DeciDiffusion と OpenVINO による画像生成¶
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

DeciDiffusion 1.0 は、拡散ベースのテキストから画像への生成モデルです。DeciDiffusion は、変分オートエンコーダー (VAE) や CLIP の事前トレーニング済みテキストエンコーダなど、Stable Diffusion の基本的なアーキテクチャー要素を維持しながら、大幅に機能強化されています。主な革新は、U-Net を、Deci が先駆けて設計した、より効率良い U-Net-NAS に置き換えたことです。この新しいコンポーネントは、パラメーターの数を減らすことでモデルを合理化し、優れた計算効率を実現します。
テキストから画像を生成する分野は、デザイン、アート、広告の分野で変革の可能性を秘めており、専門家と一般の人々の両方を魅了してきました。このテクノロジーの魅力は、テキストを鮮やかな画像に簡単に変換できる点にあり、AI 機能の大きな飛躍を示しています。Stable Diffusion のオープンソース基盤は多くの進歩を進めてきましたが、膨大な計算量を必要とするため、実際の展開には課題が伴います。これらの課題により、トレーニングと展開において顕著な遅延とコストの問題が生じます。対照的に、DeciDiffusion は際立っています。優れた計算効率により、よりスムーズなユーザー・エクスペリエンスが保証され、生産コストが約 66% 削減されます。
このチュートリアルでは、OpenVINO を使用して DeciDiffusion を変換および実行し、テキストから画像を生成するアプリケーションをよりアクセスしやすく実現可能にする方法について説明します。追加部分では、パイプラインを高速化するため NNCF を使用して量子化を実行する方法を示します。
これには次の手順が含まれます。
OpenVINO コンバーター・ツール (OVC) を使用して、PyTorch モデルを OpenVINO 中間表現に変換します。
推論パイプラインを準備します。
OpenVINO を使用して推論パイプラインを実行します。
NNCF 量子化を使用して
OVStableDiffusionPipelineを最適化します。元のパイプラインと最適化されたパイプラインの結果を比較します。
DeciDiffusion モデルのインタラクティブなデモを実行します。
目次¶
必要条件¶
必要なパッケージをインストール
%pip install -q --extra-index-url https://download.pytorch.org/whl/cpu "diffusers" "transformers" "torch" "pillow" "openvino>=2023.1.0" "gradio" "datasets" "nncf"
OpenVINO 形式変換用に DeciDiffusion モデルを準備¶
モデルについて¶
DeciDiffusion 1.0 は、LAION-v2 データセットでトレーニングされ、LAION-ART データセットで微調整された、8 億 2000 万パラメーターのテキストから画像への潜在拡散モデルです。このアーキテクチャーは、Stable Diffusion 基本モデルに基づいており、従来の U-Net コンポーネントを、Deci が考案したより合理化されたバリアントである U-Net-NAS に置き換えています。
U-Net コンポーネントの役割と重要性を理解するには、潜在的拡散アーキテクチャーを詳しく調べる価値があります。
潜在的拡散は、潜在空間における基本的な “ノイズの多い” 画像表現から始まります。“レンガの壁に描かれた 1 パイントのビールの絵” などのテキストによるガイドに従って、モデルはこの表現を徐々に改良し、ノイズが除去された画像表現を次第に明らかにしていきます。十分な反復処理の後、潜在空間におけるこの表現は高解像度の画像に拡張されます。
潜在的拡散は、3 つの主要な要素で構成されます。
変分オートエンコーダー (VAE): 画像を潜在表現に変換し、その逆も行います。トレーニング中、エンコーダーは画像を潜在バージョンに変換しますが、デコーダーはトレーニングと推論の両方でこの逆も行います。
U-Net: 潜在画像にノイズを導入し、その後ノイズを低減する反復エンコーダー/デコーダメカニズム。デコーダーはクロスアテンション・レイヤーを採用し、指定されたテキスト記述にリンクされたテキスト埋め込みに基づいて出力を調整します。
テキスト・エンコーダー: このコンポーネントは、テキストプロンプトを、U-Net デコーダーが使用する潜在的なテキスト埋め込みに変換します。
U-Net は、トレーニングと推論中にリソースを大量に消費するコンポーネントです。ノイズ処理とノイズ除去のプロセスを繰り返し実行すると、反復ごとにかなりの計算コストが発生します。

unet-vs-unet-nas¶
U-Net-NAS は、U-Net よりもアップブロックとダウンブロックが 2 つ少なくなります。その特徴的な機能は、各ブロックの可変構成であり、ResNet ブロックと Attention ブロックの数が最適化され、最小限の計算で最高の全体的なモデル・パフォーマンスが実現されます。DeciDiffusion に U-Net-NAS を組み込むことで、パラメーター数が少なくなり、計算効率が向上し、モデル全体の計算要件が軽減されます。
DeciDiffusion と Diffusers ライブラリーの統合¶
DeciDiffusion を使用するには、Hugging Face Diffusers ライブラリーを使用します。DeciDiffusion は、小さなカスタマイズを加えた StableDiffusionPipeline です。デフォルトのパラメーターを上書きして U-Net モデルを置き換えます。load_orginal_pytorch_pipeline_componets 関数で定義されたコードでは、DeciDiffusion 用のディフューザー・パイプラインを作成する方法を示しています。
from pathlib import Path
import gc
import torch
import openvino as ov
from diffusers import StableDiffusionPipeline
import warnings
warnings.filterwarnings('ignore')
TEXT_ENCODER_OV_PATH = Path("model/text_encoder.xml")
UNET_OV_PATH = Path('model/unet_nas.xml')
VAE_ENCODER_OV_PATH = Path("model/vae_encoder.xml")
VAE_DECODER_OV_PATH = Path('model/vae_decoder.xml')
checkpoint = "Deci/DeciDiffusion-v1-0"
scheduler_config_dir = Path("model/scheduler")
tokenizer_dir = Path("model/tokenizer")
def load_orginal_pytorch_pipeline_componets():
pipeline = StableDiffusionPipeline.from_pretrained(checkpoint, custom_pipeline=checkpoint, torch_dtype=torch.float32)
pipeline.unet = pipeline.unet.from_pretrained(checkpoint, subfolder='flexible_unet', torch_dtype=torch.float32)
text_encoder = pipeline.text_encoder
text_encoder.eval()
unet = pipeline.unet
unet.eval()
vae = pipeline.vae
vae.eval()
del pipeline
gc.collect();
return text_encoder, unet, vae
def cleanup_torchscript_cache():
"""
Helper for removing cached model representation
"""
torch._C._jit_clear_class_registry()
torch.jit._recursive.concrete_type_store = torch.jit._recursive.ConcreteTypeStore()
torch.jit._state._clear_class_state()
skip_conversion = TEXT_ENCODER_OV_PATH.exists() and UNET_OV_PATH.exists() and VAE_ENCODER_OV_PATH.exists() and VAE_DECODER_OV_PATH.exists()
if not skip_conversion:
text_encoder, unet, vae = load_orginal_pytorch_pipeline_componets()
else:
text_encoder, unet, vae = None, None, None
モデルを OpenVINO 形式に変換¶
2023.0 リリース以降、OpenVINO はモデル変換 API を介して PyTorch モデルを直接サポートします。ov.convert_model 関数は、PyTorch モデルのインスタンスとトレース用のサンプル入力を受け入れ、ov.Modelクラスのオブジェクトを返します。このオブジェクトは、すぐに使用したり、ov.save_model 関数でディスクに保存したりできます。
すでに前述したように、パイプラインは次の 3 つの重要な部分で構成されています。
テキストプロンプトから画像を生成する条件を作成するテキスト・エンコーダー。
段階的にノイズを除去する潜像表現のための U-Net-NAS。
潜在空間を画像にデコードするオートエンコーダー (VAE)。
各パーツを変換してみましょう。
テキスト・エンコーダー¶
テキスト・エンコーダーは、入力プロンプト (例えば、“馬に乗った宇宙飛行士の写真”) を、U-Net が理解できる埋め込みスペースに変換する役割を果たします。これは通常、入力トークンのシーケンスを潜在テキスト埋め込みのシーケンスにマッピングする単純なトランスフォーマー・ベースのエンコーダーです。
テキスト・エンコーダーの入力はテンソル input_ids です。これには、トークナイザーによって処理され、モデルによって受け入れられる最大長までパディングされたテキストからのトークン・インデックスが含まれます。モデルの出力は 2 つのテンソルです。
last_hidden_state- モデル内の最後の MultiHeadtention レイヤーからの非表示状態。pooler_out- モデル全体の非表示状態のプールされた出力。
def convert_encoder(text_encoder: torch.nn.Module, ir_path:Path):
"""
Convert Text Encoder mode.
Function accepts text encoder model, and prepares example inputs for conversion,
Parameters:
text_encoder (torch.nn.Module): text_encoder model from Stable Diffusion pipeline
ir_path (Path): File for storing model
Returns:
None
"""
input_ids = torch.ones((1, 77), dtype=torch.long)
# switch model to inference mode
text_encoder.eval()
# disable gradients calculation for reducing memory consumption
with torch.no_grad():
# Export model to IR format
ov_model = ov.convert_model(text_encoder, example_input=input_ids, input=[(1,77),])
ov.save_model(ov_model, ir_path)
del ov_model
cleanup_torchscript_cache()
gc.collect();
print(f'Text Encoder successfully converted to IR and saved to {ir_path}')
if not TEXT_ENCODER_OV_PATH.exists():
convert_encoder(text_encoder, TEXT_ENCODER_OV_PATH)
else:
print(f"Text encoder will be loaded from {TEXT_ENCODER_OV_PATH}")
del text_encoder
gc.collect();
Text encoder will be loaded from model/text_encoder.xml
U-Net NAS¶
U-Net NAS モデルは、Stable Diffusion UNet モデルと同様に、3 つの入力があります。
sample- 前のステップからの潜在画像サンプル。生成プロセスはまだ開始されていないため、ランダムノイズを使用します。timestep- 現在のスケジューラー・ステップ。encoder_hidden_state- テキスト・エンコーダーの非表示状態。
モデルは次のステップのサンプルの状態を予測します。
import numpy as np
dtype_mapping = {
torch.float32: ov.Type.f32,
torch.float64: ov.Type.f64
}
def convert_unet(unet:torch.nn.Module, ir_path:Path):
"""
Convert U-net model to IR format.
Function accepts unet model, prepares example inputs for conversion,
Parameters:
unet (StableDiffusionPipeline): unet from Stable Diffusion pipeline
ir_path (Path): File for storing model
Returns:
None
"""
# prepare inputs
encoder_hidden_state = torch.ones((2, 77, 768))
latents_shape = (2, 4, 512 // 8, 512 // 8)
latents = torch.randn(latents_shape)
t = torch.from_numpy(np.array(1, dtype=float))
dummy_inputs = (latents, t, encoder_hidden_state)
input_info = []
for i, input_tensor in enumerate(dummy_inputs):
shape = ov.PartialShape(tuple(input_tensor.shape))
if i != 1:
shape[0] = -1
element_type = dtype_mapping[input_tensor.dtype]
input_info.append((shape, element_type))
unet.eval()
with torch.no_grad():
ov_model = ov.convert_model(unet, example_input=dummy_inputs, input=input_info)
ov.save_model(ov_model, ir_path)
del ov_model
cleanup_torchscript_cache()
gc.collect();
print(f'U-Net NAS successfully converted to IR and saved to {ir_path}')
if not UNET_OV_PATH.exists():
convert_unet(unet, UNET_OV_PATH)
else:
print(f"U-Net NAS will be loaded from {UNET_OV_PATH}")
del unet
gc.collect();
U-Net NAS will be loaded from model/unet_nas.xml
VAE¶
VAE モデルには、エンコーダーとデコーダーの 2 つのパーツがあります。エンコーダーは、画像を低次元の潜在表現に変換するのに使用され、これが U-Net モデルの入力となります。逆に、デコーダーは潜在表現を変換して画像に戻します。
潜在拡散トレーニング中、エンコーダーは、順拡散プロセス用の画像の潜在表現 (潜在) を取得するために使用され、各ステップでより多くのノイズが適用されます。推論中、逆拡散プロセスによって生成されたノイズ除去された潜在は、VAE デコーダーによって画像に変換されます。テキストから画像への推論を実行する場合、開始点となる初期画像はありません。この手順をスキップして、初期のランダムノイズを直接生成することもできます。
エンコーダーとデコーダーはパイプラインの異なる部分で独立して使用されるため、それらを別々のモデルに変換する方が適切です。
def convert_vae_encoder(vae: torch.nn.Module, ir_path: Path):
"""
Convert VAE model for encoding to IR format.
Function accepts vae model, creates wrapper class for export only necessary for inference part,
prepares example inputs for conversion,
Parameters:
vae (torch.nn.Module): VAE model from StableDiffusio pipeline
ir_path (Path): File for storing model
Returns:
None
"""
class VAEEncoderWrapper(torch.nn.Module):
def __init__(self, vae):
super().__init__()
self.vae = vae
def forward(self, image):
return self.vae.encode(x=image)["latent_dist"].sample()
vae_encoder = VAEEncoderWrapper(vae)
vae_encoder.eval()
image = torch.zeros((1, 3, 512, 512))
with torch.no_grad():
ov_model = ov.convert_model(vae_encoder, example_input=image, input=[((1,3,512,512),)])
ov.save_model(ov_model, ir_path)
del ov_model
cleanup_torchscript_cache()
gc.collect();
print(f'VAE encoder successfully converted to IR and saved to {ir_path}')
if not VAE_ENCODER_OV_PATH.exists():
convert_vae_encoder(vae, VAE_ENCODER_OV_PATH)
else:
print(f"VAE encoder will be loaded from {VAE_ENCODER_OV_PATH}")
def convert_vae_decoder(vae: torch.nn.Module, ir_path: Path):
"""
Convert VAE model for decoding to IR format.
Function accepts vae model, creates wrapper class for export only necessary for inference part,
prepares example inputs for conversion,
Parameters:
vae (torch.nn.Module): VAE model frm StableDiffusion pipeline
ir_path (Path): File for storing model
Returns:
None
"""
class VAEDecoderWrapper(torch.nn.Module):
def __init__(self, vae):
super().__init__()
self.vae = vae
def forward(self, latents):
return self.vae.decode(latents)
vae_decoder = VAEDecoderWrapper(vae)
latents = torch.zeros((1, 4, 64, 64))
vae_decoder.eval()
with torch.no_grad():
ov_model = ov.convert_model(vae_decoder, example_input=latents, input=[((1,4,64,64),)])
ov.save_model(ov_model, ir_path)
del ov_model
cleanup_torchscript_cache()
gc.collect();
print(f'VAE decoder successfully converted to IR and saved to {ir_path}')
if not VAE_DECODER_OV_PATH.exists():
convert_vae_decoder(vae, VAE_DECODER_OV_PATH)
else:
print(f"VAE decoder will be loaded from {VAE_DECODER_OV_PATH}")
del vae
gc.collect();
VAE encoder will be loaded from model/vae_encoder.xml
VAE decoder will be loaded from model/vae_decoder.xml
推論パイプラインの準備¶
すべてをまとめた論理フローを図から、モデルが推論でどのように機能するかを詳しく見てみましょう。
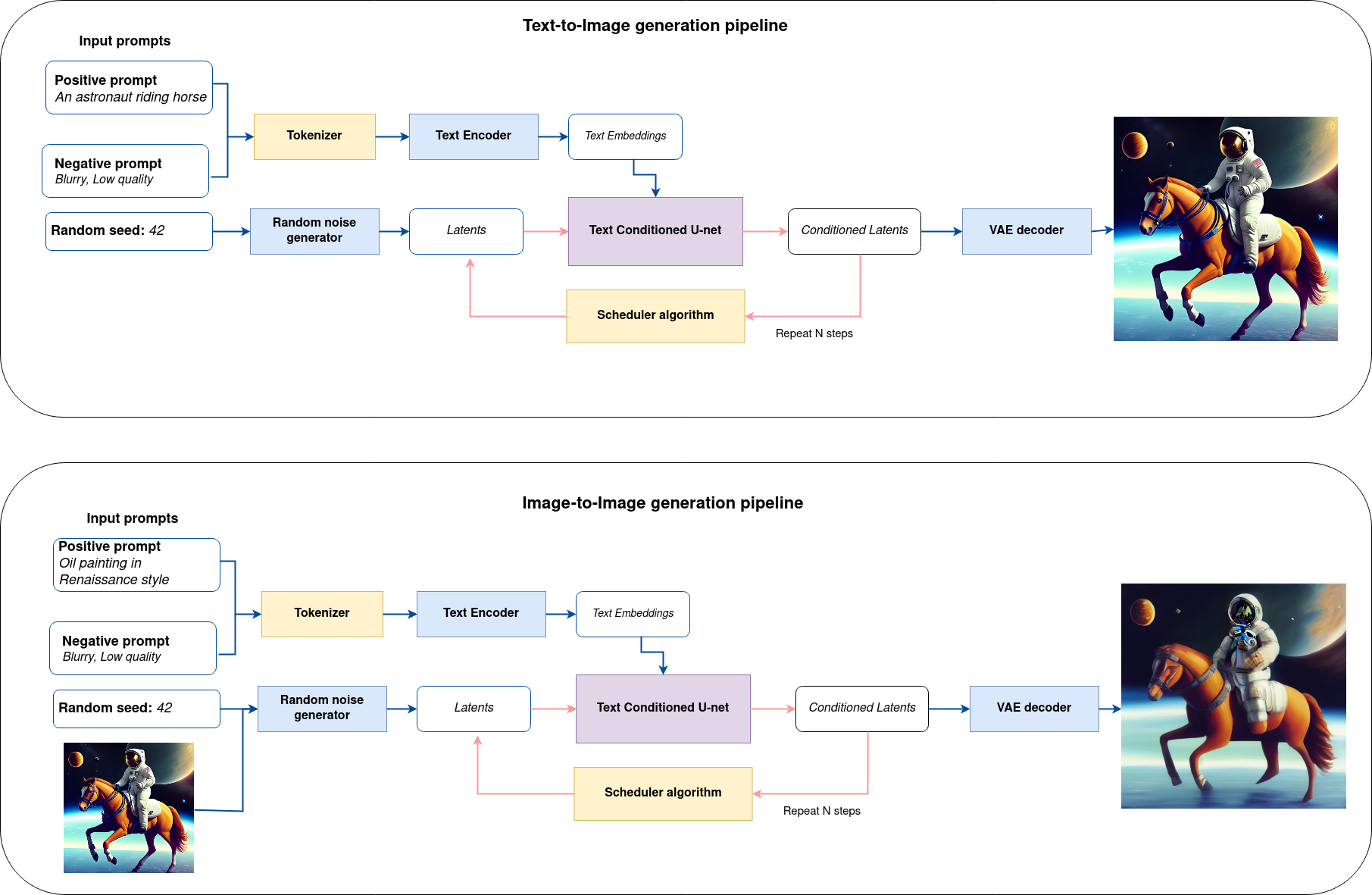
図から分かるように、テキストから画像への生成とテキスト誘導による画像から画像への生成のアプローチにおける唯一の違いは、初期の潜在状態が生成される方法です。画像から画像への生成の場合、VAE エンコーダーによってエンコードされた画像が、潜在シードを使用して生成されたノイズと混合されますが、テキストから画像への生成では、初期の潜在状態としてノイズのみを使用します。Stable diffusion モデルは、サイズ \(64 \times 64\) の潜在画像表現とテキストプロンプトの両方を入力として受け取り、CLIP のテキスト・エンコーダーを介してサイズ \(77 \times 768\) のテキスト埋め込みに変換されます。
次に、U-Net モデルは、テキスト埋め込みを条件として、ランダムな潜在画像表現を繰り返しノイズ除去します。U-Net の出力はノイズ残差であり、スケジューラー・アルゴリズムを介してノイズ除去された潜在画像表現を計算するために使用されます。この計算にはさまざまなスケジューラーのアルゴリズムを使用できますが、それぞれに長所と短所があります。サポートされているスケジューラーのアルゴリズムの詳細については、Diffusers のドキュメントを参照してください。
スケジューラーのアルゴリズム機能がどのように動作するかに関する理論は、このノートブックの範囲外ですが、以前のノイズ表現と予測されたノイズ残差から、予測されたノイズ除去画像表現を計算することを覚えておく必要があります。詳細については、推奨されている拡散ベースの生成モデルの設計空間の解明を参照してください。
ノイズ除去プロセスは、指定された回数 (DeciDiffusion の場合はデフォルトで 30 回) 繰り返され、段階的に潜在画像表現の改善が図られます。完了すると、潜在画像表現は変分オートエンコーダーのデコーダー部によってデコードされます。
生成結果を制御するガイダンス・スケールとネガティブ・プロンプト¶
ガイダンスのスケールは、生成された画像がプロンプトにどの程度類似するかを制御します。ガイダンススケールが高くなると、モデルはプロンプトに厳密に従って画像を生成しようとします。ガイダンススケールが低いほど、モデルの創造性が高まります。guidance_scale は、生成 (この場合はテキスト) をガイドする条件付き信号への準拠と、全体的なサンプル品質を高める方法です。これは分類子フリーガイダンスとも呼ばれます。DeciDiffusion のデフォルトのガイダンススケールは 0.7 です。
さらに、画像生成の品質を向上させるために、モデルは否定プロンプトをサポートします。技術的には、肯定プロンプトは拡散をそれに関連付けられた画像に向けて誘導し、否定プロンプトは拡散をそれから離れるように誘導します。言い換えれば、否定プロンプトは生成画像に対して望ましくない概念を宣言します。例えば、カラフルで明るい画像が必要な場合、グレースケール画像は避けたい結果になりますが、この場合、グレースケールは否定プロンプトとして扱うことができます。肯定プロンプトと否定プロンプトは同等です。両方を使用することも、どちらか一方だけを使用することもできます。仕組みの詳細については、この記事を参照してください。
注: 否定プロンプトは、高いガイダンススケール (少なくとも > 1) の場合にのみ適用されます。
Image-to-Image 生成制御の強み¶
画像から画像モードでは、強度パラメーターが重要な役割を果たします。新しい画像を生成する際に最初の画像に追加されるノイズのレベルを決定します。このパラメーターを調整することで、元の画像との一貫性を高め、クリエイティブな目的を達成できます。小さな変更を加えたり、画像全体を変換したりする柔軟性が得られます。
強度パラメーターの操作は非常に簡単で、極値がどのように機能するかを覚えておくだけで済みます。
強度を 0 に近づけると、元の画像とほぼ同じ画像が生成されます。
強度を 1 に設定すると、元の画像とは大きく異なる画像が生成されます。
最適な結果を得るには、元の画像の要素とプロンプトで概説されたコンセプトを組み合わせて、0.4 ~ 0.6 の値を目指すのが最適です。
import inspect
from typing import List, Optional, Union, Dict
import PIL
import cv2
from transformers import CLIPTokenizer
from diffusers.pipelines.pipeline_utils import DiffusionPipeline
from diffusers.schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
from openvino.runtime import Model
def scale_fit_to_window(dst_width:int, dst_height:int, image_width:int, image_height:int):
"""
Preprocessing helper function for calculating image size for resize with peserving original aspect ratio
and fitting image to specific window size
Parameters:
dst_width (int): destination window width
dst_height (int): destination window height
image_width (int): source image width
image_height (int): source image height
Returns:
result_width (int): calculated width for resize
result_height (int): calculated height for resize
"""
im_scale = min(dst_height / image_height, dst_width / image_width)
return int(im_scale * image_width), int(im_scale * image_height)
def preprocess(image: PIL.Image.Image):
"""
Image preprocessing function. Takes image in PIL.Image format, resizes it to keep aspect ration and fits to model input window 512x512,
then converts it to np.ndarray and adds padding with zeros on right or bottom side of image (depends from aspect ratio), after that
converts data to float32 data type and change range of values from [0, 255] to [-1, 1], finally, converts data layout from planar NHWC to NCHW.
The function returns preprocessed input tensor and padding size, which can be used in postprocessing.
Parameters:
image (PIL.Image.Image): input image
Returns:
image (np.ndarray): preprocessed image tensor
meta (Dict): dictionary with preprocessing metadata info
"""
src_width, src_height = image.size
dst_width, dst_height = scale_fit_to_window(512, 512, src_width, src_height)
image = np.array(image.resize((dst_width, dst_height),
resample=PIL.Image.Resampling.LANCZOS))[None, :]
pad_width = 512 - dst_width
pad_height = 512 - dst_height
pad = ((0, 0), (0, pad_height), (0, pad_width), (0, 0))
image = np.pad(image, pad, mode="constant")
image = image.astype(np.float32) / 255.0
image = 2.0 * image - 1.0
image = image.transpose(0, 3, 1, 2)
return image, {"padding": pad, "src_width": src_width, "src_height": src_height}
class OVStableDiffusionPipeline(DiffusionPipeline):
def __init__(
self,
vae_decoder: Model,
text_encoder: Model,
tokenizer: CLIPTokenizer,
unet: Model,
scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
vae_encoder: Model = None,
):
"""
Pipeline for text-to-image generation using Stable Diffusion.
Parameters:
vae (Model):
Variational Auto-Encoder (VAE) Model to decode images to and from latent representations.
text_encoder (Model):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the clip-vit-large-patch14(https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (CLIPTokenizer):
Tokenizer of class CLIPTokenizer(https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet (Model): Conditional U-Net architecture to denoise the encoded image latents.
scheduler (SchedulerMixin):
A scheduler to be used in combination with unet to denoise the encoded image latents. Can be one of
DDIMScheduler, LMSDiscreteScheduler, or PNDMScheduler.
"""
super().__init__()
self.scheduler = scheduler
self.vae_decoder = vae_decoder
self.vae_encoder = vae_encoder
self.text_encoder = text_encoder
self.register_to_config(unet=unet)
self._text_encoder_output = text_encoder.output(0)
self._unet_output = unet.output(0)
self._vae_d_output = vae_decoder.output(0)
self._vae_e_output = vae_encoder.output(0) if vae_encoder is not None else None
self.height = 512
self.width = 512
self.tokenizer = tokenizer
def __call__(
self,
prompt: Union[str, List[str]],
image: PIL.Image.Image = None,
num_inference_steps: Optional[int] = 30,
negative_prompt: Union[str, List[str]] = None,
guidance_scale: Optional[float] = 0.7,
eta: Optional[float] = 0.0,
output_type: Optional[str] = "pil",
seed: Optional[int] = None,
strength: float = 1.0,
gif: Optional[bool] = False,
**kwargs,
):
"""
Function invoked when calling the pipeline for generation.
Parameters:
prompt (str or List[str]):
The prompt or prompts to guide the image generation.
image (PIL.Image.Image, *optional*, None):
Intinal image for generation.
num_inference_steps (int, *optional*, defaults to 30):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
negative_prompt (str or List[str]):
The negative prompt or prompts to guide the image generation.
guidance_scale (float, *optional*, defaults to 0.7):
Guidance scale as defined in Classifier-Free Diffusion Guidance(https://arxiv.org/abs/2207.12598).
guidance_scale is defined as `w` of equation 2.
Higher guidance scale encourages to generate images that are closely linked to the text prompt,
usually at the expense of lower image quality.
eta (float, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[DDIMScheduler], will be ignored for others.
output_type (`str`, *optional*, defaults to "pil"):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): PIL.Image.Image or np.array.
seed (int, *optional*, None):
Seed for random generator state initialization.
gif (bool, *optional*, False):
Flag for storing all steps results or not.
Returns:
Dictionary with keys:
sample - the last generated image PIL.Image.Image or np.array
iterations - *optional* (if gif=True) images for all diffusion steps, List of PIL.Image.Image or np.array.
"""
if seed is not None:
np.random.seed(seed)
img_buffer = []
do_classifier_free_guidance = guidance_scale > 1.0
# get prompt text embeddings
text_embeddings = self._encode_prompt(prompt, do_classifier_free_guidance=do_classifier_free_guidance, negative_prompt=negative_prompt)
# set timesteps
accepts_offset = "offset" in set(inspect.signature(self.scheduler.set_timesteps).parameters.keys())
extra_set_kwargs = {}
if accepts_offset:
extra_set_kwargs["offset"] = 1
self.scheduler.set_timesteps(num_inference_steps, **extra_set_kwargs)
timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength)
latent_timestep = timesteps[:1]
# get the initial random noise unless the user supplied it
latents, meta = self.prepare_latents(image, latent_timestep)
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
for i, t in enumerate(self.progress_bar(timesteps)):
# expand the latents if you are doing classifier free guidance
latent_model_input = np.concatenate([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet([latent_model_input, t, text_embeddings])[self._unet_output]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred[0], noise_pred[1]
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(torch.from_numpy(noise_pred), t, torch.from_numpy(latents), **extra_step_kwargs)["prev_sample"].numpy()
if gif:
image = self.vae_decoder(latents * (1 / 0.18215))[self._vae_d_output]
image = self.postprocess_image(image, meta, output_type)
img_buffer.extend(image)
# scale and decode the image latents with vae
image = self.vae_decoder(latents * (1 / 0.18215))[self._vae_d_output]
image = self.postprocess_image(image, meta, output_type)
return {"sample": image, 'iterations': img_buffer}
def _encode_prompt(self, prompt:Union[str, List[str]], num_images_per_prompt:int = 1, do_classifier_free_guidance:bool = True, negative_prompt:Union[str, List[str]] = None):
"""
Encodes the prompt into text encoder hidden states.
Parameters:
prompt (str or list(str)): prompt to be encoded
num_images_per_prompt (int): number of images that should be generated per prompt
do_classifier_free_guidance (bool): whether to use classifier free guidance or not
negative_prompt (str or list(str)): negative prompt to be encoded
Returns:
text_embeddings (np.ndarray): text encoder hidden states
"""
batch_size = len(prompt) if isinstance(prompt, list) else 1
# tokenize input prompts
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="np",
)
text_input_ids = text_inputs.input_ids
text_embeddings = self.text_encoder(
text_input_ids)[self._text_encoder_output]
# duplicate text embeddings for each generation per prompt
if num_images_per_prompt != 1:
bs_embed, seq_len, _ = text_embeddings.shape
text_embeddings = np.tile(
text_embeddings, (1, num_images_per_prompt, 1))
text_embeddings = np.reshape(
text_embeddings, (bs_embed * num_images_per_prompt, seq_len, -1))
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
uncond_tokens: List[str]
max_length = text_input_ids.shape[-1]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
else:
uncond_tokens = negative_prompt
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="np",
)
uncond_embeddings = self.text_encoder(uncond_input.input_ids)[self._text_encoder_output]
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = uncond_embeddings.shape[1]
uncond_embeddings = np.tile(uncond_embeddings, (1, num_images_per_prompt, 1))
uncond_embeddings = np.reshape(uncond_embeddings, (batch_size * num_images_per_prompt, seq_len, -1))
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = np.concatenate([uncond_embeddings, text_embeddings])
return text_embeddings
def prepare_latents(self, image:PIL.Image.Image = None, latent_timestep:torch.Tensor = None):
"""
Function for getting initial latents for starting generation
Parameters:
image (PIL.Image.Image, *optional*, None):
Input image for generation, if not provided randon noise will be used as starting point
latent_timestep (torch.Tensor, *optional*, None):
Predicted by scheduler initial step for image generation, required for latent image mixing with nosie
Returns:
latents (np.ndarray):
Image encoded in latent space
"""
latents_shape = (1, 4, self.height // 8, self.width // 8)
noise = np.random.randn(*latents_shape).astype(np.float32)
if image is None:
# if you use LMSDiscreteScheduler, let's make sure latents are multiplied by sigmas
if isinstance(self.scheduler, LMSDiscreteScheduler):
noise = noise * self.scheduler.sigmas[0].numpy()
return noise, {}
input_image, meta = preprocess(image)
latents = self.vae_encoder(input_image)[self._vae_e_output] * 0.18215
latents = self.scheduler.add_noise(torch.from_numpy(latents), torch.from_numpy(noise), latent_timestep).numpy()
return latents, meta
def postprocess_image(self, image:np.ndarray, meta:Dict, output_type:str = "pil"):
"""
Postprocessing for decoded image. Takes generated image decoded by VAE decoder, unpad it to initila image size (if required),
normalize and convert to [0, 255] pixels range. Optionally, convertes it from np.ndarray to PIL.Image format
Parameters:
image (np.ndarray):
Generated image
meta (Dict):
Metadata obtained on latents preparing step, can be empty
output_type (str, *optional*, pil):
Output format for result, can be pil or numpy
Returns:
image (List of np.ndarray or PIL.Image.Image):
Postprocessed images
"""
if "padding" in meta:
pad = meta["padding"]
(_, end_h), (_, end_w) = pad[1:3]
h, w = image.shape[2:]
unpad_h = h - end_h
unpad_w = w - end_w
image = image[:, :, :unpad_h, :unpad_w]
image = np.clip(image / 2 + 0.5, 0, 1)
image = np.transpose(image, (0, 2, 3, 1))
# 9. Convert to PIL
if output_type == "pil":
image = self.numpy_to_pil(image)
if "src_height" in meta:
orig_height, orig_width = meta["src_height"], meta["src_width"]
image = [img.resize((orig_width, orig_height),
PIL.Image.Resampling.LANCZOS) for img in image]
else:
if "src_height" in meta:
orig_height, orig_width = meta["src_height"], meta["src_width"]
image = [cv2.resize(img, (orig_width, orig_width))
for img in image]
return image
def get_timesteps(self, num_inference_steps:int, strength:float):
"""
Helper function for getting scheduler timesteps for generation
In case of image-to-image generation, it updates number of steps according to strength
Parameters:
num_inference_steps (int):
number of inference steps for generation
strength (float):
value between 0.0 and 1.0, that controls the amount of noise that is added to the input image.
Values that approach 1.0 enable lots of variations but will also produce images that are not semantically consistent with the input.
"""
# get the original timestep using init_timestep
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
t_start = max(num_inference_steps - init_timestep, 0)
timesteps = self.scheduler.timesteps[t_start:]
return timesteps, num_inference_steps - t_start
推論パイプラインの構成¶
core = ov.Core()
まず、OpenVINO モデルのインスタンスを作成し、選択したデバイスを使用してコンパイルする必要があります。OpenVINO を使用して推論を実行するデバイスをドロップダウン・リストから選択します。
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='CPU',
description='Device:',
disabled=False,
)
device
text_enc = core.compile_model(TEXT_ENCODER_OV_PATH, device.value)
unet_model = core.compile_model(UNET_OV_PATH, device.value)
ov_vae_config = {"INFERENCE_PRECISION_HINT": "f32"} if device.value != "CPU" else {}
vae_decoder = core.compile_model(VAE_DECODER_OV_PATH, device.value, ov_vae_config)
vae_encoder = core.compile_model(VAE_ENCODER_OV_PATH, device.value, ov_vae_config)
モデル・トークナイザーとスケジューラーもパイプラインの重要なパーツです。これらを定義して、すべてのコンポーネントをまとめてみましょう。
from transformers import AutoTokenizer
from diffusers import DDIMScheduler
if not tokenizer_dir.exists():
tokenizer = AutoTokenizer.from_pretrained(checkpoint, subfolder='tokenizer')
tokenizer.save_pretrained(tokenizer_dir)
else:
tokenizer = AutoTokenizer.from_pretrained(tokenizer_dir)
if not scheduler_config_dir.exists():
scheduler = DDIMScheduler.from_pretrained(checkpoint, subfolder="scheduler")
scheduler.save_pretrained(scheduler_config_dir)
else:
scheduler = DDIMScheduler.from_pretrained(scheduler_config_dir)
ov_pipe = OVStableDiffusionPipeline(
tokenizer=tokenizer,
text_encoder=text_enc,
unet=unet_model,
vae_encoder=vae_encoder,
vae_decoder=vae_decoder,
scheduler=scheduler
)
Text-to-Image 生成¶
実際のモデルを見てみましょう。
text_prompt = 'Highly detailed portrait of a small, adorable cat with round, expressive eyes and a friendly smile'
num_steps = 30
seed = 4217
print('Pipeline settings')
print(f'Input text: {text_prompt}')
print(f'Seed: {seed}')
print(f'Number of steps: {num_steps}')
Pipeline settings
Input text: Highly detailed portrait of a small, adorable cat with round, expressive eyes and a friendly smile
Seed: 4217
Number of steps: 30
result = ov_pipe(text_prompt, num_inference_steps=num_steps, seed=seed)
0%| | 0/30 [00:00<?, ?it/s]
text = '\n\t'.join(text_prompt.split('.'))
print("Input text:")
print("\t" + text)
display(result['sample'][0])
Input text:
Highly detailed portrait of a small, adorable cat with round, expressive eyes and a friendly smile

Image-to-Image 生成¶
Stable Diffusion モデルの最も素晴らしい機能の 1 つは、既存の画像またはスケッチから画像生成を条件付けできることです。(粗い可能性のある) 画像と適切なテキストプロンプトがあれば、潜在拡散モデルを使用して画像を “強化” できます。
from diffusers.utils import load_image
default_image_url = "https://user-images.githubusercontent.com/29454499/274843996-b0d97f9b-7bfb-4d33-a6d8-d1822eec41ce.jpg"
text_i2i_prompt = 'Highly detailed realistic portrait of a grumpy small, adorable cat with round, expressive eyes'
strength = 0.87
guidance_scale = 7.5
num_i2i_steps = 15
seed_i2i = seed
image = load_image(default_image_url)
print('Pipeline settings')
print(f'Input text: {text_i2i_prompt}')
print(f'Seed: {seed_i2i}')
print(f'Number of steps: {num_i2i_steps}')
print(f"Strength: {strength}")
print(f"Guidance scale: {guidance_scale}")
display(image)
Pipeline settings
Input text: Highly detailed realistic portrait of a grumpy small, adorable cat with round, expressive eyes
Seed: 4217
Number of steps: 15
Strength: 0.87
Guidance scale: 7.5

result = ov_pipe(text_i2i_prompt, image, guidance_scale=guidance_scale, strength=strength, num_inference_steps=num_i2i_steps, seed=seed_i2i)
0%| | 0/13 [00:00<?, ?it/s]
text = '\n\t'.join(text_i2i_prompt.split('.'))
print("Input text:")
print("\t" + text)
display(result['sample'][0])
Input text:
Highly detailed realistic portrait of a grumpy small, adorable cat with round, expressive eyes

量子化¶
NNCF は、量子化レイヤーをモデルグラフに追加し、トレーニング・データセットのサブセットを使用してこれらの追加の量子化レイヤーのパラメーターを初期化することで、トレーニング後の量子化を可能にします。量子化操作は、FP16 ではなく INT8 で実行されるため、モデル推論が高速化されます。
DeciDiffusion 構造により、UNet NAS モデルはパイプライン全体の実行時間の大部分を占めます。ここでは、NNCF を使用して UNet 部分を最適化し、計算コストを削減してパイプラインを高速化する方法を説明します。DeciDiffusion パイプラインの残りのパーツを量子化しても、推論パフォーマンスは大幅に向上せず、精度が大幅に低下する可能性があります。
最適化プロセスには次の手順が含まれます。
量子化用のキャリブレーション・データセットを作成します。
nncf.quantize()を実行して、量子化されたモデルを取得します。openvino.save_model()関数を使用してINT8モデルを保存します。
モデルの推論速度を向上させるため量子化を実行するかどうかを以下で選択してください。
to_quantize = widgets.Checkbox(
value=True,
description='Quantization',
disabled=False,
)
to_quantize
Checkbox(value=True, description='Quantization')
to_quantize が選択されていない場合に量子化をスキップする skip magic 拡張機能をロードします。
import sys
sys.path.append("../utils")
int8_pipe = None
%load_ext skip_kernel_extension
キャリブレーション・データセットの準備¶
Hugging Face の検証 conceptual_captions データセットの一部をキャリブレーション・データとして使用します。キャリブレーション用の中間モデル入力を収集するには、CompiledModel をカスタマイズする必要があります。
%%skip not $to_quantize.value
class CompiledModelDecorator(ov.CompiledModel):
def __init__(self, compiled_model, prob=0.5):
super().__init__(compiled_model)
self.data_cache = []
self.prob = np.clip(prob, 0, 1)
def __call__(self, *args, **kwargs):
if np.random.rand() >= self.prob:
self.data_cache.append(*args)
return super().__call__(*args, **kwargs)
%%skip not $to_quantize.value
import datasets
from tqdm.notebook import tqdm
from transformers import set_seed
from typing import Any, Dict, List
set_seed(1)
def collect_calibration_data(pipeline: OVStableDiffusionPipeline, subset_size: int) -> List[Dict]:
original_unet = pipeline.unet
pipeline.unet = CompiledModelDecorator(original_unet, prob=0.3)
pipeline.set_progress_bar_config(disable=True)
dataset = datasets.load_dataset("conceptual_captions", split="train", streaming=True).shuffle(seed=42)
pbar = tqdm(total=subset_size)
for batch in dataset:
prompt = batch["caption"]
if len(prompt) > tokenizer.model_max_length:
continue
_ = pipeline(prompt, num_inference_steps=num_steps, seed=seed)
collected_subset_size = len(pipeline.unet.data_cache)
if collected_subset_size >= subset_size:
pbar.update(subset_size - pbar.n)
break
pbar.update(collected_subset_size - pbar.n)
calibration_dataset = pipeline.unet.data_cache
pipeline.set_progress_bar_config(disable=False)
pipeline.unet = original_unet
return calibration_dataset
%%skip not $to_quantize.value
UNET_INT8_OV_PATH = Path('model/unet_nas_int8.xml')
if not UNET_INT8_OV_PATH.exists():
subset_size = 300
unet_calibration_data = collect_calibration_data(ov_pipe, subset_size=subset_size)
量子化を実行¶
事前トレーニング済みの変換済み OpenVINO モデルから量子化モデルを作成します。
注: 量子化は時間とメモリーを消費する操作です。以下の量子化コードの実行には時間がかかる場合があります。
%%skip not $to_quantize.value
import nncf
UNET_INT8_OV_PATH = Path('model/unet_nas_int8.xml')
if not UNET_INT8_OV_PATH.exists():
unet = core.read_model(UNET_OV_PATH)
quantized_unet = nncf.quantize(
model=unet,
subset_size=subset_size,
preset=nncf.QuantizationPreset.MIXED,
calibration_dataset=nncf.Dataset(unet_calibration_data),
model_type=nncf.ModelType.TRANSFORMER,
# Smooth Quant algorithm reduces activation quantization error; optimal alpha value was obtained through grid search
advanced_parameters=nncf.AdvancedQuantizationParameters(
smooth_quant_alpha=0.05,
)
)
ov.save_model(quantized_unet, UNET_INT8_OV_PATH)
INFO:nncf:NNCF initialized successfully. Supported frameworks detected: torch, tensorflow, onnx, openvino
%%skip not $to_quantize.value
unet_optimized = core.compile_model(UNET_INT8_OV_PATH, device.value)
int8_pipe = OVStableDiffusionPipeline(
tokenizer=tokenizer,
text_encoder=text_enc,
unet=unet_optimized,
vae_encoder=vae_encoder,
vae_decoder=vae_decoder,
scheduler=scheduler
)
同じ入力データを使用して、量子化された UNet で予測を確認してみましょう。
%%skip not $to_quantize.value
import matplotlib.pyplot as plt
from PIL import Image
def visualize_results(orig_img:Image.Image, optimized_img:Image.Image):
"""
Helper function for results visualization
Parameters:
orig_img (Image.Image): generated image using FP16 models
optimized_img (Image.Image): generated image using quantized models
Returns:
fig (matplotlib.pyplot.Figure): matplotlib generated figure contains drawing result
"""
orig_title = "FP16 pipeline"
control_title = "INT8 pipeline"
figsize = (20, 20)
fig, axs = plt.subplots(1, 2, figsize=figsize, sharex='all', sharey='all')
list_axes = list(axs.flat)
for a in list_axes:
a.set_xticklabels([])
a.set_yticklabels([])
a.get_xaxis().set_visible(False)
a.get_yaxis().set_visible(False)
a.grid(False)
list_axes[0].imshow(np.array(orig_img))
list_axes[1].imshow(np.array(optimized_img))
list_axes[0].set_title(orig_title, fontsize=15)
list_axes[1].set_title(control_title, fontsize=15)
fig.subplots_adjust(wspace=0.01, hspace=0.01)
fig.tight_layout()
return fig
Text-to-Image 生成
%%skip not $to_quantize.value
fp16_image = ov_pipe(text_prompt, num_inference_steps=num_steps, seed=seed)['sample'][0]
int8_image = int8_pipe(text_prompt, num_inference_steps=num_steps, seed=seed)['sample'][0]
fig = visualize_results(fp16_image, int8_image)
0%| | 0/30 [00:00<?, ?it/s]
0%| | 0/30 [00:00<?, ?it/s]

Image-to-Image 生成
%%skip not $to_quantize.value
fp16_text_i2i = ov_pipe(text_i2i_prompt, image, guidance_scale=guidance_scale, strength=strength, num_inference_steps=num_i2i_steps, seed=seed_i2i)['sample'][0]
int8_text_i2i = int8_pipe(text_i2i_prompt, image, guidance_scale=guidance_scale, strength=strength, num_inference_steps=num_i2i_steps, seed=seed_i2i)['sample'][0]
fig = visualize_results(fp16_text_i2i, int8_text_i2i)
0%| | 0/13 [00:00<?, ?it/s]
0%| | 0/13 [00:00<?, ?it/s]

FP16 モデルと INT8 パイプラインの推論時間を比較¶
FP16 および INT8 パイプラインの推論パフォーマンスを測定するには、キャリブレーション・サブセットの推論時間の中央値を使用します。
注: 最も正確なパフォーマンス推定を行うには、他のアプリケーションを閉じた後、ターミナル/コマンドプロンプトで
benchmark_appを実行することを推奨します。
%%skip not $to_quantize.value
import time
validation_size = 10
calibration_dataset = datasets.load_dataset("conceptual_captions", split="train", streaming=True)
validation_data = []
for idx, batch in enumerate(calibration_dataset):
if idx >= validation_size:
break
prompt = batch["caption"]
validation_data.append(prompt)
def calculate_inference_time(pipeline, calibration_dataset):
inference_time = []
pipeline.set_progress_bar_config(disable=True)
for idx, prompt in enumerate(validation_data):
start = time.perf_counter()
_ = pipeline(prompt, num_inference_steps=num_steps, seed=seed)
end = time.perf_counter()
delta = end - start
inference_time.append(delta)
if idx >= validation_size:
break
return np.median(inference_time)
%%skip not $to_quantize.value
fp_latency = calculate_inference_time(ov_pipe, validation_data)
int8_latency = calculate_inference_time(int8_pipe, validation_data)
print(f"Performance speed up: {fp_latency / int8_latency:.3f}")
Performance speed up: 2.305
UNet ファイルサイズを比較¶
%%skip not $to_quantize.value
fp16_ir_model_size = UNET_OV_PATH.with_suffix(".bin").stat().st_size / 1024
quantized_model_size = UNET_INT8_OV_PATH.with_suffix(".bin").stat().st_size / 1024
print(f"FP16 model size: {fp16_ir_model_size:.2f} KB")
print(f"INT8 model size: {quantized_model_size:.2f} KB")
print(f"Model compression rate: {fp16_ir_model_size / quantized_model_size:.3f}")
FP16 model size: 1591318.15 KB
INT8 model size: 797158.32 KB
Model compression rate: 1.996
インタラクティブなデモ¶
インタラクティブなデモを起動するため量子化モデルを使用するかどうか以下で選択してください。
quantized_model_present = int8_pipe is not None
use_quantized_model = widgets.Checkbox(
value=True if quantized_model_present else False,
description='Use quantized model',
disabled=not quantized_model_present,
)
use_quantized_model
Checkbox(value=True, description='Use quantized model')
import gradio as gr
sample_img_url = "https://storage.openvinotoolkit.org/repositories/openvino_notebooks/data/data/image/tower.jpg"
img = load_image(sample_img_url).save("tower.jpg")
pipeline = int8_pipe if use_quantized_model.value else ov_pipe
def generate_from_text(text, negative_prompt, seed, num_steps, guidance_scale, _=gr.Progress(track_tqdm=True)):
result = pipeline(text, negative_prompt=negative_prompt, num_inference_steps=num_steps, seed=seed, guidance_scale=guidance_scale)
return result["sample"][0]
def generate_from_image(img, text, negative_prompt, seed, num_steps, strength, guidance_scale, _=gr.Progress(track_tqdm=True)):
result = pipeline(text, img, negative_prompt=negative_prompt, num_inference_steps=num_steps, seed=seed, strength=strength, guidance_scale=guidance_scale)
return result["sample"][0]
with gr.Blocks() as demo:
with gr.Tab("Text-to-Image generation"):
with gr.Row():
with gr.Column():
text_input = gr.Textbox(lines=3, label="Positive prompt")
neg_text_input = gr.Textbox(lines=3, label="Negative prompt")
seed_input = gr.Slider(0, 10000000, value=751, label="Seed")
steps_input = gr.Slider(1, 50, value=20, step=1, label="Steps")
guidance_scale = gr.Slider(label="Guidance Scale", minimum=0, maximum=50, value=0.7, step=0.1)
out = gr.Image(label="Result", type="pil")
sample_text = "futuristic synthwave city, retro sunset, crystals, spires, volumetric lighting, studio Ghibli style, rendered in unreal engine with clean details"
sample_text2 = "Highly detailed realistic portrait of a grumpy small, adorable cat with round, expressive eyes"
btn = gr.Button()
btn.click(generate_from_text, [text_input, neg_text_input, seed_input, steps_input, guidance_scale], out)
gr.Examples([[sample_text, "", 42, 20, 0.7], [sample_text2, "", 4218, 20, 0.7]], [text_input, neg_text_input, seed_input, steps_input, guidance_scale])
with gr.Tab("Image-to-Image generation"):
with gr.Row():
with gr.Column():
i2i_input = gr.Image(label="Image", type="pil")
i2i_text_input = gr.Textbox(lines=3, label="Text")
i2i_neg_text_input = gr.Textbox(lines=3, label="Negative prompt")
i2i_seed_input = gr.Slider(0, 10000000, value=42, label="Seed")
i2i_steps_input = gr.Slider(1, 50, value=10, step=1, label="Steps")
strength_input = gr.Slider(0, 1, value=0.5, label="Strength")
i2i_guidance_scale = gr.Slider(label="Guidance Scale", minimum=0, maximum=50, value=0.7, step=0.1)
i2i_out = gr.Image(label="Result", type="pil")
i2i_btn = gr.Button()
sample_i2i_text = "amazing watercolor painting"
i2i_btn.click(
generate_from_image,
[i2i_input, i2i_text_input, i2i_neg_text_input, i2i_seed_input, i2i_steps_input, strength_input, i2i_guidance_scale],
i2i_out,
)
gr.Examples(
[["tower.jpg", sample_i2i_text, "", 6400023, 30, 0.6, 5]],
[i2i_input, i2i_text_input, i2i_neg_text_input, i2i_seed_input, i2i_steps_input, strength_input, i2i_guidance_scale],
)
try:
demo.queue().launch(debug=False)
except Exception:
demo.queue().launch(share=True, debug=False)
# if you are launching remotely, specify server_name and server_port
# demo.launch(server_name='your server name', server_port='server port in int')
# Read more in the docs: https://gradio.app/docs/