PyTorch モデルから ONNX と OpenVINO™ IR への変換¶
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

このチュートリアルでは、OpenVINO ランタイムを使用して PyTorch セマンティック・セグメント化モデルで推論を行う方法を段階的に説明します。
まず、PyTorch モデルが ONNX 形式でエクスポートされ、OpenVINO IR に変換されます。次に、それぞれの ONNX および OpenVINO IR モデルが OpenVINO ランタイムにロードされ、モデルの予測が表示されます。このチュートリアルでは、MobileNetV3 バックボーンを備えた LR-ASPP モデルを使用します。
論文によると、MobileNetV3、LR-ASPP、または Lite Reduced Atrous Spatial Pyramid Pooling の検索には、軽量で効率的なセグメント化デコーダのアーキテクチャーが採用されています。以下の図は、モデルのアーキテクチャーを示しています。
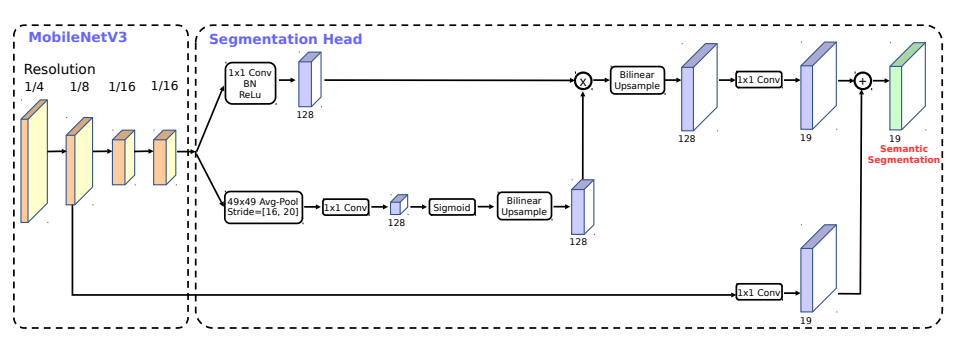
画像¶
モデルは MS COCO データセットで事前トレーニングされています。80 のクラスすべてでトレーニングする代わりに、セグメント化モデルは PASCAL VOC データセットの 20 クラスでトレーニングされました: 背景、飛行機、自転車、鳥、ボート、ボトル、バス、車、猫、椅子、牛、ダイニングテーブル、犬、 馬、バイク、人、鉢植え、羊、ソファ、電車、テレビモニター。
モデルの詳細については、torchvision のドキュメントを参照してください。
目次¶
# Install openvino package
%pip install -q "openvino>=2023.1.0" onnx
Note: you may need to restart the kernel to use updated packages.
準備¶
インポート¶
import time
import warnings
from pathlib import Path
import cv2
import numpy as np
import openvino as ov
import torch
from torchvision.models.segmentation import lraspp_mobilenet_v3_large, LRASPP_MobileNet_V3_Large_Weights
# Fetch `notebook_utils` module
import urllib.request
urllib.request.urlretrieve(
url='https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/main/notebooks/utils/notebook_utils.py',
filename='notebook_utils.py'
)
from notebook_utils import segmentation_map_to_image, viz_result_image, SegmentationMap, Label, download_file
設定¶
モデルの名前を設定し、推論中にネットワークによって使用される画像の幅と高さを定義します。入力変換関数に従って、モデルは高さ 520、幅 780 の画像で事前トレーニングされます。
IMAGE_WIDTH = 780
IMAGE_HEIGHT = 520
DIRECTORY_NAME = "model"
BASE_MODEL_NAME = DIRECTORY_NAME + "/lraspp_mobilenet_v3_large"
weights_path = Path(BASE_MODEL_NAME + ".pt")
# Paths where ONNX and OpenVINO IR models will be stored.
onnx_path = weights_path.with_suffix('.onnx')
if not onnx_path.parent.exists():
onnx_path.parent.mkdir()
ir_path = onnx_path.with_suffix(".xml")
モデルのロード¶
一般に、PyTorch モデルは、モデルの重みを含む状態辞書によって初期化された torch.nn.Module クラスのインスタンスを表します。
事前トレーニングされたモデルを取得する一般的な手順:
- モデルクラスのインスタンスを作成します。
- 事前トレーニングされたモデルの重みを含むチェックポイント状態辞書をロードします。
- 一部の操作を推論モードに切り替えるためモデルを評価に切り替えます。
torchvision モジュールは、モデルクラスの初期化に使用できる関数セットを提供します。ここでは、torchvision.models.segmentation.lraspp_mobilenet_v3_large を使用します。重み列挙型 LRASPP_MobileNet_V3_Large_Weights.COCO_WITH_VOC_LABELS_V1 を使用して、事前トレーニングされたモデルの重みをモデル初期化関数に直接渡すことができます。ただし、デモ用に別途作成します。事前トレーニングされた重みをダウンロードしてモデルをロードします。これまでにモデルをダウンロードしたことがない場合、これには時間がかかる場合があります。
print("Downloading the LRASPP MobileNetV3 model (if it has not been downloaded already)...")
download_file(LRASPP_MobileNet_V3_Large_Weights.COCO_WITH_VOC_LABELS_V1.url, filename=weights_path.name, directory=weights_path.parent)
# create model object
model = lraspp_mobilenet_v3_large()
# read state dict, use map_location argument to avoid a situation where weights are saved in cuda (which may not be unavailable on the system)
state_dict = torch.load(weights_path, map_location='cpu')
# load state dict to model
model.load_state_dict(state_dict)
# switch model from training to inference mode
model.eval()
print("Loaded PyTorch LRASPP MobileNetV3 model")
Downloading the LRASPP MobileNetV3 model (if it has not been downloaded already)...
model/lraspp_mobilenet_v3_large.pt: 0%| | 0.00/12.5M [00:00<?, ?B/s]
Loaded PyTorch LRASPP MobileNetV3 model
ONNX モデル変換¶
PyTorch モデルから ONNX への変換¶
OpenVINO は、ONNX 形式でエクスポートされる PyTorch モデルをサポートします。 torch.onnx.export 関数を使用して ONNX モデルを取得します。この機能の詳細については、PyTorch ドキュメントを参照してください。モデル・オブジェクト、モデルトレースの入力例、モデルが保存されるパスを提供する必要があります。入力例を提供する場合、実際のデータを使用する必要はなく、指定された形状のダミーの入力データで十分です。オプションで、変換のターゲット onnx 操作セットやドキュメントで指定されたその他のパラメーター (入力名と出力名や動的形状など) を提供できます。
場合によっては警告が表示されることがありますが、ほとんどの場合は無害なので、フィルター処理して除外しましょう。変換が成功すると、出力の最後の行は次のようになります: ONNX model exported to model/lraspp_mobilenet_v3_large.onnx.。
with warnings.catch_warnings():
warnings.filterwarnings("ignore")
if not onnx_path.exists():
dummy_input = torch.randn(1, 3, IMAGE_HEIGHT, IMAGE_WIDTH)
torch.onnx.export(
model,
dummy_input,
onnx_path,
)
print(f"ONNX model exported to {onnx_path}.")
else:
print(f"ONNX model {onnx_path} already exists.")
ONNX model exported to model/lraspp_mobilenet_v3_large.onnx.
ONNX モデルを OpenVINO IR 形式に変換¶
ONNX モデルを FP16 精度の OpenVINO IR に変換するには、モデル変換 API を使用します。モデルは現在のディレクトリー内に保存されます。モデルの変換方法の詳細については、このページを参照してください。
if not ir_path.exists():
print("Exporting ONNX model to IR... This may take a few minutes.")
ov_model = ov.convert_model(onnx_path)
ov.save_model(ov_model, ir_path)
else:
print(f"IR model {ir_path} already exists.")
Exporting ONNX model to IR... This may take a few minutes.
結果の表示¶
ONNX、OpenVINO IR、および PyTorch モデルの予測を比較して、セグメント化の結果が期待どおりであることを確認します。
入力画像のロードと前処理¶
画像は、ネットワークを通じて伝播する前に正規化する必要があります。
def normalize(image: np.ndarray) -> np.ndarray:
"""
Normalize the image to the given mean and standard deviation
for CityScapes models.
"""
image = image.astype(np.float32)
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
image /= 255.0
image -= mean
image /= std
return image
# Download the image from the openvino_notebooks storage
image_filename = download_file(
"https://storage.openvinotoolkit.org/repositories/openvino_notebooks/data/data/image/coco.jpg",
directory="data"
)
image = cv2.cvtColor(cv2.imread(str(image_filename)), cv2.COLOR_BGR2RGB)
resized_image = cv2.resize(image, (IMAGE_WIDTH, IMAGE_HEIGHT))
normalized_image = normalize(resized_image)
# Convert the resized images to network input shape.
input_image = np.expand_dims(np.transpose(resized_image, (2, 0, 1)), 0)
normalized_input_image = np.expand_dims(np.transpose(normalized_image, (2, 0, 1)), 0)
data/coco.jpg: 0%| | 0.00/202k [00:00<?, ?B/s]
OpenVINO IR ネットワークをロードして ONNX モデルで推論を実行¶
OpenVINO ランタイムは ONNX モデルを直接ロードできます。まず、ONNX モデルをロードし、推論を実行して結果を表示します。次に、OpenVINO 中間表現 (OpenVINO IR) に変換されたモデルを OpenVINO コンバーターで読み込み、モデルの推論を実行し、結果を画像に表示します。
1. OpenVINO ランタイムの ONNX モデル¶
# Instantiate OpenVINO Core
core = ov.Core()
# Read model to OpenVINO Runtime
model_onnx = core.read_model(model=onnx_path)
推論デバイスの選択¶
OpenVINO を使用して推論を実行するためにドロップダウン・リストからデバイスを選択します。
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='AUTO',
description='Device:',
disabled=False,
)
device
Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')
# Load model on device
compiled_model_onnx = core.compile_model(model=model_onnx, device_name=device.value)
# Run inference on the input image
res_onnx = compiled_model_onnx([normalized_input_image])[0]
モデルは、各ピクセルが特定のラベルにどの程度対応するか確率を予測します。各ピクセルに対して最も高い確率でラベルを取得するには、argmax 操作を適用する必要があります。その後、各ラベルに色分けを適用して、より便利に視覚化できます。
voc_labels = [
Label(index=0, color=(0, 0, 0), name="background"),
Label(index=1, color=(128, 0, 0), name="aeroplane"),
Label(index=2, color=(0, 128, 0), name="bicycle"),
Label(index=3, color=(128, 128, 0), name="bird"),
Label(index=4, color=(0, 0, 128), name="boat"),
Label(index=5, color=(128, 0, 128), name="bottle"),
Label(index=6, color=(0, 128, 128), name="bus"),
Label(index=7, color=(128, 128, 128), name="car"),
Label(index=8, color=(64, 0, 0), name="cat"),
Label(index=9, color=(192, 0, 0), name="chair"),
Label(index=10, color=(64, 128, 0), name="cow"),
Label(index=11, color=(192, 128, 0), name="dining table"),
Label(index=12, color=(64, 0, 128), name="dog"),
Label(index=13, color=(192, 0, 128), name="horse"),
Label(index=14, color=(64, 128, 128), name="motorbike"),
Label(index=15, color=(192, 128, 128), name="person"),
Label(index=16, color=(0, 64, 0), name="potted plant"),
Label(index=17, color=(128, 64, 0), name="sheep"),
Label(index=18, color=(0, 192, 0), name="sofa"),
Label(index=19, color=(128, 192, 0), name="train"),
Label(index=20, color=(0, 64, 128), name="tv monitor")
]
VOCLabels = SegmentationMap(voc_labels)
# Convert the network result to a segmentation map and display the result.
result_mask_onnx = np.squeeze(np.argmax(res_onnx, axis=1)).astype(np.uint8)
viz_result_image(
image,
segmentation_map_to_image(result_mask_onnx, VOCLabels.get_colormap()),
resize=True,
)
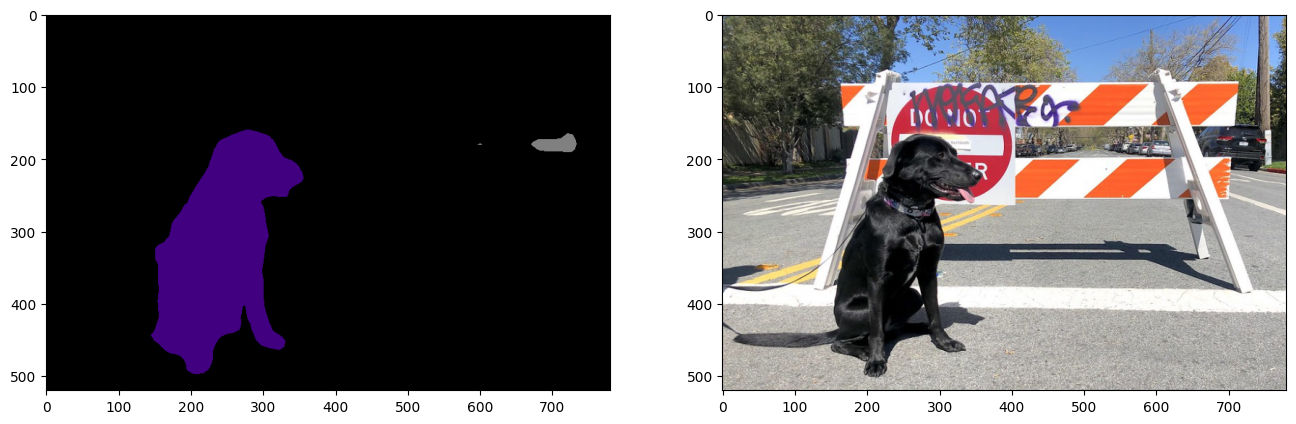
2. OpenVINO ランタイムの OpenVINO IR モデル¶
推論デバイスの選択¶
OpenVINO を使用して推論を実行するためにドロップダウン・リストからデバイスを選択します。
device
Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')
# Load the network in OpenVINO Runtime.
core = ov.Core()
model_ir = core.read_model(model=ir_path)
compiled_model_ir = core.compile_model(model=model_ir, device_name=device.value)
# Get input and output layers.
output_layer_ir = compiled_model_ir.output(0)
# Run inference on the input image.
res_ir = compiled_model_ir([normalized_input_image])[output_layer_ir]
result_mask_ir = np.squeeze(np.argmax(res_ir, axis=1)).astype(np.uint8)
viz_result_image(
image,
segmentation_map_to_image(result=result_mask_ir, colormap=VOCLabels.get_colormap()),
resize=True,
)
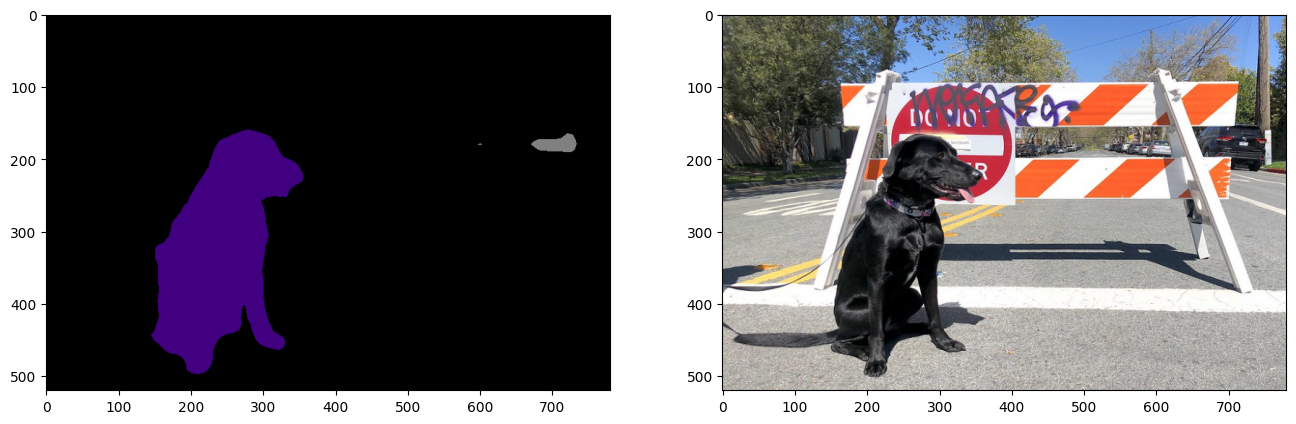
PyTorch の比較¶
PyTorch モデルで推論を実行し、出力が ONNX/OpenVINO IR モデルの出力と視覚的に同じであることを確認します。
model.eval()
with torch.no_grad():
result_torch = model(torch.as_tensor(normalized_input_image).float())
result_mask_torch = torch.argmax(result_torch['out'], dim=1).squeeze(0).numpy().astype(np.uint8)
viz_result_image(
image,
segmentation_map_to_image(result=result_mask_torch, colormap=VOCLabels.get_colormap()),
resize=True,
)
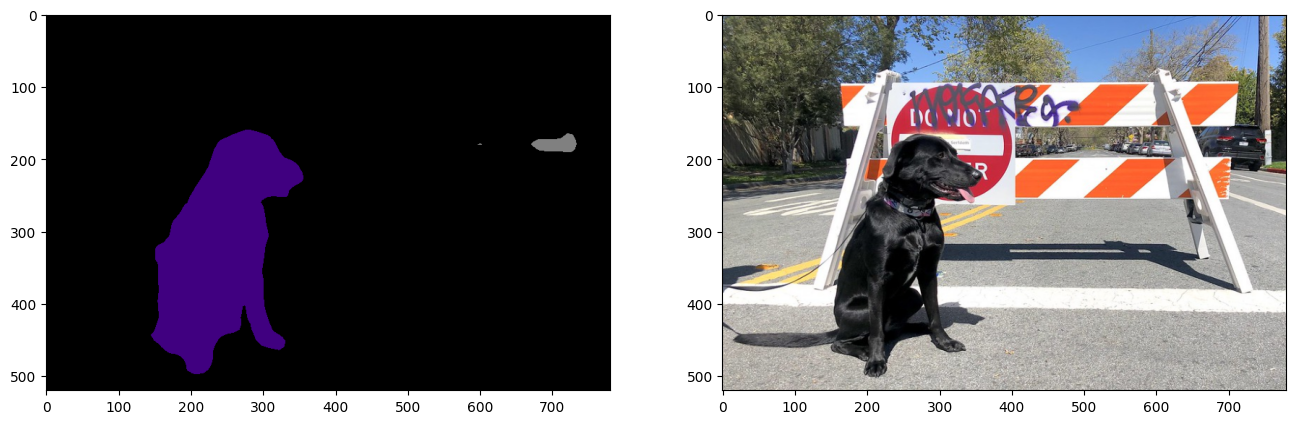
パフォーマンスの比較¶
20 枚の画像の推論にかかる時間を測定します。これはパフォーマンスの指標となります。より正確なベンチマークを行うには、ベンチマーク・ツールを使用します。パフォーマンスを向上するには多くの最適化が可能であることに注意してください。
num_images = 100
with torch.no_grad():
start = time.perf_counter()
for _ in range(num_images):
model(torch.as_tensor(input_image).float())
end = time.perf_counter()
time_torch = end - start
print(
f"PyTorch model on CPU: {time_torch/num_images:.3f} seconds per image, "
f"FPS: {num_images/time_torch:.2f}"
)
compiled_model_onnx = core.compile_model(model=model_onnx, device_name="CPU")
start = time.perf_counter()
for _ in range(num_images):
compiled_model_onnx([normalized_input_image])
end = time.perf_counter()
time_onnx = end - start
print(
f"ONNX model in OpenVINO Runtime/CPU: {time_onnx/num_images:.3f} "
f"seconds per image, FPS: {num_images/time_onnx:.2f}"
)
compiled_model_ir = core.compile_model(model=model_ir, device_name="CPU")
start = time.perf_counter()
for _ in range(num_images):
compiled_model_ir([input_image])
end = time.perf_counter()
time_ir = end - start
print(
f"OpenVINO IR model in OpenVINO Runtime/CPU: {time_ir/num_images:.3f} "
f"seconds per image, FPS: {num_images/time_ir:.2f}"
)
if "GPU" in core.available_devices:
compiled_model_onnx_gpu = core.compile_model(model=model_onnx, device_name="GPU")
start = time.perf_counter()
for _ in range(num_images):
compiled_model_onnx_gpu([input_image])
end = time.perf_counter()
time_onnx_gpu = end - start
print(
f"ONNX model in OpenVINO/GPU: {time_onnx_gpu/num_images:.3f} "
f"seconds per image, FPS: {num_images/time_onnx_gpu:.2f}"
)
compiled_model_ir_gpu = core.compile_model(model=model_ir, device_name="GPU")
start = time.perf_counter()
for _ in range(num_images):
compiled_model_ir_gpu([input_image])
end = time.perf_counter()
time_ir_gpu = end - start
print(
f"IR model in OpenVINO/GPU: {time_ir_gpu/num_images:.3f} "
f"seconds per image, FPS: {num_images/time_ir_gpu:.2f}"
)
PyTorch model on CPU: 0.040 seconds per image, FPS: 24.69
ONNX model in OpenVINO Runtime/CPU: 0.018 seconds per image, FPS: 56.48
OpenVINO IR model in OpenVINO Runtime/CPU: 0.018 seconds per image, FPS: 55.11
デバイス情報の表示
devices = core.available_devices
for device in devices:
device_name = core.get_property(device, "FULL_DEVICE_NAME")
print(f"{device}: {device_name}")
CPU: Intel(R) Core(TM) i9-10920X CPU @ 3.50GHz