FreeVC と OpenVINO™ による高品質のテキストフリーのワンショット音声変換¶
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

FreeVC を使用すると、テキスト・アノテーションを付けず、言語コンテンツを変更することなく、ソースの話者の音声をターゲットスタイルに変更できます。
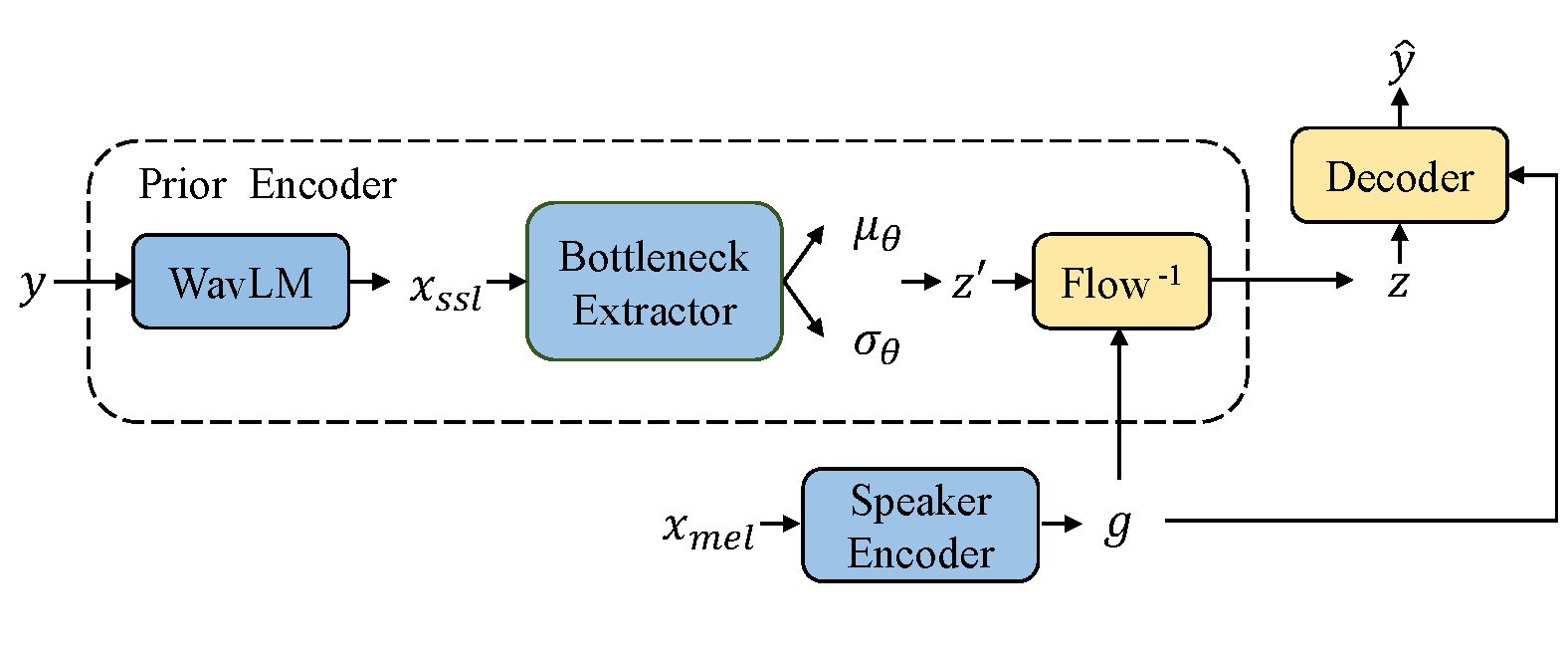
以下の図は、推論用の FreeVC のモデル・アーキテクチャーを示しています。このノートでは推論部分のみに焦点を当てます。優先エンコーダー、スピーカー・エンコーダー、デコーダの 3 つの主要な部分があります。優先エンコーダには、WavLM モデル、ボトルネック抽出器、および正規化フローが含まれています。詳細については、この文書を参照してください。
推論¶
FreeVC は、コマンドライン・インターフェイスを使用し、CUDA のみを使用することを提案します。このノートブックでは、CUDA デバイスを使用せずに Python で FreeVC を使用する方法を示します。これは次の手順で構成されます。
モデルをダウンロードして準備します。
推論を実行します。
モデルを OpenVINO 中間表現に変換します。
OpenVINO の IR モデルのみを使用した推論を実行します。
目次¶
必要条件¶
この手順は手動で行うことも、ノートブックの実行中に自動的に実行されることもありますが、必要最小限の範囲で実行されます。
- このリポジトリーのクローンを作成します: git clone https://github.com/OlaWod/FreeVC.git。
- WavLM-Large をダウンロードし、
FreeVC/wavlm/ディレクトリーの下に置きます。 - VCTK データセットをダウンロードできます。この例では、Hugging Face FreeVC の例から 2 つだけをダウンロードします。
- 事前トレーニングされたモデルをダウンロードし、ディレクトリー ‘checkpoints’ の下に置きます (この例では、
freevc.pthのみが必要です)。
追加の要件をインストールします。
%pip install -q "openvino>=2023.3.0" "librosa>=0.8.1" "webrtcvad==2.0.10" gradio "torch>=2.1" torchvision --extra-index-url https://download.pytorch.org/whl/cpu
DEPRECATION: pytorch-lightning 1.6.5 has a non-standard dependency specifier torch>=1.8.*. pip 24.1 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of pytorch-lightning or contact the author to suggest that they release a version with a conforming dependency specifiers. Discussion can be found at https://github.com/pypa/pip/issues/12063
Note: you may need to restart the kernel to use updated packages.
FreeVC がインストールされているかどうかを確認し、そのパスを sys.path に追加します。
from pathlib import Path
import sys
free_vc_repo = 'FreeVC'
if not Path(free_vc_repo).exists():
!git clone https://github.com/OlaWod/FreeVC.git
sys.path.append(free_vc_repo)
Cloning into 'FreeVC'...
remote: Enumerating objects: 131, done.[K
remote: Counting objects: 1% (1/65)[K
remote: Enumerating objects: 131, done.[K
remote: Counting objects: 1% (1/65)[K
remote: Counting objects: 3% (2/65)[K
remote: Counting objects: 4% (3/65)[K
remote: Counting objects: 6% (4/65)[K
remote: Counting objects: 7% (5/65)[K
remote: Counting objects: 9% (6/65)[K
remote: Counting objects: 10% (7/65)[K
remote: Counting objects: 12% (8/65)[K
remote: Counting objects: 13% (9/65)[K
remote: Counting objects: 15% (10/65)[K
remote: Counting objects: 16% (11/65)[K
remote: Counting objects: 18% (12/65)[K
remote: Counting objects: 20% (13/65)[K
remote: Counting objects: 21% (14/65)[K
remote: Counting objects: 23% (15/65)[K
remote: Counting objects: 24% (16/65)[K
remote: Counting objects: 26% (17/65)[K
remote: Counting objects: 27% (18/65)[K
remote: Counting objects: 29% (19/65)[K
remote: Counting objects: 30% (20/65)[K
remote: Counting objects: 32% (21/65)[K
remote: Counting objects: 33% (22/65)[K
remote: Counting objects: 35% (23/65)[K
remote: Counting objects: 36% (24/65)[K
remote: Counting objects: 38% (25/65)[K
remote: Counting objects: 40% (26/65)[K
remote: Counting objects: 41% (27/65)[K
remote: Counting objects: 43% (28/65)[K
remote: Counting objects: 44% (29/65)[K
remote: Counting objects: 46% (30/65)[K
remote: Counting objects: 47% (31/65)[K
remote: Counting objects: 49% (32/65)[K
remote: Counting objects: 50% (33/65)[K
remote: Counting objects: 52% (34/65)[K
remote: Counting objects: 53% (35/65)[K
remote: Counting objects: 55% (36/65)[K
remote: Counting objects: 56% (37/65)[K
remote: Counting objects: 58% (38/65)[K
remote: Counting objects: 60% (39/65)[K
remote: Counting objects: 61% (40/65)[K
remote: Counting objects: 63% (41/65)[K
remote: Counting objects: 64% (42/65)[K
remote: Counting objects: 66% (43/65)[K
remote: Counting objects: 67% (44/65)[K
remote: Counting objects: 69% (45/65)[K
remote: Counting objects: 70% (46/65)[K
remote: Counting objects: 72% (47/65)[K
remote: Counting objects: 73% (48/65)[K
remote: Counting objects: 75% (49/65)[K
remote: Counting objects: 76% (50/65)[K
remote: Counting objects: 78% (51/65)[K
remote: Counting objects: 80% (52/65)[K
remote: Counting objects: 81% (53/65)[K
remote: Counting objects: 83% (54/65)[K
remote: Counting objects: 84% (55/65)[K
remote: Counting objects: 86% (56/65)[K
remote: Counting objects: 87% (57/65)[K
remote: Counting objects: 89% (58/65)[K
remote: Counting objects: 90% (59/65)[K
remote: Counting objects: 92% (60/65)[K
remote: Counting objects: 93% (61/65)[K
remote: Counting objects: 95% (62/65)[K
remote: Counting objects: 96% (63/65)[K
remote: Counting objects: 98% (64/65)[K
remote: Counting objects: 100% (65/65)[K
remote: Counting objects: 100% (65/65), done.[K
remote: Compressing objects: 2% (1/41)[K
remote: Compressing objects: 4% (2/41)[K
remote: Compressing objects: 7% (3/41)[K
remote: Compressing objects: 9% (4/41)[K
remote: Compressing objects: 12% (5/41)[K
remote: Compressing objects: 14% (6/41)[K
remote: Compressing objects: 17% (7/41)[K
remote: Compressing objects: 19% (8/41)[K
remote: Compressing objects: 21% (9/41)[K
remote: Compressing objects: 24% (10/41)[K
remote: Compressing objects: 26% (11/41)[K
remote: Compressing objects: 29% (12/41)[K
remote: Compressing objects: 31% (13/41)[K
remote: Compressing objects: 34% (14/41)[K
remote: Compressing objects: 36% (15/41)[K
remote: Compressing objects: 39% (16/41)[K
remote: Compressing objects: 41% (17/41)[K
remote: Compressing objects: 43% (18/41)[K
remote: Compressing objects: 46% (19/41)[K
remote: Compressing objects: 48% (20/41)[K
remote: Compressing objects: 51% (21/41)[K
remote: Compressing objects: 53% (22/41)[K
remote: Compressing objects: 56% (23/41)[K
remote: Compressing objects: 58% (24/41)[K
remote: Compressing objects: 60% (25/41)[K
remote: Compressing objects: 63% (26/41)[K
remote: Compressing objects: 65% (27/41)[K
remote: Compressing objects: 68% (28/41)[K
remote: Compressing objects: 70% (29/41)[K
remote: Compressing objects: 73% (30/41)[K
remote: Compressing objects: 75% (31/41)[K
remote: Compressing objects: 78% (32/41)[K
remote: Compressing objects: 80% (33/41)[K
remote: Compressing objects: 82% (34/41)[K
remote: Compressing objects: 85% (35/41)[K
remote: Compressing objects: 87% (36/41)[K
remote: Compressing objects: 90% (37/41)[K
remote: Compressing objects: 92% (38/41)[K
remote: Compressing objects: 95% (39/41)[K
remote: Compressing objects: 97% (40/41)[K
remote: Compressing objects: 100% (41/41)[K
remote: Compressing objects: 100% (41/41), done.[K
Receiving objects: 0% (1/131)
Receiving objects: 1% (2/131)
Receiving objects: 2% (3/131)
Receiving objects: 3% (4/131)
Receiving objects: 4% (6/131)
Receiving objects: 5% (7/131)
Receiving objects: 6% (8/131)
Receiving objects: 7% (10/131)
Receiving objects: 8% (11/131)
Receiving objects: 9% (12/131)
Receiving objects: 10% (14/131)
Receiving objects: 11% (15/131)
Receiving objects: 12% (16/131)
Receiving objects: 13% (18/131)
Receiving objects: 14% (19/131)
Receiving objects: 15% (20/131)
Receiving objects: 16% (21/131)
Receiving objects: 17% (23/131)
Receiving objects: 18% (24/131)
Receiving objects: 19% (25/131)
Receiving objects: 20% (27/131)
Receiving objects: 21% (28/131)
Receiving objects: 22% (29/131)
Receiving objects: 23% (31/131)
Receiving objects: 24% (32/131)
Receiving objects: 25% (33/131)
Receiving objects: 26% (35/131)
Receiving objects: 27% (36/131)
Receiving objects: 28% (37/131)
Receiving objects: 29% (38/131)
Receiving objects: 30% (40/131)
Receiving objects: 31% (41/131)
Receiving objects: 32% (42/131)
Receiving objects: 33% (44/131)
Receiving objects: 34% (45/131)
Receiving objects: 34% (45/131), 3.43 MiB | 3.36 MiB/s
Receiving objects: 34% (45/131), 7.09 MiB | 3.45 MiB/s
Receiving objects: 34% (45/131), 10.62 MiB | 3.46 MiB/s
Receiving objects: 34% (45/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 35% (46/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 36% (48/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 37% (49/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 38% (50/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 39% (52/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 40% (53/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 41% (54/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 42% (56/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 43% (57/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 44% (58/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 45% (59/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 46% (61/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 47% (62/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 48% (63/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 49% (65/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 50% (66/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 51% (67/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 52% (69/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 53% (70/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 54% (71/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 55% (73/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 56% (74/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 57% (75/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 58% (76/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 59% (78/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 60% (79/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 61% (80/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 62% (82/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 63% (83/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 64% (84/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 65% (86/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 66% (87/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 67% (88/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 68% (90/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 69% (91/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 70% (92/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 71% (94/131), 14.22 MiB | 3.47 MiB/s
remote: Total 131 (delta 39), reused 24 (delta 24), pack-reused 66[K
Receiving objects: 72% (95/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 73% (96/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 74% (97/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 75% (99/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 76% (100/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 77% (101/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 78% (103/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 79% (104/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 80% (105/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 81% (107/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 82% (108/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 83% (109/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 84% (111/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 85% (112/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 86% (113/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 87% (114/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 88% (116/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 89% (117/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 90% (118/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 91% (120/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 92% (121/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 93% (122/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 94% (124/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 95% (125/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 96% (126/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 97% (128/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 98% (129/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 99% (130/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 100% (131/131), 14.22 MiB | 3.47 MiB/s
Receiving objects: 100% (131/131), 15.28 MiB | 3.49 MiB/s, done.
Resolving deltas: 0% (0/43)
Resolving deltas: 20% (9/43)
Resolving deltas: 25% (11/43)
Resolving deltas: 51% (22/43)
Resolving deltas: 62% (27/43)
Resolving deltas: 67% (29/43)
Resolving deltas: 74% (32/43)
Resolving deltas: 79% (34/43)
Resolving deltas: 81% (35/43)
Resolving deltas: 86% (37/43)
Resolving deltas: 88% (38/43)
Resolving deltas: 97% (42/43)
Resolving deltas: 100% (43/43)
Resolving deltas: 100% (43/43), done.
sys.path.append("../utils")
from notebook_utils import download_file
wavlm_large_dir_path = Path('FreeVC/wavlm')
wavlm_large_path = wavlm_large_dir_path / 'WavLM-Large.pt'
if not wavlm_large_path.exists():
download_file(
'https://valle.blob.core.windows.net/share/wavlm/WavLM-Large.pt?sv=2020-08-04&st=2023-03-01T07%3A51%3A05Z&se=2033-03-02T07%3A51%3A00Z&sr=c&sp=rl&sig=QJXmSJG9DbMKf48UDIU1MfzIro8HQOf3sqlNXiflY1I%3D',
directory=wavlm_large_dir_path
)
FreeVC/wavlm/WavLM-Large.pt: 0%| | 0.00/1.18G [00:00<?, ?B/s]
freevc_chpt_dir = Path('checkpoints')
freevc_chpt_name = 'freevc.pth'
freevc_chpt_path = freevc_chpt_dir / freevc_chpt_name
if not freevc_chpt_path.exists():
download_file(
f'https://storage.openvinotoolkit.org/repositories/openvino_notebooks/models/freevc/{freevc_chpt_name}',
directory=freevc_chpt_dir
)
checkpoints/freevc.pth: 0%| | 0.00/451M [00:00<?, ?B/s]
audio1_name = 'p225_001.wav'
audio1_url = f'https://huggingface.co/spaces/OlaWod/FreeVC/resolve/main/{audio1_name}'
audio2_name = 'p226_002.wav'
audio2_url = f'https://huggingface.co/spaces/OlaWod/FreeVC/resolve/main/{audio2_name}'
if not Path(audio1_name).exists():
download_file(audio1_url)
if not Path(audio2_name).exists():
download_file(audio2_url)
p225_001.wav: 0%| | 0.00/50.8k [00:00<?, ?B/s]
p226_002.wav: 0%| | 0.00/135k [00:00<?, ?B/s]
インポートと設定¶
import logging
import os
import time
import librosa
import numpy as np
import torch
from scipy.io.wavfile import write
from tqdm import tqdm
import openvino as ov
import utils
from models import SynthesizerTrn
from speaker_encoder.voice_encoder import SpeakerEncoder
from wavlm import WavLM, WavLMConfig
logger = logging.getLogger()
logger.setLevel(logging.CRITICAL)
CUDA を除外するために utils から関数 get_model を再定義します。
def get_cmodel():
checkpoint = torch.load(wavlm_large_path)
cfg = WavLMConfig(checkpoint['cfg'])
cmodel = WavLM(cfg)
cmodel.load_state_dict(checkpoint['model'])
cmodel.eval()
return cmodel
モデルを初期化します。
hps = utils.get_hparams_from_file('FreeVC/configs/freevc.json')
os.makedirs('outputs/freevc', exist_ok=True)
net_g = SynthesizerTrn(
hps.data.filter_length // 2 + 1,
hps.train.segment_size // hps.data.hop_length,
**hps.model
)
utils.load_checkpoint(freevc_chpt_path, net_g, optimizer=None, strict=True)
cmodel = get_cmodel()
smodel = SpeakerEncoder('FreeVC/speaker_encoder/ckpt/pretrained_bak_5805000.pt', device='cpu')
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/torch/nn/utils/weight_norm.py:28: UserWarning: torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.
warnings.warn("torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.")
Loaded the voice encoder model on cpu in 0.00 seconds.
データセットの設定を読み取ります。
srcs = [audio1_name, audio2_name]
tgts = [audio2_name, audio1_name]
推論を実行します。
with torch.no_grad():
for line in tqdm(zip(srcs, tgts)):
src, tgt = line
# tgt
wav_tgt, _ = librosa.load(tgt, sr=hps.data.sampling_rate)
wav_tgt, _ = librosa.effects.trim(wav_tgt, top_db=20)
g_tgt = smodel.embed_utterance(wav_tgt)
g_tgt = torch.from_numpy(g_tgt).unsqueeze(0)
# src
wav_src, _ = librosa.load(src, sr=hps.data.sampling_rate)
wav_src = torch.from_numpy(wav_src).unsqueeze(0)
c = utils.get_content(cmodel, wav_src)
tgt_audio = net_g.infer(c, g=g_tgt)
tgt_audio = tgt_audio[0][0].data.cpu().float().numpy()
timestamp = time.strftime("%m-%d_%H-%M", time.localtime())
write(os.path.join('outputs/freevc', "{}.wav".format(timestamp)), hps.data.sampling_rate,
tgt_audio)
0it [00:00, ?it/s]
1it [00:00, 1.06it/s]
2it [00:01, 1.25it/s]
2it [00:01, 1.22it/s]
結果のオーディオファイルは ‘outputs/freevc’ で利用できます。
モデルを OpenVINO 中間表現に変換¶
各モデルを FP16 精度で OpenVINO IR に変換します。ov.convert_model 関数は、元の PyTorch モデル・オブジェクトとトレース用の入力例を受け入れ、このモデルを表す OpenVINO Model クラスのインスタンスを返します。取得したモデルはすぐに使用でき、compile_model を使用してデバイスにロードするか、ov.save_model 関数でディスクに保存できます。read_model メソッドは、保存されたモデルをディスクからロードします。モデル変換の詳細については、このページを参照してください。
最初に、以前のエンコーダーを OpenVINO IR 形式に変換する一環として、WavLM モデルを変換します。モデルの元の名前をコード内に保持します: cmodel。
# define forward as extract_features for compatibility
cmodel.forward = cmodel.extract_features
OUTPUT_DIR = Path("output")
BASE_MODEL_NAME = "cmodel"
OUTPUT_DIR.mkdir(exist_ok=True)
ir_cmodel_path = Path(OUTPUT_DIR / (BASE_MODEL_NAME + "_ir")).with_suffix(".xml")
length = 32000
dummy_input = torch.randn(1, length)
OpenVINO の IR 形式に変換します。
core = ov.Core()
class ModelWrapper(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = model
def forward(self, input):
return self.model(input)[0]
if not ir_cmodel_path.exists():
ir_cmodel = ov.convert_model(ModelWrapper(cmodel), example_input=dummy_input)
ov.save_model(ir_cmodel, ir_cmodel_path)
else:
ir_cmodel = core.read_model(ir_cmodel_path)
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/notebooks/242-freevc-voice-conversion/FreeVC/wavlm/modules.py:495: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert embed_dim == self.embed_dim
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/notebooks/242-freevc-voice-conversion/FreeVC/wavlm/modules.py:496: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert list(query.size()) == [tgt_len, bsz, embed_dim]
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/notebooks/242-freevc-voice-conversion/FreeVC/wavlm/modules.py:500: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert key_bsz == bsz
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/notebooks/242-freevc-voice-conversion/FreeVC/wavlm/modules.py:502: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert src_len, bsz == value.shape[:2]
OpenVINO を使用して推論を実行するデバイスをドロップダウン・リストから選択します。
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='AUTO',
description='Device:',
disabled=False,
)
device
Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')
compiled_cmodel = core.compile_model(ir_cmodel, device.value)
OUTPUT_DIR = Path("output")
BASE_MODEL_NAME = "smodel"
OUTPUT_DIR.mkdir(exist_ok=True)
ir_smodel_path = Path(OUTPUT_DIR / (BASE_MODEL_NAME + "ir")).with_suffix(".xml")
length = 32000
dummy_input = torch.randn(1, length, 40)
if not ir_smodel_path.exists():
ir_smodel = ov.convert_model(smodel, example_input=dummy_input)
ov.save_model(ir_smodel, ir_smodel_path)
else:
ir_smodel = core.read_model(ir_smodel_path)
推論の入力を準備するには、speaker_encoder.voice_encoder.SpeakerEncoder クラスメソッドに基づいてヘルパー関数を定義する必要があります。
from speaker_encoder.hparams import sampling_rate, mel_window_step, partials_n_frames
from speaker_encoder import audio
def compute_partial_slices(n_samples: int, rate, min_coverage):
"""
Computes where to split an utterance waveform and its corresponding mel spectrogram to
obtain partial utterances of <partials_n_frames> each. Both the waveform and the
mel spectrogram slices are returned, so as to make each partial utterance waveform
correspond to its spectrogram.
The returned ranges may be indexing further than the length of the waveform. It is
recommended that you pad the waveform with zeros up to wav_slices[-1].stop.
:param n_samples: the number of samples in the waveform
:param rate: how many partial utterances should occur per second. Partial utterances must
cover the span of the entire utterance, thus the rate should not be lower than the inverse
of the duration of a partial utterance. By default, partial utterances are 1.6s long and
the minimum rate is thus 0.625.
:param min_coverage: when reaching the last partial utterance, it may or may not have
enough frames. If at least <min_pad_coverage> of <partials_n_frames> are present,
then the last partial utterance will be considered by zero-padding the audio. Otherwise,
it will be discarded. If there aren't enough frames for one partial utterance,
this parameter is ignored so that the function always returns at least one slice.
:return: the waveform slices and mel spectrogram slices as lists of array slices. Index
respectively the waveform and the mel spectrogram with these slices to obtain the partial
utterances.
"""
assert 0 < min_coverage <= 1
# Compute how many frames separate two partial utterances
samples_per_frame = int((sampling_rate * mel_window_step / 1000))
n_frames = int(np.ceil((n_samples + 1) / samples_per_frame))
frame_step = int(np.round((sampling_rate / rate) / samples_per_frame))
assert 0 < frame_step, "The rate is too high"
assert frame_step <= partials_n_frames, "The rate is too low, it should be %f at least" % \
(sampling_rate / (samples_per_frame * partials_n_frames))
# Compute the slices
wav_slices, mel_slices = [], []
steps = max(1, n_frames - partials_n_frames + frame_step + 1)
for i in range(0, steps, frame_step):
mel_range = np.array([i, i + partials_n_frames])
wav_range = mel_range * samples_per_frame
mel_slices.append(slice(*mel_range))
wav_slices.append(slice(*wav_range))
# Evaluate whether extra padding is warranted or not
last_wav_range = wav_slices[-1]
coverage = (n_samples - last_wav_range.start) / (last_wav_range.stop - last_wav_range.start)
if coverage < min_coverage and len(mel_slices) > 1:
mel_slices = mel_slices[:-1]
wav_slices = wav_slices[:-1]
return wav_slices, mel_slices
def embed_utterance(wav: np.ndarray, smodel: ov.CompiledModel, return_partials=False, rate=1.3, min_coverage=0.75):
"""
Computes an embedding for a single utterance. The utterance is divided in partial
utterances and an embedding is computed for each. The complete utterance embedding is the
L2-normed average embedding of the partial utterances.
:param wav: a preprocessed utterance waveform as a numpy array of float32
:param smodel: compiled speaker encoder model.
:param return_partials: if True, the partial embeddings will also be returned along with
the wav slices corresponding to each partial utterance.
:param rate: how many partial utterances should occur per second. Partial utterances must
cover the span of the entire utterance, thus the rate should not be lower than the inverse
of the duration of a partial utterance. By default, partial utterances are 1.6s long and
the minimum rate is thus 0.625.
:param min_coverage: when reaching the last partial utterance, it may or may not have
enough frames. If at least <min_pad_coverage> of <partials_n_frames> are present,
then the last partial utterance will be considered by zero-padding the audio. Otherwise,
it will be discarded. If there aren't enough frames for one partial utterance,
this parameter is ignored so that the function always returns at least one slice.
:return: the embedding as a numpy array of float32 of shape (model_embedding_size,). If
<return_partials> is True, the partial utterances as a numpy array of float32 of shape
(n_partials, model_embedding_size) and the wav partials as a list of slices will also be
returned.
"""
# Compute where to split the utterance into partials and pad the waveform with zeros if
# the partial utterances cover a larger range.
wav_slices, mel_slices = compute_partial_slices(len(wav), rate, min_coverage)
max_wave_length = wav_slices[-1].stop
if max_wave_length >= len(wav):
wav = np.pad(wav, (0, max_wave_length - len(wav)), "constant")
# Split the utterance into partials and forward them through the model
mel = audio.wav_to_mel_spectrogram(wav)
mels = np.array([mel[s] for s in mel_slices])
with torch.no_grad():
mels = torch.from_numpy(mels).to(torch.device('cpu'))
output_layer = smodel.output(0)
partial_embeds = smodel(mels)[output_layer]
# Compute the utterance embedding from the partial embeddings
raw_embed = np.mean(partial_embeds, axis=0)
embed = raw_embed / np.linalg.norm(raw_embed, 2)
if return_partials:
return embed, partial_embeds, wav_slices
return embed
OpenVINO を使用して推論を実行するデバイスをドロップダウン・リストから選択します。
device
Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')
次にモデルをコンパイルします。
compiled_smodel = core.compile_model(ir_smodel, device.value)
同様にデコーダー機能を実装した SynthesizerTrn モデルを OpenVINO IR 形式にエクスポートします。
OUTPUT_DIR = Path("output")
BASE_MODEL_NAME = "net_g"
onnx_net_g_path = Path(OUTPUT_DIR / (BASE_MODEL_NAME + "_fp32")).with_suffix(".onnx")
ir_net_g_path = Path(OUTPUT_DIR / (BASE_MODEL_NAME + "ir")).with_suffix(".xml")
dummy_input_1 = torch.randn(1, 1024, 81)
dummy_input_2 = torch.randn(1, 256)
# define forward as infer
net_g.forward = net_g.infer
if not ir_net_g_path.exists():
ir_net_g_model = ov.convert_model(net_g, example_input=(dummy_input_1, dummy_input_2))
ov.save_model(ir_net_g_model, ir_net_g_path)
else:
ir_net_g_model = core.read_model(ir_net_g_path)
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/torch/jit/_trace.py:1102: TracerWarning: Output nr 1. of the traced function does not match the corresponding output of the Python function. Detailed error:
Tensor-likes are not close!
Mismatched elements: 25920 / 25920 (100.0%)
Greatest absolute difference: 1.6649601459503174 at index (0, 0, 25248) (up to 1e-05 allowed)
Greatest relative difference: 12715.998370804822 at index (0, 0, 5088) (up to 1e-05 allowed)
_check_trace(
OpenVINO を使用して推論を実行するデバイスをドロップダウン・リストから選択します。
compiled_ir_net_g_model = core.compile_model(ir_net_g_model, device.value)
合成のため関数を定義します。
def synthesize_audio(src, tgt):
wav_tgt, _ = librosa.load(tgt, sr=hps.data.sampling_rate)
wav_tgt, _ = librosa.effects.trim(wav_tgt, top_db=20)
g_tgt = embed_utterance(wav_tgt, compiled_smodel)
g_tgt = torch.from_numpy(g_tgt).unsqueeze(0)
# src
wav_src, _ = librosa.load(src, sr=hps.data.sampling_rate)
wav_src = np.expand_dims(wav_src, axis=0)
output_layer = compiled_cmodel.output(0)
c = compiled_cmodel(wav_src)[output_layer]
c = c.transpose((0, 2, 1))
output_layer = compiled_ir_net_g_model.output(0)
tgt_audio = compiled_ir_net_g_model((c, g_tgt))[output_layer]
tgt_audio = tgt_audio[0][0]
return tgt_audio
そして、IR モデルのみを使用して推論を確認できるようになります。
result_wav_names = []
with torch.no_grad():
for line in tqdm(zip(srcs, tgts)):
src, tgt = line
output_audio = synthesize_audio(src, tgt)
timestamp = time.strftime("%m-%d_%H-%M", time.localtime())
result_name = f'{timestamp}.wav'
result_wav_names.append(result_name)
write(
os.path.join('outputs/freevc', result_name),
hps.data.sampling_rate,
output_audio
)
0it [00:00, ?it/s]
1it [00:00, 1.34it/s]
2it [00:02, 1.29s/it]
2it [00:02, 1.21s/it]
結果のオーディオファイルは ‘outputs/freevc’ で利用可能になり、それらを確認して以前に生成されたものと比較できます。以下に結果の 1 つを示します。
ソースオーディオ (テキストのソース):
import IPython.display as ipd
ipd.Audio(srcs[0])
ターゲットオーディオ (音声ソース):
ipd.Audio(tgts[0])
結果オーディオ:
ipd.Audio(f'outputs/freevc/{result_wav_names[0]}')
独自の音声ファイルを使用することもできます。アップロードするだけで推論に使用できます。hps.data.sampling_rate の値に対応するレートを使用します。
import gradio as gr
audio1 = gr.Audio(label="Source Audio", type='filepath')
audio2 = gr.Audio(label="Reference Audio", type='filepath')
outputs = gr.Audio(label="Output Audio", type='filepath')
examples = [[audio1_name, audio2_name]]
title = 'FreeVC with Gradio'
description = 'Gradio Demo for FreeVC and OpenVINO™. Upload a source audio and a reference audio, then click the "Submit" button to inference.'
def infer(src, tgt):
output_audio = synthesize_audio(src, tgt)
timestamp = time.strftime("%m-%d_%H-%M", time.localtime())
result_name = f'{timestamp}.wav'
write(result_name, hps.data.sampling_rate, output_audio)
return result_name
iface = gr.Interface(infer, [audio1, audio2], outputs, title=title, description=description, examples=examples)
iface.launch()
# if you are launching remotely, specify server_name and server_port
# iface.launch(server_name='your server name', server_port='server port in int')
# if you have any issue to launch on your platform, you can pass share=True to launch method:
# iface.launch(share=True)
# it creates a publicly shareable link for the interface. Read more in the docs: https://gradio.app/docs/
Running on local URL: http://127.0.0.1:7860 To create a public link, set share=True in launch().
iface.close()
Closing server running on port: 7860