Datumaro#
Datumaro は、35 を超えるパブリックなビジョンデータ形式と、検証、修正、フィルター処理、一部の変換などの操作機能向けの基本的なデータインポート/エクスポート (IE) スイートを提供します。ウェブスケールでのトレーニングを実現するために、これはさらに、コンパレーターとマージを通じて複数のヘテロジニアス・データセットをマージすることを目的としています。Datumaro は、Geti*、OpenVINO™ トレーニング拡張、および CVAT に統合されており、データの準備が容易です。Datumaro はオープンソースであり、GitHub で入手できます。詳細については、公式のドキュメントをお読みください。さらに、Jupyter* Notebook で実際の Datumaro の実践をお楽しみください。
詳細なワークフロー#
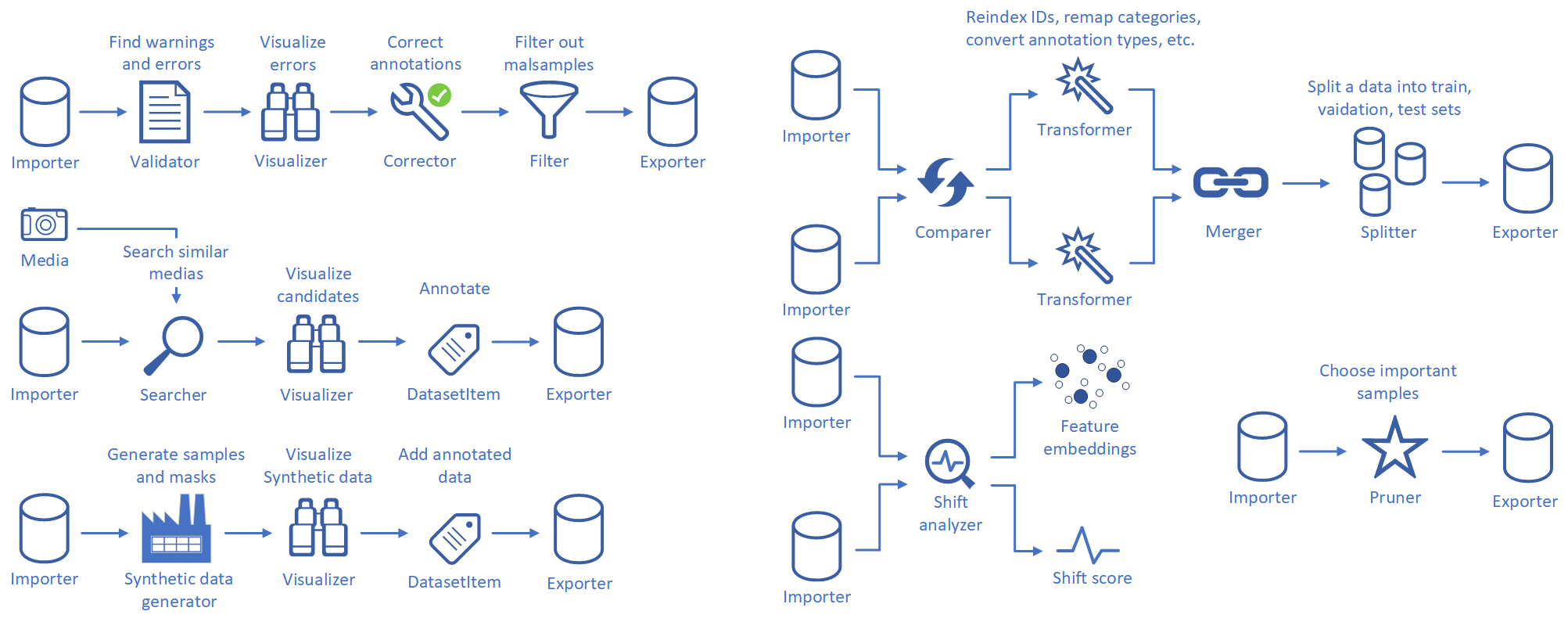
Datumaro の利用を開始するには、公開データセットをダウンロードするか、独自のアノテーション付きデータセットを準備します。
注
Datumaro は、TensorFlow データセットをダウンロードする CLI データ・ダウンロードを提供します。
データを Datumaro にインポートし、Validator、Corrector、および Filter を使用してデータ品質を調整するためにデータセットを操作します。
2 つのデータセットを比較し、マージする前にラベルスキーマ (カテゴリー情報) を変換します。
2 つのデータセットを大規模なデータセットに結合します。
注
マージ機能には、ExactMerger、IntersectMerger、UnionMerger などの選択肢があります。
統合されたデータセットをサブセットに分割します (例: スプリッターを介してトレーニング、評価、テスト)。
注
サンプル数またはアノテーションの両方に従って、指定された割合でサブセットにデータを分割できます。タスク固有の分割については、SplitTask を参照してください。
6.モデルのトレーニングなどワークフローのフォローアップのため、クリーン化および統合されたデータセットをエクスポートします。OpenVINO™ トレーニング拡張をご覧ください。
結果に満足できない場合、データセットを追加し、データセットのアノテーションから始めて同じ手順を繰り返します。