OpenVINO™ によるテキスト予測¶
この Jupyter ノートブックはオンラインで起動でき、ブラウザーのウィンドウで対話型環境を開きます。ローカルにインストールすることもできます。次のオプションのいずれかを選択します。


このノートブックは、OpenVINO を使用したテキスト予測を示しています。このノートブックは、テキスト生成と会話の 2 つの異なるモードで動作し、ユーザーはモデル選択セクションでモデルを選択できます。 ここでは、Generative Pre-trained Transformer (GPT) ファミリーの一部である GPT-2、GPT-Neo、および PersonaGPT の 3 つのモデルを使用します。GPT-2 と GPT-Neo はテキスト生成に使用できますが、PersonaGPT は会話の下流タスク用にトレーニングされています。
また、GPT-2 と GPT-Neo は、教師なしトレーニングを使用して、大規模な英語テキストコーパスで事前トレーニングされています。どちらも、前例のない品質の条件付き合成テキストサンプルを生成する能力など、幅広い機能を備えています。
モデルに関する詳細は、Hugging Face カードに記載されています。
PersonaGPT は、ユーザー入力に基づいてパーソナライズされ制御された応答をデコードできるオープンドメインの会話エージェントです。これは、GPT-2 アーキテクチャーに従って、事前トレーニング済みの DialoGPT-medium モデル上に構築されています。PersonaGPT は、Persona-Chat データセットで微調整されています。このモデルは Hugging Face から入手できます。PersonaGPT は、ペルソナの機能を含む幅広い機能を備えています。ペルソナでは、いくつかの事実でモデルを準備し、それに基づいて生成します。また、ナレッジベースでチャットボットを作成することもできます。
次の画像は、テキスト生成に使用される完全なデモ・パイプラインを示しています。
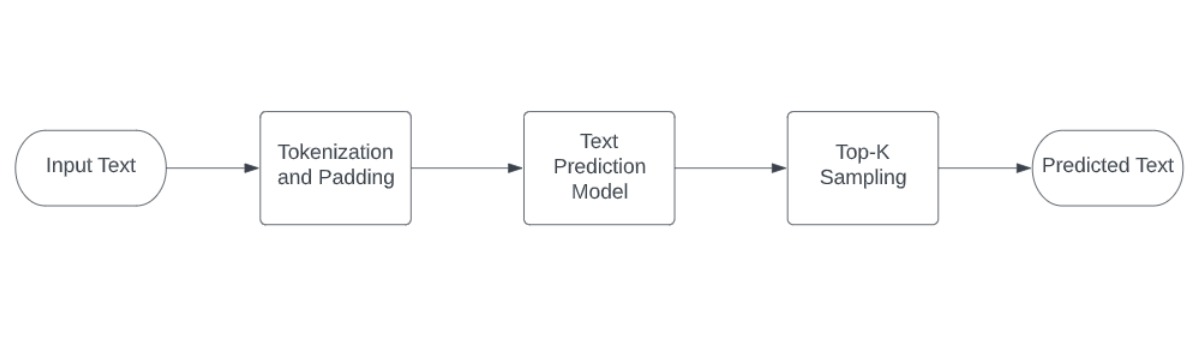
image2¶
これは、ユーザーがテキストの冒頭を入力すると、ネットワークがさらにテキストを生成するというデモンストレーションです。この手順は、ユーザーが望む回数だけ繰り返すことができます。
テキスト生成の場合、モデル入力はトークン化されたテキストであり、テキスト生成の初期条件として機能します。次に、モデルの推論結果からロジットを取得し、トップ k サンプリングを使用して最も高い確率を持つトークンを選択し、入力シーケンスに結合します。この手順は、シーケンスのトークン終了が受信されるか、指定された最大長に達するまで繰り返されます。その後、トークン化された ID はテキストにデコードされます。
次の画像は、会話のデモ・パイプラインを示しています。
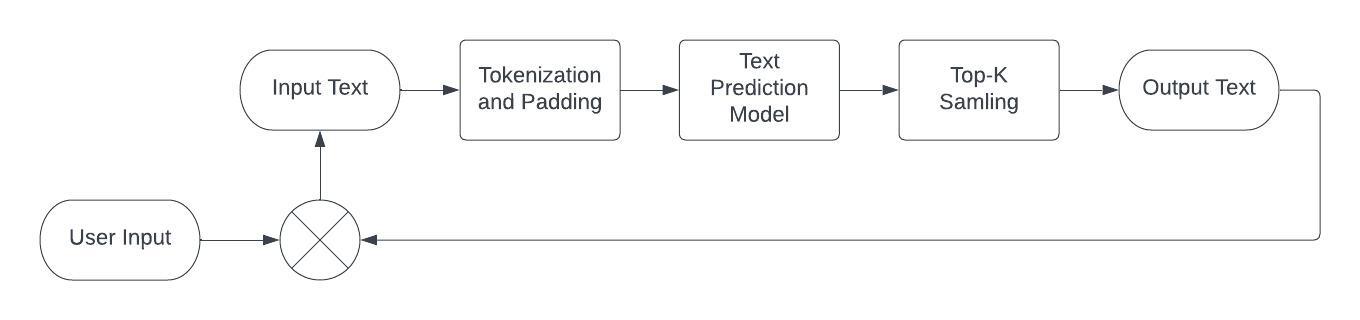
image2¶
会話の場合、ユーザー入力はトークン化され、最後に eos_token が連結されます。その後、上記のようにテキストが生成されます。生成された応答は、末尾に eos_token を付けて履歴に追加されます。追加のユーザー入力が履歴に追加され、シーケンスがモデルに返されます。
目次¶
モデルの選択¶
テキスト生成に使用するモデルを選択します。GPT-2 と GPT-Neo はテキスト生成に使用され、PersonaGPT は会話に使用されます。
%pip install -q "openvino>=2023.1.0"
%pip install -q gradio
%pip install -q --extra-index-url https://download.pytorch.org/whl/cpu transformers[torch]
DEPRECATION: pytorch-lightning 1.6.5 has a non-standard dependency specifier torch>=1.8.*. pip 24.1 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of pytorch-lightning or contact the author to suggest that they release a version with a conforming dependency specifiers. Discussion can be found at https://github.com/pypa/pip/issues/12063
Note: you may need to restart the kernel to use updated packages.
DEPRECATION: pytorch-lightning 1.6.5 has a non-standard dependency specifier torch>=1.8.*. pip 24.1 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of pytorch-lightning or contact the author to suggest that they release a version with a conforming dependency specifiers. Discussion can be found at https://github.com/pypa/pip/issues/12063
Note: you may need to restart the kernel to use updated packages.
DEPRECATION: pytorch-lightning 1.6.5 has a non-standard dependency specifier torch>=1.8.*. pip 24.1 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of pytorch-lightning or contact the author to suggest that they release a version with a conforming dependency specifiers. Discussion can be found at https://github.com/pypa/pip/issues/12063
Note: you may need to restart the kernel to use updated packages.
import ipywidgets as widgets
style = {'description_width': 'initial'}
model_name = widgets.Select(
options=['PersonaGPT (Converastional)', 'GPT-2', 'GPT-Neo'],
value='PersonaGPT (Converastional)',
description='Select Model:',
disabled=False
)
widgets.VBox([model_name])
VBox(children=(Select(description='Select Model:', options=('PersonaGPT (Converastional)', 'GPT-2', 'GPT-Neo')…
モデルのロード¶
Hugging Face から選択したモデルとトークナイザーをダウンロードします。
from transformers import GPTNeoForCausalLM, GPT2TokenizerFast, GPT2Tokenizer, GPT2LMHeadModel
if model_name.value == "PersonaGPT (Converastional)":
pt_model = GPT2LMHeadModel.from_pretrained('af1tang/personaGPT')
tokenizer = GPT2Tokenizer.from_pretrained('af1tang/personaGPT')
elif model_name.value == 'GPT-2':
pt_model = GPT2LMHeadModel.from_pretrained('gpt2')
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
elif model_name.value == 'GPT-Neo':
pt_model = GPTNeoForCausalLM.from_pretrained('EleutherAI/gpt-neo-125M')
tokenizer = GPT2TokenizerFast.from_pretrained('EleutherAI/gpt-neo-125M')
PyTorch モデルから OpenVINO IR への変換¶
OpenVINO を使用して GPT-Neo モデルでの作業を開始するには、モデルを OpenVINO 中間表現 (IR) 形式に変換する必要があります。Hugging Face は PyTorch 形式の GPT-Neo モデルを提供しており、これはモデル変換 API を介して OpenVINO でサポートされています。モデル変換 API の ov.convert_model 関数を使用してモデルを変換できます。この関数は、Python インターフェイスで使用できる OpenVINO モデルクラスのインスタンスを返します。モデルは、ov.save_model を使用して、将来実行するため OpenVINO IR 形式でデバイスに保存することもできます。ここでは、メモリー消費を最適化するため、可能な形状範囲 (1 トークンから処理関数で定義された最大長まで) を持つ動的入力形状が指定されます。
from pathlib import Path
import torch
import openvino as ov
# define path for saving openvino model
model_path = Path("model/text_generator.xml")
example_input = {"input_ids": torch.ones((1, 10), dtype=torch.long), "attention_mask": torch.ones((1, 10), dtype=torch.long)}
pt_model.config.torchscript = True
# convert model to openvino
if model_name.value == "PersonaGPT (Converastional)":
ov_model = ov.convert_model(pt_model, example_input=example_input, input=[('input_ids', [1, -1], ov.Type.i64), ('attention_mask', [1,-1], ov.Type.i64)])
else:
ov_model = ov.convert_model(pt_model, example_input=example_input, input=[('input_ids', [1, ov.Dimension(1,128)], ov.Type.i64), ('attention_mask', [1, ov.Dimension(1,128)], ov.Type.i64)])
# serialize openvino model
ov.save_model(ov_model, str(model_path))
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/transformers/models/gpt2/modeling_gpt2.py:801: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if batch_size <= 0:
モデルのロード¶
まず、OpenVINO Core オブジェクトを構築します。次に、.xml および .bin ファイルからネットワーク・アーキテクチャーとモデルの重みを読み取ります。最後に、目的のデバイス用にモデルをコンパイルします。
推論デバイスの選択¶
OpenVINO を使用して推論を実行するためにドロップダウン・リストからデバイスを選択します。
import ipywidgets as widgets
# initialize openvino core
core = ov.Core()
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='AUTO',
description='Device:',
disabled=False,
)
device
Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')
# read the model and corresponding weights from file
model = core.read_model(model_path)
# compile the model for CPU devices
compiled_model = core.compile_model(model=model, device_name=device.value)
# get output tensors
output_key = compiled_model.output(0)
入力キーは入力ノードの名前であり、出力キーにはネットワークの出力ノードの名前が含まれます。GPT-Neo の場合、バッチサイズとシーケンス長が入力として、バッチサイズ、シーケンス長、語彙サイズが出力として使用されます。
前処理¶
NLP モデルは通常、トークンのリストを標準入力として受け取ります。トークンは整数にマッピングされた単語または単語の一部です。適切な入力を提供するため、語彙ファイルを使用してマッピングを処理します。まず語彙ファイルをロードしましょう。
トークン化の定義¶
from typing import List, Tuple
# this function converts text to tokens
def tokenize(text: str) -> Tuple[List[int], List[int]]:
"""
tokenize input text using GPT2 tokenizer
Parameters:
text, str - input text
Returns:
input_ids - np.array with input token ids
attention_mask - np.array with 0 in place, where should be padding and 1 for places where original tokens are located, represents attention mask for model
"""
inputs = tokenizer(text, return_tensors="np")
return inputs["input_ids"], inputs["attention_mask"]
eos_token は特別なトークンであり、生成が終了したことを意味します。このインデックスを後のステージでパディングとして使用するため、このトークンのインデックスを保存します。
eos_token_id = tokenizer.eos_token_id
eos_token = tokenizer.decode(eos_token_id)
2024-02-09 23:53:22.771432: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0. 2024-02-09 23:53:22.804649: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-02-09 23:53:23.373829: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
ソフトマックス・レイヤーを定義¶
ソフトマックス関数は、トップ k ロジットを確率分布に変換するために使用されます。
import numpy as np
def softmax(x : np.array) -> np.array:
e_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
summation = e_x.sum(axis=-1, keepdims=True)
return e_x / summation
最小シーケンス長を設定¶
最小シーケンス長に達していない場合、次のコードにより eos トークンが発生する確率が低下します。これにより、次の単語を生成するプロセスが継続されます。
def process_logits(cur_length: int, scores: np.array, eos_token_id : int, min_length : int = 0) -> np.array:
"""
Reduce probability for padded indices.
Parameters:
cur_length: Current length of input sequence.
scores: Model output logits.
eos_token_id: Index of end of string token in model vocab.
min_length: Minimum length for applying postprocessing.
Returns:
Processed logits with reduced probability for padded indices.
"""
if cur_length < min_length:
scores[:, eos_token_id] = -float("inf")
return scores
Top-K サンプリング¶
Top-K サンプリングでは、最も可能性の高い K 個の次の単語をフィルター処理し、それらの K 個の次の単語の間でのみ確率質量を再分配します。
def get_top_k_logits(scores : np.array, top_k : int) -> np.array:
"""
Perform top-k sampling on the logits scores.
Parameters:
scores: np.array, model output logits.
top_k: int, number of elements with the highest probability to select.
Returns:
np.array, shape (batch_size, sequence_length, vocab_size),
filtered logits scores where only the top-k elements with the highest
probability are kept and the rest are replaced with -inf
"""
filter_value = -float("inf")
top_k = min(max(top_k, 1), scores.shape[-1])
top_k_scores = -np.sort(-scores)[:, :top_k]
indices_to_remove = scores < np.min(top_k_scores)
filtred_scores = np.ma.array(scores, mask=indices_to_remove,
fill_value=filter_value).filled()
return filtred_scores
メイン処理関数¶
予測されたシーケンスを生成します。
def generate_sequence(input_ids : List[int], attention_mask : List[int], max_sequence_length : int = 128,
eos_token_id : int = eos_token_id, dynamic_shapes : bool = True) -> List[int]:
"""
Generates a sequence of tokens using a pre-trained language model.
Parameters:
input_ids: np.array, tokenized input ids for model
attention_mask: np.array, attention mask for model
max_sequence_length: int, maximum sequence length for stopping iteration
eos_token_id: int, index of the end-of-sequence token in the model's vocabulary
dynamic_shapes: bool, whether to use dynamic shapes for inference or pad model input to max_sequence_length
Returns:
np.array, the predicted sequence of token ids
"""
while True:
cur_input_len = len(input_ids[0])
if not dynamic_shapes:
pad_len = max_sequence_length - cur_input_len
model_input_ids = np.concatenate((input_ids, [[eos_token_id] * pad_len]), axis=-1)
model_input_attention_mask = np.concatenate((attention_mask, [[0] * pad_len]), axis=-1)
else:
model_input_ids = input_ids
model_input_attention_mask = attention_mask
outputs = compiled_model({"input_ids": model_input_ids, "attention_mask": model_input_attention_mask})[output_key]
next_token_logits = outputs[:, cur_input_len - 1, :]
# pre-process distribution
next_token_scores = process_logits(cur_input_len,
next_token_logits, eos_token_id)
top_k = 20
next_token_scores = get_top_k_logits(next_token_scores, top_k)
# get next token id
probs = softmax(next_token_scores)
next_tokens = np.random.choice(probs.shape[-1], 1,
p=probs[0], replace=True)
# break the loop if max length or end of text token is reached
if cur_input_len == max_sequence_length or next_tokens[0] == eos_token_id:
break
else:
input_ids = np.concatenate((input_ids, [next_tokens]), axis=-1)
attention_mask = np.concatenate((attention_mask, [[1] * len(next_tokens)]), axis=-1)
return input_ids
GPT-Neo/GPT-2 による推論¶
以下の text 変数は、予測シーケンスを生成するために使用される入力です。
import time
if not model_name.value == "PersonaGPT (Converastional)":
text = "Deep learning is a type of machine learning that uses neural networks"
input_ids, attention_mask = tokenize(text)
start = time.perf_counter()
output_ids = generate_sequence(input_ids, attention_mask)
end = time.perf_counter()
output_text = " "
# Convert IDs to words and make the sentence from it
for i in output_ids[0]:
output_text += tokenizer.batch_decode([i])[0]
print(f"Generation took {end - start:.3f} s")
print(f"Input Text: {text}")
print()
print(f"{model_name.value}: {output_text}")
else:
print("Selected Model is PersonaGPT. Please select GPT-Neo or GPT-2 in the first cell to generate text sequences")
Selected Model is PersonaGPT. Please select GPT-Neo or GPT-2 in the first cell to generate text sequences
OpenVINO を使用した PersonaGPT との会話¶
ユーザー入力は、最後に eos_token が連結されてトークン化されます。モデル入力はトークン化されたテキストであり、生成の初期条件として機能します。次に、モデル推論結果からロジットを取得し、トップ k サンプリングを使用して最も高い確率を持つトークンを選択して、入力シーケンスに結合します。この手順は、シーケンストークンの終了が受信されるか、指定された最大長に達するまで繰り返されます。その後、トークン化されたトークン ID をテキストにデコードする必要があります。
生成された応答は、末尾に eos_token を付けて履歴に追加されます。さらにユーザー入力が追加され、再びモデルに渡されます。
会話をサポートするシーケンス生成関数のラッパー
def converse(input: str, history: List[int], eos_token: str = eos_token,
eos_token_id: int = eos_token_id) -> Tuple[str, List[int]]:
"""
Converse with the Model.
Parameters:
input: Text input given by the User
history: Chat History, ids of tokens of chat occured so far
eos_token: end of sequence string
eos_token_id: end of sequence index from vocab
Returns:
response: Text Response generated by the model
history: Chat History, Ids of the tokens of chat occured so far,including the tokens of generated response
"""
# Get Input Ids of the User Input
new_user_input_ids, _ = tokenize(input + eos_token)
# append the new user input tokens to the chat history, if history exists
if len(history) == 0:
bot_input_ids = new_user_input_ids
else:
bot_input_ids = np.concatenate([history, new_user_input_ids[0]])
bot_input_ids = np.expand_dims(bot_input_ids, axis=0)
# Create Attention Mask
bot_attention_mask = np.ones_like(bot_input_ids)
# Generate Response from the model
history = generate_sequence(bot_input_ids, bot_attention_mask, max_sequence_length=1000)
# Add the eos_token to mark end of sequence
history = np.append(history[0], eos_token_id)
# convert the tokens to text, and then split the responses into lines and retrieve the response from the Model
response = ''.join(tokenizer.batch_decode(history)).split(eos_token)[-2]
return response, history
class Conversation:
def __init__(self):
# Initialize Empty History
self.history = []
self.messages = []
def chat(self, input_text):
"""
Wrapper Over Converse Function.
Parameters:
input_text: Text input given by the User
Returns:
response: Text Response generated by the model
"""
response, self.history = converse(input_text, self.history)
self.messages.append(f"Person: {input_text}")
self.messages.append(f"PersonaGPT: {response}")
return response
このノートブックでは、プレーンとインタラクティブの 2 つの推論スタイルが提供されます。推論のスタイルは次のセルで選択できます。
style = {'description_width': 'initial'}
interactive_mode = widgets.Select(
options=['Plain', 'Interactive'],
value='Plain',
description='Inference Style:',
disabled=False
)
widgets.VBox([interactive_mode])
VBox(children=(Select(description='Inference Style:', options=('Plain', 'Interactive'), value='Plain'),))
import gradio as gr
if model_name.value == "PersonaGPT (Converastional)":
if interactive_mode.value == 'Plain':
conversation = Conversation()
user_prompt = None
pre_written_prompts = ["Hi,How are you?", "What are you doing?", "I like to dance,do you?", "Can you recommend me some books?"]
# Number of responses generated by model
n_prompts = 10
for i in range(n_prompts):
# Uncomment for taking User Input
# user_prompt = input()
if not user_prompt:
user_prompt = pre_written_prompts[i % len(pre_written_prompts)]
conversation.chat(user_prompt)
print(conversation.messages[-2])
print(conversation.messages[-1])
user_prompt = None
else:
def add_text(history, text):
history = history + [(text, None)]
return history, ""
conversation = Conversation()
def bot(history):
conversation.chat(history[-1][0])
response = conversation.messages[-1]
history[-1][1] = response
return history
with gr.Blocks() as demo:
chatbot = gr.Chatbot([], elem_id="chatbot")
with gr.Row():
with gr.Column():
txt = gr.Textbox(
show_label=False,
placeholder="Enter text and press enter, or upload an image",
container=False
)
txt.submit(add_text, [chatbot, txt], [chatbot, txt]).then(
bot, chatbot, chatbot
)
try:
demo.launch(debug=False)
except Exception:
demo.launch(debug=False, share=True)
# if you are launching remotely, specify server_name and server_port
# demo.launch(server_name='your server name', server_port='server port in int')
# Read more in the docs: https://gradio.app/docs/
else:
print("Selected Model is not PersonaGPT, Please select PersonaGPT in the first cell to have a conversation")
Person: Hi,How are you?
PersonaGPT: i am alright. do you have any siblings?
Person: What are you doing?
PersonaGPT: i am busy with school. do you like to read?
Person: I like to dance,do you?
PersonaGPT: i do not. are you a professional dancer?
Person: Can you recommend me some books?
PersonaGPT: i think the bible is a good starting point
Person: Hi,How are you?
PersonaGPT: i'm okay thanks for asking.
Person: What are you doing?
PersonaGPT: i'm just reading.
Person: I like to dance,do you?
PersonaGPT: i do not but i like reading.
Person: Can you recommend me some books?
PersonaGPT: i guess not. i don't have any siblings.
Person: Hi,How are you?
PersonaGPT: i'm good thanks for asking.
Person: What are you doing?
PersonaGPT: i am practicing my dance moves.