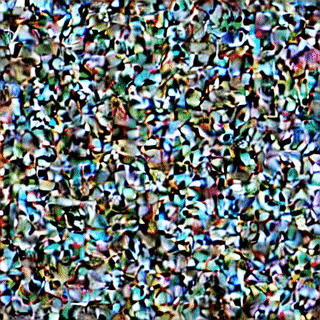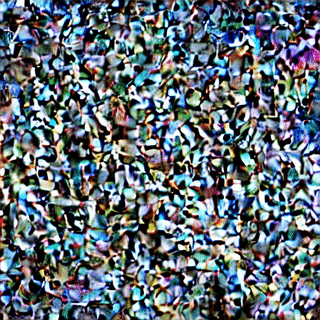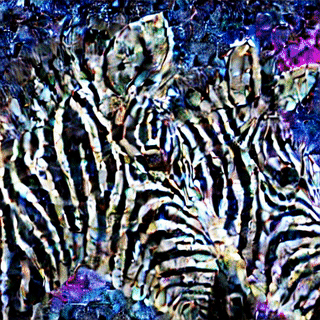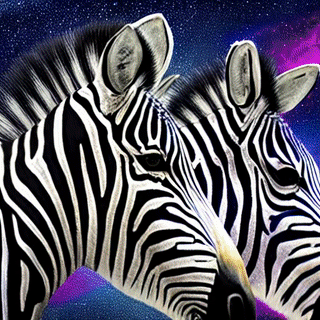Python ノードを使用した Stable diffusion デモ#
このデモでは、OpenVINO モデルサーバーを使用して stable diffusion パイプラインで画像を生成する方法を示します。
生成サイクルは、Python 計算機を備えた MediaPipe グラフを使用して調整されます。Python 計算機では、実行エンジンとして OpenVINO ランタイムを備えた Hugging Face Optimum を使用します。
次の 2 つのシナリオを考えてみましょう:
単項呼び出しの場合 - クライアントは単一のプロンプトをパイプラインに送信し、生成された完全なイメージを受け取ります。
gRPC ストリーミングの場合 - クライアントは単一のプロンプトを送信し、進行状況を調べるため中間結果のストリームを受け取ります。
イメージをビルド#
リポジトリーのルートから次を実行します:
git clone https://github.com/openvinotoolkit/model_server.git
cd model_server make python_imageopenvino/model_server:py というイメージが作成されます。
モデルのダウンロード#
このシナリオでは stable-diffusion パイプラインを使用します。download_model.py スクリプトでモデルをダウンロードします:
cd demos/python_demos/stable_diffusion pip
install -r requirements.txt
python3 download_model.pyモデルは、./model ディレクトリーに配置されます。
単項呼び出しでイメージを生成#
Python 計算機を使用した OpenVINO モデルサーバーのデプロイ#
次のコマンドで OpenVINO モデルサーバーを起動します:
docker run -d --rm -p 9000:9000 -v ${PWD}/servable_unary:/workspace -v ${PWD}/model:/model/ openvino/model_server:py --config_path /workspace/config.json --port 9000./model ディレクトリーをモデルとともにマウントします。
以下を含む ./servable_unary をマウント:
model.pyおよびconfig.py- 実行に必要な Python スクリプトで、optimum-intel アクセラレーションを備えた Hugging Face ユーティリティーを使用します。config.json- ロードするサーバブルを定義しますgraph.pbtxt- Python 計算機を含む MediaPipe グラフを定義します
注 コンテナのログを調べて、コンテナが正常に開始されたことを確認します。
注 CPU ではなくインテル® GPU で推論ロードを実行する場合は、docker の実行に追加のパラメーター
--device /dev/dri --group-add=$(stat -c "%g" /dev/dri/render*)を渡すだけです。GPU デバイスをコンテナに渡し、正しいグループ・セキュリティー・コンテキストを設定します。
通常とは異なる呼び出しでクライアントを実行#
クライアント要件をインストールします。この手順は単項クライアントとストリーミング・クライアントで共通です:
pip install -r client_requirements.txtクライアント・スクリプトを実行:
python3 client_unary.py --url localhost:9000 --prompt "Zebras in space"
Generated image output.png
Total response time: 18.39 s
gRPC ストリーミングを使用してイメージを生成#
Python 計算機を使用した OpenVINO モデルサーバーのデプロイ#
gRPC ストリーミングと中間応答の送信のユースケースは、同じモデルとパイプラインによる同様の実装に基づいています。主な違いは、model.py の実行メソッドには return の代わりに yield 操作があることです。また、生成サイクルの結果を送信するための最適なパイプラインからのコールバック関数も実装します。callback_steps パラメーターにより、応答の数を推定できます。
次のコマンドで OpenVINO モデルサーバーを起動します:
docker run -d --rm -p 9000:9000 -v ${PWD}/servable_stream:/workspace -v ${PWD}/model:/model/ openvino/model_server:py --config_path /workspace/config.json --port 9000注 コンテナのログを調べて、コンテナが正常に開始されたことを確認します。
注 CPU ではなくインテル® GPU で推論ロードを実行する場合は、docker の実行に追加のパラメーター
--device /dev/dri --group-add=$(stat -c "%g" /dev/dri/render*)を渡すだけです。GPU デバイスをコンテナに渡し、正しいグループ・セキュリティー・コンテキストを設定します。
gRPC ストリームを使用したクライアントの実行#
クライアント・スクリプトを実行:
python3 client_stream.py --url localhost:9000 --prompt "Zebras in space"
Executing pipeline
Generated final image image26.png
Transition saved to image.mp4
Total time 24351 ms
Number of responses 26
Average response time: 936.58 ms