INT8 推論に適した中間表現#
はじめに
OpenVINO ランタイム CPU および GPU デバイスは、低精度でモデルを推論できます。詳細は、モデル最適化ガイドを参照してください。
中間表現は、低精度の推論に適するように形成される必要があります。
このようなモデルは低精度 IR と呼ばれ、次の 2 つの方法で生成できます:
低精度推論用に事前トレーニングされたモデルの変換を使用します: TensorFlow モデル (
FakeQuantize操作を含む.pbモデルファイル)、量子化された TensorFlow Lite モデル、および ONNX 量子化モデル。TensorFlow および ONNX 量子化モデルは、ニューラル・ネットワーク圧縮フレームワークによって準備できます。
INT8 で実行される操作には、入力として FakeQuantize 操作が必要です。詳細については、FakeQuantize 操作の仕様を参照してください。
CPU 上の INT8 で畳み込み操作を実行するには、データ入力と重み入力の両方に入力操作として FakeQuantize が必要です。
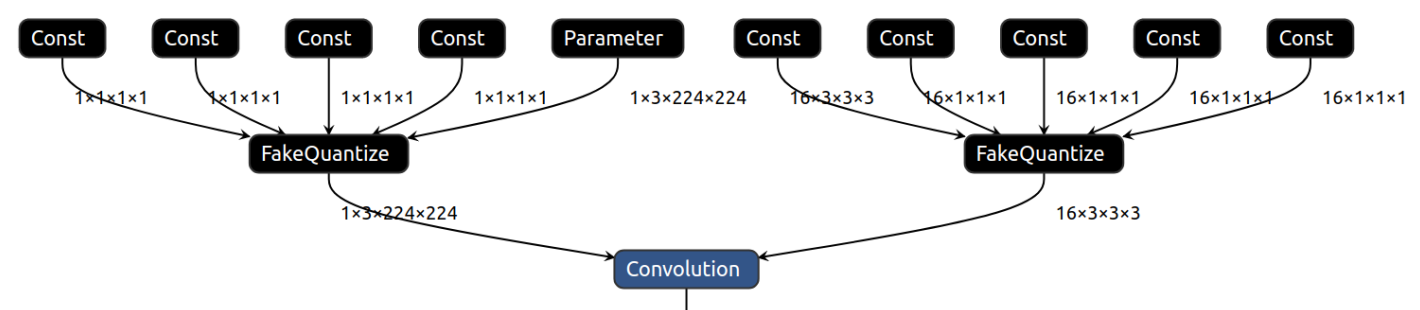
選択したプラグインが IR のすべての操作をサポートしている場合、低精度 IR は FP32 および FP16 推論にも適しています。低精度 IR と FP16 または FP32 IR の唯一の違いは、低精度 IR における FakeQuantize の存在です。低精度推論をサポートするプラグインは、推論中にこれらのサブグラフを認識し、量子化します。そうでないものは、FakeQuantize を含むすべての操作を FP32 または FP16 精度のまま実行します。
実際、FakeQuantize 操作が OpenVINO IR に存在する場合、モデル内の特定の操作を量子化する方法を推論デバイスに提案します。デバイスが対応する場合、提案を受け入れ、低精度推論を実行します。そうでない場合は、モデルを浮動小数点精度で実行します。
圧縮された低精度の重み#
Convolution や MatMul などの重み付き操作では、重みを浮動小数点定数としてグラフに保存し、その後 FakeQuantize 操作を実行します。FakeQuantize 操作に続く Constant は、FakeQuantize 操作のセマンティクスによりメモリーに関して最適化できます。結果として得られる重みサブグラフは、重みを低精度定数で保存します。これは、Convert 操作でアンパックされて浮動小数点に戻されます。重み圧縮により、FakeQuantize がオプションの減算および乗算操作に置き換えられ、出力は算術的に同じになり、重みの保存に必要なメモリーは 4 分の 1 になります。
圧縮された重みを使用した畳み込みの視覚化を参照してください:
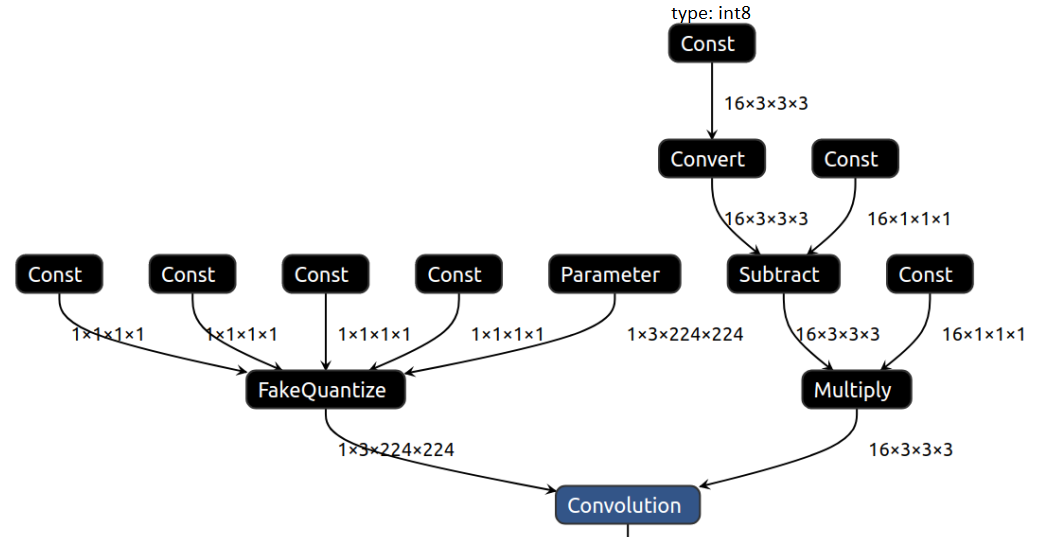
モデル・トランスフォーメーション API は、デフォルトで圧縮された IR を生成します。