DeepFloyd IF と OpenVINO™ による画像生成¶
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

DeepFloyd IF は、優れたフォトリアリズムと言語理解を実現する、高度なオープンソースのテキストから画像への変換モデルです。DeepFloyd IF は、フリーズされたテキスト・エンコーダーと 3 つのカスケードピクセル拡散モジュールで構成されています。テキストプロンプトに基づいて 64 x 64 ピクセルの画像を作成する基本モデルと、256 x 256 ピクセルと 1024 x 1024 ピクセルの解像度で画像を生成するように設計された 2 つの超解像度モデルです。モデルのすべてのステージでは、T5 トランスフォーマー上に構築された凍結テキスト・エンコーダーを使用してテキスト埋め込みを導出し、クロスアテンションとアテンション・プーリングで強化された UNet アーキテクチャーに渡します。
テキスト・エンコーダーの影響¶
深いテキストが理解を促します。生成パイプラインは、テキスト・エンコーダーとして T5-XXL-1.1 Large Language Model (LLM) を活用します。その知能は、多数のテキストと画像のクロスアテンション・レイヤーによって支えられており、プロンプトと生成された画像間の優れた整合を保証します。
生成された画像内のリアルなテキスト。DeepFloyd IF は、T5 モデルの機能を活用して、従来のほとんどのテキストから画像への変換モデルでは課題となっていた、明確な属性を持つオブジェクトとともに判読可能なテキスト表現を生成します。
DeepFloyd IF の特徴的な機能¶
まず第一に、DeepFloyd IF はモジュラーです。DeepFloyd IF パイプラインは、複数のニューラル・ネットワークの連続的な推論です。
つまり、カスケードになります。基本モデルは低解像度のサンプルを生成し、その後、超解像度モデルが画像をアップサンプリングして高解像度の結果を生成します。モデルは異なる解像度で個別にトレーニングされました。
DeepFloyd IF は拡散モデルを採用しています。拡散モデルは、画像などの対象サンプルを取得するために、ランダムなガウスノイズを段階的に除去するようにトレーニングされたマシンラーニング・システムです。拡散モデルは、画像データを生成するため最先端の結果を達成することが示されています。
そして、DeepFloyd IF はピクセル空間で動作します。潜在拡散モデル (例えば、Stable Diffusion) とは異なり、拡散はピクセルレベルで実装されます。
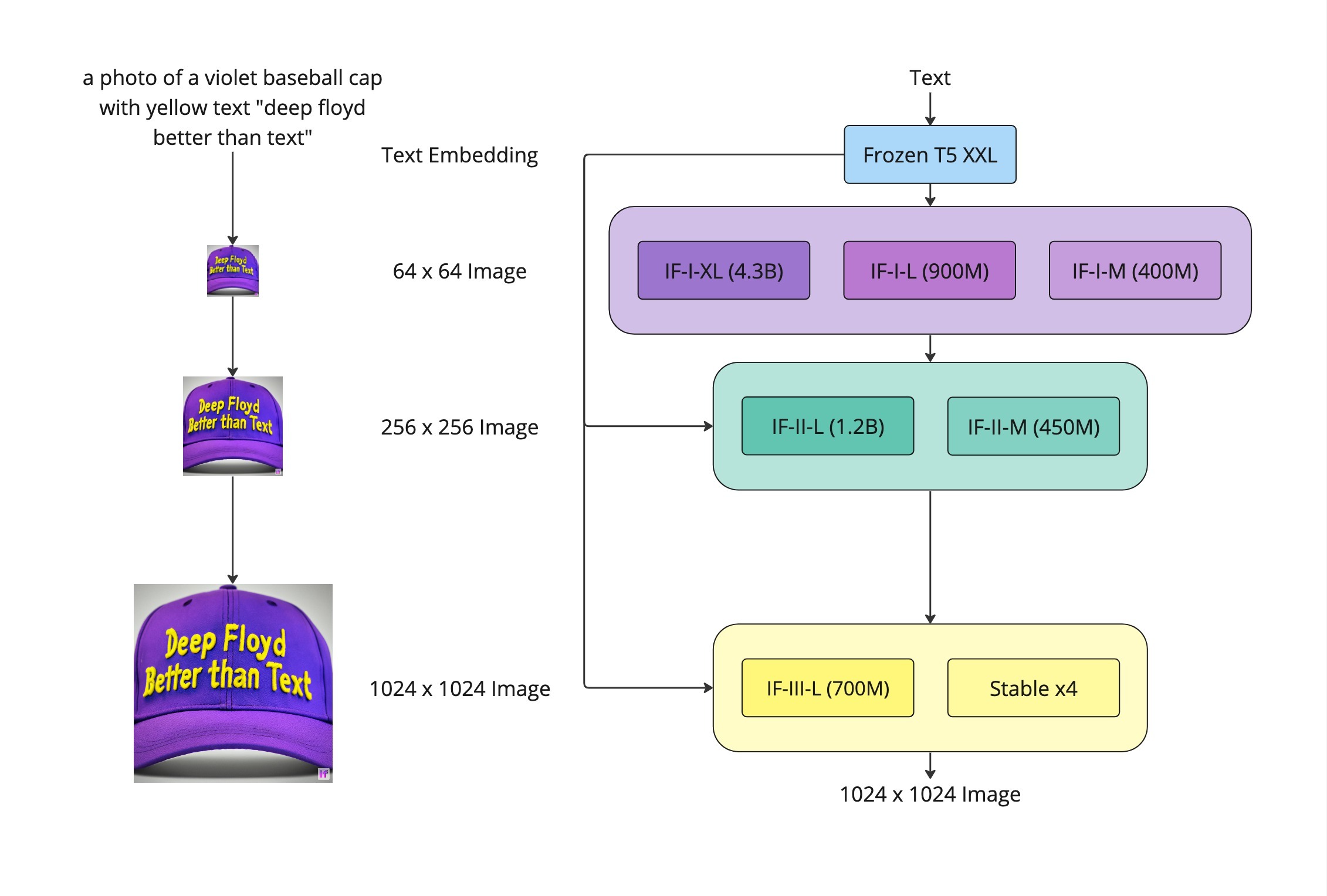
deepfloyd_if_scheme¶
上のグラフは、3 ステージの生成パイプラインを示しています。テキストプロンプトは、凍結された T5-XXL LLM を通過し、埋め込み空間でベクトルに変換されます。
ステージ 1: カスケードの最初の拡散モデルは、埋め込みベクトルを 64x64 の画像に変換します。DeepFloyd チームは、それぞれ異なるパラメーターを持つ 3 つのバージョンの基本モデルをトレーニングしました: IF-I 400M、IF-I 900M、および IF-I 4.3B。デフォルトでは最小のものが使用されますが、ユーザーはチェックポイント名を “DeepFloyd/IF-I-L-v1.0” または “DeepFloyd/IF-I-XL-v1.0” に自由に変更できます。
ステージ 2: 画像を拡大するため、最初の拡散モデルの出力に 2 つのテキスト条件付き超解像モデル (Efficient U-Net) が適用されます。最初は、サンプルを 64 x 64 ピクセルから 256 x 256 ピクセルの解像度にアップスケールします。このモデルにも、IF-II 400M (デフォルト) と IF-II 1.2B (チェックポイント名 “DeepFloyd/IF-II-L-v1.0”) など、複数のバージョンが利用できます。
ステージ 3: ステージ 2 と同じパスをたどり、画像を 1024 x 1024 ピクセルの解像度にアップスケールします。まだリリースされていないため、高解像度の結果を得るには従来の超解像度ネットワークを使用します。
目次¶
- 必要条件
- Diffusers ライブラリーの Stable Diffusion
- モデルを OpenVINO 中間表現 (IR) 形式に変換
- 1. テキスト・エンコーダーを変換
- 最初のピクセル拡散モジュールの Unet を変換
- 2番目のピクセル拡散モジュールを変換
- 推論パイプラインの準備
- テキストから画像への生成を実行
- Gradio で変換したパイプラインを試す
- 次のステップ
注:
この例では、約 27 GB のモデル・チェックポイントをダウンロードする必要がありますが、インターネット接続速度によっては時間がかかる場合があります。さらに、変換されたモデルはさらに 27 GB のディスク容量を消費します。
モデルを変換して推論を実行するには、少なくとも 32 GB の RAM が必要です。ノートブックがフリーズしたり、応答しなくなったりすることがあります。
モデル・チェックポイントにアクセスするには、Hugging Face アカウントが必要です。また、モデルのライセンスを明示的に受け入れるように求められます。
必要条件¶
必要なパッケージをインストールします。
# Set up requirements
%pip install -q --upgrade pip
%pip install -q transformers "diffusers>=0.16.1" accelerate safetensors sentencepiece huggingface_hub --extra-index-url https://download.pytorch.org/whl/cpu
%pip install -q "openvino>=2023.3.0" opencv-python
%pip install -q gradio
Note: you may need to restart the kernel to use updated packages.
DEPRECATION: distro-info 0.23ubuntu1 has a non-standard version number. pip 24.0 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of distro-info or contact the author to suggest that they release a version with a conforming version number. Discussion can be found at https://github.com/pypa/pip/issues/12063
DEPRECATION: python-debian 0.1.36ubuntu1 has a non-standard version number. pip 24.0 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of python-debian or contact the author to suggest that they release a version with a conforming version number. Discussion can be found at https://github.com/pypa/pip/issues/12063
Note: you may need to restart the kernel to use updated packages.
DEPRECATION: distro-info 0.23ubuntu1 has a non-standard version number. pip 24.0 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of distro-info or contact the author to suggest that they release a version with a conforming version number. Discussion can be found at https://github.com/pypa/pip/issues/12063
DEPRECATION: python-debian 0.1.36ubuntu1 has a non-standard version number. pip 24.0 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of python-debian or contact the author to suggest that they release a version with a conforming version number. Discussion can be found at https://github.com/pypa/pip/issues/12063
Note: you may need to restart the kernel to use updated packages.
DEPRECATION: distro-info 0.23ubuntu1 has a non-standard version number. pip 24.0 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of distro-info or contact the author to suggest that they release a version with a conforming version number. Discussion can be found at https://github.com/pypa/pip/issues/12063
DEPRECATION: python-debian 0.1.36ubuntu1 has a non-standard version number. pip 24.0 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of python-debian or contact the author to suggest that they release a version with a conforming version number. Discussion can be found at https://github.com/pypa/pip/issues/12063
Note: you may need to restart the kernel to use updated packages.
import gc
from pathlib import Path
from PIL import Image
from diffusers import DiffusionPipeline
import openvino as ov
import torch
from utils import TextEncoder, UnetFirstStage, UnetSecondStage, convert_result_to_image, download_omz_model
checkpoint_variant = 'fp16'
model_dtype = torch.float32
ir_input_type = ov.Type.f32
compress_to_fp16 = True
models_dir = Path('./models')
models_dir.mkdir(exist_ok=True)
encoder_ir_path = models_dir / 'encoder_ir.xml'
first_stage_unet_ir_path = models_dir / 'unet_ir_I.xml'
second_stage_unet_ir_path = models_dir / 'unet_ir_II.xml'
def pt_to_pil(images):
"""
Convert a torch image to a PIL image.
"""
images = (images / 2 + 0.5).clamp(0, 1)
images = images.cpu().permute(0, 2, 3, 1).float().numpy()
images = numpy_to_pil(images)
return images
def numpy_to_pil(images):
"""
Convert a numpy image or a batch of images to a PIL image.
"""
if images.ndim == 3:
images = images[None, ...]
images = (images * 255).round().astype("uint8")
if images.shape[-1] == 1:
# special case for grayscale (single channel) images
pil_images = [Image.fromarray(image.squeeze(), mode="L") for image in images]
else:
pil_images = [Image.fromarray(image) for image in images]
return pil_images
認証¶
IF チェックポイントにアクセスするには、ユーザーは認証トークンを提供する必要があります。
すでにトークンを所持する場合、次のセルのフォームに入力できます。そうでない場合は、次の手順に従ってください。
Hugging Face アカウントでログインしていることを確認してください。
DeepFloyd/IF-I-M-v1.0 のモデルカードのライセンスに同意します。
トークンを生成するには、このページに進んでください。
Add token as git credential? ボックスのチェックを外します。
from huggingface_hub import login
# Execute this cell to access the authentication form
login()
VBox(children=(HTML(value='<center> <imgnsrc=https://huggingface.co/front/assets/huggingface_logo-noborder.sv…
DeepFloyd Lab の IF を使用するには、Hugging Face Diffusers パッケージを使用します。Diffusers パッケージは DiffusionPipeline クラスを公開し、拡散モデルを使った実験を暗示します。以下のコードは、IF 構成を使用して DiffusionPipeline を作成する方法を示しています。
# Downloading the model weights may take some time. The approximate total checkpoints size is 27GB.
stage_1 = DiffusionPipeline.from_pretrained(
"DeepFloyd/IF-I-M-v1.0",
variant=checkpoint_variant,
torch_dtype=model_dtype
)
stage_2 = DiffusionPipeline.from_pretrained(
"DeepFloyd/IF-II-M-v1.0",
text_encoder=None,
variant=checkpoint_variant,
torch_dtype=model_dtype
)
model_index.json: 0%| | 0.00/604 [00:00<?, ?B/s]
safety_checker/model.safetensors not found
A mixture of fp16 and non-fp16 filenames will be loaded.
Loaded fp16 filenames:
[text_encoder/pytorch_model.fp16-00002-of-00002.bin, text_encoder/pytorch_model.fp16-00001-of-00002.bin, unet/diffusion_pytorch_model.fp16.bin]
Loaded non-fp16 filenames:
[safety_checker/pytorch_model.bin, watermarker/diffusion_pytorch_model.bin
If this behavior is not expected, please check your folder structure.
Fetching 16 files: 0%| | 0/16 [00:00<?, ?it/s]
text_encoder/config.json: 0%| | 0.00/741 [00:00<?, ?B/s]
scheduler/scheduler_config.json: 0%| | 0.00/454 [00:00<?, ?B/s]
(…)ature_extractor/preprocessor_config.json: 0%| | 0.00/518 [00:00<?, ?B/s]
safety_checker/config.json: 0%| | 0.00/4.57k [00:00<?, ?B/s]
(…)ncoder/pytorch_model.bin.index.fp16.json: 0%| | 0.00/21.0k [00:00<?, ?B/s]
tokenizer/special_tokens_map.json: 0%| | 0.00/2.20k [00:00<?, ?B/s]
tokenizer/tokenizer_config.json: 0%| | 0.00/2.50k [00:00<?, ?B/s]
unet/config.json: 0%| | 0.00/1.63k [00:00<?, ?B/s]
watermarker/config.json: 0%| | 0.00/74.0 [00:00<?, ?B/s]
pytorch_model.fp16-00002-of-00002.bin: 0%| | 0.00/1.58G [00:00<?, ?B/s]
pytorch_model.fp16-00001-of-00002.bin: 0%| | 0.00/9.96G [00:00<?, ?B/s]
pytorch_model.bin: 0%| | 0.00/1.22G [00:00<?, ?B/s]
diffusion_pytorch_model.fp16.bin: 0%| | 0.00/743M [00:00<?, ?B/s]
spiece.model: 0%| | 0.00/792k [00:00<?, ?B/s]
diffusion_pytorch_model.bin: 0%| | 0.00/16.3k [00:00<?, ?B/s]
Loading pipeline components...: 0%| | 0/7 [00:00<?, ?it/s]
Loading checkpoint shards: 0%| | 0/2 [00:00<?, ?it/s]
You are using the default legacy behaviour of the <class 'transformers.models.t5.tokenization_t5.T5Tokenizer'>. This is expected, and simply means that the legacy (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set legacy=False. This should only be set if you understand what it means, and thouroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 A mixture of fp16 and non-fp16 filenames will be loaded. Loaded fp16 filenames: [unet/diffusion_pytorch_model.fp16.safetensors, text_encoder/model.fp16-00002-of-00002.safetensors, text_encoder/model.fp16-00001-of-00002.safetensors, safety_checker/model.fp16.safetensors] Loaded non-fp16 filenames: [watermarker/diffusion_pytorch_model.safetensors If this behavior is not expected, please check your folder structure.
Loading pipeline components...: 0%| | 0/7 [00:00<?, ?it/s]
モデル変換 API を使用すると、PyTorch モデルを直接変換できます。ov.convert_model メソッドを使用して、モデルの OpenVINO IR バージョンを取得します。これには、モデル・オブジェクト、モデルトレースの入力データ、およびその他の関連パラメーターを提供する必要があります。
パイプラインは次の 3 つの重要な部分で構成されます。
ユーザープロンプトを、拡散モデルが理解できる潜在空間内のベクトルに変換するテキスト・エンコーダー。
潜在画像表現を段階的にノイズ除去するステージ 1 U-Net。
前のステップからの低解像度の出力と潜在表現を取得して、結果の画像をアップスケールするステージ 2 U-Net。
各パーツを変換してみましょう。
テキスト・エンコーダーは、“森の中の鹿の角を持つ虹色のフクロウの超クローズアップ・カラー写真ポートレート” などの入力プロンプトを、次のステージの U-Net に送ることができる埋め込み空間に変換する役割を担います。通常、これは、入力トークンのシーケンスをテキスト埋め込みのシーケンスにマッピングするトランスフォーマー・ベースのエンコーダーです。
テキスト・エンコーダーの入力は、トークナイザーによって処理され、モデルが受け入れる最大長にパディングされたテキストのトークン・インデックスを含むテンソル input_ids で構成されます。
convert_model メソッドに渡される input 引数に関する注: convert_model は、入力 shape 引数および/または PyTorch 固有の example_input 引数を使用して呼び出すことができます。ただし、この場合は、タプルを使用してモデル入力を記述し、それを入力引数として提供しました。このソリューションはフレームワークに依存しないソリューションを提供し、複雑な入力の定義を可能にします。入力名、形状、タイプ、値を 1 つのタプル内で指定できるため、柔軟性が向上します。
if not encoder_ir_path.exists():
encoder_ir = ov.convert_model(
stage_1.text_encoder,
example_input=torch.ones(1, 77).long(),
input=((1, 77), ov.Type.i64),
)
# Serialize the IR model to disk, we will load it at inference time
ov.save_model(encoder_ir, encoder_ir_path, compress_to_fp16=compress_to_fp16)
del encoder_ir
del stage_1.text_encoder
gc.collect();
U-Net モデルは、テキスト・エンコーダーの隠れ状態に基づいて、潜在画像表現のノイズを段階的に除去します。
U-Net モデルには 3 つの入力があります。
sample- 前のステップからの潜在画像サンプル。生成プロセスはまだ開始されていないため、ランダムノイズを使用します。timestep- 現在のスケジューラー・ステップ。encoder_hidden_state- テキスト・エンコーダーの非表示状態。モデルは次のステップのサンプルの状態を予測します。
カスケードの最初の拡散モジュールは、64 x 64 ピクセルの低解像度画像を生成します。
if not first_stage_unet_ir_path.exists():
unet_1_ir = ov.convert_model(
stage_1.unet,
example_input=(torch.ones(2, 3, 64, 64), torch.tensor(1).int(), torch.ones(2, 77, 4096)),
input=[((2, 3, 64, 64), ir_input_type), ((), ov.Type.i32), ((2, 77, 4096), ir_input_type)],
)
ov.save_model(unet_1_ir, first_stage_unet_ir_path, compress_to_fp16=compress_to_fp16)
del unet_1_ir
stage_1_config = stage_1.unet.config
del stage_1.unet
gc.collect();
/home/ea/.local/lib/python3.8/site-packages/diffusers/models/unet_2d_condition.py:878: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if dim % default_overall_up_factor != 0:
/home/ea/.local/lib/python3.8/site-packages/diffusers/models/resnet.py:265: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert hidden_states.shape[1] == self.channels
/home/ea/.local/lib/python3.8/site-packages/diffusers/models/resnet.py:271: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert hidden_states.shape[1] == self.channels
/home/ea/.local/lib/python3.8/site-packages/diffusers/models/resnet.py:739: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if hidden_states.shape[0] >= 64:
/home/ea/.local/lib/python3.8/site-packages/diffusers/models/resnet.py:173: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert hidden_states.shape[1] == self.channels
/home/ea/.local/lib/python3.8/site-packages/diffusers/models/resnet.py:186: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if hidden_states.shape[0] >= 64:
カスケードの 2 番目の拡散モジュールは、256 x 256 ピクセルの画像を生成します。
第 2 ステージのパイプラインは、双線形補間を使用して、前のステージで生成された 64x64 イメージをより高い 256x256 解像度にアップスケールします。次に、エンコードされたユーザープロンプトを考慮して画像のノイズを除去します。
if not second_stage_unet_ir_path.exists():
unet_2_ir = ov.convert_model(
stage_2.unet,
example_input=(
torch.ones(2, 6, 256, 256),
torch.tensor(1).int(),
torch.ones(2, 77, 4096),
torch.ones(2).int(),
),
input=[
((2, 6, 256, 256), ir_input_type),
((), ov.Type.i32),
((2, 77, 4096), ir_input_type),
((2,), ov.Type.i32),
],
)
ov.save_model(unet_2_ir, second_stage_unet_ir_path, compress_to_fp16=compress_to_fp16)
del unet_2_ir
stage_2_config = stage_2.unet.config
del stage_2.unet
gc.collect();
この例では、ソース・リポジトリーの元のパイプラインが再利用されます。これを実現するために、OpenVINO モデルを Pytorch モデルに置き換えてパイプラインにシームレスに統合できるようにするアダプタークラスが作成されました。
core = ov.Core()
推論デバイスの選択¶
OpenVINO を使用して推論を実行するためにドロップダウン・リストからデバイスを選択します。
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='AUTO',
description='Device:',
disabled=False,
)
device
Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')
これで、画像生成用のテキストプロンプトを設定し、推論パイプラインを実行できます。オプションで、潜在状態初期化用のランダム・ジェネレーター・シードを変更し、指定されたプロンプトに対して生成される画像数を調整することもできます。
テキスト・エンコーダー推論¶
GPU 上の FP16 でモデルを推論すると、パフォーマンスが大幅に向上し、必要なメモリーが削減されますが、一部のモデルでは精度が低下する可能性があります。特に stage_1.text_encoder はこれが顕著です。この影響を回避するには、一部のレイヤーの精度を調整する必要があります。partially_upcast_nodes_to_fp32 ヘルパーは、精度に最も敏感なノードのみを FP32 にアップキャストし、ほとんどのノードが FP16 のままで精度が回復されるようにします。これにより、推論パフォーマンスは完全に FP16 と同等になります。
# Fetch `model_upcast_utils` which helps to restore accuracy when inferred on GPU
import urllib.request
urllib.request.urlretrieve(
url='https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/main/notebooks/utils/model_upcast_utils.py',
filename='model_upcast_utils.py'
)
from model_upcast_utils import is_model_partially_upcasted, partially_upcast_nodes_to_fp32
encoder_ov_model = core.read_model(encoder_ir_path)
if 'GPU' in core.available_devices and not is_model_partially_upcasted(encoder_ov_model):
example_input_prompt = 'ultra close color photo portrait of rainbow owl with deer horns in the woods'
text_inputs = stage_1.tokenizer(example_input_prompt, max_length=77, padding="max_length", return_tensors="np")
upcasted_ov_model = partially_upcast_nodes_to_fp32(encoder_ov_model, text_inputs.input_ids, upcast_ratio=0.05,
operation_types=["MatMul"], batch_size=10)
del encoder_ov_model
gc.collect()
import os
os.remove(encoder_ir_path)
os.remove(str(encoder_ir_path).replace('.xml', '.bin'))
ov.save_model(upcasted_ov_model, encoder_ir_path, compress_to_fp16=compress_to_fp16)
prompt = 'ultra close color photo portrait of rainbow owl with deer horns in the woods'
negative_prompt = 'blurred unreal uncentered occluded'
# Initialize TextEncoder wrapper class
stage_1.text_encoder = TextEncoder(encoder_ir_path, dtype=model_dtype, device=device.value)
print('The model has been loaded')
# Generate text embeddings
prompt_embeds, negative_embeds = stage_1.encode_prompt(prompt, negative_prompt=negative_prompt)
# Delete the encoder to free up memory
del stage_1.text_encoder.encoder_openvino
gc.collect()
The model has been loaded
/home/ea/.local/lib/python3.8/site-packages/diffusers/configuration_utils.py:135: FutureWarning: Accessing config attribute unet directly via 'IFPipeline' object attribute is deprecated. Please access 'unet' over 'IFPipeline's config object instead, e.g. 'scheduler.config.unet'.
deprecate("direct config name access", "1.0.0", deprecation_message, standard_warn=False)
CPU times: user 32.9 s, sys: 6.82 s, total: 39.8 s
Wall time: 11.2 s
0
第 1 ステージの拡散ブロック推論¶
# Changing the following parameters will affect the model output
# Note that increasing the number of diffusion steps will increase the inference time linearly.
RANDOM_SEED = 42
N_DIFFUSION_STEPS = 50
# Initialize the First Stage UNet wrapper class
stage_1.unet = UnetFirstStage(
first_stage_unet_ir_path,
stage_1_config,
dtype=model_dtype,
device=device.value
)
print('The model has been loaded')
# Fix PRNG seed
generator = torch.manual_seed(RANDOM_SEED)
# Inference
image = stage_1(prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds,
generator=generator, output_type="pt", num_inference_steps=N_DIFFUSION_STEPS).images
# Delete the model to free up memory
del stage_1.unet.unet_openvino
gc.collect()
# Show the image
pt_to_pil(image)[0]
The model has been loaded
0%| | 0/50 [00:00<?, ?it/s]
CPU times: user 4min 14s, sys: 3.04 s, total: 4min 17s
Wall time: 17.3 s

第 2 ステージの拡散ブロック推論¶
# Initialize the Second Stage UNet wrapper class
stage_2.unet = UnetSecondStage(
second_stage_unet_ir_path,
stage_2_config,
dtype=model_dtype,
device=device.value
)
print('The model has been loaded')
image = stage_2(
image=image, prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds,
generator=generator, output_type="pt", num_inference_steps=20).images
# Delete the model to free up memory
del stage_2.unet.unet_openvino
gc.collect()
# Show the image
pil_image = pt_to_pil(image)[0]
pil_image
The model has been loaded
0%| | 0/20 [00:00<?, ?it/s]
CPU times: user 11min 41s, sys: 5.08 s, total: 11min 46s
Wall time: 45.4 s

第 3 ステージの拡散ブロック¶
画像をより高い解像度 (1024x1024 ピクセル) にアップスケールする最終ブロックは、DeepFloyd ではまだリリースされていません。
生成された画像を超解像ネットワークを使用して拡大¶
3 番目のステージはまだ正式にリリースされていませんが、例 #202 の超解像ネットワークを使用して、低解像度の結果を強化します。
注意: このステップは、リリース時に第 3 IF ステージに置き換えられます。
# Temporary requirement
%pip install -q matplotlib
DEPRECATION: distro-info 0.23ubuntu1 has a non-standard version number. pip 24.0 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of distro-info or contact the author to suggest that they release a version with a conforming version number. Discussion can be found at https://github.com/pypa/pip/issues/12063
DEPRECATION: python-debian 0.1.36ubuntu1 has a non-standard version number. pip 24.0 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of python-debian or contact the author to suggest that they release a version with a conforming version number. Discussion can be found at https://github.com/pypa/pip/issues/12063
Note: you may need to restart the kernel to use updated packages.
超解像モデルの重みをダウンロード¶
import cv2
import numpy as np
# 1032: 4x superresolution, 1033: 3x superresolution
model_name = 'single-image-super-resolution-1032'
download_omz_model(model_name, models_dir)
sr_model_xml_path = models_dir / f'{model_name}.xml'
models/single-image-super-resolution-1032.xml: 0%| | 0.00/89.3k [00:00<?, ?B/s]
models/single-image-super-resolution-1032.bin: 0%| | 0.00/58.4k [00:00<?, ?B/s]
モデルの入力を再形成¶
モデルの入力を再形成する必要があります。これは、IR モデルが異なるターゲット入力解像度で変換されたことによるものです。2 番目の IF ステージは 256 x 256 ピクセルの画像を返します。4 倍超解像度モデルを使用すると、ターゲット画像のサイズは 1024 x 1024 ピクセルになります。
model = core.read_model(model=sr_model_xml_path)
model.reshape({
0: [1, 3, 256, 256],
1: [1, 3, 1024, 1024]
})
compiled_sr_model = core.compile_model(model=model, device_name=device.value)
入力画像を準備してモデルを実行¶
original_image = np.array(pil_image)
bicubic_image = cv2.resize(
src=original_image, dsize=(1024, 1024), interpolation=cv2.INTER_CUBIC
)
# Reshape the images from (H,W,C) to (N,C,H,W) as expected by the model.
input_image_original = np.expand_dims(original_image.transpose(2, 0, 1), axis=0)
input_image_bicubic = np.expand_dims(bicubic_image.transpose(2, 0, 1), axis=0)
# Model Inference
result = compiled_sr_model(
[input_image_original, input_image_bicubic]
)[compiled_sr_model.output(0)]
結果を表示¶
img = convert_result_to_image(result)
img

Gradio で変換したパイプラインを試す¶
以下のデモアプリは Gradio パッケージを使用して作成されています。
# Build up the pipeline
stage_1.text_encoder = TextEncoder(encoder_ir_path, dtype=model_dtype, device=device.value)
print('The model has been loaded')
stage_1.unet = UnetFirstStage(
first_stage_unet_ir_path,
stage_1_config,
dtype=model_dtype,
device=device.value
)
print('The Stage-1 UNet has been loaded')
stage_2.unet = UnetSecondStage(
second_stage_unet_ir_path,
stage_2_config,
dtype=model_dtype,
device=device.value
)
print('The Stage-2 UNet has been loaded')
generator = torch.manual_seed(RANDOM_SEED)
# Combine the models' calls into a single `_generate` function
def _generate(prompt, negative_prompt):
# Text encoder inference
prompt_embeds, negative_embeds = stage_1.encode_prompt(prompt, negative_prompt=negative_prompt)
# Stage-1 UNet Inference
image = stage_1(
prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds,
generator=generator, output_type="pt", num_inference_steps=N_DIFFUSION_STEPS
).images
# Stage-2 UNet Inference
image = stage_2(
image=image, prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds,
generator=generator, output_type="pt", num_inference_steps=20
).images
# Infer Super Resolution model
original_image = np.array(pt_to_pil(image)[0])
bicubic_image = cv2.resize(
src=original_image, dsize=(1024, 1024), interpolation=cv2.INTER_CUBIC
)
# Reshape the images from (H,W,C) to (N,C,H,W) as expected by the model.
input_image_original = np.expand_dims(original_image.transpose(2, 0, 1), axis=0)
input_image_bicubic = np.expand_dims(bicubic_image.transpose(2, 0, 1), axis=0)
# Model Inference
result = compiled_sr_model(
[input_image_original, input_image_bicubic]
)[compiled_sr_model.output(0)]
return convert_result_to_image(result)
The model has been loaded
The Stage-1 UNet has been loaded
The Stage-2 UNet has been loaded
import gradio as gr
demo = gr.Interface(
_generate,
inputs=[
gr.Textbox(label="Text Prompt"),
gr.Textbox(label="Negative Text Prompt"),
],
outputs=[
"image"
],
examples=[
[
"ultra close color photo portrait of rainbow owl with deer horns in the woods",
"blurred unreal uncentered occluded"
],
[
"A scaly mischievous dragon is driving the car in a street art style",
"blurred uncentered occluded"
],
],
)
try:
demo.queue().launch(debug=False)
except Exception:
demo.queue().launch(share=True, debug=False)
# If you are launching remotely, specify server_name and server_port
# EXAMPLE: `demo.launch(server_name='your server name', server_port='server port in int')`
# To learn more please refer to the Gradio docs: https://gradio.app/docs/
次のステップ¶
238-deep-floyd-if-optimize ノートブックを開き、NNCF のトレーニング後の量子化 API を使用してステージ 1 およびステージ 2 の U-Net モデルを量子化し、テキスト・エンコーダーの重みを圧縮します。次に、変換および最適化された OpenVINO モデルを比較します。