OpenVINO のレイテンシー・モードのパフォーマンスに関するヒント¶
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

このノートブックの目的は、待機モードでの推論のパフォーマンスを向上させる段階的なチュートリアルを提供することです。リアルタイム・アプリケーションでは、データが表示されてからできるだけ早く結果が必要な場合、低レイテンシーが望まれます。このノートブックはコンピューター・ビジョン・ワークフローを想定しており、YOLOv5n モデルを使用します。フレームを 1 つずつ提供するカメラ・アプリケーションをシミュレートします。
このノートブックで適用されたパフォーマンスのヒントは、次の図に要約できます。以下の手順の一部は、どの段階のどのデバイスにも適用できます (例: shared_memory)。 特定のデバイスにのみ使用できるものもあります (例: CPU に対する INFERENCE_NUM_THREADS)。考えられる構成は膨大であるため、以下の手順を確認してから、試行錯誤のアプローチを適用することをお勧めします。より多くの推論スレッド + 共有メモリーなど、多くのヒントを同時に組み込むことができます。
パフォーマンスはさらに向上するはずですが、とにかくテストすることです。
注: OpenVINO IR モデル + CPU + レイテンシー・モードの共有メモリー、または OpenVINO IR モデル + CPU + 共有メモリー + より多くの推論スレッドを試すことを推奨します。
量子化および前後処理 API は、精度 (量子化) または処理グラフ (前後処理) を変更するため、ここには含まれていません。これらを適用して OpenVINO IR ファイルのパフォーマンスを最適化する例は、118-optimize-preprocessing で見つけることができます。
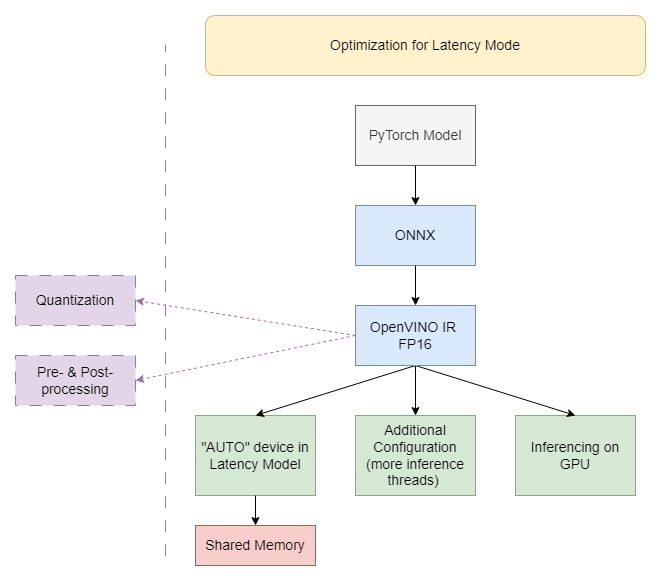
注: 以下に示す手順は、パフォーマンスを向上させるために役立ちます。ただし、ハードウェアまたはモデルに強く依存している場合は、何も変わらないか、パフォーマンスが悪化するものもあります。使用するモデルをコンピューター上のノートブックで実行して、どちらがケースに適しているかを確認してください。
以下のヒントはすべて OpenVINO 2023.0 で実行されました。OpenVINO の将来のバージョンでは、パフォーマンスが異なるさまざまな最適化が含まれる可能性があります。
スループット・モードに焦点を当てた同様のノートブックは、ここで入手できます。
目次¶
必要条件¶
%pip install -q "openvino>=2023.1.0" seaborn "ultralytics<=8.0.178" onnx --extra-index-url https://download.pytorch.org/whl/cpu
Note: you may need to restart the kernel to use updated packages.
import os
import time
from pathlib import Path
from typing import Any, List, Tuple
# Fetch `notebook_utils` module
import urllib.request
urllib.request.urlretrieve(
url='https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/main/notebooks/utils/notebook_utils.py',
filename='notebook_utils.py'
)
import notebook_utils as utils
データ¶
以下のすべての実験では、自転車に座っている犬の同じ画像を使用しています。この特定のオブジェクト検出モデルの要件を満たすよう、画像のサイズが変更され、前処理されます。
import numpy as np
import cv2
IMAGE_WIDTH = 640
IMAGE_HEIGHT = 480
# load image
image = utils.load_image("https://storage.openvinotoolkit.org/repositories/openvino_notebooks/data/data/image/coco_bike.jpg")
image = cv2.resize(image, dsize=(IMAGE_WIDTH, IMAGE_HEIGHT), interpolation=cv2.INTER_AREA)
# preprocess it for YOLOv5
input_image = image / 255.0
input_image = np.transpose(input_image, axes=(2, 0, 1))
input_image = np.expand_dims(input_image, axis=0)
# show the image
utils.show_array(image)

<DisplayHandle display_id=c7531cff1487c41296f1ac25e2e96b93>
モデル¶
ここでは、PyTorch Hub から簡単に入手でき、パフォーマンスの違いを確認できる小さな最先端のオブジェクト検出モデルの 1 つである YOLOv5n を使用することにしました。
import torch
from IPython.utils import io
# directory for all models
base_model_dir = Path("model")
model_name = "yolov5n"
model_path = base_model_dir / model_name
# load YOLOv5n from PyTorch Hub
pytorch_model = torch.hub.load("ultralytics/yolov5", "custom", path=model_path, device="cpu", skip_validation=True)
# don't print full model architecture
with io.capture_output():
pytorch_model.eval()
Using cache found in /opt/home/k8sworker/.cache/torch/hub/ultralytics_yolov5_master
YOLOv5 🚀 2023-4-21 Python-3.8.10 torch-2.1.0+cpu CPU
requirements: /opt/home/k8sworker/.cache/torch/hub/requirements.txt not found, check failed.
Downloading https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n.pt to model/yolov5n.pt...
0%| | 0.00/3.87M [00:00<?, ?B/s]
7%|▋ | 272k/3.87M [00:00<00:01, 2.23MB/s]
19%|█▉ | 752k/3.87M [00:00<00:00, 3.64MB/s]
29%|██▉ | 1.13M/3.87M [00:00<00:00, 3.87MB/s]
39%|███▉ | 1.52M/3.87M [00:00<00:00, 3.61MB/s]
49%|████▉ | 1.89M/3.87M [00:00<00:00, 3.68MB/s]
61%|██████▏ | 2.38M/3.87M [00:00<00:00, 4.06MB/s]
72%|███████▏ | 2.77M/3.87M [00:00<00:00, 3.82MB/s]
83%|████████▎ | 3.23M/3.87M [00:00<00:00, 4.07MB/s]
94%|█████████▍| 3.63M/3.87M [00:01<00:00, 3.85MB/s]
100%|██████████| 3.87M/3.87M [00:01<00:00, 3.87MB/s]
Fusing layers...
YOLOv5n summary: 213 layers, 1867405 parameters, 0 gradients
Adding AutoShape...
ハードウェア¶
以下のコードには、ベンチマーク・プロセスで使用する利用可能なハードウェアがリストされています。
注: 皆さんが使用するハードウェアは、おそらくここで使用するものとは全く異なります。つまり、全く異なる結果が見られるということです。
import openvino as ov
# initialize OpenVINO
core = ov.Core()
# print available devices
for device in core.available_devices:
device_name = core.get_property(device, "FULL_DEVICE_NAME")
print(f"{device}: {device_name}")
CPU: Intel(R) Core(TM) i9-10920X CPU @ 3.50GHz
ヘルパー関数¶
以下のすべての最適化モデルに使用するベンチマーク・モデル関数を定義します。推論を 1000 回実行し、待機時間を平均して、画像あたりの秒数と 1 秒あたりのフレーム数 (FPS) の 2 つの測定値を出力します。
INFER_NUMBER = 1000
def benchmark_model(model: Any, input_data: np.ndarray, benchmark_name: str, device_name: str = "CPU") -> float:
"""
Helper function for benchmarking the model. It measures the time and prints results.
"""
# measure the first inference separately - it may be slower as it contains also initialization
start = time.perf_counter()
model(input_data)
end = time.perf_counter()
first_infer_time = end - start
print(f"{benchmark_name} on {device_name}. First inference time: {first_infer_time :.4f} seconds")
# benchmarking
start = time.perf_counter()
for _ in range(INFER_NUMBER):
model(input_data)
end = time.perf_counter()
# elapsed time
infer_time = end - start
# print second per image and FPS
mean_infer_time = infer_time / INFER_NUMBER
mean_fps = INFER_NUMBER / infer_time
print(f"{benchmark_name} on {device_name}: {mean_infer_time :.4f} seconds per image ({mean_fps :.2f} FPS)")
return mean_infer_time
次の関数は、結果を後処理し、画像上にボックスを描画します。
# https://gist.github.com/AruniRC/7b3dadd004da04c80198557db5da4bda
classes = [
"person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light", "fire hydrant",
"stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear", "zebra",
"giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite",
"baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork",
"knife", "spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut",
"cake", "chair", "couch", "potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard",
"cell phone", "microwave", "oven", "oaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear",
"hair drier", "toothbrush"
]
# Colors for the classes above (Rainbow Color Map).
colors = cv2.applyColorMap(
src=np.arange(0, 255, 255 / len(classes), dtype=np.float32).astype(np.uint8),
colormap=cv2.COLORMAP_RAINBOW,
).squeeze()
def postprocess(detections: np.ndarray) -> List[Tuple]:
"""
Postprocess the raw results from the model.
"""
# candidates - probability > 0.25
detections = detections[detections[..., 4] > 0.25]
boxes = []
labels = []
scores = []
for obj in detections:
xmin, ymin, ww, hh = obj[:4]
score = obj[4]
label = np.argmax(obj[5:])
# Create a box with pixels coordinates from the box with normalized coordinates [0,1].
boxes.append(
tuple(map(int, (xmin - ww // 2, ymin - hh // 2, ww, hh)))
)
labels.append(int(label))
scores.append(float(score))
# Apply non-maximum suppression to get rid of many overlapping entities.
# See https://paperswithcode.com/method/non-maximum-suppression
# This algorithm returns indices of objects to keep.
indices = cv2.dnn.NMSBoxes(
bboxes=boxes, scores=scores, score_threshold=0.25, nms_threshold=0.5
)
# If there are no boxes.
if len(indices) == 0:
return []
# Filter detected objects.
return [(labels[idx], scores[idx], boxes[idx]) for idx in indices.flatten()]
def draw_boxes(img: np.ndarray, boxes):
"""
Draw detected boxes on the image.
"""
for label, score, box in boxes:
# Choose color for the label.
color = tuple(map(int, colors[label]))
# Draw a box.
x2 = box[0] + box[2]
y2 = box[1] + box[3]
cv2.rectangle(img=img, pt1=box[:2], pt2=(x2, y2), color=color, thickness=2)
# Draw a label name inside the box.
cv2.putText(
img=img,
text=f"{classes[label]} {score:.2f}",
org=(box[0] + 10, box[1] + 20),
fontFace=cv2.FONT_HERSHEY_COMPLEX,
fontScale=img.shape[1] / 1200,
color=color,
thickness=1,
lineType=cv2.LINE_AA,
)
def show_result(results: np.ndarray):
"""
Postprocess the raw results, draw boxes and show the image.
"""
output_img = image.copy()
detections = postprocess(results)
draw_boxes(output_img, detections)
utils.show_array(output_img)
最適化¶
以下に、レイテンシー・モードで推論を高速化するパフォーマンスのヒントを示します。すべての検証で同じ量のリソースが利用可能であることを確認するため、ベンチマークごとにリソースを解放します。
PyTorch モデル¶
まず、最適化を適用せずに元の PyTorch モデルをベンチマークします。これをベースラインとして扱います。
import torch
with torch.no_grad():
result = pytorch_model(torch.as_tensor(input_image)).detach().numpy()[0]
show_result(result)
pytorch_infer_time = benchmark_model(pytorch_model, input_data=torch.as_tensor(input_image).float(), benchmark_name="PyTorch model")

PyTorch model on CPU. First inference time: 0.0280 seconds
PyTorch model on CPU: 0.0218 seconds per image (45.96 FPS)
ONNX モデル¶
最初の最適化は、PyTorch モデルを ONNX にエクスポートし、OpenVINO で実行することです。ONNX フロントエンドにより、これが可能になります。つまり、OpenVINO ランタイムを活用するには、必ずしもモデルを中間表現 (IR) に変換する必要はないということです。
onnx_path = base_model_dir / Path(f"{model_name}_{IMAGE_WIDTH}_{IMAGE_HEIGHT}").with_suffix(".onnx")
# export PyTorch model to ONNX if it doesn't already exist
if not onnx_path.exists():
dummy_input = torch.randn(1, 3, IMAGE_HEIGHT, IMAGE_WIDTH)
torch.onnx.export(pytorch_model, dummy_input, onnx_path)
# load and compile in OpenVINO
onnx_model = core.read_model(onnx_path)
onnx_model = core.compile_model(onnx_model, device_name="CPU")
/opt/home/k8sworker/.cache/torch/hub/ultralytics_yolov5_master/models/common.py:514: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
y = self.model(im, augment=augment, visualize=visualize) if augment or visualize else self.model(im)
/opt/home/k8sworker/.cache/torch/hub/ultralytics_yolov5_master/models/yolo.py:64: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if self.dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
result = onnx_model(input_image)[onnx_model.output(0)][0]
show_result(result)
onnx_infer_time = benchmark_model(model=onnx_model, input_data=input_image, benchmark_name="ONNX model")
del onnx_model # release resources

ONNX model on CPU. First inference time: 0.0174 seconds
ONNX model on CPU: 0.0136 seconds per image (73.63 FPS)
OpenVINO IR モデル¶
ONNX モデルを OpenVINO 中間表現 (IR) FP16 に変換して実行します。FP16 や INT8 などの低精度をサポートするハードウェアでは、精度を下げることは推論を高速化する方法の 1 つです。ハードウェアが低精度をサポートしない場合、モデルは自動的に FP32 で推論されます。量子化 (INT8) を使用することもできますが、精度が若干低下します。そのため、このノートブックではこの手順は省略します。
ov_model = ov.convert_model(onnx_path)
# save the model on disk
ov.save_model(ov_model, str(onnx_path.with_suffix(".xml")))
ov_cpu_model = core.compile_model(ov_model, device_name="CPU")
result = ov_cpu_model(input_image)[ov_cpu_model.output(0)][0]
show_result(result)
ov_cpu_infer_time = benchmark_model(model=ov_cpu_model, input_data=input_image, benchmark_name="OpenVINO model")
del ov_cpu_model # release resources

OpenVINO model on CPU. First inference time: 0.0153 seconds
OpenVINO model on CPU: 0.0122 seconds per image (82.17 FPS)
GPU 上の OpenVINO IR モデル¶
通常、GPU デバイスは CPU よりも高速であるため、上記のモデルを GPU で実行してみます。この手順を実行するには、インテル® GPU が必要であり、ドライバーをインストールする必要があることに注意してください。さらに、GPU へのオフロードにより、CPU の負荷とメモリーの消費が軽減され、他のプロセスにそれらを割り当てることができます。GPU で高速な推論が確認できない場合、モデルが軽量すぎるため大規模な並列実行のメリットが得られていない可能性があります。
ov_gpu_infer_time = 0.0
if "GPU" in core.available_devices:
ov_gpu_model = core.compile_model(ov_model, device_name="GPU")
result = ov_gpu_model(input_image)[ov_gpu_model.output(0)][0]
show_result(result)
ov_gpu_infer_time = benchmark_model(model=ov_gpu_model, input_data=input_image, benchmark_name="OpenVINO model", device_name="GPU")
del ov_gpu_model # release resources
OpenVINO IR モデル + より多くの推論スレッド¶
任意のデバイス (この場合は CPU) の設定を追加する可能性があります。スレッド数をコア数と同じ数まで増やします。変更できるオプションは他にもあるので、実際に試してみて、自身のケースに最適なものを見つける価値はあります。場合によっては、この最適化によってパフォーマンスが低下する可能性があります。そうであれば使用しないでください。
num_cores = os.cpu_count()
ov_cpu_config_model = core.compile_model(ov_model, device_name="CPU", config={"INFERENCE_NUM_THREADS": num_cores})
result = ov_cpu_config_model(input_image)[ov_cpu_config_model.output(0)][0]
show_result(result)
ov_cpu_config_infer_time = benchmark_model(model=ov_cpu_config_model, input_data=input_image, benchmark_name="OpenVINO model + more threads")
del ov_cpu_config_model # release resources

OpenVINO model + more threads on CPU. First inference time: 0.0150 seconds
OpenVINO model + more threads on CPU: 0.0122 seconds per image (81.82 FPS)
レイテンシー・モードの OpenVINO IR モデル¶
OpenVINO は、パフォーマンスのヒントに基づいて最適なデバイスを選択できる AUTO と呼ばれる仮想デバイスを提供します。ヒントには、LATENCY、THROUGHPUT、CUMULATIVE_THROUGHPUT の 3 つがあります。このノートブックはレイテンシー・モードに重点を置いているため、LATENCY を使用します。上記のヒントは他のデバイスでも使用できます。
ov_auto_model = core.compile_model(ov_model, device_name="AUTO", config={"PERFORMANCE_HINT": "LATENCY"})
result = ov_auto_model(input_image)[ov_auto_model.output(0)][0]
show_result(result)
ov_auto_infer_time = benchmark_model(model=ov_auto_model, input_data=input_image, benchmark_name="OpenVINO model", device_name="AUTO")

OpenVINO model on AUTO. First inference time: 0.0153 seconds
OpenVINO model on AUTO: 0.0125 seconds per image (80.25 FPS)
レイテンシー・モード + 共有メモリーの OpenVINO IR モデル¶
OpenVINO は、Python ラッパー (API) を備えた C++ ツールキットです。Python API のデフォルトの動作では、入力を追加バッファーにコピーしてから C++ で処理を実行するため、多くのマルチプロセス関連の問題を排除できます。ただし、時間コストが増加します。共有メモリーを有効にしたテンソルを作成し (入力を上書きできないことに注意してください)、コピーの時間を節約してパフォーマンスを向上できます。
# it must be assigned to a variable, not to be garbage collected
c_input_image = np.ascontiguousarray(input_image, dtype=np.float32)
input_tensor = ov.Tensor(c_input_image, shared_memory=True)
result = ov_auto_model(input_tensor)[ov_auto_model.output(0)][0]
show_result(result)
ov_auto_shared_infer_time = benchmark_model(model=ov_auto_model, input_data=input_tensor, benchmark_name="OpenVINO model + shared memory", device_name="AUTO")
del ov_auto_model # release resources

OpenVINO model + shared memory on AUTO. First inference time: 0.0113 seconds
OpenVINO model + shared memory on AUTO: 0.0054 seconds per image (186.01 FPS)
その他のヒント¶
量子化や前後処理、スループット・モード専用など、パフォーマンスを向上させる他のヒントもあります。モデルをさらに活用するには、118-optimize-preprocessing、および 109-latency-tricks をご覧ください。
パフォーマンスの比較¶
次のグラフ比較は、選択したモデルとハードウェアに対して同時に有効です。いくつかのステップ間で改善が見られない場合は、スキップしてください。
%matplotlib inline
from matplotlib import pyplot as plt
labels = ["PyTorch model", "ONNX model", "OpenVINO IR model", "OpenVINO IR model on GPU", "OpenVINO IR model + more inference threads",
"OpenVINO IR model in latency mode", "OpenVINO IR model in latency mode + shared memory"]
# make them milliseconds
times = list(map(lambda x: 1000 * x, [pytorch_infer_time, onnx_infer_time, ov_cpu_infer_time, ov_gpu_infer_time, ov_cpu_config_infer_time,
ov_auto_infer_time, ov_auto_shared_infer_time]))
bar_colors = colors[::10] / 255.0
fig, ax = plt.subplots(figsize=(16, 8))
ax.bar(labels, times, color=bar_colors)
ax.set_ylabel("Inference time [ms]")
ax.set_title("Performance difference")
plt.xticks(rotation='vertical')
plt.show()
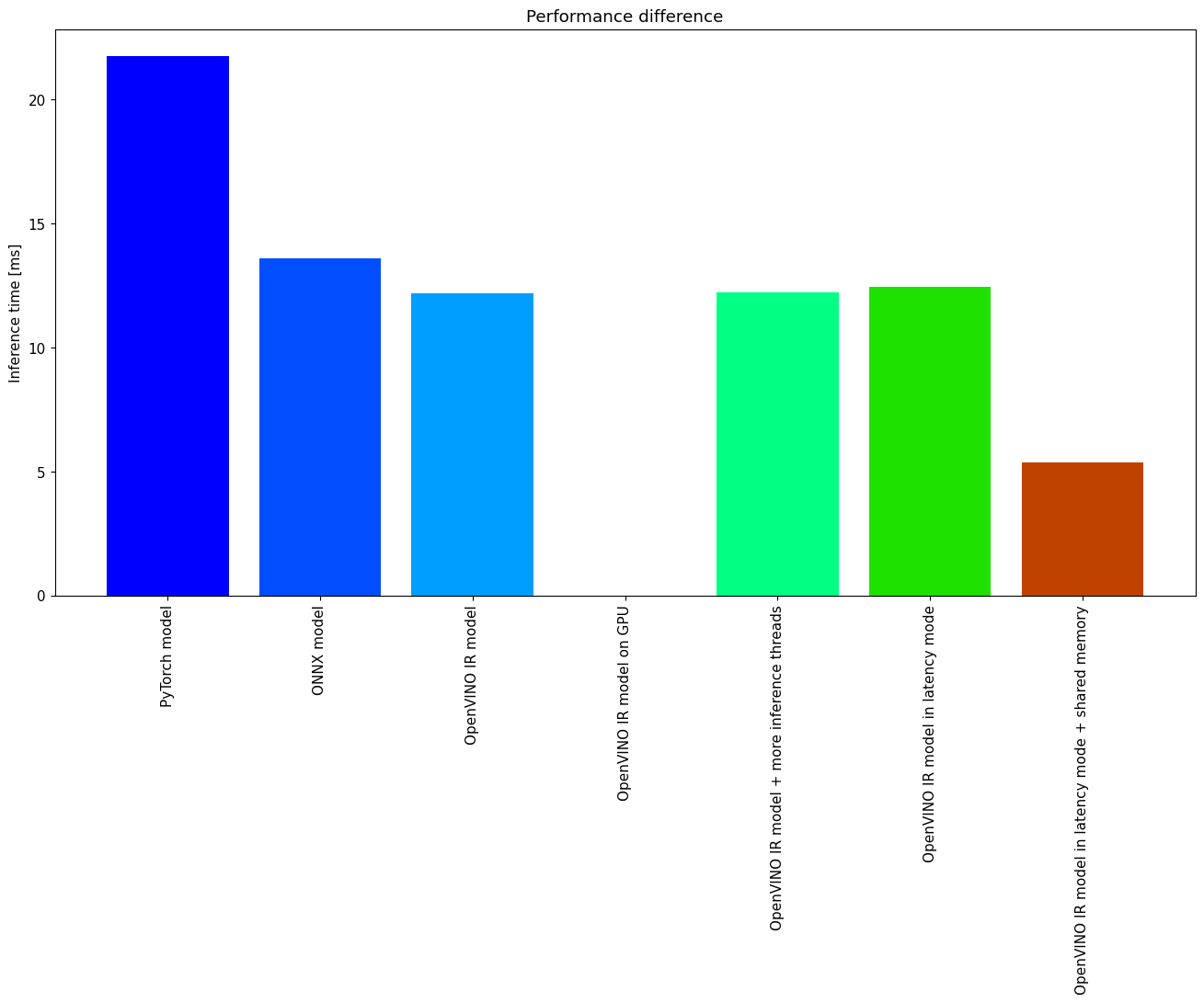
まとめ¶
物体検出モデルのパフォーマンスを向上させるために必要な手順はすでに示しました。このノートブックを実行した後にパフォーマンスが大幅に向上したとしても、これはすべてのハードウェアまたはすべてのモデルに有効であるとは限らないことに注意してください。最も正確な結果を得るには、benchmark_app コマンドラインツールを使用してください。benchmark_app は、共有メモリーなど、上記のいくつかのヒントの影響を測定できないことに注意してください。