MobileVLM と OpenVINO によるモバイル言語アシスタント¶
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

MobileVLM は、モバイルデバイス上で実行することを目的とした適格なマルチモーダル・ビジョン言語モデル (MMVLM) です。これは、モバイル指向のアーキテクチャー設計と技術の融合であり、ゼロからトレーニングされた 1.4B および 2.7B パラメーターのスケールの言語モデルのセットと、CLIP 方式で事前トレーニングされたマルチモーダル・ビジョン・モデル、効率的なプロジェクターを介したクロスモダリティー・インタラクションです。
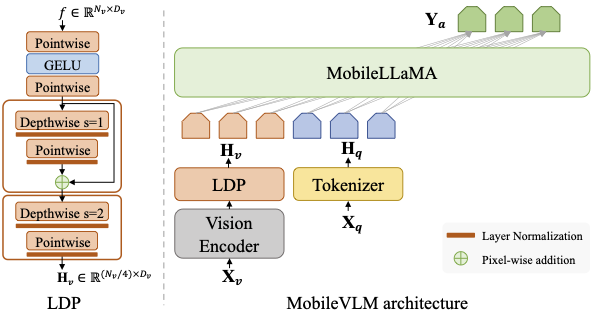
MobileVLM アーキテクチャー (右) は、言語モデルとして MobileLLaMA を利用し、画像と言語の命令である \(\mathbf{X}_v\) と \(\mathbf{X}_q\) をそれぞれの入力として取り込み、\(\mathbf{Y}_a\) を出力言語応答として使用します。LDP は軽量のダウンサンプル・プロジェクターを指します (左)。
詳細については、公式 GitHub プロジェクト・ページと論文を参照してください。
目次¶
要件をインストール¶
%pip install -q "torch>=2.0.1" "timm>=0.9.12" --extra-index-url "https://download.pytorch.org/whl/cpu"
%pip install -q "transformers>=4.33.1,<4.35.0" accelerate "sentencepiece>=0.1.99" "openvino>=2023.2.0" "nncf>=2.7.0" ipywidgets numpy gradio
DEPRECATION: pytorch-lightning 1.6.5 has a non-standard dependency specifier torch>=1.8.*. pip 24.1 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of pytorch-lightning or contact the author to suggest that they release a version with a conforming dependency specifiers. Discussion can be found at https://github.com/pypa/pip/issues/12063
Note: you may need to restart the kernel to use updated packages.
DEPRECATION: pytorch-lightning 1.6.5 has a non-standard dependency specifier torch>=1.8.*. pip 24.1 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of pytorch-lightning or contact the author to suggest that they release a version with a conforming dependency specifiers. Discussion can be found at https://github.com/pypa/pip/issues/12063
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
datasets 2.17.0 requires huggingface-hub>=0.19.4, but you have huggingface-hub 0.17.3 which is incompatible.
diffusers 0.26.2 requires huggingface-hub>=0.20.2, but you have huggingface-hub 0.17.3 which is incompatible.
pyannote-audio 2.0.1 requires torchaudio<1.0,>=0.10, but you have torchaudio 2.2.0+cpu which is incompatible.
Note: you may need to restart the kernel to use updated packages.
MobileVLM リポジトリーのクローンを作成¶
from pathlib import Path
import sys
MOBILEVLM_REPO_DIR = Path("./MobileVLM")
if not MOBILEVLM_REPO_DIR.exists():
!git clone -q "https://github.com/Meituan-AutoML/MobileVLM.git"
sys.path.insert(0, str(MOBILEVLM_REPO_DIR))
必要なパッケージをインポート¶
import warnings
import itertools
import gc
from typing import Optional, List, Tuple
from mobilevlm.model.mobilevlm import load_pretrained_model
from mobilevlm.conversation import conv_templates, SeparatorStyle
from mobilevlm.utils import (
disable_torch_init,
process_images,
tokenizer_image_token,
KeywordsStoppingCriteria,
)
from mobilevlm.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN
import PIL
import torch
import transformers
import numpy as np
import gradio as gr
import openvino as ov
import nncf
import ipywidgets as widgets
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/transformers/utils/generic.py:311: UserWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead.
torch.utils._pytree._register_pytree_node(
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/transformers/utils/generic.py:311: UserWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead.
torch.utils._pytree._register_pytree_node(
2024-02-10 00:45:20.724190: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0. 2024-02-10 00:45:20.759074: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-02-10 00:45:21.267446: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
INFO:nncf:NNCF initialized successfully. Supported frameworks detected: torch, tensorflow, onnx, openvino
MODELS_DIR = Path("./models")
MODEL_PATH = 'mtgv/MobileVLM-1.7B'
TEMPERATURE = 0.2
TOP_P = None
NUM_BEAMS = 1
MAX_NEW_TOKENS = 512
IMAGE_PATH = MOBILEVLM_REPO_DIR / "assets" / "samples" / "demo.jpg"
PROMPT_STR = "Who is the author of this book?\nAnswer the question using a single word or phrase."
モデルのロード¶
モデルをロードするには、mobilevlm モジュールで事前定義されたload_pretrained_model 関数を使用します。モデル自身、トークナイザー、および画像を適切なテンソルに変換する画像プロセッサーを返します。
model_name = MODEL_PATH.split('/')[-1]
disable_torch_init()
with warnings.catch_warnings():
warnings.simplefilter("ignore")
tokenizer, model, image_processor, _ = load_pretrained_model(MODEL_PATH, device="cpu")
model = model.to(dtype=torch.float32)
モデルを OpenVINO 中間表現 (IR) に変換¶
def cleanup_torchscript_cache():
"""
Helper for removing cached model representation
"""
torch._C._jit_clear_class_registry()
torch.jit._recursive.concrete_type_store = torch.jit._recursive.ConcreteTypeStore()
torch.jit._state._clear_class_state()
メモリー消費を削減するため、NNCF を使用して重み圧縮を最適化できます。重み圧縮は、モデルのメモリー使用量を削減することを目的としています。また、大規模言語モデル (LLM) など、メモリーに依存する大規模なモデルのパフォーマンスを大幅に向上することもできます。LLM やその他のモデルは、推論中に重みを保存する大量のメモリーを必要とするため、次の方法で重み圧縮の利点を得られます。
デバイスのメモリーに格納できない大規模なモデルの推論を可能にします。
線形レイヤーなどの重みを使用した演算を行う際のメモリーアクセス・レイテンシーを短縮することで、モデルの推論パフォーマンスを向上させます。
ニューラル・ネットワーク圧縮フレームワーク (NNCF) は、主に LLM の最適化向けに設計された圧縮方法として、4 ビット/8 ビット混合重み量子化を提供します。重み圧縮とフルモデル量子化 (トレーニング後の量子化) の違いは、重み圧縮のでは、アクティベーションが浮動小数点のままであるため、精度が向上することです。LLM の重み圧縮は、完全なモデル量子化のパフォーマンスに匹敵する推論パフォーマンスの向上をもたらします。さらに、重み圧縮はデータに依存せず、キャリブレーション・データセットも必要としないため、容易に利用できます。
nncf.compress_weights 関数は重み圧縮の実行に使用できます。この関数は、OpenVINO モデルとその他の圧縮パラメーターを受け入れます。INT8 圧縮と比較して、INT4 圧縮はパフォーマンスをさらに向上させますが、予測品質は若干低下します。
重み圧縮の詳細については、OpenVINO のドキュメントを参照してください。
INT8 重み圧縮の代わりに INT4 重み圧縮を実行するかどうかは、以下で選択してください。
compression_mode = widgets.Dropdown(
options=['INT4', 'INT8'],
value='INT4',
description='Compression mode:',
disabled=False,
)
compression_mode
Dropdown(description='Compression mode:', options=('INT4', 'INT8'), value='INT4')
stage1_xml_path = MODELS_DIR / f"stage1_{compression_mode.value}.xml"
stage2_xml_path = MODELS_DIR / f"stage2_{compression_mode.value}.xml"
if compression_mode.value == 'INT4':
wc_parameters = dict(mode=nncf.CompressWeightsMode.INT4_ASYM, group_size=128, ratio=0.8)
else:
wc_parameters = dict(mode=nncf.CompressWeightsMode.INT8)
class ModelWrapper(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = model
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None
):
outputs = self.model.model(
input_ids=input_ids,
attention_mask=attention_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds
)
hidden_states = outputs[0]
logits = self.model.lm_head(hidden_states)
return (logits,) + outputs[1:]
def set_input_names(model, past_key_values):
input_names = [
"input_ids",
"attention_mask",
*itertools.chain.from_iterable(
[f"past_key_values.{idx}.key", f"past_key_values.{idx}.value"]
for idx, _ in enumerate(past_key_values)
),
]
assert len(input_names) == len(model.inputs)
for _input, input_name in zip(model.inputs, input_names):
_input.get_tensor().set_names({input_name})
def set_output_names(model, past_key_values):
output_names = [
"logits",
*itertools.chain.from_iterable(
[f"present.{idx}.key", f"present.{idx}.value"]
for idx, _ in enumerate(past_key_values)
),
]
assert len(output_names) == len(model.outputs)
for out, out_name in zip(ov_model.outputs, output_names):
out.get_tensor().set_names({out_name})
example_input = {
"inputs_embeds": torch.zeros((1, 205, 2048)),
"attention_mask": torch.ones((1, 205), dtype=torch.long),
}
wrapped = ModelWrapper(model)
past_key_values = wrapped(**example_input)[1]
if not stage1_xml_path.exists():
ov_model = ov.convert_model(wrapped, example_input=example_input)
set_output_names(ov_model, past_key_values)
ov_model = nncf.compress_weights(ov_model, **wc_parameters)
ov.save_model(ov_model, stage1_xml_path)
cleanup_torchscript_cache()
del ov_model
gc.collect()
WARNING:tensorflow:Please fix your imports. Module tensorflow.python.training.tracking.base has been moved to tensorflow.python.trackable.base. The old module will be deleted in version 2.11.
[ WARNING ] Please fix your imports. Module %s has been moved to %s. The old module will be deleted in version %s.
WARNING:nncf:NNCF provides best results with torch==2.1.2, while current torch version is 2.2.0+cpu. If you encounter issues, consider switching to torch==2.1.2
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/transformers/models/llama/modeling_llama.py:808: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if input_shape[-1] > 1:
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/transformers/models/llama/modeling_llama.py:146: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if seq_len > self.max_seq_len_cached:
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/transformers/models/llama/modeling_llama.py:375: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/transformers/models/llama/modeling_llama.py:382: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/transformers/models/llama/modeling_llama.py:392: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
Output()
INFO:nncf:Statistics of the bitwidth distribution:
+--------------+---------------------------+-----------------------------------+
| Num bits (N) | % all parameters (layers) | % ratio-defining parameters |
| | | (layers) |
+==============+===========================+===================================+
| 8 | 24% (43 / 169) | 20% (42 / 168) |
+--------------+---------------------------+-----------------------------------+
| 4 | 76% (126 / 169) | 80% (126 / 168) |
+--------------+---------------------------+-----------------------------------+
Output()
example_input = {
"input_ids": torch.ones((1, 1), dtype=torch.long),
"past_key_values": past_key_values,
"attention_mask": torch.ones((1, past_key_values[-1][-1].shape[-2] + 1), dtype=torch.long),
}
if not stage2_xml_path.exists():
ov_model = ov.convert_model(
wrapped,
example_input=example_input,
)
set_input_names(ov_model, past_key_values)
set_output_names(ov_model, past_key_values)
ov_model = nncf.compress_weights(ov_model, **wc_parameters)
ov.save_model(ov_model, stage2_xml_path)
cleanup_torchscript_cache()
del ov_model
gc.collect()
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/torch/jit/_trace.py:165: UserWarning: The .grad attribute of a Tensor that is not a leaf Tensor is being accessed. Its .grad attribute won't be populated during autograd.backward(). If you indeed want the .grad field to be populated for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-leaf Tensor by mistake, make sure you access the leaf Tensor instead. See github.com/pytorch/pytorch/pull/30531 for more informations. (Triggered internally at aten/src/ATen/core/TensorBody.h:489.)
if a.grad is not None:
Output()
INFO:nncf:Statistics of the bitwidth distribution:
+--------------+---------------------------+-----------------------------------+
| Num bits (N) | % all parameters (layers) | % ratio-defining parameters |
| | | (layers) |
+==============+===========================+===================================+
| 8 | 28% (44 / 170) | 20% (42 / 168) |
+--------------+---------------------------+-----------------------------------+
| 4 | 72% (126 / 170) | 80% (126 / 168) |
+--------------+---------------------------+-----------------------------------+
Output()
prepare_inputs_labels_for_multimodal = model.prepare_inputs_labels_for_multimodal
prepare_inputs_for_generation = model.prepare_inputs_for_generation
config = model.config
config.save_pretrained(MODELS_DIR)
del wrapped
del model
gc.collect();
推論¶
OVMobileLlamaForCausalLM クラスは、生成シナリオでモデルを使用するのに使いやすいインターフェイスを提供します。これは、Hugging Face Transformers ライブラリーに実装されている生成のすべてのリーチ機能を再利用する可能性をもたらす、transformers.generation.GenerationMixin に基づいています。このインターフェースの詳細については、Hugging Face のドキュメントを参照してください。
class OVMobileLlamaForCausalLM(transformers.GenerationMixin):
def __init__(self, stage1_path, stage2_path, device):
self.stage1 = core.compile_model(stage1_path, device)
self.stage2 = core.read_model(stage2_path)
self.generation_config = transformers.GenerationConfig.from_model_config(config)
self.config = transformers.AutoConfig.from_pretrained(MODELS_DIR)
self.main_input_name = "input_ids"
self.device = torch.device("cpu")
self.prepare_inputs_for_generation = prepare_inputs_for_generation
self.num_pkv = 2
self.input_names = {key.get_any_name(): idx for idx, key in enumerate(self.stage2.inputs)}
self.output_names = {key.get_any_name(): idx for idx, key in enumerate(self.stage2.outputs)}
self.key_value_input_names = [key for key in self.input_names if "key_values" in key]
self.key_value_output_names = [key for key in self.output_names if "present" in key]
stage2 = core.compile_model(self.stage2, device)
self.request = stage2.create_infer_request()
def can_generate(self):
"""Returns True to validate the check that the model using `GenerationMixin.generate()` can indeed generate."""
return True
def __call__(
self,
input_ids: torch.LongTensor,
images: torch.Tensor,
attention_mask: Optional[torch.LongTensor] = None,
prefix_mask: Optional[torch.LongTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
**kwargs,
) -> transformers.modeling_outputs.CausalLMOutputWithPast:
return self.forward(input_ids, images, attention_mask, prefix_mask, past_key_values)
def forward(
self,
input_ids: torch.LongTensor,
images: torch.Tensor,
attention_mask: Optional[torch.LongTensor] = None,
prefix_mask: Optional[torch.LongTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
**kwargs,
) -> transformers.modeling_outputs.CausalLMOutputWithPast:
"""General inference method"""
inputs = {}
if past_key_values is not None:
# Flatten the past_key_values
attention_mask = torch.ones(
(input_ids.shape[0], past_key_values[-1][-1].shape[-2] + 1),
dtype=input_ids.dtype,
)
past_key_values = tuple(
past_key_value
for pkv_per_layer in past_key_values
for past_key_value in pkv_per_layer
)
# Add the past_key_values to the decoder inputs
inputs = dict(zip(self.key_value_input_names, past_key_values))
else:
return self.forward_with_image(input_ids, images, attention_mask)
inputs["input_ids"] = np.array(input_ids)
if "attention_mask" in self.input_names:
inputs["attention_mask"] = np.array(attention_mask)
# Run inference
self.request.start_async(inputs, share_inputs=True)
self.request.wait()
logits = torch.from_numpy(self.request.get_tensor("logits").data)
# Tuple of length equal to : number of layer * number of past_key_value per decoder layer (2 corresponds to the self-attention layer)
past_key_values = tuple(
self.request.get_tensor(key).data for key in self.key_value_output_names
)
# Tuple of tuple of length `n_layers`, with each tuple of length equal to 2 (k/v of self-attention)
past_key_values = tuple(
past_key_values[i : i + self.num_pkv]
for i in range(0, len(past_key_values), self.num_pkv)
)
return transformers.modeling_outputs.CausalLMOutputWithPast(
logits=logits, past_key_values=past_key_values
)
def forward_with_image(self, input_ids, images, attention_mask):
"""First step inference method, that resolves multimodal data"""
_, attention_mask, _, input_embed, _ = prepare_inputs_labels_for_multimodal(
input_ids, attention_mask, images=images, past_key_values=None, labels=None
)
outs = self.stage1({"inputs_embeds": input_embed, "attention_mask": attention_mask})
logits = outs[0]
pkv = list(outs.values())[1:]
pkv = tuple(pkv[i : i + self.num_pkv] for i in range(0, len(pkv), self.num_pkv))
return transformers.modeling_outputs.CausalLMOutputWithPast(
logits=torch.from_numpy(logits), past_key_values=pkv
)
モデルと生成パイプラインを定義したら、モデル推論を実行できます。
OpenVINO を使用して推論を実行するデバイスをドロップダウン・リストから選択します。
core = ov.Core()
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value="AUTO",
description="Device:",
disabled=False,
)
device
Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')
OpenVINO モデルのロード¶
ov_model = OVMobileLlamaForCausalLM(stage1_xml_path, stage2_xml_path, device.value)
入力データを準備¶
images = [PIL.Image.open(IMAGE_PATH).convert("RGB")]
images_tensor = process_images(
images, image_processor, transformers.AutoConfig.from_pretrained(MODELS_DIR)
)
conv = conv_templates["v1"].copy()
conv.append_message(conv.roles[0], DEFAULT_IMAGE_TOKEN + "\n" + PROMPT_STR)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
input_ids = tokenizer_image_token(
prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors="pt"
).unsqueeze(0)
stopping_criteria = KeywordsStoppingCriteria([stop_str], tokenizer, input_ids)
print(PROMPT_STR)
images[0]
Who is the author of this book?
Answer the question using a single word or phrase.

生成プロセスの実行¶
output_ids = ov_model.generate(
input_ids,
images=images_tensor,
do_sample=True if TEMPERATURE > 0 else False,
temperature=TEMPERATURE,
top_p=TOP_P,
num_beams=NUM_BEAMS,
max_new_tokens=MAX_NEW_TOKENS,
use_cache=True,
stopping_criteria=[stopping_criteria],
)
input_token_len = input_ids.shape[1]
n_diff_input_output = (input_ids != output_ids[:, :input_token_len]).sum().item()
if n_diff_input_output > 0:
print(f"[Warning] {n_diff_input_output} output_ids are not the same as the input_ids")
outputs = tokenizer.batch_decode(output_ids[:, input_token_len:], skip_special_tokens=True)[0]
outputs = outputs.strip()
if outputs.endswith(stop_str):
outputs = outputs[: -len(stop_str)]
print(f"🚀 {model_name} with OpenVINO: {outputs.strip()}\n")
🚀 MobileVLM-1.7B with OpenVINO: Susan Wise Bauer
インタラクティブな推論¶
def generate(img, prompt):
images_tensor = process_images(
[img], image_processor, transformers.AutoConfig.from_pretrained(MODELS_DIR)
)
prompt = DEFAULT_IMAGE_TOKEN + "\n" + prompt
conv = conv_templates["v1"].copy()
conv.append_message(conv.roles[0], prompt)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
input_ids = tokenizer_image_token(
prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors="pt"
).unsqueeze(0)
stopping_criteria = KeywordsStoppingCriteria([stop_str], tokenizer, input_ids)
output_ids = ov_model.generate(
input_ids,
images=images_tensor,
do_sample=True if TEMPERATURE > 0 else False,
temperature=TEMPERATURE,
top_p=TOP_P,
num_beams=NUM_BEAMS,
max_new_tokens=MAX_NEW_TOKENS,
use_cache=True,
stopping_criteria=[stopping_criteria],
)
input_token_len = input_ids.shape[1]
outputs = tokenizer.batch_decode(output_ids[:, input_token_len:], skip_special_tokens=True)[0]
outputs = outputs.strip()
if outputs.endswith(stop_str):
outputs = outputs[: -len(stop_str)]
return outputs.strip()
demo = gr.Interface(
generate,
[gr.Image(label="Image", type="pil"), gr.Textbox(label="Prompt")],
gr.Textbox(),
examples=[
[
str(IMAGE_PATH),
PROMPT_STR,
]
],
allow_flagging="never"
)
try:
demo.launch(debug=False)
except Exception:
demo.launch(debug=False, share=True)
# if you are launching remotely, specify server_name and server_port
# demo.launch(server_name='your server name', server_port='server port in int')
# Read more in the docs: https://gradio.app/docs/
Running on local URL: http://127.0.0.1:7860 To create a public link, set share=True in launch().