, width=800, height=800)
Video(value=b"x00x00x00x18ftypmp42x00x00x00x00isommp42x00x00:'moovx00x00x00lmvhd...", height='800…
print("".join(srt_lines))
1
00:00:00,000 --> 00:00:05,000
What's that?
2
00:00:05,000 --> 00:00:07,000
Wow.
3
00:00:07,000 --> 00:00:10,000
Hello, humans.
4
00:00:10,000 --> 00:00:15,000
Focus on me.
5
00:00:15,000 --> 00:00:16,000
Focus on the guard.
6
00:00:16,000 --> 00:00:20,000
Don't tell anyone what you've seen in here.
7
00:00:20,000 --> 00:00:24,000
Have you seen what's in there?
8
00:00:24,000 --> 00:00:30,000
Intel. This is where it all changes.
インタラクティブなデモ¶
import gradio as gr
def transcribe(url, task):
output_file = Path("downloaded_video.mp4")
yt = YouTube(url)
yt.streams.get_highest_resolution().download(filename=output_file)
audio, duration = get_audio(output_file)
transcription = model.transcribe(audio, task=task.lower())
srt_lines = prepare_srt(transcription, duration)
with output_file.with_suffix(".srt").open("w") as f:
f.writelines(srt_lines)
return [str(output_file), str(output_file.with_suffix(".srt"))]
demo = gr.Interface(
transcribe,
[gr.Textbox(label="YouTube URL"), gr.Radio(["Transcribe", "Translate"], value="Transcribe")],
"video",
examples=[["https://youtu.be/kgL5LBM-hFI", "Transcribe"]],
allow_flagging="never"
)
try:
demo.launch(debug=False)
except Exception:
demo.launch(share=True, debug=False)
# if you are launching remotely, specify server_name and server_port
# demo.launch(server_name='your server name', server_port='server port in int')
# Read more in the docs: https://gradio.app/docs/
Running on local URL: http://127.0.0.1:7862 To create a public link, set share=True in launch().
Keyboard interruption in main thread... closing server.