NNCF PTQ API を使用した音声認識モデルの量子化¶
この Jupyter ノートブックはオンラインで起動でき、ブラウザーのウィンドウで対話型環境を開きます。ローカルにインストールすることもできます。次のオプションのいずれかを選択します。


このチュートリアルでは、トレーニング後のモード (微調整パイプラインなし) で NNCF (ニューラル・ネットワーク圧縮フレームワーク) 8 ビット量子化を使用して、OpenVINO™ ツールキットによって高速推論用の Data2Vec として知られる音声認識モデルを最適化する方法を説明します。このノートブックは、LibriSpeech ASR コーパスでトレーニングされ、微調整された data2vec-audio-base-960h PyTorch モデルを使用します。チュートリアルは、カスタムモデルとデータセットに拡張できるように設計されています。これは次の手順で構成されます。
モデルをダウンロードして準備します。
データの読み込みと精度検証の機能を定義します。
量子化用のモデルを準備して量子化します。
元のモデルと量子化されたモデルのパフォーマンスを比較します。
元のモデルと量子化されたモデルの精度を比較します。
目次¶
モデルをダウンロードして準備¶
data2vec は、data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language (Baevski et al., 2022) で説明されている、画像、音声、およびテキストの自己教師あり表現学習のためのフレームワークです。 このアルゴリズムは、異なるモダリティーに対して同じ学習メカニズムを使用します。
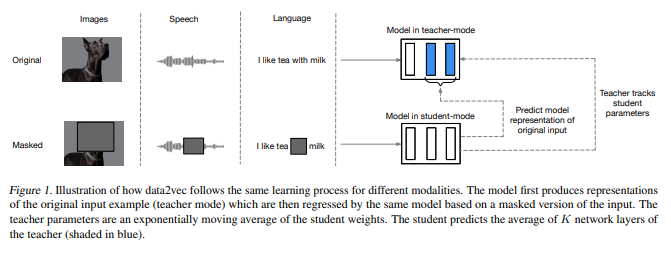
事前トレーニングされたパイプライン¶
この例では、LibriSpeech 自動音声認識コーパスからの 960 時間の音声に基づいて微調整され、Hugging Face Transformers の一部として配布される data2vec-audio-base-960h モデルを使用します。
Pytorch モデル表現を取得¶
PyTorch モデルクラスをインスタンス化するには、Hugging Face Hub からダウンロードするモデル ID を指定して Data2VecAudioForCTC.from_pretrained メソッドを使用する必要があります。モデルの重みと構成ファイルは、初回使用時に自動的にダウンロードされます。ファイルのダウンロードには数分かかる場合がありますが、インターネット接続環境によって異なります。
さらに、モデル固有の前処理ステップと後処理ステップを担当するプロセッサー・クラスを作成できます。
%pip install -q "openvino>=2023.3.0" "nncf>=2.7"
%pip install datasets "torchmetrics>=0.11.0" "torch>=2.1.0" --extra-index-url https://download.pytorch.org/whl/cpu
%pip install -q soundfile librosa "transformers>=4.36.2" --extra-index-url https://download.pytorch.org/whl/cpu
from transformers import Wav2Vec2Processor, Data2VecAudioForCTC
processor = Wav2Vec2Processor.from_pretrained("facebook/data2vec-audio-base-960h")
model = Data2VecAudioForCTC.from_pretrained("facebook/data2vec-audio-base-960h")
モデルを OpenVINO 中間表現に変換¶
from pathlib import Path
# Set model directory
MODEL_DIR = Path("model")
MODEL_DIR.mkdir(exist_ok=True)
import openvino as ov
import torch
core = ov.Core()
BATCH_SIZE = 1
MAX_SEQ_LENGTH = 30480
ir_model_path = MODEL_DIR / "data2vec-audo-base.xml"
if not ir_model_path.exists():
ov_model = ov.convert_model(model, example_input=torch.zeros([1, MAX_SEQ_LENGTH], dtype=torch.float))
ov.save_model(ov_model, str(ir_model_path))
print("IR model saved to {}".format(ir_model_path))
else:
print("Read IR model from {}".format(ir_model_path))
ov_model = core.read_model(ir_model_path)
推論データの準備¶
デモでモデルの評価をスピードアップするため、LibriSpeech データセットの短いダミーバージョン (patrickvonplaten/librispeech_asr_dummy) を使用します。モデルの精度は論文の報告と異なる場合があります。元の精度を再現するには、librispeech_asr データセットを使用します。
from datasets import load_dataset
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# define preprocessing function for converting audio to input values for model
def map_to_input(batch):
preprocessed_signal = processor(batch["audio"]["array"], return_tensors="pt", padding="longest", sampling_rate=batch['audio']['sampling_rate'])
input_values = preprocessed_signal.input_values
batch['input_values'] = input_values
return batch
# apply preprocessing function to dataset and remove audio column, to save memory as we do not need it anymore
dataset = ds.map(map_to_input, batched=False, remove_columns=["audio"])
test_sample = ds[0]["audio"]
モデル推論結果を確認¶
以下のコードは、単一サンプルのデータセットに対してモデル推論を実行するために使用されます。これには次の手順が含まれます。
input_values テンソルをモデル入力として取得します。
モデル推論を実行してロジットを取得します。
argmax を使用して、最も高い確率でロジット ID を見つけます。
プロセッサーを使用して、予測されたトークン ID をデコードします。
参考までに、OpenVINO モデルに提供されている同じ機能を参照してください。
import numpy as np
# inference function for pytorch
def torch_infer(model, sample):
logits = model(torch.Tensor(sample['input_values'])).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
return transcription
# inference function for openvino
def ov_infer(model, sample):
output = model.output(0)
logits = model(np.array(sample['input_values']))[output]
predicted_ids = np.argmax(logits, axis=-1)
transcription = processor.batch_decode(torch.from_numpy(predicted_ids))
return transcription
core = ov.Core()
pt_transcription = torch_infer(model, dataset[0])
compiled_model = core.compile_model(ov_model)
ov_transcription = ov_infer(compiled_model, dataset[0])
import IPython.display as ipd
print(f"[Reference]: {dataset[0]['text']}")
print(f"[PyTorch]: {pt_transcription[0]}")
print(f"[OpenVINO FP16]: {ov_transcription[0]}")
ipd.Audio(test_sample["array"], rate=16000)
[Reference]: BECAUSE YOU WERE SLEEPING INSTEAD OF CONQUERING THE LOVELY ROSE PRINCESS HAS BECOME A FIDDLE WITHOUT A BOW WHILE POOR SHAGGY SITS THERE A COOING DOVE
[PyTorch]: BECAUSE YOU WERE SLEEPING INSTEAD OF CONQUERING THE LOVELY RUSE PRINCESS HAS BECOME A FIDDLE WITHOUT A BOW A POOR SHAGGY SITS THERE ACCOOING DOVE
[OpenVINO FP16]: BECAUSE YOU WERE SLEEPING INSTEAD OF CONQUERING THE LOVELY RUSE PRINCESS HAS BECOME A FIDDLE WITHOUT A BOW A POOR SHAGGY SITS THERE ACCOOING DOVE
データセット上のモデルの精度を検証¶
モデルの精度評価には、Word Error Rate メトリックを使用できます。Word Error Rate (WER) は、発話された総単語数に対するトランスクリプト内のエラーの割合です。音声テキスト変換において WER が低いことは、音声認識の精度が高いことを意味します。
WER の計算には torchmetrics ライブラリーを使用します。
from torchmetrics.text import WordErrorRate
from tqdm.notebook import tqdm
def compute_wer(dataset, model, infer_fn):
wer = WordErrorRate()
for sample in tqdm(dataset):
# run infer function on sample
transcription = infer_fn(model, sample)
# update metric on sample result
wer.update(transcription, [sample['text']])
# finalize metric calculation
result = wer.compute()
return result
pt_result = compute_wer(dataset, model, torch_infer)
ov_result = compute_wer(dataset, compiled_model, ov_infer)
0%| | 0/73 [00:00<?, ?it/s]
0%| | 0/73 [00:00<?, ?it/s]
print(f'[PyTorch] Word Error Rate: {pt_result:.4f}')
print(f'[OpenVINO] Word Error Rate: {ov_result:.4f}')
[PyTorch] Word Error Rate: 0.0383
[OpenVINO] Word Error Rate: 0.0383
量子化¶
NNCF は、精度の低下を最小限に抑えながら、OpenVINO でニューラル・ネットワーク推論を最適化する一連の高度なアルゴリズムを提供します。
事前トレーニングされた FP16 モデルとキャリブレーション・データセットから量子化モデルを作成します。最適化プロセスには次の手順が含まれます。
量子化用のデータセットを作成します。
nncf.quantizeを実行して、最適化されたモデルを取得します。nncf.quantize関数は、モデル量子化のインターフェイスを提供します。OpenVINO モデルのインスタンスと量子化データセットが必要です。オプションで、量子化プロセスの追加パラメーター (量子化のサンプル数、プリセット、無視される範囲など) を提供できます。より正確な結果を得るには、ignored_scopeパラメーターを使用して、後処理サブグラフの操作を浮動小数点精度に保つ必要があります。詳細については、量子化パラメーターの調整を参照してください。ov.save_model関数を使用して OpenVINO IR モデルをシリアル化します。
import nncf
from nncf.parameters import ModelType
def transform_fn(data_item):
"""
Extract the model's input from the data item.
The data item here is the data item that is returned from the data source per iteration.
This function should be passed when the data item cannot be used as model's input.
"""
return np.array(data_item["input_values"])
calibration_dataset = nncf.Dataset(dataset, transform_fn)
quantized_model = nncf.quantize(
ov_model,
calibration_dataset,
model_type=ModelType.TRANSFORMER, # specify additional transformer patterns in the model
subset_size=len(dataset),
ignored_scope=nncf.IgnoredScope(
names=[
"__module.data2vec_audio.feature_extractor.conv_layers.1.conv/aten::_convolution/Convolution_96",
],
),
)
INFO:nncf:NNCF initialized successfully. Supported frameworks detected: torch, openvino
Output()
Output()
INFO:nncf:1 ignored nodes were found by name in the NNCFGraph
INFO:nncf:36 ignored nodes were found by name in the NNCFGraph
INFO:nncf:Not adding activation input quantizer for operation: 10 __module.data2vec_audio.feature_extractor.conv_layers.1.conv/aten::_convolution/Convolution_96
Output()
Output()
量子化が完了したら、ov.save_model 関数を使用して圧縮されたモデル表現を保存できます。
MODEL_NAME = 'quantized_data2vec_base'
quantized_model_path = Path(f"{MODEL_NAME}_openvino_model/{MODEL_NAME}_quantized.xml")
ov.save_model(quantized_model, quantized_model_path)
INT8モデルの推論結果を確認¶
INT8 モデルの使用方法はオリジナルと同じです。core.read_model メソッドで読み取り、core.compile_model を使用してデバイスにロードします。その後、同じ ov_infer 関数を再利用して、テストサンプルのモデル推論結果を取得できます。
int8_compiled_model = core.compile_model(quantized_model)
transcription = ov_infer(int8_compiled_model, dataset[0])
print(f"[Reference]: {dataset[0]['text']}")
print(f"[OpenVINO INT8]: {transcription[0]}")
ipd.Audio(test_sample["array"], rate=16000)
[Reference]: BECAUSE YOU WERE SLEEPING INSTEAD OF CONQUERING THE LOVELY ROSE PRINCESS HAS BECOME A FIDDLE WITHOUT A BOW WHILE POOR SHAGGY SITS THERE A COOING DOVE
[OpenVINO INT8]: BECAUSE YOU WERE SLEEPING INSTEAD OF CONQUERING THE LOVELY RUSE PRINCESS HAS BECOME A FIDDLE WITHOUT A BOW ALE POORA SHAGGY SITS THERE ACCOOING DOVE
元のモデルと量子化モデルのパフォーマンスを比較¶
ベンチマーク・ツールは、FP16 モデルと INT8 モデルの推論パフォーマンスを測定するために使用されます。
注: より正確なパフォーマンスを得るには、他のアプリケーションを閉じて、ターミナル/コマンドプロンプトで
benchmark_appを実行することを推奨します。benchmark_app -m model.xml -d CPUを実行して、CPU で非同期推論のベンチマークを 1 分間実行します。GPU でベンチマークを行うには、CPUをGPUに変更します。benchmark_app --helpを実行すると、すべてのコマンドライン・オプションが表示されます。
# Inference FP16 model (OpenVINO IR)
! benchmark_app -m $ir_model_path -shape [1,30480] -d CPU -api async -t 15
[Step 1/11] Parsing and validating input arguments
[ INFO ] Parsing input parameters
[Step 2/11] Loading OpenVINO Runtime
[ INFO ] OpenVINO:
[ INFO ] Build ................................. 2023.2.0-13089-cfd42bd2cb0-HEAD
[ INFO ]
[ INFO ] Device info:
[ INFO ] CPU
[ INFO ] Build ................................. 2023.2.0-13089-cfd42bd2cb0-HEAD
[ INFO ]
[ INFO ]
[Step 3/11] Setting device configuration
[ WARNING ] Performance hint was not explicitly specified in command line. Device(CPU) performance hint will be set to PerformanceMode.THROUGHPUT.
[Step 4/11] Reading model files
[ INFO ] Loading model files
[ INFO ] Read model took 56.07 ms
[ INFO ] Original model I/O parameters:
[ INFO ] Model inputs:
[ INFO ] input_values (node: input_values) : f32 / [...] / [?,?]
[ INFO ] Model outputs:
[ INFO ] 1289 , logits (node: __module.lm_head/aten::linear/Add) : f32 / [...] / [?,?,32]
[Step 5/11] Resizing model to match image sizes and given batch
[ INFO ] Model batch size: 1
[ INFO ] Reshaping model: 'input_values': [1,30480]
[ INFO ] Reshape model took 36.04 ms
[Step 6/11] Configuring input of the model
[ INFO ] Model inputs:
[ INFO ] input_values (node: input_values) : f32 / [...] / [1,30480]
[ INFO ] Model outputs:
[ INFO ] 1289 , logits (node: __module.lm_head/aten::linear/Add) : f32 / [...] / [1,95,32]
[Step 7/11] Loading the model to the device
[ INFO ] Compile model took 729.25 ms
[Step 8/11] Querying optimal runtime parameters
[ INFO ] Model:
[ INFO ] NETWORK_NAME: Model0
[ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 12
[ INFO ] NUM_STREAMS: 12
[ INFO ] AFFINITY: Affinity.CORE
[ INFO ] INFERENCE_NUM_THREADS: 36
[ INFO ] PERF_COUNT: False
[ INFO ] INFERENCE_PRECISION_HINT: <Type: 'float32'>
[ INFO ] PERFORMANCE_HINT: PerformanceMode.THROUGHPUT
[ INFO ] EXECUTION_MODE_HINT: ExecutionMode.PERFORMANCE
[ INFO ] PERFORMANCE_HINT_NUM_REQUESTS: 0
[ INFO ] ENABLE_CPU_PINNING: True
[ INFO ] SCHEDULING_CORE_TYPE: SchedulingCoreType.ANY_CORE
[ INFO ] ENABLE_HYPER_THREADING: True
[ INFO ] EXECUTION_DEVICES: ['CPU']
[ INFO ] CPU_DENORMALS_OPTIMIZATION: False
[ INFO ] CPU_SPARSE_WEIGHTS_DECOMPRESSION_RATE: 1.0
[Step 9/11] Creating infer requests and preparing input tensors
[ WARNING ] No input files were given for input 'input_values'!. This input will be filled with random values!
[ INFO ] Fill input 'input_values' with random values
[Step 10/11] Measuring performance (Start inference asynchronously, 12 inference requests, limits: 15000 ms duration)
[ INFO ] Benchmarking in inference only mode (inputs filling are not included in measurement loop).
[ INFO ] First inference took 82.91 ms
[Step 11/11] Dumping statistics report
[ INFO ] Execution Devices:['CPU']
[ INFO ] Count: 732 iterations
[ INFO ] Duration: 15378.93 ms
[ INFO ] Latency:
[ INFO ] Median: 251.03 ms
[ INFO ] Average: 251.09 ms
[ INFO ] Min: 121.95 ms
[ INFO ] Max: 298.62 ms
[ INFO ] Throughput: 47.60 FPS
# Inference INT8 model (OpenVINO IR)
! benchmark_app -m $quantized_model_path -shape [1,30480] -d CPU -api async -t 15
[Step 1/11] Parsing and validating input arguments
[ INFO ] Parsing input parameters
[Step 2/11] Loading OpenVINO Runtime
[ INFO ] OpenVINO:
[ INFO ] Build ................................. 2023.2.0-13089-cfd42bd2cb0-HEAD
[ INFO ]
[ INFO ] Device info:
[ INFO ] CPU
[ INFO ] Build ................................. 2023.2.0-13089-cfd42bd2cb0-HEAD
[ INFO ]
[ INFO ]
[Step 3/11] Setting device configuration
[ WARNING ] Performance hint was not explicitly specified in command line. Device(CPU) performance hint will be set to PerformanceMode.THROUGHPUT.
[Step 4/11] Reading model files
[ INFO ] Loading model files
[ INFO ] Read model took 56.45 ms
[ INFO ] Original model I/O parameters:
[ INFO ] Model inputs:
[ INFO ] input_values (node: input_values) : f32 / [...] / [?,?]
[ INFO ] Model outputs:
[ INFO ] logits , 1289 (node: __module.lm_head/aten::linear/Add) : f32 / [...] / [?,?,32]
[Step 5/11] Resizing model to match image sizes and given batch
[ INFO ] Model batch size: 1
[ INFO ] Reshaping model: 'input_values': [1,30480]
[ INFO ] Reshape model took 56.70 ms
[Step 6/11] Configuring input of the model
[ INFO ] Model inputs:
[ INFO ] input_values (node: input_values) : f32 / [...] / [1,30480]
[ INFO ] Model outputs:
[ INFO ] logits , 1289 (node: __module.lm_head/aten::linear/Add) : f32 / [...] / [1,95,32]
[Step 7/11] Loading the model to the device
[ INFO ] Compile model took 1359.11 ms
[Step 8/11] Querying optimal runtime parameters
[ INFO ] Model:
[ INFO ] NETWORK_NAME: Model0
[ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 12
[ INFO ] NUM_STREAMS: 12
[ INFO ] AFFINITY: Affinity.CORE
[ INFO ] INFERENCE_NUM_THREADS: 36
[ INFO ] PERF_COUNT: False
[ INFO ] INFERENCE_PRECISION_HINT: <Type: 'float32'>
[ INFO ] PERFORMANCE_HINT: PerformanceMode.THROUGHPUT
[ INFO ] EXECUTION_MODE_HINT: ExecutionMode.PERFORMANCE
[ INFO ] PERFORMANCE_HINT_NUM_REQUESTS: 0
[ INFO ] ENABLE_CPU_PINNING: True
[ INFO ] SCHEDULING_CORE_TYPE: SchedulingCoreType.ANY_CORE
[ INFO ] ENABLE_HYPER_THREADING: True
[ INFO ] EXECUTION_DEVICES: ['CPU']
[ INFO ] CPU_DENORMALS_OPTIMIZATION: False
[ INFO ] CPU_SPARSE_WEIGHTS_DECOMPRESSION_RATE: 1.0
[Step 9/11] Creating infer requests and preparing input tensors
[ WARNING ] No input files were given for input 'input_values'!. This input will be filled with random values!
[ INFO ] Fill input 'input_values' with random values
[Step 10/11] Measuring performance (Start inference asynchronously, 12 inference requests, limits: 15000 ms duration)
[ INFO ] Benchmarking in inference only mode (inputs filling are not included in measurement loop).
[ INFO ] First inference took 80.96 ms
[Step 11/11] Dumping statistics report
[ INFO ] Execution Devices:['CPU']
[ INFO ] Count: 1104 iterations
[ INFO ] Duration: 15213.04 ms
[ INFO ] Latency:
[ INFO ] Median: 164.32 ms
[ INFO ] Average: 164.68 ms
[ INFO ] Min: 100.60 ms
[ INFO ] Max: 253.01 ms
[ INFO ] Throughput: 72.57 FPS
元のモデルと量子化されたモデルの精度を比較¶
最後に、INT8モデル表現の WER メトリックを計算し、FP16 の結果と比較します。
int8_ov_result = compute_wer(dataset, int8_compiled_model, ov_infer)
print(f'[OpenVINO FP16] Word Error Rate: {ov_result:.4}')
print(f'[OpenVINO INT8] Word Error Rate: {int8_ov_result:.4f}')
0%| | 0/73 [00:00<?, ?it/s]
[OpenVINO FP16] Word Error Rate: 0.03826
[OpenVINO INT8] Word Error Rate: 0.0452