潜在整合性モデルと OpenVINO による画像生成¶
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

LCM: 潜在拡散モデル (Latent Diffusion Models - LDM) に続く次世代の生成モデル。潜在拡散モデル (LDM) は、高解像度画像の合成において目覚ましい成果を達成しました。ただし、反復サンプリングには計算量が多く、生成が遅くなります。
一貫性モデルにヒントを得て、潜在一貫性モデル (LCM) が提案され、安定拡散 (Stable Diffusion) を含む事前トレーニング済みの LDM で最小限の手順で迅速な推論が可能になりました。一貫性モデル (CM) (Song 氏ら、2023) は、1 ステップまたは数ステップの生成を可能にする新しい生成モデルファミリーです。CM のコアアイデアは、PF-ODE (常微分方程式の確率フロー) の軌跡上の任意の点をその軌跡の原点 (つまり、PF-ODE の解) にマッピングする関数を学習することです。これらのモデルでは、ODE 軌道上の点の一貫性を維持する一貫性マッピングを学習することにより、単一ステップの生成が可能になり、計算集約型の反復が不要になります。ただし、CM はピクセル空間の画像生成タスクに制限されているため、高解像度の画像合成には適していません。LCM は、高解像度の画像を生成するため、画像潜在空間における一貫性モデルを採用しています。ガイド付き逆拡散プロセスを拡張確率フロー ODE (PF-ODE) の解決として捉え、LCM は潜在空間でそのような ODE の解を直接予測するように設計されており、多数の反復を軽減し、迅速かつ忠実度の高いサンプリングを可能にします。Stable Diffusion (SD) などの大規模拡散モデルで画像潜在空間を利用すると、画像生成品質が向上し、計算負荷が軽減されます。LCM の著者らは、潜在的一貫性蒸留 (LCD) と呼ばれるシンプルで効率的な 1 段階ガイド付き一貫性蒸留法を提供し、数ステップ (2〜4) または 1 ステップのサンプリングで SD を蒸留し、さらに収束を加速する SKIPPING-STEP 手法を提案しています。提案されたアプローチとモデルの詳細については、プロジェクトのページ、論文、元のリポジトリーを参照してください。
このチュートリアルでは、OpenVINO を使用して LCM を変換して実行する方法について説明します。 追加部分では、パイプラインを高速化するため NNCF を使用して量子化を実行する方法を示します。
目次¶
必要条件¶
%pip install -q "torch" --index-url https://download.pytorch.org/whl/cpu
%pip install -q "openvino>=2023.1.0" transformers "diffusers>=0.23.1" pillow gradio "nncf>=2.6.0" datasets --extra-index-url https://download.pytorch.org/whl/cpu
OpenVINO 形式変換用にモデルを準備¶
このチュートリアルでは、Hugging Face Hubの LCM_Dreamshaper_v7 を使用します。このモデルは、上で説明した潜在一貫性蒸留 (LCD) アプローチを使用して、Stable-Diffusion v1-5 を微調整した Dreamshaper v7 から蒸留されました。このモデルは、Diffusers ライブラリーにも統合されています。Diffusers は、画像、音声、さらには分子の 3D 構造を生成するための最先端の事前トレーニング済み拡散モデルを提供するライブラリーです。これにより、オリジナルの Stable Diffusion (このノートブックから) と LCD を使用して蒸留した実行を比較できます。蒸留アプローチは、拡張 PF-ODE を解くことによって、事前トレーニング済みのガイド付き拡散モデルを潜在一貫性モデルに効率的に変換します。
LCM の作業を開始するには、まず生成パイプラインをインスタンス化する必要があります。DiffusionPipeline.from_pretrained メソッドは、LCM のすべてのパイプライン・コンポーネントをダウンロードして構成します。このモデルは、モデル・リポジトリーの一部として保存されているカスタム推論パイプラインを使用します。また、custom_pipeline 引数とそのリビジョンを使用して、初期化のためロードするモジュールも提供する必要があります。
import gc
import warnings
from pathlib import Path
from diffusers import DiffusionPipeline
import numpy as np
warnings.filterwarnings("ignore")
TEXT_ENCODER_OV_PATH = Path("model/text_encoder.xml")
UNET_OV_PATH = Path("model/unet.xml")
VAE_DECODER_OV_PATH = Path("model/vae_decoder.xml")
def load_orginal_pytorch_pipeline_componets(skip_models=False, skip_safety_checker=False):
pipe = DiffusionPipeline.from_pretrained("SimianLuo/LCM_Dreamshaper_v7")
scheduler = pipe.scheduler
tokenizer = pipe.tokenizer
feature_extractor = pipe.feature_extractor if not skip_safety_checker else None
safety_checker = pipe.safety_checker if not skip_safety_checker else None
text_encoder, unet, vae = None, None, None
if not skip_models:
text_encoder = pipe.text_encoder
text_encoder.eval()
unet = pipe.unet
unet.eval()
vae = pipe.vae
vae.eval()
del pipe
gc.collect()
return (
scheduler,
tokenizer,
feature_extractor,
safety_checker,
text_encoder,
unet,
vae,
)
skip_conversion = (
TEXT_ENCODER_OV_PATH.exists()
and UNET_OV_PATH.exists()
and VAE_DECODER_OV_PATH.exists()
)
(
scheduler,
tokenizer,
feature_extractor,
safety_checker,
text_encoder,
unet,
vae,
) = load_orginal_pytorch_pipeline_componets(skip_conversion)
Fetching 15 files: 0%| | 0/15 [00:00<?, ?it/s]
diffusion_pytorch_model.safetensors: 0%| | 0.00/3.44G [00:00<?, ?B/s]
model.safetensors: 0%| | 0.00/1.22G [00:00<?, ?B/s]
model.safetensors: 0%| | 0.00/492M [00:00<?, ?B/s]
Loading pipeline components...: 0%| | 0/7 [00:00<?, ?it/s]
モデルを OpenVINO 形式に変換¶
2023.0 リリース以降、OpenVINO はモデル変換 API を介して PyTorch モデルを直接サポートします。ov.convert_model 関数は、PyTorch モデルのインスタンスとトレース用のサンプル入力を受け入れ、ov.Modelクラスのオブジェクトを返します。このオブジェクトは、すぐに使用したり、ov.save_model 関数でディスクに保存したりできます。
オリジナルの Stable Diffusion パイプラインと同様に、LCM パイプラインは次の 3 つの重要な部分で構成されます。
テキストプロンプトから画像を生成する条件を作成するテキスト・エンコーダー。
段階的にノイズを除去する潜像表現のための U-Net。
潜在空間を画像にデコードするオートエンコーダー (VAE)。
各パーツを変換してみましょう。
テキスト・エンコーダー¶
テキスト・エンコーダーは、入力プロンプト (例えば、“馬に乗った宇宙飛行士の写真”) を、U-Net が理解できる埋め込みスペースに変換する役割を果たします。これは通常、入力トークンのシーケンスを潜在テキスト埋め込みのシーケンスにマッピングする単純なトランスフォーマー・ベースのエンコーダーです。
テキスト・エンコーダーの入力はテンソル input_ids です。これには、トークナイザーによって処理され、モデルによって受け入れられる最大長までパディングされたテキストからのトークン・インデックスが含まれます。モデルの出力は 2 つのテンソルです。
last_hidden_state- モデル内の最後の MultiHeadtention レイヤーからの非表示状態。pooler_out- モデル全体の非表示状態のプールされた出力。
import torch
import openvino as ov
def cleanup_torchscript_cache():
"""
Helper for removing cached model representation
"""
torch._C._jit_clear_class_registry()
torch.jit._recursive.concrete_type_store = torch.jit._recursive.ConcreteTypeStore()
torch.jit._state._clear_class_state()
def convert_encoder(text_encoder: torch.nn.Module, ir_path: Path):
"""
Convert Text Encoder mode.
Function accepts text encoder model, and prepares example inputs for conversion,
Parameters:
text_encoder (torch.nn.Module): text_encoder model from Stable Diffusion pipeline
ir_path (Path): File for storing model
Returns:
None
"""
input_ids = torch.ones((1, 77), dtype=torch.long)
# switch model to inference mode
text_encoder.eval()
# disable gradients calculation for reducing memory consumption
with torch.no_grad():
# Export model to IR format
ov_model = ov.convert_model(
text_encoder,
example_input=input_ids,
input=[
(-1, 77),
],
)
ov.save_model(ov_model, ir_path)
del ov_model
cleanup_torchscript_cache()
gc.collect()
print(f"Text Encoder successfully converted to IR and saved to {ir_path}")
if not TEXT_ENCODER_OV_PATH.exists():
convert_encoder(text_encoder, TEXT_ENCODER_OV_PATH)
else:
print(f"Text encoder will be loaded from {TEXT_ENCODER_OV_PATH}")
del text_encoder
gc.collect()
Text encoder will be loaded from model/text_encoder.xml
9
U-Net¶
U-Net NAS モデルは、Stable Diffusion UNet モデルと同様に、4 つの入力があります。
sample- 前のステップからの潜在画像サンプル。生成プロセスはまだ開始されていないため、ランダムノイズを使用します。timestep- 現在のスケジューラー・ステップ。encoder_hidden_state- テキスト・エンコーダーの非表示状態。timestep_cond- 生成のためのタイムステップ条件。この入力は、元の Stable Diffusion U-Net モデルには存在せず、分類子フリー ガイダンスを使用して生成品質を向上させるため LCM によって導入されました。分類子フリーガイダンス (CFG) は、生成された画像がプロンプトにどの程度類似するか制御するため、Stable Diffusion で高品質のテキスト配置画像を合成するには不可欠です。潜在一貫性モデルでは、CFG は PF-ODE の拡張パラメーターとして機能します。
モデルは次のステップのサンプルの状態を予測します。
def convert_unet(unet: torch.nn.Module, ir_path: Path):
"""
Convert U-net model to IR format.
Function accepts unet model, prepares example inputs for conversion,
Parameters:
unet (StableDiffusionPipeline): unet from Stable Diffusion pipeline
ir_path (Path): File for storing model
Returns:
None
"""
# prepare inputs
dummy_inputs = {
"sample": torch.randn((1, 4, 64, 64)),
"timestep": torch.ones([1]).to(torch.float32),
"encoder_hidden_states": torch.randn((1, 77, 768)),
"timestep_cond": torch.randn((1, 256)),
}
unet.eval()
with torch.no_grad():
ov_model = ov.convert_model(unet, example_input=dummy_inputs)
ov.save_model(ov_model, ir_path)
del ov_model
cleanup_torchscript_cache()
gc.collect()
print(f"Unet successfully converted to IR and saved to {ir_path}")
if not UNET_OV_PATH.exists():
convert_unet(unet, UNET_OV_PATH)
else:
print(f"Unet will be loaded from {UNET_OV_PATH}")
del unet
gc.collect()
Unet successfully converted to IR and saved to model/unet.xml
0
VAE¶
VAE モデルには、エンコーダーとデコーダーの 2 つのパーツがあります。エンコーダーは、画像を低次元の潜在表現に変換するのに使用され、これが U-Net モデルの入力となります。逆に、デコーダーは潜在表現を変換して画像に戻します。
潜在拡散トレーニング中、エンコーダーは、順拡散プロセス用の画像の潜在表現 (潜在) を取得するために使用され、各ステップでより多くのノイズが適用されます。推論中、逆拡散プロセスによって生成されたノイズ除去された潜在は、VAE デコーダーによって画像に変換されます。テキストから画像への推論を実行する場合、開始点となる初期画像はありません。この手順をスキップして、初期のランダムノイズを直接生成することもできます。
ここでの推論パイプラインでは、メモリー消費量を削減するために、VAE エンコーダー部分を使用せず、その変換をスキップします。VAE エンコーダーの変換プロセスについては、Stable Diffusion ノートブックを参照してください。
def convert_vae_decoder(vae: torch.nn.Module, ir_path: Path):
"""
Convert VAE model for decoding to IR format.
Function accepts vae model, creates wrapper class for export only necessary for inference part,
prepares example inputs for conversion,
Parameters:
vae (torch.nn.Module): VAE model frm StableDiffusion pipeline
ir_path (Path): File for storing model
Returns:
None
"""
class VAEDecoderWrapper(torch.nn.Module):
def __init__(self, vae):
super().__init__()
self.vae = vae
def forward(self, latents):
return self.vae.decode(latents)
vae_decoder = VAEDecoderWrapper(vae)
latents = torch.zeros((1, 4, 64, 64))
vae_decoder.eval()
with torch.no_grad():
ov_model = ov.convert_model(vae_decoder, example_input=latents)
ov.save_model(ov_model, ir_path)
del ov_model
cleanup_torchscript_cache()
print(f"VAE decoder successfully converted to IR and saved to {ir_path}")
if not VAE_DECODER_OV_PATH.exists():
convert_vae_decoder(vae, VAE_DECODER_OV_PATH)
else:
print(f"VAE decoder will be loaded from {VAE_DECODER_OV_PATH}")
del vae
gc.collect()
VAE decoder will be loaded from model/vae_decoder.xml
0
推論パイプラインの準備¶
すべてをまとめた論理フローを図から、モデルが推論でどのように機能するかを詳しく見てみましょう。
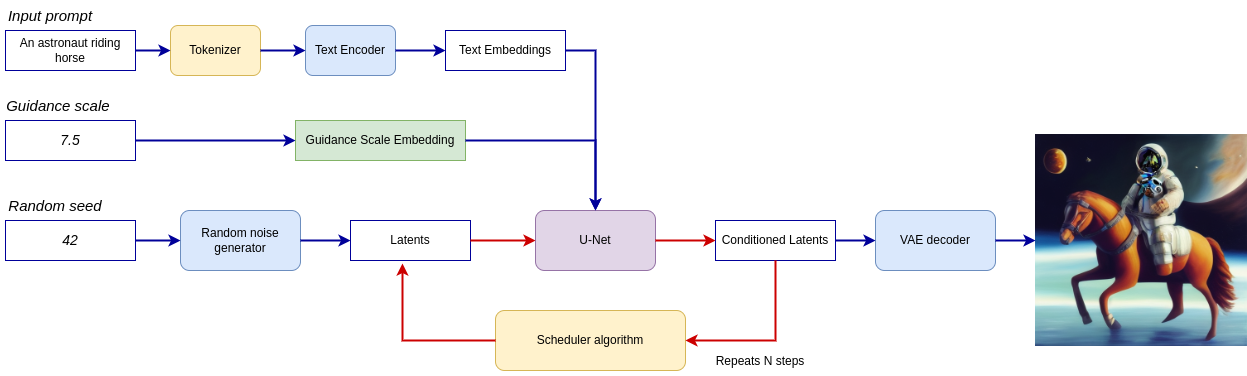
lcm-pipeline¶
パイプラインは潜在画像表現を受け取り、テキストプロンプトは入力として CLIP のテキスト・エンコーダーを介してテキスト埋め込みに変換されます。ランダム・ノイズ・ジェネレーターで生成された初期潜在画像表現。違いは、オリジナルの Stable Diffusion パイプラインでは、LCM は拡散プロセスの入力としてタイムステップ条件付き埋め込みを取得するためにガイダンススケールも使用するのに対し、Stable Diffusion では出力潜在変数をスケーリングするのに使用することです。
次に、U-Net モデルは、テキスト埋め込みを条件として、ランダムな潜在画像表現を繰り返しノイズ除去します。U-Net の出力はノイズ残差であり、スケジューラー・アルゴリズムを介してノイズ除去された潜在画像表現を計算するために使用されます。LCM は、非マルコフガイダンスによるノイズ除去拡散確率モデル (DDPM) で導入されたノイズ除去手順を拡張する独自のスケジューリング・アルゴリズムを導入します。ノイズ除去プロセスは、指定された回数 (元の SD パイプラインではデフォルトで 50 回ですが、LCM の場合は 2 ~ 8 回の少ないステップ) 繰り返され、段階的に潜在画像表現の改善が図られます。完了すると、潜在画像表現は変分オートエンコーダーのデコーダー部によってデコードされます。
from typing import Union, Optional, Any, List, Dict
from transformers import CLIPTokenizer, CLIPImageProcessor
from diffusers.pipelines.stable_diffusion.safety_checker import (
StableDiffusionSafetyChecker,
)
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.image_processor import VaeImageProcessor
class OVLatentConsistencyModelPipeline(DiffusionPipeline):
def __init__(
self,
vae_decoder: ov.Model,
text_encoder: ov.Model,
tokenizer: CLIPTokenizer,
unet: ov.Model,
scheduler: None,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super().__init__()
self.vae_decoder = vae_decoder
self.text_encoder = text_encoder
self.tokenizer = tokenizer
self.register_to_config(unet=unet)
self.scheduler = scheduler
self.safety_checker = safety_checker
self.feature_extractor = feature_extractor
self.vae_scale_factor = 2**3
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
def _encode_prompt(
self,
prompt,
num_images_per_prompt,
prompt_embeds: None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
num_images_per_prompt (`int`):
number of images that should be generated per prompt
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
"""
if prompt_embeds is None:
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(
prompt, padding="longest", return_tensors="pt"
).input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[
-1
] and not torch.equal(text_input_ids, untruncated_ids):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
prompt_embeds = self.text_encoder(text_input_ids, share_inputs=True, share_outputs=True)
prompt_embeds = torch.from_numpy(prompt_embeds[0])
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(
bs_embed * num_images_per_prompt, seq_len, -1
)
# Don't need to get uncond prompt embedding because of LCM Guided Distillation
return prompt_embeds
def run_safety_checker(self, image, dtype):
if self.safety_checker is None:
has_nsfw_concept = None
else:
if torch.is_tensor(image):
feature_extractor_input = self.image_processor.postprocess(
image, output_type="pil"
)
else:
feature_extractor_input = self.image_processor.numpy_to_pil(image)
safety_checker_input = self.feature_extractor(
feature_extractor_input, return_tensors="pt"
)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
return image, has_nsfw_concept
def prepare_latents(
self, batch_size, num_channels_latents, height, width, dtype, latents=None
):
shape = (
batch_size,
num_channels_latents,
height // self.vae_scale_factor,
width // self.vae_scale_factor,
)
if latents is None:
latents = torch.randn(shape, dtype=dtype)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
def get_w_embedding(self, w, embedding_dim=512, dtype=torch.float32):
"""
see https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
Args:
timesteps: torch.Tensor: generate embedding vectors at these timesteps
embedding_dim: int: dimension of the embeddings to generate
dtype: data type of the generated embeddings
Returns:
embedding vectors with shape `(len(timesteps), embedding_dim)`
"""
assert len(w.shape) == 1
w = w * 1000.0
half_dim = embedding_dim // 2
emb = torch.log(torch.tensor(10000.0)) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, dtype=dtype) * -emb)
emb = w.to(dtype)[:, None] * emb[None, :]
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
if embedding_dim % 2 == 1: # zero pad
emb = torch.nn.functional.pad(emb, (0, 1))
assert emb.shape == (w.shape[0], embedding_dim)
return emb
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]] = None,
height: Optional[int] = 512,
width: Optional[int] = 512,
guidance_scale: float = 7.5,
num_images_per_prompt: Optional[int] = 1,
latents: Optional[torch.FloatTensor] = None,
num_inference_steps: int = 4,
lcm_origin_steps: int = 50,
prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
):
# 1. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
# do_classifier_free_guidance = guidance_scale > 0.0
# In LCM Implementation: cfg_noise = noise_cond + cfg_scale * (noise_cond - noise_uncond) , (cfg_scale > 0.0 using CFG)
# 2. Encode input prompt
prompt_embeds = self._encode_prompt(
prompt,
num_images_per_prompt,
prompt_embeds=prompt_embeds,
)
# 3. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, original_inference_steps=lcm_origin_steps)
timesteps = self.scheduler.timesteps
# 4. Prepare latent variable
num_channels_latents = 4
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
latents,
)
bs = batch_size * num_images_per_prompt
# 5. Get Guidance Scale Embedding
w = torch.tensor(guidance_scale).repeat(bs)
w_embedding = self.get_w_embedding(w, embedding_dim=256)
# 6. LCM MultiStep Sampling Loop:
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
ts = torch.full((bs,), t, dtype=torch.long)
# model prediction (v-prediction, eps, x)
model_pred = self.unet([latents, ts, prompt_embeds, w_embedding], share_inputs=True, share_outputs=True)[0]
# compute the previous noisy sample x_t -> x_t-1
latents, denoised = self.scheduler.step(
torch.from_numpy(model_pred), t, latents, return_dict=False
)
progress_bar.update()
if not output_type == "latent":
image = torch.from_numpy(self.vae_decoder(denoised / 0.18215, share_inputs=True, share_outputs=True)[0])
image, has_nsfw_concept = self.run_safety_checker(
image, prompt_embeds.dtype
)
else:
image = denoised
has_nsfw_concept = None
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.image_processor.postprocess(
image, output_type=output_type, do_denormalize=do_denormalize
)
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(
images=image, nsfw_content_detected=has_nsfw_concept
)
推論パイプラインの構成¶
まず、OpenVINO モデルのインスタンスを作成し、選択したデバイスを使用してコンパイルする必要があります。OpenVINO を使用して推論を実行するデバイスをドロップダウン・リストから選択します。
core = ov.Core()
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value="CPU",
description="Device:",
disabled=False,
)
device
Dropdown(description='Device:', options=('CPU', 'AUTO'), value='CPU')
text_enc = core.compile_model(TEXT_ENCODER_OV_PATH, device.value)
unet_model = core.compile_model(UNET_OV_PATH, device.value)
ov_config = {"INFERENCE_PRECISION_HINT": "f32"} if device.value != "CPU" else {}
vae_decoder = core.compile_model(VAE_DECODER_OV_PATH, device.value, ov_config)
モデル・トークナイザーとスケジューラーもパイプラインの重要なパーツです。このパイプラインでは、対応する生成されたイメージに “職場で閲覧できない” (nsfw) コンテンツが含まれているかどうかを検出するフィルターであるセーフティーチェッカーも使用できます。nsfw コンテンツ検出のプロセスでは、CLIP モデルを使用して画像の埋め込みを取得する必要があるため、パイプラインにさらに機能抽出コンポーネントを追加する必要があります。オリジナルの LCM パイプラインからトークナイザー、特徴抽出器、スケジューラー、安全性チェッカーを再利用します。
ov_pipe = OVLatentConsistencyModelPipeline(
tokenizer=tokenizer,
text_encoder=text_enc,
unet=unet_model,
vae_decoder=vae_decoder,
scheduler=scheduler,
feature_extractor=feature_extractor,
safety_checker=safety_checker,
)
テキストから画像への生成¶
実際のモデルを見てみましょう。
prompt = "a beautiful pink unicorn, 8k"
num_inference_steps = 4
torch.manual_seed(1234567)
images = ov_pipe(
prompt=prompt,
num_inference_steps=num_inference_steps,
guidance_scale=8.0,
lcm_origin_steps=50,
output_type="pil",
height=512,
width=512,
).images
0%| | 0/4 [00:00<?, ?it/s]
images[0]

ご覧の通り、画像はかなり高解像度です 🔥。
量子化¶
NNCF は、量子化レイヤーをモデルグラフに追加し、トレーニング・データセットのサブセットを使用してこれらの追加の量子化レイヤーのパラメーターを初期化することで、トレーニング後の量子化を可能にします。量子化操作は FP32/FP16 ではなく INT8 で実行されるため、モデル推論が高速化されます。
LatentConsistencyModelPipeline 構造に従って、入力の反復的なノイズ除去に UNet が使用されます。これは、モデルが各拡散ステップで推論を繰り返すサイクルで実行され、パイプラインの他の部分は 1 回だけ実行されることを意味します。そのため、UNet ノイズ除去の計算コストと速度がパイプラインのクリティカル・パスになります。SD パイプラインの残りのパーツを量子化しても、推論パフォーマンスは大幅に向上せず、精度が大幅に低下する可能性があります。
最適化プロセスには次の手順が含まれます。
量子化用のキャリブレーション・データセットを作成します。
nncf.quantize()を実行して、量子化されたモデルを取得します。openvino.save_model()関数を使用してINT8モデルを保存します。
モデルの推論速度を向上させるため量子化を実行するかどうかを以下で選択してください。
to_quantize = widgets.Checkbox(
value=True,
description='Quantization',
disabled=False,
)
to_quantize
Checkbox(value=True, description='Quantization')
to_quantize が選択されていない場合に量子化をスキップする skip magic 拡張機能をロードします。
import sys
sys.path.append("../utils")
int8_pipe = None
if to_quantize.value and "GPU" in device.value:
to_quantize.value = False
%load_ext skip_kernel_extension
キャリブレーション・データセットの準備¶
Hugging Face の検証 conceptual_captions データセットの一部をキャリブレーション・データとして使用します。キャリブレーション用の中間モデル入力を収集するには、CompiledModel をカスタマイズする必要があります。
%%skip not $to_quantize.value
import datasets
from tqdm.notebook import tqdm
from transformers import set_seed
from typing import Any, Dict, List
set_seed(1)
class CompiledModelDecorator(ov.CompiledModel):
def __init__(self, compiled_model, prob: float, data_cache: List[Any] = None):
super().__init__(compiled_model)
self.data_cache = data_cache if data_cache else []
self.prob = np.clip(prob, 0, 1)
def __call__(self, *args, **kwargs):
if np.random.rand() >= self.prob:
self.data_cache.append(*args)
return super().__call__(*args, **kwargs)
def collect_calibration_data(lcm_pipeline: OVLatentConsistencyModelPipeline, subset_size: int) -> List[Dict]:
original_unet = lcm_pipeline.unet
lcm_pipeline.unet = CompiledModelDecorator(original_unet, prob=0.3)
dataset = datasets.load_dataset("conceptual_captions", split="train").shuffle(seed=42)
lcm_pipeline.set_progress_bar_config(disable=True)
safety_checker = lcm_pipeline.safety_checker
lcm_pipeline.safety_checker = None
# Run inference for data collection
pbar = tqdm(total=subset_size)
diff = 0
for batch in dataset:
prompt = batch["caption"]
if len(prompt) > tokenizer.model_max_length:
continue
_ = lcm_pipeline(
prompt,
num_inference_steps=num_inference_steps,
guidance_scale=8.0,
lcm_origin_steps=50,
output_type="pil",
height=512,
width=512,
)
collected_subset_size = len(lcm_pipeline.unet.data_cache)
if collected_subset_size >= subset_size:
pbar.update(subset_size - pbar.n)
break
pbar.update(collected_subset_size - diff)
diff = collected_subset_size
calibration_dataset = lcm_pipeline.unet.data_cache
lcm_pipeline.set_progress_bar_config(disable=False)
lcm_pipeline.unet = original_unet
lcm_pipeline.safety_checker = safety_checker
return calibration_dataset
%%skip not $to_quantize.value
import logging
logging.basicConfig(level=logging.WARNING)
logger = logging.getLogger(__name__)
UNET_INT8_OV_PATH = Path("model/unet_int8.xml")
if not UNET_INT8_OV_PATH.exists():
subset_size = 200
unet_calibration_data = collect_calibration_data(ov_pipe, subset_size=subset_size)
0%| | 0/200 [00:00<?, ?it/s]
量子化を実行¶
事前トレーニング済みの変換済み OpenVINO モデルから量子化モデルを作成します。
注: 量子化は時間とメモリーを消費する操作です。以下の量子化コードの実行には時間がかかる場合があります。
%%skip not $to_quantize.value
import nncf
from nncf.scopes import IgnoredScope
if UNET_INT8_OV_PATH.exists():
print("Loading quantized model")
quantized_unet = core.read_model(UNET_INT8_OV_PATH)
else:
unet = core.read_model(UNET_OV_PATH)
quantized_unet = nncf.quantize(
model=unet,
subset_size=subset_size,
preset=nncf.QuantizationPreset.MIXED,
calibration_dataset=nncf.Dataset(unet_calibration_data),
model_type=nncf.ModelType.TRANSFORMER,
advanced_parameters=nncf.AdvancedQuantizationParameters(
disable_bias_correction=True
)
)
ov.save_model(quantized_unet, UNET_INT8_OV_PATH)
INFO:nncf:NNCF initialized successfully. Supported frameworks detected: torch, onnx, openvino
Output()
Output()
INFO:nncf:122 ignored nodes were found by name in the NNCFGraph
Output()
%%skip not $to_quantize.value
unet_optimized = core.compile_model(UNET_INT8_OV_PATH, device.value)
int8_pipe = OVLatentConsistencyModelPipeline(
tokenizer=tokenizer,
text_encoder=text_enc,
unet=unet_optimized,
vae_decoder=vae_decoder,
scheduler=scheduler,
feature_extractor=feature_extractor,
safety_checker=safety_checker,
)
同じ入力データを使用して、量子化された UNet で予測を確認してみましょう。
%%skip not $to_quantize.value
from IPython.display import display
prompt = "a beautiful pink unicorn, 8k"
num_inference_steps = 4
torch.manual_seed(1234567)
images = int8_pipe(
prompt=prompt,
num_inference_steps=num_inference_steps,
guidance_scale=8.0,
lcm_origin_steps=50,
output_type="pil",
height=512,
width=512,
).images
display(images[0])
0%| | 0/4 [00:00<?, ?it/s]

FP16 モデルと INT8 モデルの推論時間を比較¶
FP16 および INT8 パイプラインの推論パフォーマンスを測定するには、キャリブレーション・サブセットの推論時間の中央値を使用します。
注: 最も正確なパフォーマンス推定を行うには、他のアプリケーションを閉じた後、ターミナル/コマンドプロンプトで
benchmark_appを実行することを推奨します。
%%skip not $to_quantize.value
import time
validation_size = 10
calibration_dataset = datasets.load_dataset("conceptual_captions", split="train")
validation_data = []
for idx, batch in enumerate(calibration_dataset):
if idx >= validation_size:
break
prompt = batch["caption"]
validation_data.append(prompt)
def calculate_inference_time(pipeline, calibration_dataset):
inference_time = []
pipeline.set_progress_bar_config(disable=True)
for idx, prompt in enumerate(validation_data):
start = time.perf_counter()
_ = pipeline(
prompt,
num_inference_steps=num_inference_steps,
guidance_scale=8.0,
lcm_origin_steps=50,
output_type="pil",
height=512,
width=512,
)
end = time.perf_counter()
delta = end - start
inference_time.append(delta)
if idx >= validation_size:
break
return np.median(inference_time)
%%skip not $to_quantize.value
fp_latency = calculate_inference_time(ov_pipe, validation_data)
int8_latency = calculate_inference_time(int8_pipe, validation_data)
print(f"Performance speed up: {fp_latency / int8_latency:.3f}")
Performance speed up: 1.319
UNet ファイルサイズを比較¶
%%skip not $to_quantize.value
fp16_ir_model_size = UNET_OV_PATH.with_suffix(".bin").stat().st_size / 1024
quantized_model_size = UNET_INT8_OV_PATH.with_suffix(".bin").stat().st_size / 1024
print(f"FP16 model size: {fp16_ir_model_size:.2f} KB")
print(f"INT8 model size: {quantized_model_size:.2f} KB")
print(f"Model compression rate: {fp16_ir_model_size / quantized_model_size:.3f}")
FP16 model size: 1678912.37 KB
INT8 model size: 840792.93 KB
Model compression rate: 1.997
インタラクティブなデモ¶
import random
import gradio as gr
from functools import partial
MAX_SEED = np.iinfo(np.int32).max
examples = [
"portrait photo of a girl, photograph, highly detailed face, depth of field, moody light, golden hour,"
"style by Dan Winters, Russell James, Steve McCurry, centered, extremely detailed, Nikon D850, award winning photography",
"Self-portrait oil painting, a beautiful cyborg with golden hair, 8k",
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
"A photo of beautiful mountain with realistic sunset and blue lake, highly detailed, masterpiece",
]
def randomize_seed_fn(seed: int, randomize_seed: bool) -> int:
if randomize_seed:
seed = random.randint(0, MAX_SEED)
return seed
MAX_IMAGE_SIZE = 768
def generate(
pipeline: OVLatentConsistencyModelPipeline,
prompt: str,
seed: int = 0,
width: int = 512,
height: int = 512,
guidance_scale: float = 8.0,
num_inference_steps: int = 4,
randomize_seed: bool = False,
num_images: int = 1,
progress=gr.Progress(track_tqdm=True),
):
seed = randomize_seed_fn(seed, randomize_seed)
torch.manual_seed(seed)
result = pipeline(
prompt=prompt,
width=width,
height=height,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
num_images_per_prompt=num_images,
lcm_origin_steps=50,
output_type="pil",
).images[0]
return result, seed
generate_original = partial(generate, ov_pipe)
generate_optimized = partial(generate, int8_pipe)
quantized_model_present = int8_pipe is not None
with gr.Blocks() as demo:
with gr.Group():
with gr.Row():
prompt = gr.Text(
label="Prompt",
show_label=False,
max_lines=1,
placeholder="Enter your prompt",
container=False,
)
with gr.Row():
with gr.Column():
result = gr.Image(label="Result (Original)" if quantized_model_present else "Image", type="pil")
run_button = gr.Button("Run")
with gr.Column(visible=quantized_model_present):
result_optimized = gr.Image(label="Result (Optimized)", type="pil", visible=quantized_model_present)
run_quantized_button = gr.Button(value="Run quantized", visible=quantized_model_present)
with gr.Accordion("Advanced options", open=False):
seed = gr.Slider(
label="Seed", minimum=0, maximum=MAX_SEED, step=1, value=0, randomize=True
)
randomize_seed = gr.Checkbox(label="Randomize seed across runs", value=True)
with gr.Row():
width = gr.Slider(
label="Width",
minimum=256,
maximum=MAX_IMAGE_SIZE,
step=32,
value=512,
)
height = gr.Slider(
label="Height",
minimum=256,
maximum=MAX_IMAGE_SIZE,
step=32,
value=512,
)
with gr.Row():
guidance_scale = gr.Slider(
label="Guidance scale for base",
minimum=2,
maximum=14,
step=0.1,
value=8.0,
)
num_inference_steps = gr.Slider(
label="Number of inference steps for base",
minimum=1,
maximum=8,
step=1,
value=4,
)
gr.Examples(
examples=examples,
inputs=prompt,
outputs=result,
cache_examples=False,
)
gr.on(
triggers=[
prompt.submit,
run_button.click,
],
fn=generate_original,
inputs=[
prompt,
seed,
width,
height,
guidance_scale,
num_inference_steps,
randomize_seed,
],
outputs=[result, seed],
)
if quantized_model_present:
gr.on(
triggers=[
prompt.submit,
run_quantized_button.click,
],
fn=generate_optimized,
inputs=[
prompt,
seed,
width,
height,
guidance_scale,
num_inference_steps,
randomize_seed,
],
outputs=[result_optimized, seed],
)
try:
demo.queue().launch(debug=False)
except Exception:
demo.queue().launch(share=True, debug=False)
# if you are launching remotely, specify server_name and server_port
# demo.launch(server_name='your server name', server_port='server port in int')
# Read more in the docs: https://gradio.app/docs/