SlowFast と OpenVINO™ を使用したビデオ認識¶
この Jupyter ノートブックはオンラインで起動でき、ブラウザーのウィンドウで対話型環境を開きます。ローカルにインストールすることもできます。次のオプションのいずれかを選択します。


画像の内容を検出、理解、分析するようにマシンに教えることは、コンピューター・ビジョンにおいて最もよく知られ、よく研究されている問題の 1 つです。しかし、ビデオを分析してビデオ内で何が起こっているかを理解し、注目するオブジェクトを検出することは、自動運転、ヘルスケア、セキュリティーなど、さまざまな分野で幅広く応用される重要かつ困難なタスクです。
SlowFast モデルは、ビデオには通常、静的要素と動的要素が含まれており、静的コンテンツを分析し、低フレームレートで動作する低速経路と、動的コンテンツをキャプチャーする高フレームレートで動作する高速経路が使用されることに基づいて、ビデオを分析する興味深いアプローチを提供します。その利点は、ビデオシーケンス内の高速モーション情報とスローモーション情報の両方を効果的にキャプチャーできることにあり、データの時間的および空間的な理解を必要とするタスクに特に適しています。
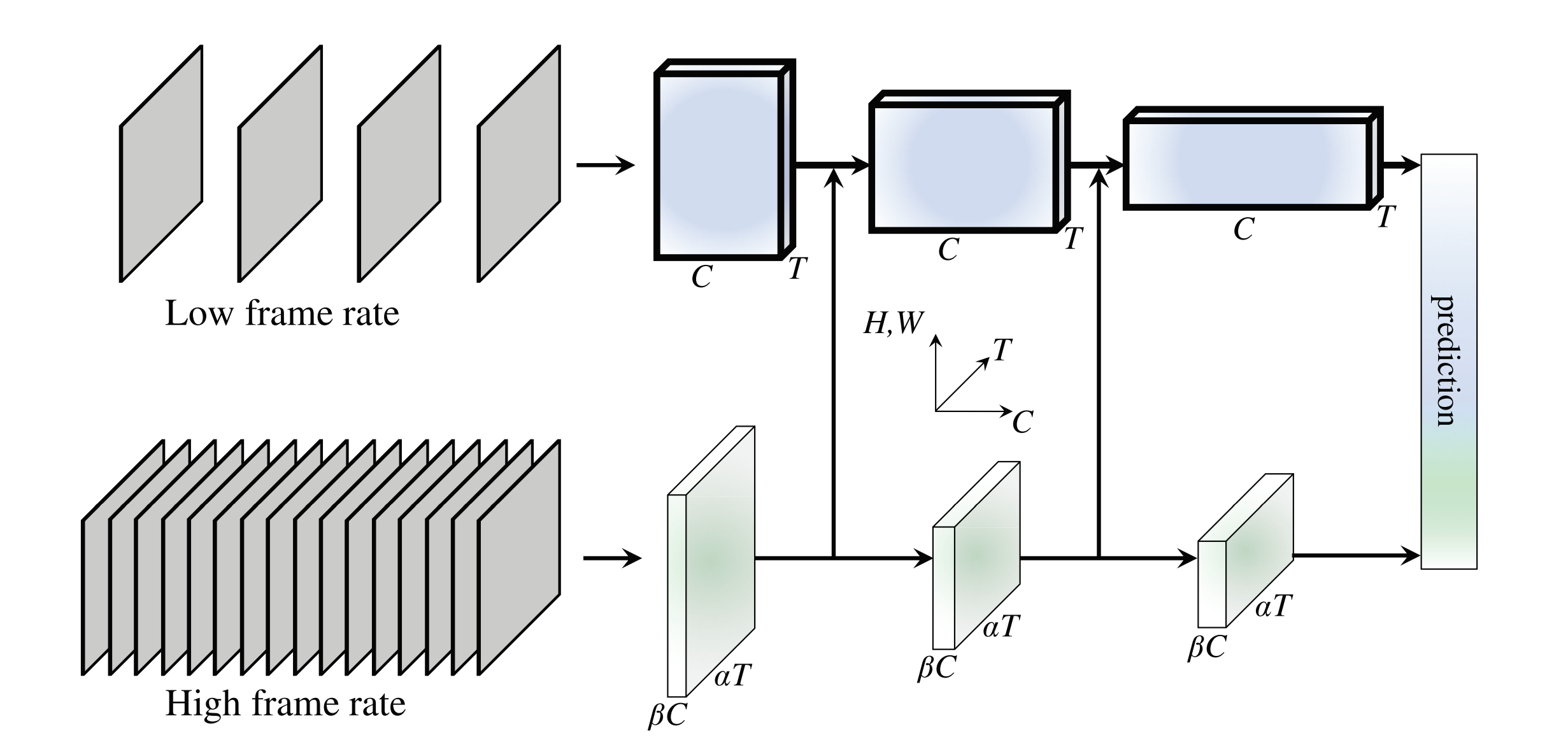
ネットワークの詳細については、オリジナルの論文とリポジトリーを参照してください。
このノートブックでは、OpenVINO を使用して ResNet-50 ベースの SlowFast モデルを変換して実行する方法を説明します。
このチュートリアルは次のステップで構成されます
PyTorch モデルの準備
データをダウンロードして準備
PyTorch モデルで推論を確認
モデルを OpenVINO 中間表現に変換
変換されたモデルの推論の検証
目次¶
PyTorch モデルの準備¶
必要なパッケージのインストール¶
%pip install -q "openvino>=2023.3.0" fvcore --extra-index-url https://download.pytorch.org/whl/cpu
Note: you may need to restart the kernel to use updated packages.
インポートと設定¶
import json
import math
import sys
import cv2
import torch
import numpy as np
from pathlib import Path
from typing import Any, List, Dict
from IPython.display import Video
import openvino as ov
sys.path.append("../utils")
from notebook_utils import download_file
DATA_DIR = Path("data/")
MODEL_DIR = Path("model/")
MODEL_DIR.mkdir(exist_ok=True)
DATA_DIR.mkdir(exist_ok=True)
まず、PyTorchVideo リポジトリーから PyTorch モデルをダウンロードします。このノートブックでは、Kinetics 400 データセットでトレーニングされた ResNet-50 アーキテクチャーに基づく SlowFast ネットワークを使用します。Kinetics 400 は、ビデオ内の行動認識向けの大規模なデータセットで、400 の人間のアクションクラスと、各アクションごとに少なくとも 400 のビデオクリップが含まれています。データセットと論文の詳細については、こちらをご覧ください。
MODEL_NAME = "slowfast_r50"
MODEL_REPOSITORY = "facebookresearch/pytorchvideo"
DEVICE = "cpu"
# load the pretrained model from the repository
model = torch.hub.load(
repo_or_dir=MODEL_REPOSITORY, model=MODEL_NAME, pretrained=True, skip_validation=True
)
# set the device to allocate tensors to. for example, "cpu" or "cuda"
model.to(DEVICE)
# set the model to eval mode
model.eval()
Using cache found in /opt/home/k8sworker/.cache/torch/hub/facebookresearch_pytorchvideo_main
Net(
(blocks): ModuleList(
(0): MultiPathWayWithFuse(
(multipathway_blocks): ModuleList(
(0): ResNetBasicStem(
(conv): Conv3d(3, 64, kernel_size=(1, 7, 7), stride=(1, 2, 2), padding=(0, 3, 3), bias=False)
(norm): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activation): ReLU()
(pool): MaxPool3d(kernel_size=(1, 3, 3), stride=(1, 2, 2), padding=[0, 1, 1], dilation=1, ceil_mode=False)
)
(1): ResNetBasicStem(
(conv): Conv3d(3, 8, kernel_size=(5, 7, 7), stride=(1, 2, 2), padding=(2, 3, 3), bias=False)
(norm): BatchNorm3d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activation): ReLU()
(pool): MaxPool3d(kernel_size=(1, 3, 3), stride=(1, 2, 2), padding=[0, 1, 1], dilation=1, ceil_mode=False)
)
)
(multipathway_fusion): FuseFastToSlow(
(conv_fast_to_slow): Conv3d(8, 16, kernel_size=(7, 1, 1), stride=(4, 1, 1), padding=(3, 0, 0), bias=False)
(norm): BatchNorm3d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activation): ReLU()
)
)
(1): MultiPathWayWithFuse(
(multipathway_blocks): ModuleList(
(0): ResStage(
(res_blocks): ModuleList(
(0): ResBlock(
(branch1_conv): Conv3d(80, 256, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(branch1_norm): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(branch2): BottleneckBlock(
(conv_a): Conv3d(80, 64, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(norm_a): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_a): ReLU()
(conv_b): Conv3d(64, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1), bias=False)
(norm_b): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_b): ReLU()
(conv_c): Conv3d(64, 256, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(norm_c): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU()
)
(1-2): 2 x ResBlock(
(branch2): BottleneckBlock(
(conv_a): Conv3d(256, 64, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(norm_a): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_a): ReLU()
(conv_b): Conv3d(64, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1), bias=False)
(norm_b): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_b): ReLU()
(conv_c): Conv3d(64, 256, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(norm_c): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU()
)
)
)
(1): ResStage(
(res_blocks): ModuleList(
(0): ResBlock(
(branch1_conv): Conv3d(8, 32, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(branch1_norm): BatchNorm3d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(branch2): BottleneckBlock(
(conv_a): Conv3d(8, 8, kernel_size=(3, 1, 1), stride=(1, 1, 1), padding=(1, 0, 0), bias=False)
(norm_a): BatchNorm3d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_a): ReLU()
(conv_b): Conv3d(8, 8, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1), bias=False)
(norm_b): BatchNorm3d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_b): ReLU()
(conv_c): Conv3d(8, 32, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(norm_c): BatchNorm3d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU()
)
(1-2): 2 x ResBlock(
(branch2): BottleneckBlock(
(conv_a): Conv3d(32, 8, kernel_size=(3, 1, 1), stride=(1, 1, 1), padding=(1, 0, 0), bias=False)
(norm_a): BatchNorm3d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_a): ReLU()
(conv_b): Conv3d(8, 8, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1), bias=False)
(norm_b): BatchNorm3d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_b): ReLU()
(conv_c): Conv3d(8, 32, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(norm_c): BatchNorm3d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU()
)
)
)
)
(multipathway_fusion): FuseFastToSlow(
(conv_fast_to_slow): Conv3d(32, 64, kernel_size=(7, 1, 1), stride=(4, 1, 1), padding=(3, 0, 0), bias=False)
(norm): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activation): ReLU()
)
)
(2): MultiPathWayWithFuse(
(multipathway_blocks): ModuleList(
(0): ResStage(
(res_blocks): ModuleList(
(0): ResBlock(
(branch1_conv): Conv3d(320, 512, kernel_size=(1, 1, 1), stride=(1, 2, 2), bias=False)
(branch1_norm): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(branch2): BottleneckBlock(
(conv_a): Conv3d(320, 128, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(norm_a): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_a): ReLU()
(conv_b): Conv3d(128, 128, kernel_size=(1, 3, 3), stride=(1, 2, 2), padding=(0, 1, 1), bias=False)
(norm_b): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_b): ReLU()
(conv_c): Conv3d(128, 512, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(norm_c): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU()
)
(1-3): 3 x ResBlock(
(branch2): BottleneckBlock(
(conv_a): Conv3d(512, 128, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(norm_a): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_a): ReLU()
(conv_b): Conv3d(128, 128, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1), bias=False)
(norm_b): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_b): ReLU()
(conv_c): Conv3d(128, 512, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(norm_c): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU()
)
)
)
(1): ResStage(
(res_blocks): ModuleList(
(0): ResBlock(
(branch1_conv): Conv3d(32, 64, kernel_size=(1, 1, 1), stride=(1, 2, 2), bias=False)
(branch1_norm): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(branch2): BottleneckBlock(
(conv_a): Conv3d(32, 16, kernel_size=(3, 1, 1), stride=(1, 1, 1), padding=(1, 0, 0), bias=False)
(norm_a): BatchNorm3d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_a): ReLU()
(conv_b): Conv3d(16, 16, kernel_size=(1, 3, 3), stride=(1, 2, 2), padding=(0, 1, 1), bias=False)
(norm_b): BatchNorm3d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_b): ReLU()
(conv_c): Conv3d(16, 64, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(norm_c): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU()
)
(1-3): 3 x ResBlock(
(branch2): BottleneckBlock(
(conv_a): Conv3d(64, 16, kernel_size=(3, 1, 1), stride=(1, 1, 1), padding=(1, 0, 0), bias=False)
(norm_a): BatchNorm3d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_a): ReLU()
(conv_b): Conv3d(16, 16, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1), bias=False)
(norm_b): BatchNorm3d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_b): ReLU()
(conv_c): Conv3d(16, 64, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(norm_c): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU()
)
)
)
)
(multipathway_fusion): FuseFastToSlow(
(conv_fast_to_slow): Conv3d(64, 128, kernel_size=(7, 1, 1), stride=(4, 1, 1), padding=(3, 0, 0), bias=False)
(norm): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activation): ReLU()
)
)
(3): MultiPathWayWithFuse(
(multipathway_blocks): ModuleList(
(0): ResStage(
(res_blocks): ModuleList(
(0): ResBlock(
(branch1_conv): Conv3d(640, 1024, kernel_size=(1, 1, 1), stride=(1, 2, 2), bias=False)
(branch1_norm): BatchNorm3d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(branch2): BottleneckBlock(
(conv_a): Conv3d(640, 256, kernel_size=(3, 1, 1), stride=(1, 1, 1), padding=(1, 0, 0), bias=False)
(norm_a): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_a): ReLU()
(conv_b): Conv3d(256, 256, kernel_size=(1, 3, 3), stride=(1, 2, 2), padding=(0, 1, 1), bias=False)
(norm_b): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_b): ReLU()
(conv_c): Conv3d(256, 1024, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(norm_c): BatchNorm3d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU()
)
(1-5): 5 x ResBlock(
(branch2): BottleneckBlock(
(conv_a): Conv3d(1024, 256, kernel_size=(3, 1, 1), stride=(1, 1, 1), padding=(1, 0, 0), bias=False)
(norm_a): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_a): ReLU()
(conv_b): Conv3d(256, 256, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1), bias=False)
(norm_b): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_b): ReLU()
(conv_c): Conv3d(256, 1024, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(norm_c): BatchNorm3d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU()
)
)
)
(1): ResStage(
(res_blocks): ModuleList(
(0): ResBlock(
(branch1_conv): Conv3d(64, 128, kernel_size=(1, 1, 1), stride=(1, 2, 2), bias=False)
(branch1_norm): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(branch2): BottleneckBlock(
(conv_a): Conv3d(64, 32, kernel_size=(3, 1, 1), stride=(1, 1, 1), padding=(1, 0, 0), bias=False)
(norm_a): BatchNorm3d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_a): ReLU()
(conv_b): Conv3d(32, 32, kernel_size=(1, 3, 3), stride=(1, 2, 2), padding=(0, 1, 1), bias=False)
(norm_b): BatchNorm3d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_b): ReLU()
(conv_c): Conv3d(32, 128, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(norm_c): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU()
)
(1-5): 5 x ResBlock(
(branch2): BottleneckBlock(
(conv_a): Conv3d(128, 32, kernel_size=(3, 1, 1), stride=(1, 1, 1), padding=(1, 0, 0), bias=False)
(norm_a): BatchNorm3d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_a): ReLU()
(conv_b): Conv3d(32, 32, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1), bias=False)
(norm_b): BatchNorm3d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_b): ReLU()
(conv_c): Conv3d(32, 128, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(norm_c): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU()
)
)
)
)
(multipathway_fusion): FuseFastToSlow(
(conv_fast_to_slow): Conv3d(128, 256, kernel_size=(7, 1, 1), stride=(4, 1, 1), padding=(3, 0, 0), bias=False)
(norm): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activation): ReLU()
)
)
(4): MultiPathWayWithFuse(
(multipathway_blocks): ModuleList(
(0): ResStage(
(res_blocks): ModuleList(
(0): ResBlock(
(branch1_conv): Conv3d(1280, 2048, kernel_size=(1, 1, 1), stride=(1, 2, 2), bias=False)
(branch1_norm): BatchNorm3d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(branch2): BottleneckBlock(
(conv_a): Conv3d(1280, 512, kernel_size=(3, 1, 1), stride=(1, 1, 1), padding=(1, 0, 0), bias=False)
(norm_a): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_a): ReLU()
(conv_b): Conv3d(512, 512, kernel_size=(1, 3, 3), stride=(1, 2, 2), padding=(0, 1, 1), bias=False)
(norm_b): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_b): ReLU()
(conv_c): Conv3d(512, 2048, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(norm_c): BatchNorm3d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU()
)
(1-2): 2 x ResBlock(
(branch2): BottleneckBlock(
(conv_a): Conv3d(2048, 512, kernel_size=(3, 1, 1), stride=(1, 1, 1), padding=(1, 0, 0), bias=False)
(norm_a): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_a): ReLU()
(conv_b): Conv3d(512, 512, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1), bias=False)
(norm_b): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_b): ReLU()
(conv_c): Conv3d(512, 2048, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(norm_c): BatchNorm3d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU()
)
)
)
(1): ResStage(
(res_blocks): ModuleList(
(0): ResBlock(
(branch1_conv): Conv3d(128, 256, kernel_size=(1, 1, 1), stride=(1, 2, 2), bias=False)
(branch1_norm): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(branch2): BottleneckBlock(
(conv_a): Conv3d(128, 64, kernel_size=(3, 1, 1), stride=(1, 1, 1), padding=(1, 0, 0), bias=False)
(norm_a): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_a): ReLU()
(conv_b): Conv3d(64, 64, kernel_size=(1, 3, 3), stride=(1, 2, 2), padding=(0, 1, 1), bias=False)
(norm_b): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_b): ReLU()
(conv_c): Conv3d(64, 256, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(norm_c): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU()
)
(1-2): 2 x ResBlock(
(branch2): BottleneckBlock(
(conv_a): Conv3d(256, 64, kernel_size=(3, 1, 1), stride=(1, 1, 1), padding=(1, 0, 0), bias=False)
(norm_a): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_a): ReLU()
(conv_b): Conv3d(64, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1), bias=False)
(norm_b): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act_b): ReLU()
(conv_c): Conv3d(64, 256, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(norm_c): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(activation): ReLU()
)
)
)
)
(multipathway_fusion): Identity()
)
(5): PoolConcatPathway(
(pool): ModuleList(
(0): AvgPool3d(kernel_size=(8, 7, 7), stride=(1, 1, 1), padding=(0, 0, 0))
(1): AvgPool3d(kernel_size=(32, 7, 7), stride=(1, 1, 1), padding=(0, 0, 0))
)
)
(6): ResNetBasicHead(
(dropout): Dropout(p=0.5, inplace=False)
(proj): Linear(in_features=2304, out_features=400, bias=True)
(output_pool): AdaptiveAvgPool3d(output_size=1)
)
)
)
事前トレーニング済みのモデルを読み込んでいるため、それを使用して推論を確認します。モデルは検出されたクラス ID を返すため、Kinetics 400 データセットの ID からクラスラベルへのマッピングをダウンロードし、後で使用するためマッピングを辞書に読み込みます。
CLASSNAMES_SOURCE = (
"https://dl.fbaipublicfiles.com/pyslowfast/dataset/class_names/kinetics_classnames.json"
)
CLASSNAMES_FILE = "kinetics_classnames.json"
download_file(url=CLASSNAMES_SOURCE, directory=DATA_DIR, show_progress=True)
# load from json
with open(DATA_DIR / CLASSNAMES_FILE, "r") as f:
kinetics_classnames = json.load(f)
# load dict of id to class label mapping
kinetics_id_to_classname = {}
for k, v in kinetics_classnames.items():
kinetics_id_to_classname[v] = str(k).replace('"', "")
data/kinetics_classnames.json: 0.00B [00:00, ?B/s]
推論を実行するサンプルビデオをダウンロードし、ダウンロードしたビデオを見てみましょう。
VIDEO_SOURCE = "https://dl.fbaipublicfiles.com/pytorchvideo/projects/archery.mp4"
VIDEO_NAME = "archery.mp4"
VIDEO_PATH = DATA_DIR / VIDEO_NAME
download_file(url=VIDEO_SOURCE, directory=DATA_DIR, show_progress=True)
Video(VIDEO_PATH, embed=True)
data/archery.mp4: 0%| | 0.00/536k [00:00<?, ?B/s]
サンプルビデオでは、推論を実行する前にいくつかの前処理が必要です。前処理中に、ビデオは正規化され、サイズが調整されます。さらに、この前処理パイプラインでは、ビデオからフレームをサンプリングして 2 つの経路を通過することも含まれます。低速経路は、入力フレームに対して大きな時間ストライドを使用する任意の畳み込みネットワークになります。高速経路は、係数 alpha (\(\alpha\)) だけ小さい時間ストライドを使用する別の畳み込みネットワークです。ここのモデルでは、両方の経路で 3D ResNet モデルが使用されます。前処理ステップを実装するため、次のヘルパー関数を定義します。
def scale_short_side(size: int, frame: np.ndarray) -> np.ndarray:
"""
Scale the short side of the frame to size and return a float
array.
"""
height = frame.shape[0]
width = frame.shape[1]
# return unchanged if short side already scaled
if (width <= height and width == size) or (height <= width and height == size):
return frame
new_width = size
new_height = size
if width < height:
new_height = int(math.floor((float(height) / width) * size))
else:
new_width = int(math.floor((float(width) / height) * size))
scaled = cv2.resize(frame, (new_width, new_height), interpolation=cv2.INTER_LINEAR)
return scaled.astype(np.float32)
def center_crop(size: int, frame: np.ndarray) -> np.ndarray:
"""
Center crop the input frame to size.
"""
height = frame.shape[0]
width = frame.shape[1]
y_offset = int(math.ceil((height - size) / 2))
x_offset = int(math.ceil((width - size) / 2))
cropped = frame[y_offset:y_offset + size, x_offset:x_offset + size, :]
assert cropped.shape[0] == size, "Image height not cropped properly"
assert cropped.shape[1] == size, "Image width not cropped properly"
return cropped
def normalize(array: np.ndarray, mean: List[float], std: List[float]) -> np.ndarray:
"""
Normalize a given array by subtracting the mean and dividing the std.
"""
if array.dtype == np.uint8:
array = array.astype(np.float32)
array = array / 255.0
mean = np.array(mean, dtype=np.float32)
std = np.array(std, dtype=np.float32)
array = array - mean
array = array / std
return array
def pack_pathway_output(frames: np.ndarray, alpha: int = 4) -> List[np.ndarray]:
"""
Prepare output as a list of arrays, each corresponding
to a unique pathway.
"""
fast_pathway = frames
# Perform temporal sampling from the fast pathway.
slow_pathway = np.take(
frames,
indices=np.linspace(0, frames.shape[1] - 1, frames.shape[1] // alpha).astype(np.int_),
axis=1
)
frame_list = [slow_pathway, fast_pathway]
return frame_list
def process_inputs(
frames: List[np.ndarray],
num_frames: int,
crop_size: int,
mean: List[float],
std: List[float],
) -> List[np.ndarray]:
"""
Performs normalization and applies required transforms
to prepare the input frames and returns a list of arrays.
Specifically the following actions are performed
1. scale the short side of the frames
2. center crop the frames to crop_size
3. perform normalization by subtracting mean and dividing std
4. sample frames for specified num_frames
5. sample frames for slow and fast pathways
"""
inputs = [scale_short_side(size=crop_size, frame=frame) for frame in frames]
inputs = [center_crop(size=crop_size, frame=frame) for frame in inputs]
inputs = np.array(inputs).astype(np.float32) / 255
inputs = normalize(array=inputs, mean=mean, std=std)
# T H W C -> C T H W
inputs = inputs.transpose([3, 0, 1, 2])
# Sample frames for num_frames specified
indices = np.linspace(0, inputs.shape[1] - 1, num_frames).astype(np.int_)
inputs = np.take(inputs, indices=indices, axis=1)
# prepare pathways for the model
inputs = pack_pathway_output(inputs)
inputs = [np.expand_dims(inp, 0) for inp in inputs]
return inputs
指定されたモデルを使用してカスタムビデオで推論を実行する別のヘルパーメソッド。
def run_inference(
model: Any,
video_path: str,
top_k: int,
id_to_label_mapping: Dict[str, str],
num_frames: int,
sampling_rate: int,
crop_size: int,
mean: List[float],
std: List[float],
) -> List[str]:
"""
Run inference on the video given by video_path using the given model.
First, the video is loaded from source. Frames are collected, processed
and fed to the model. The top top_k predicted class IDs are converted to class
labels and returned as a list of strings.
"""
video_cap = cv2.VideoCapture(video_path)
frames = []
seq_length = num_frames * sampling_rate
# get the list of frames from the video
ret = True
while ret and len(frames) < seq_length:
ret, frame = video_cap.read()
frames.append(frame)
# prepare the inputs
inputs = process_inputs(
frames=frames, num_frames=num_frames, crop_size=crop_size, mean=mean, std=std
)
if isinstance(model, ov.CompiledModel):
# openvino compiled model
output_blob = model.output(0)
predictions = model(inputs)[output_blob]
else:
# pytorch model
predictions = model([torch.from_numpy(inp) for inp in inputs])
predictions = predictions.detach().cpu().numpy()
def softmax(x):
return (np.exp(x) / np.exp(x).sum(axis=None))
# apply activation
predictions = softmax(predictions)
# top k predicted class IDs
topk = 5
pred_classes = np.argsort(-1 * predictions, axis=1)[:, :topk]
# Map the predicted classes to the label names
pred_class_names = [id_to_label_mapping[int(i)] for i in pred_classes[0]]
return pred_class_names
入力を処理するモデル固有のパラメーターを定義し、それを使用して推論を実行します。上位 5 つの予測は以下で確認できます。
NUM_FRAMES = 32
SAMPLING_RATE = 2
CROP_SIZE = 256
MEAN = [0.45, 0.45, 0.45]
STD = [0.225, 0.225, 0.225]
TOP_K = 5
predictions = run_inference(
model=model,
video_path=str(VIDEO_PATH),
top_k=TOP_K,
id_to_label_mapping=kinetics_id_to_classname,
num_frames=NUM_FRAMES,
sampling_rate=SAMPLING_RATE,
crop_size=CROP_SIZE,
mean=MEAN,
std=STD,
)
print(f"Predicted labels: {', '.join(predictions)}")
モデルを OpenVINO 中間表現に変換¶
トレーニング済みのモデルを取得し、それを使用して推論を確認したので、PyTorch モデルを OpenVINO IR 形式にエクスポートします。この形式では、ネットワークは 2 つのファイルを使用して表現されます。1 つはネットワーク・アーキテクチャーを記述する xml ファイル、もう 1 つは畳み込み重みなどの定数値をバイナリー形式で格納する付随するバイナリーファイルです。次のように、モデル変換 API を使用して IR 形式に変換できます。ov.convert_model メソッドは、コンパイルして推論するか、シリアル化できる ov.Model オブジェクトを返します。
class ModelWrapper(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = model
def forward(self, input):
return model(list(input))
dummy_input = [torch.randn((1, 3, 8, 256, 256)), torch.randn([1, 3, 32, 256, 256])]
model = ov.convert_model(ModelWrapper(model), example_input=(dummy_input,))
IR_PATH = MODEL_DIR / "slowfast-r50.xml"
# serialize model for saving IR
ov.save_model(model=model, output_model=str(IR_PATH), compress_to_fp16=False)
次に、OpenVINO ランタイムを使用してシリアル化されたモデルを読み取ってコンパイルします。read_model 関数では、.bin 重みファイルが .xmlファイルと同じファイル名を持ち、同じディレクトリーに配置されていることが想定されています。重みファイルのファイル名が異なる場合は、weights パラメーターを使用して指定できます。
core = ov.Core()
# read converted model
conv_model = core.read_model(str(IR_PATH))
推論デバイスの選択¶
OpenVINO を使用して推論を実行するためにドロップダウン・リストからデバイスを選択します。
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='AUTO',
description='Device:',
disabled=False,
)
device
Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')
# load model on device
compiled_model = core.compile_model(model=conv_model, device_name=device.value)
モデルの推論を検証¶
コンパイルされたモデルを使用して、同じサンプルビデオで推論を実行し、上位 5 つの予測を再度出力します。
pred_class_names = run_inference(
model=compiled_model,
video_path=str(VIDEO_PATH),
top_k=TOP_K,
id_to_label_mapping=kinetics_id_to_classname,
num_frames=NUM_FRAMES,
sampling_rate=SAMPLING_RATE,
crop_size=CROP_SIZE,
mean=MEAN,
std=STD,
)
print(f"Predicted labels: {', '.join(pred_class_names)}")
Predicted labels: archery, throwing axe, playing paintball, golf driving, riding or walking with horse