低精度モデルの表現¶
このドキュメントの目的は、最適化されたモデルが OpenVINO 中間表現 (IR) でどのように表現されるかを説明し、実行時のモデルの解釈ルールに関するガイダンスを提供することです。
現在、完全精度モデルにした後に IR に影響を与える可能性がある最適化手法には 2 つのグループがあります。
粗さ (スパース性) - 重み内のゼロで表され、これらのゼロをどのように解釈するかはハードウェア・プラグインによって決まります (重みをそのまま使用するか、特別な圧縮アルゴリズムとスパース操作を適用します)。このモデルには追加のマスクは提供されません。
量子化 - このドキュメントの以降の節では、量子化モデルの表現に注目します。
量子化モデルの表現¶
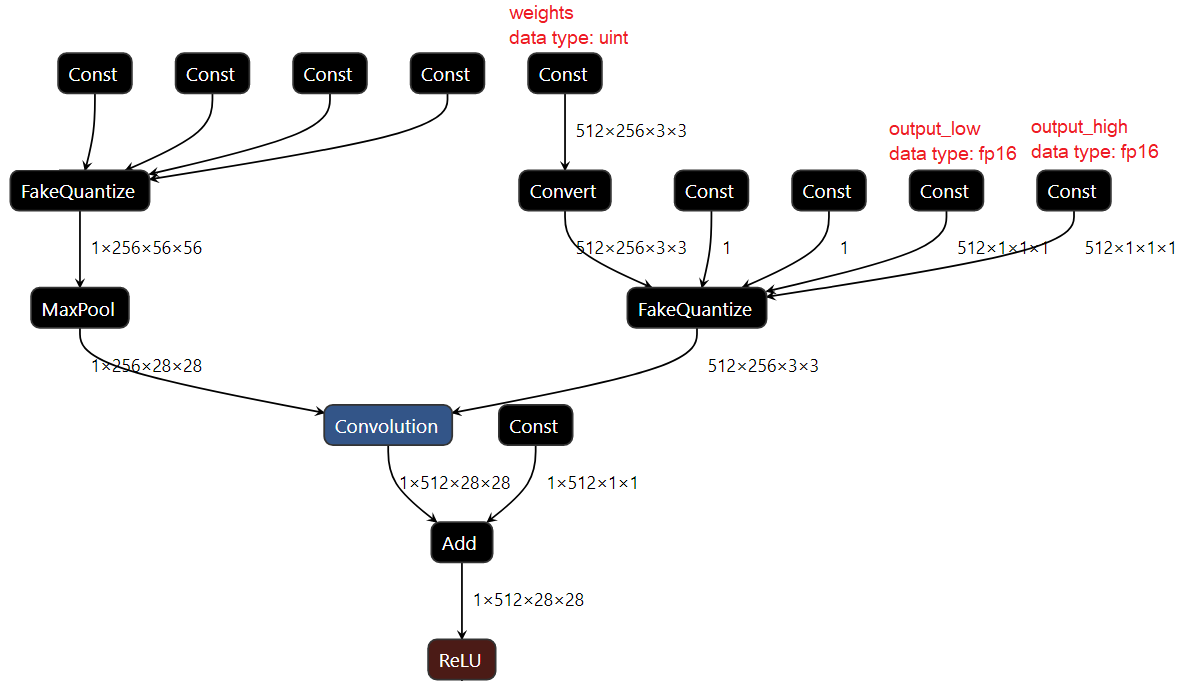
OpenVINO ツールキットは、いわゆる FakeQuantize 操作によってすべての量子化モデルを表します (このドキュメントの説明を参照)。この操作は非常に表現力が豊かで、任意の入力範囲と出力範囲から値をマッピングできます。背後にある考え方は非常に単純です。アフィン変換 (クランプと丸めを使用) を使用して入力値を低精度データタイプに投影 (離散化) し、次に離散値を元の範囲とデータタイプに再投影します。これは、実行時に発生する量子化プロセスのエミュレーションと考えることができます。特定の DL 操作を低精度で実行できるようにするには、すべての入力を量子化する必要があります。つまり、操作とデータ BLOB の間に FakeQuantize が必要です。以下の図は、2 つの FakeQuantize ノードを含む量子化された畳み込みの例を示しています。1 つは重み用、もう 1 つはアクティベーション用です (バイアスは同じパラメーターを使用して量子化されます)。
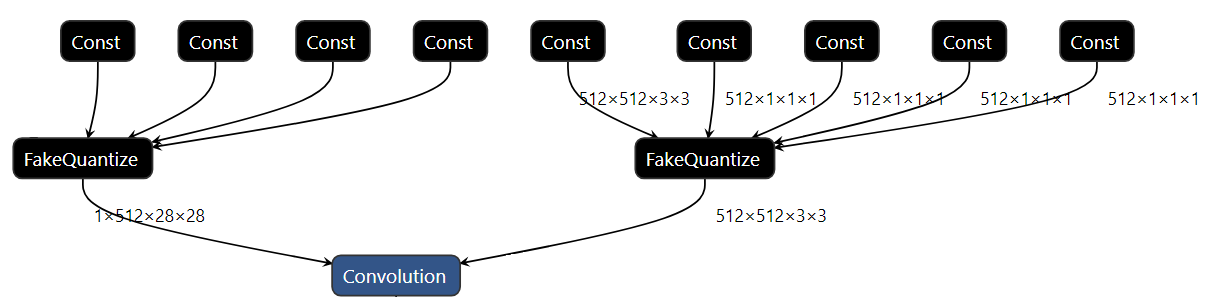
OpenVINO 2020.2 リリース以降、すべての量子化モデルは圧縮形式で表現されます。これは、低精度演算の重みがターゲット精度 (INT8 など) に変換されることを意味します。モデルのサイズを大幅に縮小するのに役立ちます。残りのパラメーターは、量子化プロセスで使用される入力の完全精度モデルに応じて、FLOAT32 または FLOAT16 精度で表現できます。下の図 2 は、圧縮された IR の例を示しています。