OpenVINO による文法エラー修正¶
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

AI ベースの自動修正製品は、使いやすさ、編集速度、手頃な価格のため、ますます人気が高まっています。これらの製品は、電子メール、ブログ、チャットのテキストの品質を向上させます。
文法エラー修正 (GEC) は、スペル、句読点、文法、単語選択のエラーなど、テキスト内のさまざまな種類のエラーを修正するタスクです。GEC は通常、文の修正タスクとして策定されます。GEC システムは、誤りの可能性がある文を入力として受け取り、それをより正しいバージョンに変換することが期待されます。以下の例を参照してください。
入力 (エラーあり) |
出力 (修正済み) |
|---|---|
I like to rides my bicycle. |
I like to ride my bicycle. |
下の画像に示すように、書き言葉におけるさまざまな種類のエラーを修正できます。
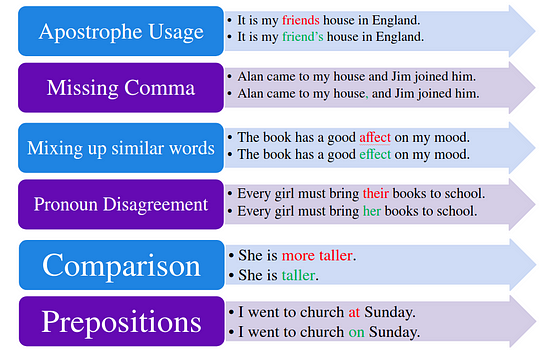
error_types¶
このチュートリアルでは、OpenVINO を使用して文法エラー修正を実行する方法を説明します。Hugging Face Transformers ライブラリーの事前トレーニング済みモデルを使用します。ユーザー・エクスペリエンスを簡素化するために、Hugging Face Optimum ライブラリーを使用してモデルを OpenVINO™ IR 形式に変換します。
これは次の手順で構成されます。
前提条件をインストールします。
OpenVINO と Hugging Face Optimum の統合を使用して、パブリックソースからモデルをダウンロードして変換します。
文法エラーチェックのための推論パイプラインを作成します。
NNCF 量子化による文法修正パイプラインを最適化します。
パフォーマンスと精度の観点から、元のパイプラインと最適化されたパイプラインを比較します。
目次¶
どのような仕組みか ?¶
文法エラー修正タスクは、文法的に誤った文を入力として受け取り、正しい文を出力として返すようにモデルをトレーニングするシーケンスツーシーケンス・タスクと考えることができます。JFLEG データセットの拡張バージョンで微調整された FLAN-T5 モデルを使用します。
スケーリング命令 - 微調整された言語モデル論文とともにリリースされた FLAN-T5 のバージョンは、タスクの組み合わせに基づいて微調整された T5 の拡張バージョンです。この論文では、タスク数のスケーリング、モデルサイズのスケーリング、思考連鎖データの微調整に特に焦点を当てて、命令の微調整について説明します。この論文では、全体の命令の微調整が、事前トレーニング済み言語モデルのパフォーマンスと使いやすさを向上させる一般的な方法であることが分かりました。
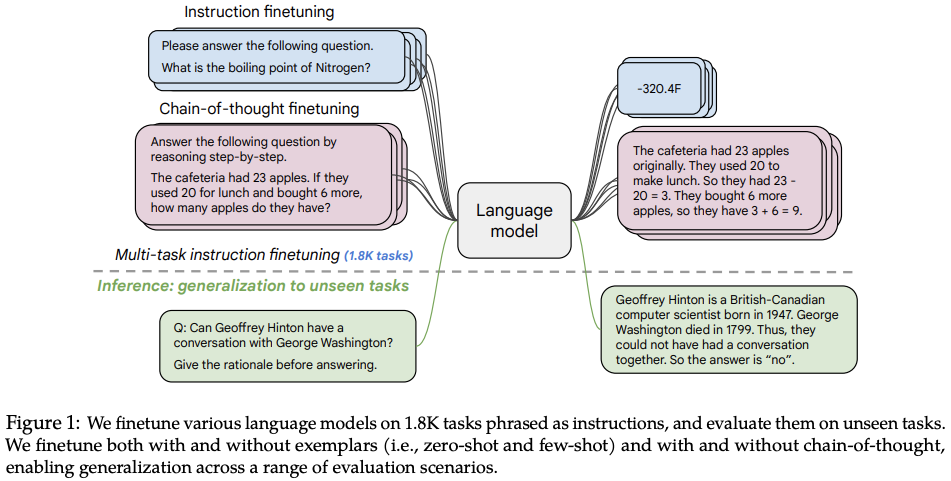
flan-t5_training¶
モデルの詳細については、論文、オリジナルのリポジトリー、Hugging Face モデルカードをご覧ください。
さらに、処理する文の数を減らすため、文法の正確さチェックを実行することもできます。このタスクは、モデルが入力テキストを取得し、テキストに文法エラーが含まれている場合はラベル 1 を予測し、含まれていない場合はラベル 0 を予測する、単純なバイナリーテキスト分類として考える必要があります。CoLA データセットで微調整された RoBERTa ベースモデルである roberta-base-CoLA モデルを使用します。RoBERTa モデルは、「RoBERTa: A Robustly Optimized BERT Pretraining Approach」論文で提案されました。これは BERT を基盤として主要なハイパーパラメーターを変更し、次の文の事前トレーニング目標を削除して、はるかに大きなミニバッチと学習率でトレーニングします。モデルに関する詳細は、Meta AI のブログ投稿と Hugging Face のドキュメントで確認できます。
FLAN-T5 と RoBERTa について詳しく理解できたので、始めましょう。🚀
必要条件¶
最初に、OpenVINO 統合によって高速化された Hugging Face Optimum ライブラリーをインストールする必要があります。Hugging Face Optimum API は、Hugging Face Transformers ライブラリーのモデルを OpenVINO™ IR 形式に変換および量子化できる高レベル API です。詳細については、Hugging Face Optimum のドキュメントを参照してください。
%pip install -q "git+https://github.com/huggingface/optimum-intel.git" "openvino>=2023.1.0" onnx gradio "transformers>=4.33.0" --extra-index-url https://download.pytorch.org/whl/cpu
%pip install -q "nncf>=2.7.0" datasets jiwer
Note: you may need to restart the kernel to use updated packages.
Note: you may need to restart the kernel to use updated packages.
モデルのダウンロードと変換¶
Optimum Intel を使用すると、Hugging Face Hubから最適化されたモデルをロードし、Hugging Face API を使用して OpenVINO ランタイムで推論を実行するパイプラインを作成できます。Optimum 推論モデルは、Hugging Face Transformers モデルと API の互換性があります。つまり、AutoModelForXxx クラスを対応する OVModelForXxx クラスに置き換えるだけで済みます。
以下は RoBERTa テキスト分類モデルの例です。
-from transformers import AutoModelForSequenceClassification
+from optimum.intel.openvino import OVModelForSequenceClassification
from transformers import AutoTokenizer, pipeline
model_id = "textattack/roberta-base-CoLA"
-model = AutoModelForSequenceClassification.from_pretrained(model_id)
+model = OVModelForSequenceClassification.from_pretrained(model_id, from_transformers=True)
モデルクラスの初期化は、from_pretrained メソッドの呼び出しから始まります。Transformers モデルをダウンロードして変換する場合は、パラメーター from_transformers=True を追加する必要があります。save_pretrained メソッドを使用して、変換されたモデルを次回に使用するため保存できます。トークナイザー・クラスとパイプライン API は Optimum モデルと互換性があります。
from pathlib import Path
from transformers import pipeline, AutoTokenizer
from optimum.intel.openvino import OVModelForSeq2SeqLM, OVModelForSequenceClassification
2023-09-27 14:53:36.462575: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0. 2023-09-27 14:53:36.496914: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags. 2023-09-27 14:53:37.063292: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
INFO:nncf:NNCF initialized successfully. Supported frameworks detected: torch, tensorflow, onnx, openvino
No CUDA runtime is found, using CUDA_HOME='/usr/local/cuda-11.7'
/home/nsavel/venvs/ov_notebooks_tmp/lib/python3.8/site-packages/transformers/deepspeed.py:23: FutureWarning: transformers.deepspeed module is deprecated and will be removed in a future version. Please import deepspeed modules directly from transformers.integrations
warnings.warn(
推論デバイスの選択¶
OpenVINO を使用して推論を実行するためにドロップダウン・リストからデバイスを選択します。
import ipywidgets as widgets
import openvino as ov
core = ov.Core()
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='AUTO',
description='Device:',
disabled=False,
)
device
Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')
文法チェッカー¶
grammar_checker_model_id = "textattack/roberta-base-CoLA"
grammar_checker_dir = Path("roberta-base-cola")
grammar_checker_tokenizer = AutoTokenizer.from_pretrained(grammar_checker_model_id)
if grammar_checker_dir.exists():
grammar_checker_model = OVModelForSequenceClassification.from_pretrained(grammar_checker_dir, device=device.value)
else:
grammar_checker_model = OVModelForSequenceClassification.from_pretrained(grammar_checker_model_id, export=True, device=device.value, load_in_8bit=False)
grammar_checker_model.save_pretrained(grammar_checker_dir)
Framework not specified. Using pt to export to ONNX.
Some weights of the model checkpoint at textattack/roberta-base-CoLA were not used when initializing RobertaForSequenceClassification: ['roberta.pooler.dense.weight', 'roberta.pooler.dense.bias']
- This IS expected if you are initializing RobertaForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing RobertaForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Using framework PyTorch: 1.13.1+cpu
Overriding 1 configuration item(s)
- use_cache -> False
WARNING:tensorflow:Please fix your imports. Module tensorflow.python.training.tracking.base has been moved to tensorflow.python.trackable.base. The old module will be deleted in version 2.11.
[ WARNING ] Please fix your imports. Module %s has been moved to %s. The old module will be deleted in version %s.
Compiling the model to CPU ...
Set CACHE_DIR to /tmp/tmpcqv99eqb/model_cache
text-classification タスクの推論パイプラインを使用して、モデルの動作を確認しましょう。Hugging Face 推論パイプラインの使用法の詳細については、チュートリアルをご覧ください
input_text = "They are moved by salar energy"
grammar_checker_pipe = pipeline("text-classification", model=grammar_checker_model, tokenizer=grammar_checker_tokenizer)
result = grammar_checker_pipe(input_text)[0]
print(f"input text: {input_text}")
print(f'predicted label: {"contains_errors" if result["label"] == "LABEL_1" else "no errors"}')
print(f'predicted score: {result["score"] :.2}')
input text: They are moved by salar energy
predicted label: contains_errors
predicted score: 0.88
これで完了です! モデルはサンプル内のエラーを検出できるようです。
文法コレクター¶
文法コレクターモデルをロードする手順は、使用されるモデルクラスを除いて、非常に似ています。FLAN-T5 はシーケンス間テキスト生成モデルであるため、これを実行するには OVModelForSeq2SeqLM クラスと text2text-generation 生成パイプラインを使用する必要があります。
grammar_corrector_model_id = "pszemraj/flan-t5-large-grammar-synthesis"
grammar_corrector_dir = Path("flan-t5-large-grammar-synthesis")
grammar_corrector_tokenizer = AutoTokenizer.from_pretrained(grammar_corrector_model_id)
if grammar_corrector_dir.exists():
grammar_corrector_model = OVModelForSeq2SeqLM.from_pretrained(grammar_corrector_dir, device=device.value)
else:
grammar_corrector_model = OVModelForSeq2SeqLM.from_pretrained(grammar_corrector_model_id, export=True, device=device.value)
grammar_corrector_model.save_pretrained(grammar_corrector_dir)
Framework not specified. Using pt to export to ONNX.
Using framework PyTorch: 1.13.1+cpu
Overriding 1 configuration item(s)
- use_cache -> False
Using framework PyTorch: 1.13.1+cpu
Overriding 1 configuration item(s)
- use_cache -> True
/home/nsavel/venvs/ov_notebooks_tmp/lib/python3.8/site-packages/transformers/modeling_utils.py:875: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if causal_mask.shape[1] < attention_mask.shape[1]:
Using framework PyTorch: 1.13.1+cpu
Overriding 1 configuration item(s)
- use_cache -> True
/home/nsavel/venvs/ov_notebooks_tmp/lib/python3.8/site-packages/transformers/models/t5/modeling_t5.py:509: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
elif past_key_value.shape[2] != key_value_states.shape[1]:
Compiling the encoder to AUTO ...
Compiling the decoder to AUTO ...
Compiling the decoder to AUTO ...
grammar_corrector_pipe = pipeline("text2text-generation", model=grammar_corrector_model, tokenizer=grammar_corrector_tokenizer)
result = grammar_corrector_pipe(input_text)[0]
print(f"input text: {input_text}")
print(f'generated text: {result["generated_text"]}')
/home/nsavel/venvs/ov_notebooks_tmp/lib/python3.8/site-packages/optimum/intel/openvino/modeling_seq2seq.py:339: FutureWarning: shared_memory is deprecated and will be removed in 2024.0. Value of shared_memory is going to override share_inputs value. Please use only share_inputs explicitly. last_hidden_state = torch.from_numpy(self.request(inputs, shared_memory=True)["last_hidden_state"]).to( /home/nsavel/venvs/ov_notebooks_tmp/lib/python3.8/site-packages/optimum/intel/openvino/modeling_seq2seq.py:416: FutureWarning: shared_memory is deprecated and will be removed in 2024.0. Value of shared_memory is going to override share_inputs value. Please use only share_inputs explicitly. self.request.start_async(inputs, shared_memory=True)
input text: They are moved by salar energy
generated text: They are powered by solar energy.
結果はかなり良さそうです!
デモ・パイプラインの準備¶
それでは、すべてをまとめて文法修正のパイプラインを作成しましょう。パイプラインは入力テキストを受け入れ、その正確性を検証し、必要に応じて正しいバージョンを生成します。それはいくつかのステップから構成されます。
文章ごとにテキストを分割します。
文法チェッカーを使用して各文の文法の正確さを確認します。
必要に応じて、文の改善版を生成します。
import re
import transformers
from tqdm.notebook import tqdm
def split_text(text: str) -> list:
"""
Split a string of text into a list of sentence batches.
Parameters:
text (str): The text to be split into sentence batches.
Returns:
list: A list of sentence batches. Each sentence batch is a list of sentences.
"""
# Split the text into sentences using regex
sentences = re.split(r"(?<=[^A-Z].[.?]) +(?=[A-Z])", text)
# Initialize a list to store the sentence batches
sentence_batches = []
# Initialize a temporary list to store the current batch of sentences
temp_batch = []
# Iterate through the sentences
for sentence in sentences:
# Add the sentence to the temporary batch
temp_batch.append(sentence)
# If the length of the temporary batch is between 2 and 3 sentences, or if it is the last batch, add it to the list of sentence batches
if len(temp_batch) >= 2 and len(temp_batch) <= 3 or sentence == sentences[-1]:
sentence_batches.append(temp_batch)
temp_batch = []
return sentence_batches
def correct_text(text: str, checker: transformers.pipelines.Pipeline, corrector: transformers.pipelines.Pipeline, separator: str = " ") -> str:
"""
Correct the grammar in a string of text using a text-classification and text-generation pipeline.
Parameters:
text (str): The inpur text to be corrected.
checker (transformers.pipelines.Pipeline): The text-classification pipeline to use for checking the grammar quality of the text.
corrector (transformers.pipelines.Pipeline): The text-generation pipeline to use for correcting the text.
separator (str, optional): The separator to use when joining the corrected text into a single string. Default is a space character.
Returns:
str: The corrected text.
"""
# Split the text into sentence batches
sentence_batches = split_text(text)
# Initialize a list to store the corrected text
corrected_text = []
# Iterate through the sentence batches
for batch in tqdm(
sentence_batches, total=len(sentence_batches), desc="correcting text.."
):
# Join the sentences in the batch into a single string
raw_text = " ".join(batch)
# Check the grammar quality of the text using the text-classification pipeline
results = checker(raw_text)
# Only correct the text if the results of the text-classification are not LABEL_1 or are LABEL_1 with a score below 0.9
if results[0]["label"] != "LABEL_1" or (
results[0]["label"] == "LABEL_1" and results[0]["score"] < 0.9
):
# Correct the text using the text-generation pipeline
corrected_batch = corrector(raw_text)
corrected_text.append(corrected_batch[0]["generated_text"])
else:
corrected_text.append(raw_text)
# Join the corrected text into a single string
corrected_text = separator.join(corrected_text)
return corrected_text
実際に動作を見てみましょう。
default_text = (
"Most of the course is about semantic or content of language but there are also interesting"
" topics to be learned from the servicefeatures except statistics in characters in documents.At"
" this point, He introduces herself as his native English speaker and goes on to say that if"
" you contine to work on social scnce"
)
corrected_text = correct_text(default_text, grammar_checker_pipe, grammar_corrector_pipe)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using tokenizers before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
correcting text..: 0%| | 0/1 [00:00<?, ?it/s]
print(f"input text: {default_text}\n")
print(f'generated text: {corrected_text}')
input text: Most of the course is about semantic or content of language but there are also interesting topics to be learned from the servicefeatures except statistics in characters in documents.At this point, He introduces herself as his native English speaker and goes on to say that if you contine to work on social scnce
generated text: Most of the course is about the semantic content of language but there are also interesting topics to be learned from the service features except statistics in characters in documents. At this point, she introduces herself as a native English speaker and goes on to say that if you continue to work on social science, you will continue to be successful.
量子化¶
NNCF は、量子化レイヤーをモデルグラフに追加し、トレーニング・データセットのサブセットを使用してこれらの追加の量子化レイヤーのパラメーターを初期化することで、トレーニング後の量子化を可能にします。量子化操作は FP32/FP16 ではなく INT8 で実行されるため、モデル推論が高速化されます。
文法チェッカーモデルはテキスト修正パイプライン全体のごく一部を占めるため、文法コレクターモデルのみを最適化します。文法コレクター自体は、エンコーダー、ファースト・コール・デコーダー、履歴付きデコーダーの 3 つのモデルで構成されています。最後のモデルの推論のシェアが他のモデルを圧倒します。このため、それだけを量子化します。
最適化プロセスには次の手順が含まれます。
量子化用のキャリブレーション・データセットを作成します。
nncf.quantize()を実行して、量子化されたモデルを取得します。openvino.save_model()関数を使用してINT8モデルをシリアル化します。
モデルの推論速度を向上させるため量子化を実行するかどうかを以下で選択してください。
to_quantize = widgets.Checkbox(
value=True,
description='Quantization',
disabled=False,
)
to_quantize
Checkbox(value=True, description='Quantization')
量子化の実行¶
以下では量子化されたモデルを取得します。ソースコードについては utils.py を参照してください。量子化には比較的時間がかかり、完了するまでに時間がかかります。
from utils import get_quantized_pipeline
grammar_corrector_pipe_fp32 = grammar_corrector_pipe
grammar_corrector_pipe_int8 = None
if to_quantize.value:
quantized_model_path = Path("quantized_decoder_with_past") / "openvino_model.xml"
grammar_corrector_pipe_int8 = get_quantized_pipeline(grammar_corrector_pipe_fp32, grammar_corrector_tokenizer, core, grammar_corrector_dir,
quantized_model_path, device.value)
Collecting calibration data: 0%| | 0/10 [00:00<?, ?it/s]
/home/nsavel/workspace/openvino_notebooks/notebooks/214-grammar-correction/utils.py:39: FutureWarning: shared_memory is deprecated and will be removed in 2024.0. Value of shared_memory is going to override share_inputs value. Please use only share_inputs explicitly. return original_fn(*args, **kwargs)
Output()
Output()
Output()
Compiling the encoder to AUTO ...
Compiling the decoder to AUTO ...
Compiling the decoder to AUTO ...
Compiling the decoder to AUTO ...
修正結果を見てみましょう。量子化された INT8 モデルと元の FP32 モデルに対して生成されたテキストはほぼ同じになるはずです。
if to_quantize.value:
corrected_text_int8 = correct_text(default_text, grammar_checker_pipe, grammar_corrector_pipe_int8)
print(f"Input text: {default_text}\n")
print(f'Generated text by INT8 model: {corrected_text_int8}')
correcting text..: 0%| | 0/1 [00:00<?, ?it/s]
Input text: Most of the course is about semantic or content of language but there are also interesting topics to be learned from the servicefeatures except statistics in characters in documents.At this point, He introduces herself as his native English speaker and goes on to say that if you contine to work on social scnce
Generated text by INT8 model: Most of the course is about the semantic content of language but there are also interesting topics to be learned from the service features except statistics in characters in documents. At this point, she introduces himself as a native English speaker and goes on to say that if you continue to work on social issues, you will continue to be successful.
モデルのサイズ、パフォーマンス、精度を比較¶
まず、FP32 モデルと INT8 モデルのファイルサイズを比較します。
from utils import calculate_compression_rate
if to_quantize.value:
model_size_fp32, model_size_int8 = calculate_compression_rate(grammar_corrector_dir / "openvino_decoder_with_past_model.xml", quantized_model_path)
Model footprint comparison:
* FP32 IR model size: 1658150.26 KB
* INT8 IR model size: 415713.38 KB
次に、パフォーマンスと精度の観点から 2 つの文法修正パイプラインを比較します。
テストには、jfleg データセットのテスト分割が使用されます。データセット・サンプルは、入力としてエラーを含むテキストと、ラベルとして複数の修正バージョンで構成されます。精度を測定するときは、修正されたテキストバージョンに対して平均 (1 - WER) を使用します。ここで、WER は Word Error Rate メトリックです。
from utils import calculate_inference_time_and_accuracy
TEST_SUBSET_SIZE = 50
if to_quantize.value:
inference_time_fp32, accuracy_fp32 = calculate_inference_time_and_accuracy(grammar_corrector_pipe_fp32, TEST_SUBSET_SIZE)
print(f"Evaluation results of FP32 grammar correction pipeline. Accuracy: {accuracy_fp32:.2f}%. Time: {inference_time_fp32:.2f} sec.")
inference_time_int8, accuracy_int8 = calculate_inference_time_and_accuracy(grammar_corrector_pipe_int8, TEST_SUBSET_SIZE)
print(f"Evaluation results of INT8 grammar correction pipeline. Accuracy: {accuracy_int8:.2f}%. Time: {inference_time_int8:.2f} sec.")
print(f"Performance speedup: {inference_time_fp32 / inference_time_int8:.3f}")
print(f"Accuracy drop :{accuracy_fp32 - accuracy_int8:.2f}%.")
print(f"Model footprint reduction: {model_size_fp32 / model_size_int8:.3f}")
Evaluation: 0%| | 0/50 [00:00<?, ?it/s]
Evaluation results of FP32 grammar correction pipeline. Accuracy: 58.04%. Time: 61.03 sec.
Evaluation: 0%| | 0/50 [00:00<?, ?it/s]
Evaluation results of INT8 grammar correction pipeline. Accuracy: 57.46%. Time: 42.38 sec.
Performance speedup: 1.440
Accuracy drop :0.59%.
Model footprint reduction: 3.989
インタラクティブなデモ¶
import gradio as gr
import time
def correct(text, quantized, progress=gr.Progress(track_tqdm=True)):
grammar_corrector = grammar_corrector_pipe_int8 if quantized else grammar_corrector_pipe
start_time = time.perf_counter()
corrected_text = correct_text(text, grammar_checker_pipe, grammar_corrector)
end_time = time.perf_counter()
return corrected_text, f"{end_time - start_time:.2f}"
def create_demo_block(quantized: bool, show_model_type: bool):
model_type = (" optimized" if quantized else " original") if show_model_type else ""
with gr.Row():
gr.Markdown(f"## Run{model_type} grammar correction pipeline")
with gr.Row():
with gr.Column():
input_text = gr.Textbox(label="Text")
with gr.Column():
output_text = gr.Textbox(label="Correction")
correction_time = gr.Textbox(label="Time (seconds)")
with gr.Row():
gr.Examples(examples=[default_text], inputs=[input_text])
with gr.Row():
button = gr.Button(f"Run{model_type}")
button.click(correct, inputs=[input_text, gr.Number(quantized, visible=False)], outputs=[output_text, correction_time])
with gr.Blocks() as demo:
gr.Markdown("# Interactive demo")
quantization_is_present = grammar_corrector_pipe_int8 is not None
create_demo_block(quantized=False, show_model_type=quantization_is_present)
if quantization_is_present:
create_demo_block(quantized=True, show_model_type=True)
# if you are launching remotely, specify server_name and server_port
# demo.launch(server_name='your server name', server_port='server port in int')
# Read more in the docs: https://gradio.app/docs/
try:
demo.queue().launch(debug=False)
except Exception:
demo.queue().launch(share=True, debug=False)
Running on local URL: http://127.0.0.1:7860 To create a public link, set share=True in launch().