ControlNet コンディショニングによるテキストからの画像生成¶
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

拡散モデルは、AI によって生成されたアートに革命をもたらします。この技術により、テキストプロンプトを記述するだけで高品質な画像を作成できます。このテクノロジーは非常に有望な結果をもたらしますが、拡散プロセスはランダムなノイズとテキストの状態から画像を生成するプロセスであり、望ましいコンテンツがどのように見えるべきか、どのような形式であるべきか、どこに配置されるべきかを必ずしも明確にするわけではありません。 画像上の他のオブジェクトとの関係で配置されます。研究者は、生成プロセスの結果をより詳細に制御する方法を模索してきました。ControlNet は、生成プロセスを大幅にカスタマイズできる最小限のインターフェイスを提供します。
ControlNet は、論文「テキストから画像への拡散モデルへの条件付き制御の追加」で紹介されました。これは、深度マップ、セグメント化マップ、スクリブル、安定拡散などの拡散モデルへの追加条件として機能するキーポイントなど、さまざまな空間コンテキストのサポートを可能にするフレームワークを提供します。
このノートブックでは、ControlNet、特に合成画像の形状を高度に制御する新しい手法について詳しく説明します。OpenVINO を使用して実行する方法を説明します。“コントロール” を習得しましょう!
背景¶
Stable Diffusion¶
Stable Diffusion (安定拡散) は、CompVis、Stability AI、LAION の研究者とエンジニアによって作成されたテキストから画像への潜在拡散モデルです。このような拡散モデルを使用すると、高品質の画像を生成できます。安定拡散は、「潜在拡散モデルによる高解像度画像合成」論文で提案されている、潜在拡散と呼ばれるタイプの拡散モデルに基づいています。一般に、拡散モデルは、画像などの対象サンプルを取得するために、ランダムなガウスノイズを段階的に除去するようにトレーニングされたマシンラーニング・システムです。拡散モデルは、画像データを生成するため最先端の結果を達成することが示されています。ただし、拡散モデルの欠点は、逆ノイズ除去プロセスが反復的かつ逐次的に行われるため、処理が遅くなるです。さらに、これらのモデルはピクセル空間で動作するため、大量のメモリーを消費しますが、高解像度の画像を生成すると巨大なメモリーを消費します。潜在拡散では、実際のピクセル空間を使用する代わりに、低次元の潜在空間で拡散プロセスを適用することで、メモリーを削減し、複雑な計算を軽減できます。これが、標準拡散モデルと潜在拡散モデルの主な違いです。潜在拡散では、画像の潜在 (圧縮) 表現を生成するようにモデルがトレーニングされます。
潜在的な拡散には 3 つの主要コンポーネントがあります。
テキスト・エンコーダー、例えば、テキストプロンプトから画像を生成するための作成条件用の CLIP のテキスト・エンコーダー。
段階的にノイズを除去する潜像表現のための U-Net。
入力イメージを潜在空間にエンコードし (必要な場合)、生成後に潜在空間を画像にデコードするオートエンコーダー (VAE)。
安定拡散作業の詳細については、プロジェクトのウェブサイトを参照してください。OpenVINO を使用した安定拡散テキストから画像への生成に関するチュートリアルがあります。このノートブックを参照してください。
ControlNet¶
ControlNet は、条件を追加することで拡散モデルを制御するニューラル・ネットワーク構造です。この新しいフレームワークを使用すると、入力画像からシーン、構造、オブジェクト、または被写体のポーズをキャプチャーし、その品質を生成プロセスに転送できます。実際には、これによりモデルは元の入力形状を完全に保持し、入力されたプロンプトからの新しい特徴を使用しながら、形状、ポーズ、輪郭を保存する新しい画像を作成できます。
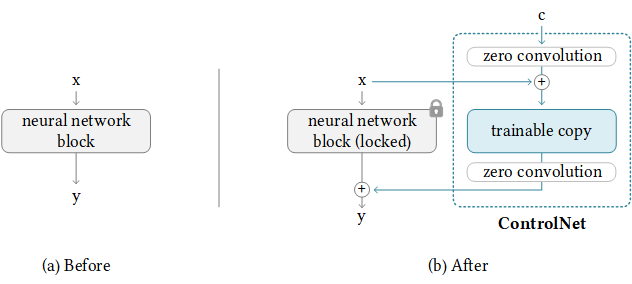
controlnet ブロック¶
機能的には、ControlNet は画像合成プロセスをラップアラウンドして動作し、組み込みの予測または多数の追加アノテーター・モデルの 1 つを使用してモデルを操作するのに必要な形状に注目します。上の図では、ControlNet が元のネットワークと組み合わせてトレーニング可能なコピーを使用して、入力制御ソースの形状に関して最終出力を変更する方法の基本が分かります。
上記の単純な構造を 14 回繰り返すことで、次のように安定拡散を制御できます。
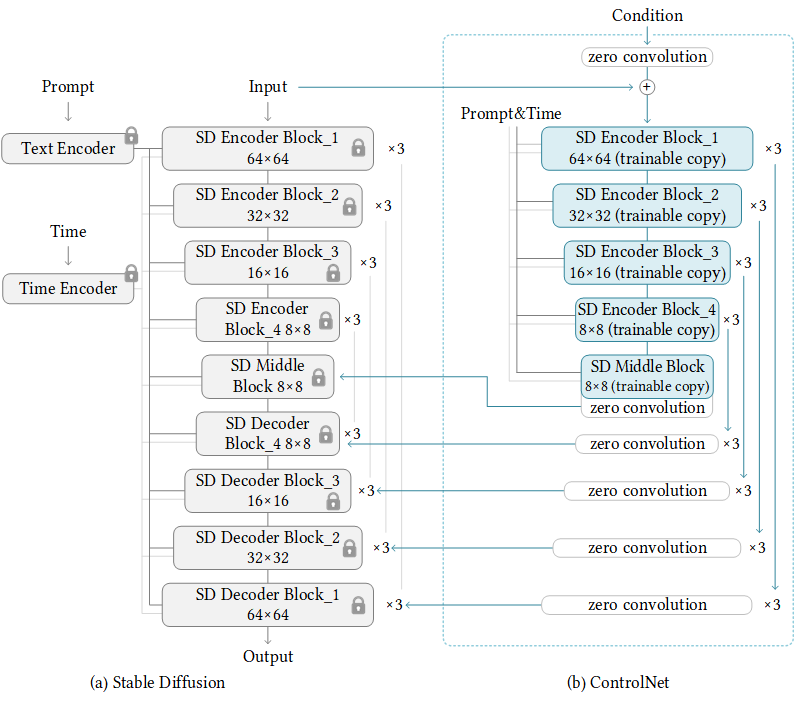
sd + controlnet¶
入力は、左側に示されている SD ブロックを同時に通過し、同時に右側の ControlNet ブロックによって処理されます。このプロセスはエンコード時とほぼ同じです。画像のノイズを除去する際に、SD デコーダーブロックは各ステップで ControlNet の並列処理パスから制御調整を受け取ります。
最終的には、最終画像の出力特徴の形状に対して追加の制御が追加された、非常によく似た画像合成パイプラインが残ります。
この ControlNet のチュートリアルは次のステップで構成されます。
Stable Diffusion の潜在的な UNet など、Diffusion モデルの事前トレーニング済みパラメーターを複製し (“トレーニング可能なコピー” と呼ばれる)、事前トレーニング済みパラメーターを個別に維持します (”ロックされたコピー”)。これは、ロックされたパラメーターのコピーが大規模なデータセットから学習した膨大な知識を保持できるよう、トレーニング可能なコピーがタスク固有の側面を学習するのに使用されるためです。
パラメーターのトレーニング可能でロックされたコピーは、ControlNet フレームワークの一部として最適化された “ゼロ畳み込み” レイヤーを介して接続されます。これは、新しい条件をトレーニングする際に、凍結されたモデルによってすでに学習されたセマンティクスを保持するトレーニングのトリックです。
入力画像から特定の情報を抽出する処理をアノテーションと呼びます。ControlNet は、画像内のターゲットの形状を識別するのに役立つアノテーター・モデルとの互換性を備えてあらかじめパッケージ化されています。
キャニーエッジ検出
M-LSD ライン
HED 境界
スクリブル
法線マップ
人間の姿勢推定
セマンティックのセグメント化。
深度推定
このチュートリアルでは、主にポーズによる条件に焦点を当てています。ただし、ここで説明した手順は他のアノテーション・モードにも適用できます。
必要条件¶
%pip install -q --extra-index-url https://download.pytorch.org/whl/cpu "torch" "torchvision"
%pip install -q "diffusers>=0.14.0" "transformers>=4.30.2" "controlnet-aux>=0.0.6" "gradio>=3.36" --extra-index-url https://download.pytorch.org/whl/cpu
%pip install -q "openvino>=2023.1.0"
生成パイプラインのインスタンス化¶
Diffusers ライブラリーの ControlNet¶
安定拡散モデルと ControlNet モデルを操作するには、Hugging Face Diffusers ライブラリーを使用します。ControlNet を実験するため、Diffuser は他の Diffuser パイプラインと同様に StableDiffusionControlNetPipeline を公開します。StableDiffusionControlNetPipeline の中核となるのは、事前トレーニングされた拡散モデルの重みを同じに保ちながら、独自にトレーニングされた ControlNetModel インスタンスを提供できるようにする controlnet 引数です。以下のコードは、controlnet-openpose controlnet モデルと stable-diffusion-v1-5 を使用して StableDiffusionControlNetPipeline を作成する方法を示しています。
import torch
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
controlnet = ControlNetModel.from_pretrained("lllyasviel/control_v11p_sd15_openpose", torch_dtype=torch.float32)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet
)
Loading pipeline components...: 0%| | 0/7 [00:00<?, ?it/s]
text_config_dict is provided which will be used to initialize CLIPTextConfig. The value text_config["id2label"] will be overriden. text_config_dict is provided which will be used to initialize CLIPTextConfig. The value text_config["bos_token_id"] will be overriden. text_config_dict is provided which will be used to initialize CLIPTextConfig. The value text_config["eos_token_id"] will be overriden.
OpenPose¶
アノテーションは、ControlNet を使用する上で重要です。OpenPose は、手、足、頭の位置など人間のポーズを抽出できる高速キーポイント検出モデルです。以下は OpenPose を使用した ControlNet ワークフローです。キーポイントは OpenPose を使用して入力画像から抽出され、キーポイントの位置を含む制御マップとして保存されます。次に、テキストプロンプトとともに追加の条件付けとして Stable Diffusion に送られます。これら 2 つの条件に基づいて画像が生成されます。
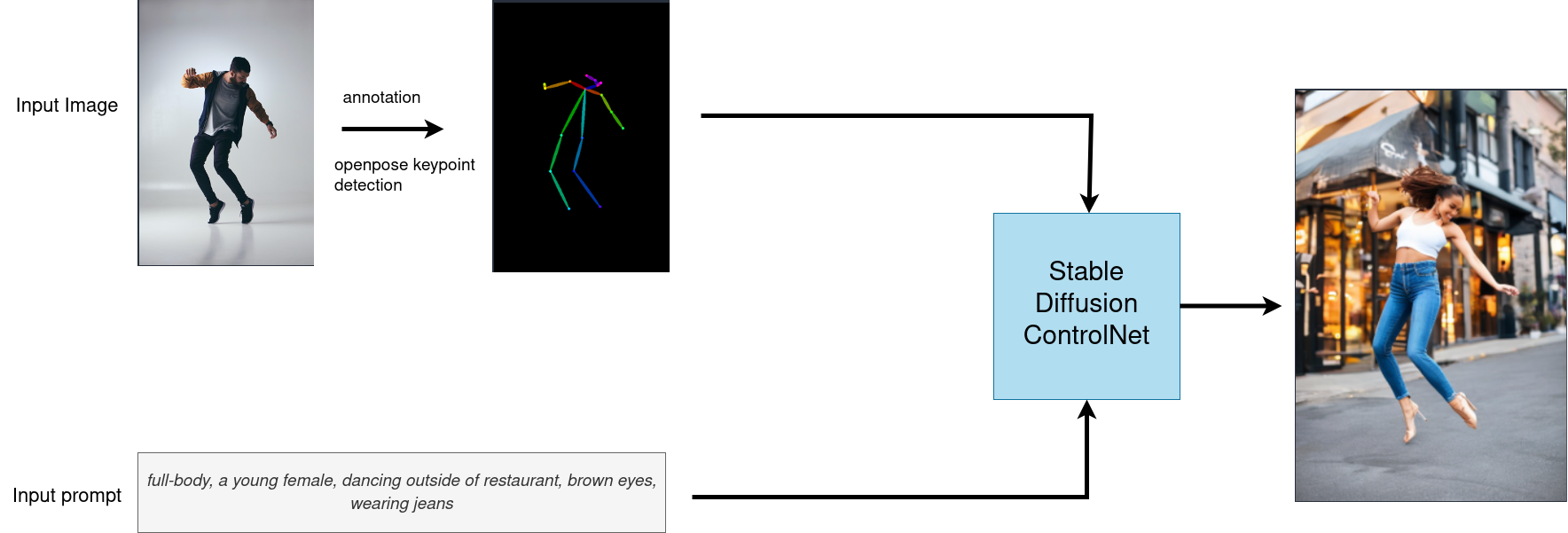
controlnet-openpose-pipe¶
以下のコードは、OpenPose モデルをインスタンス化する方法を示しています。
from controlnet_aux import OpenposeDetector
pose_estimator = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
/home/ea/work/openvino_notebooks/test_env/lib/python3.8/site-packages/controlnet_aux/mediapipe_face/mediapipe_face_common.py:7: UserWarning: The module 'mediapipe' is not installed. The package will have limited functionality. Please install it using the command: pip install 'mediapipe'
warnings.warn(
それでは、サンプル画像で結果を確認してみます。
import requests
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
example_url = "https://user-images.githubusercontent.com/29454499/224540208-c172c92a-9714-4a7b-857a-b1e54b4d4791.jpg"
img = Image.open(requests.get(example_url, stream=True).raw)
pose = pose_estimator(img)
def visualize_pose_results(orig_img:Image.Image, skeleton_img:Image.Image):
"""
Helper function for pose estimationresults visualization
Parameters:
orig_img (Image.Image): original image
skeleton_img (Image.Image): processed image with body keypoints
Returns:
fig (matplotlib.pyplot.Figure): matplotlib generated figure contains drawing result
"""
orig_img = orig_img.resize(skeleton_img.size)
orig_title = "Original image"
skeleton_title = "Pose"
im_w, im_h = orig_img.size
is_horizontal = im_h <= im_w
figsize = (20, 10) if is_horizontal else (10, 20)
fig, axs = plt.subplots(2 if is_horizontal else 1, 1 if is_horizontal else 2, figsize=figsize, sharex='all', sharey='all')
fig.patch.set_facecolor('white')
list_axes = list(axs.flat)
for a in list_axes:
a.set_xticklabels([])
a.set_yticklabels([])
a.get_xaxis().set_visible(False)
a.get_yaxis().set_visible(False)
a.grid(False)
list_axes[0].imshow(np.array(orig_img))
list_axes[1].imshow(np.array(skeleton_img))
list_axes[0].set_title(orig_title, fontsize=15)
list_axes[1].set_title(skeleton_title, fontsize=15)
fig.subplots_adjust(wspace=0.01 if is_horizontal else 0.00 , hspace=0.01 if is_horizontal else 0.1)
fig.tight_layout()
return fig
fig = visualize_pose_results(img, pose)

モデルを OpenVINO 中間表現 (IR) 形式に変換¶
2023.0 リリース以降、OpenVINO は PyTorch モデルの変換を直接サポートするようになりました。OpenVINO ov.Model オブジェクト・インスタンスを取得するには、モデル・オブジェクト、モデルトレース用の入力データを ov.convert_model 関数に提供する必要があります。ov.save_model 関数を使用して、次回のデプロイのためにモデルをディスクに保存できます。
パイプラインは 5 つの重要なパーツで構成されます。
推定されたポーズに基づいてアノテーションを取得する OpenPose。
画像アノテーションによる調整のための ControlNet。
テキストプロンプトから画像を生成する作成条件のテキスト・エンコーダー。
段階的にノイズを除去する潜像表現のための Unet。
潜在空間を画像にデコードするオートエンコーダー (VAE)。
各パーツを変換してみましょう。
OpenPose 変換¶
OpenPose モデルは、パイプライン内で PyTorch モデルのラッパーとして表現され、入力画像のポーズを検出するだけでなく、ポーズマップの描画も行います。ラッパー pose_estimator.body_estimation.model 内にある姿勢推定部分のみを変換する必要があります。
from pathlib import Path
import torch
import openvino as ov
OPENPOSE_OV_PATH = Path("openpose.xml")
def cleanup_torchscript_cache():
"""
Helper for removing cached model representation
"""
torch._C._jit_clear_class_registry()
torch.jit._recursive.concrete_type_store = torch.jit._recursive.ConcreteTypeStore()
torch.jit._state._clear_class_state()
if not OPENPOSE_OV_PATH.exists():
with torch.no_grad():
ov_model = ov.convert_model(pose_estimator.body_estimation.model, example_input=torch.zeros([1, 3, 184, 136]), input=[[1,3,184,136]])
ov.save_model(ov_model, OPENPOSE_OV_PATH)
del ov_model
cleanup_torchscript_cache()
print('OpenPose successfully converted to IR')
else:
print(f"OpenPose will be loaded from {OPENPOSE_OV_PATH}")
OpenPose successfully converted to IR
元の描画手順を再利用するには、次のコードを使用して、PyTorch OpenPose モデルを OpenVINO モデルに置き換えます。
from collections import namedtuple
class OpenPoseOVModel:
""" Helper wrapper for OpenPose model inference"""
def __init__(self, core, model_path, device="AUTO"):
self.core = core
self. model = core.read_model(model_path)
self.compiled_model = core.compile_model(self.model, device)
def __call__(self, input_tensor:torch.Tensor):
"""
inference step
Parameters:
input_tensor (torch.Tensor): tensor with prerpcessed input image
Returns:
predicted keypoints heatmaps
"""
h, w = input_tensor.shape[2:]
input_shape = self.model.input(0).shape
if h != input_shape[2] or w != input_shape[3]:
self.reshape_model(h, w)
results = self.compiled_model(input_tensor)
return torch.from_numpy(results[self.compiled_model.output(0)]), torch.from_numpy(results[self.compiled_model.output(1)])
def reshape_model(self, height:int, width:int):
"""
helper method for reshaping model to fit input data
Parameters:
height (int): input tensor height
width (int): input tensor width
Returns:
None
"""
self.model.reshape({0: [1, 3, height, width]})
self.compiled_model = self.core.compile_model(self.model)
def parameters(self):
Device = namedtuple("Device", ["device"])
return [Device(torch.device("cpu"))]
core = ov.Core()
推論デバイスの選択¶
OpenVINO を使用して推論を実行するためにドロップダウン・リストからデバイスを選択します。
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='AUTO',
description='Device:',
disabled=False,
)
device
Dropdown(description='Device:', index=2, options=('CPU', 'GPU', 'AUTO'), value='AUTO')
ov_openpose = OpenPoseOVModel(core, OPENPOSE_OV_PATH, device=device.value)
pose_estimator.body_estimation.model = ov_openpose
pose = pose_estimator(img)
fig = visualize_pose_results(img, pose)

これで完了です! ご覧のとおり、完璧に動作します。
ControlNet 変換¶
ControlNet モデルは、安定拡散パイプラインの UNet と同じ入力、および追加の条件サンプル (姿勢推定器によって予測されたスケルトン・キー・ポイント・マップ) を受け入れます。
sample- 前のステップの潜像サンプル。生成プロセスがまだ開始されていないため、ランダムノイズを使用します。timestep- 現在のスケジューラー・ステップ。encoder_hidden_state- テキスト・エンコーダーの非表示状態。controlnet_cond- 条件入力アノテーション。
モデルの出力は、下および中央のブロックからのアテンションの隠れ状態であり、UNet モデルの追加コンテキストとして機能します。
import gc
from functools import partial
inputs = {
"sample": torch.randn((2, 4, 64, 64)),
"timestep": torch.tensor(1),
"encoder_hidden_states": torch.randn((2,77,768)),
"controlnet_cond": torch.randn((2,3,512,512))
}
input_info = [(name, ov.PartialShape(inp.shape)) for name, inp in inputs.items()]
CONTROLNET_OV_PATH = Path('controlnet-pose.xml')
controlnet.eval()
with torch.no_grad():
down_block_res_samples, mid_block_res_sample = controlnet(**inputs, return_dict=False)
if not CONTROLNET_OV_PATH.exists():
with torch.no_grad():
controlnet.forward = partial(controlnet.forward, return_dict=False)
ov_model = ov.convert_model(controlnet, example_input=inputs, input=input_info)
ov.save_model(ov_model, CONTROLNET_OV_PATH)
del ov_model
cleanup_torchscript_cache()
print('ControlNet successfully converted to IR')
else:
print(f"ControlNet will be loaded from {CONTROLNET_OV_PATH}")
del controlnet
gc.collect()
ControlNet will be loaded from controlnet-pose.xml
9962
UNet 変換¶
UNet モデル変換のプロセスは、元の安定拡散モデルと同じですが、ControlNet によって生成された新しい入力を尊重します。
from typing import Tuple
UNET_OV_PATH = Path('unet_controlnet.xml')
dtype_mapping = {
torch.float32: ov.Type.f32,
torch.float64: ov.Type.f64,
torch.int32: ov.Type.i32,
torch.int64: ov.Type.i64
}
class UnetWrapper(torch.nn.Module):
def __init__(
self,
unet,
sample_dtype=torch.float32,
timestep_dtype=torch.int64,
encoder_hidden_states=torch.float32,
down_block_additional_residuals=torch.float32,
mid_block_additional_residual=torch.float32
):
super().__init__()
self.unet = unet
self.sample_dtype = sample_dtype
self.timestep_dtype = timestep_dtype
self.encoder_hidden_states_dtype = encoder_hidden_states
self.down_block_additional_residuals_dtype = down_block_additional_residuals
self.mid_block_additional_residual_dtype = mid_block_additional_residual
def forward(
self,
sample:torch.Tensor,
timestep:torch.Tensor,
encoder_hidden_states:torch.Tensor,
down_block_additional_residuals:Tuple[torch.Tensor],
mid_block_additional_residual:torch.Tensor
):
sample.to(self.sample_dtype)
timestep.to(self.timestep_dtype)
encoder_hidden_states.to(self.encoder_hidden_states_dtype)
down_block_additional_residuals = [res.to(self.down_block_additional_residuals_dtype) for res in down_block_additional_residuals]
mid_block_additional_residual.to(self.mid_block_additional_residual_dtype)
return self.unet(
sample,
timestep,
encoder_hidden_states,
down_block_additional_residuals=down_block_additional_residuals,
mid_block_additional_residual=mid_block_additional_residual
)
def flattenize_inputs(inputs):
flatten_inputs = []
for input_data in inputs:
if input_data is None:
continue
if isinstance(input_data, (list, tuple)):
flatten_inputs.extend(flattenize_inputs(input_data))
else:
flatten_inputs.append(input_data)
return flatten_inputs
if not UNET_OV_PATH.exists():
inputs.pop("controlnet_cond", None)
inputs["down_block_additional_residuals"] = down_block_res_samples
inputs["mid_block_additional_residual"] = mid_block_res_sample
unet = UnetWrapper(pipe.unet)
unet.eval()
with torch.no_grad():
ov_model = ov.convert_model(unet, example_input=inputs)
flatten_inputs = flattenize_inputs(inputs.values())
for input_data, input_tensor in zip(flatten_inputs, ov_model.inputs):
input_tensor.get_node().set_partial_shape(ov.PartialShape(input_data.shape))
input_tensor.get_node().set_element_type(dtype_mapping[input_data.dtype])
ov_model.validate_nodes_and_infer_types()
ov.save_model(ov_model, UNET_OV_PATH)
del ov_model
cleanup_torchscript_cache()
del unet
del pipe.unet
gc.collect()
print('Unet successfully converted to IR')
else:
del pipe.unet
print(f"Unet will be loaded from {UNET_OV_PATH}")
gc.collect()
Unet will be loaded from unet_controlnet.xml
0
テキスト・エンコーダー¶
テキスト・エンコーダーは、入力プロンプト (例えば、“馬に乗った宇宙飛行士の写真”) を、U-Net が理解できる埋め込みスペースに変換する役割を果たします。これは通常、入力トークンのシーケンスを潜在テキスト埋め込みのシーケンスにマッピングする単純なトランスフォーマー・ベースのエンコーダーです。
テキスト・エンコーダーの入力はテンソル input_ids です。これには、トークナイザーによって処理され、モデルによって受け入れられる最大長までパディングされたテキストからのトークン・インデックスが含まれます。モデルの出力は 2 つのテンソルです。
last_hidden_state- モデル内の最後の MultiHeadtention レイヤーからの非表示状態。pooler_out- モデル全体の非表示状態のプールされた出力。
TEXT_ENCODER_OV_PATH = Path('text_encoder.xml')
def convert_encoder(text_encoder:torch.nn.Module, ir_path:Path):
"""
Convert Text Encoder model to OpenVINO IR.
Function accepts text encoder model, prepares example inputs for conversion, and convert it to OpenVINO Model
Parameters:
text_encoder (torch.nn.Module): text_encoder model
ir_path (Path): File for storing model
Returns:
None
"""
if not ir_path.exists():
input_ids = torch.ones((1, 77), dtype=torch.long)
# switch model to inference mode
text_encoder.eval()
# disable gradients calculation for reducing memory consumption
with torch.no_grad():
ov_model = ov.convert_model(
text_encoder, # model instance
example_input=input_ids, # inputs for model tracing
input=([1,77],)
)
ov.save_model(ov_model, ir_path)
del ov_model
cleanup_torchscript_cache()
print('Text Encoder successfully converted to IR')
if not TEXT_ENCODER_OV_PATH.exists():
convert_encoder(pipe.text_encoder, TEXT_ENCODER_OV_PATH)
else:
print(f"Text encoder will be loaded from {TEXT_ENCODER_OV_PATH}")
del pipe.text_encoder
gc.collect()
Text encoder will be loaded from text_encoder.xml
0
VAE デコーダー変換¶
VAE モデルには、エンコーダーとデコーダーの 2 つのパーツがあります。エンコーダーは、画像を低次元の潜在表現に変換するのに使用され、これが U-Net モデルの入力となります。逆に、デコーダーは潜在表現を変換して画像に戻します。
潜在拡散トレーニング中、エンコーダーは、順拡散プロセス用の画像の潜在表現 (潜在) を取得するために使用され、各ステップでより多くのノイズが適用されます。推論中、逆拡散プロセスによって生成されたノイズ除去された潜在は、VAE デコーダーによって画像に変換されます。推論中に、VAE デコーダーのみが必要であることが分かります。エンコーダー部分を変換する方法については、安定拡散のノートブックに記載されています。
VAE_DECODER_OV_PATH = Path('vae_decoder.xml')
def convert_vae_decoder(vae: torch.nn.Module, ir_path: Path):
"""
Convert VAE model to IR format.
Function accepts pipeline, creates wrapper class for export only necessary for inference part,
prepares example inputs for convert,
Parameters:
vae (torch.nn.Module): VAE model
ir_path (Path): File for storing model
Returns:
None
"""
class VAEDecoderWrapper(torch.nn.Module):
def __init__(self, vae):
super().__init__()
self.vae = vae
def forward(self, latents):
return self.vae.decode(latents)
if not ir_path.exists():
vae_decoder = VAEDecoderWrapper(vae)
latents = torch.zeros((1, 4, 64, 64))
vae_decoder.eval()
with torch.no_grad():
ov_model = ov.convert_model(vae_decoder, example_input=latents, input=[(1,4,64,64),])
ov.save_model(ov_model, ir_path)
del ov_model
cleanup_torchscript_cache()
print('VAE decoder successfully converted to IR')
if not VAE_DECODER_OV_PATH.exists():
convert_vae_decoder(pipe.vae, VAE_DECODER_OV_PATH)
else:
print(f"VAE decoder will be loaded from {VAE_DECODER_OV_PATH}")
VAE decoder will be loaded from vae_decoder.xml
推論パイプラインの準備¶
すべてをまとめた論理フローを図から、モデルが推論でどのように機能するかを詳しく見てみましょう。
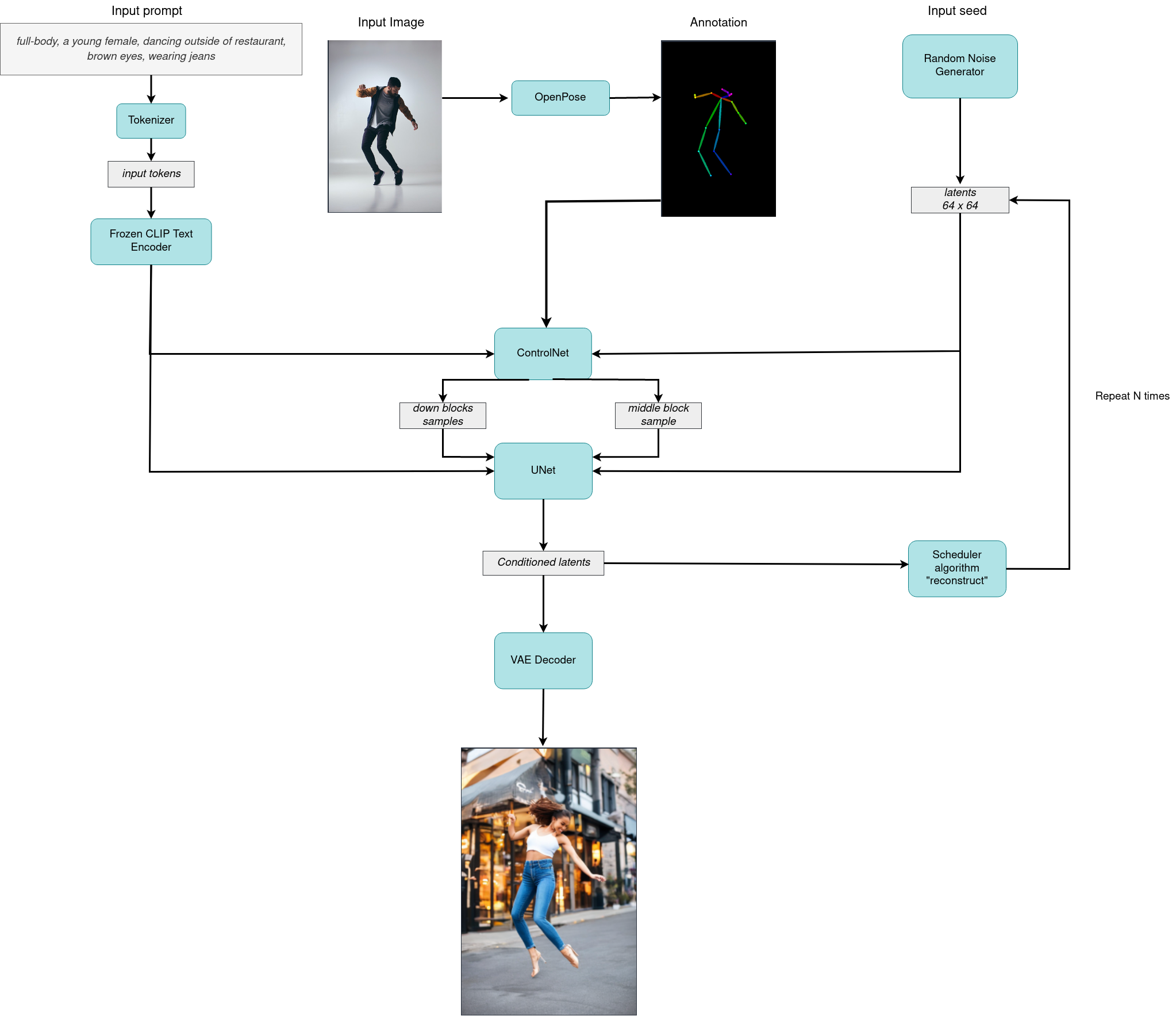
Stable diffusion モデルは、潜在シードとテキストプロンプトの両方を入力として受け取ります。次に、潜在シードを使用して、サイズ \(64 \times 64\) のランダムな潜在画像表現を生成します。ここで、テキストプロンプトは、CLIP のテキスト・エンコーダーを介してサイズ \(77 \times 768\) のテキスト埋め込みに変換されます。
次に、U-Net モデルは、テキスト埋め込みを条件として、ランダムな潜在画像表現を繰り返しノイズ除去します。中間ブロックと下流ブロックの注意パラメーターを取得するため、各ノイズ除去ステップで ControlNet を介して渡される元の stable-diffusion パイプライン、潜在画像表現、エンコーダーの隠れ状態、および制御条件注釈と比較して、これらの注意ブロックの結果は、制御生成プロセス向けに UNet モデルに追加で提供されます。U-Net の出力はノイズ残差であり、スケジューラー・アルゴリズムを介してノイズ除去された潜在画像表現を計算するために使用されます。この計算にはさまざまなスケジューラー・アルゴリズムを使用できますが、それぞれに長所と短所があります。Stable Diffusion の場合、次のいずれかを使用することを推奨します。
スケジューラーのアルゴリズム関数が動作する理論は、このノートブックの範囲外ですが、以前のノイズ表現と予測されたノイズ残差から、予測されたノイズ除去画像表現を計算することを覚えておく必要があります。詳細については、拡散ベースの生成モデルの設計空間の解明を参照することを推奨します。
このチュートリアルでは、Stable Diffusion のデフォルトの PNDMScheduler の代わりに、現在最も高速な拡散モデル・スケジューラーの 1 つである UniPCMultistepScheduler を使用します。改善されたスケジューラーを選択すると、推論時間を大幅に短縮できます。この場合、ほぼ同じ画像生成品質を維持しながら、推論ステップの数を 50 から 20 に減らすことができます。スケジューラーに関する詳細は、こちらを参照してください。
ノイズ除去プロセスは、指定された回数 (デフォルトでは 50 回) 繰り返され、段階的に潜在画像表現の改善が図られます。完了すると、潜在画像表現は変分オートエンコーダーのデコーダー部によってデコードされます。
Diffusers の StableDiffusionControlNetPipeline と同様に、OpenVINO に基づいて独自の OVContrlNetStableDiffusionPipeline 推論パイプラインを定義します。
from diffusers import DiffusionPipeline
from transformers import CLIPTokenizer
from typing import Union, List, Optional, Tuple
import cv2
def scale_fit_to_window(dst_width:int, dst_height:int, image_width:int, image_height:int):
"""
Preprocessing helper function for calculating image size for resize with peserving original aspect ratio
and fitting image to specific window size
Parameters:
dst_width (int): destination window width
dst_height (int): destination window height
image_width (int): source image width
image_height (int): source image height
Returns:
result_width (int): calculated width for resize
result_height (int): calculated height for resize
"""
im_scale = min(dst_height / image_height, dst_width / image_width)
return int(im_scale * image_width), int(im_scale * image_height)
def preprocess(image: Image.Image):
"""
Image preprocessing function. Takes image in PIL.Image format, resizes it to keep aspect ration and fits to model input window 512x512,
then converts it to np.ndarray and adds padding with zeros on right or bottom side of image (depends from aspect ratio), after that
converts data to float32 data type and change range of values from [0, 255] to [-1, 1], finally, converts data layout from planar NHWC to NCHW.
The function returns preprocessed input tensor and padding size, which can be used in postprocessing.
Parameters:
image (Image.Image): input image
Returns:
image (np.ndarray): preprocessed image tensor
pad (Tuple[int]): pading size for each dimension for restoring image size in postprocessing
"""
src_width, src_height = image.size
dst_width, dst_height = scale_fit_to_window(512, 512, src_width, src_height)
image = np.array(image.resize((dst_width, dst_height), resample=Image.Resampling.LANCZOS))[None, :]
pad_width = 512 - dst_width
pad_height = 512 - dst_height
pad = ((0, 0), (0, pad_height), (0, pad_width), (0, 0))
image = np.pad(image, pad, mode="constant")
image = image.astype(np.float32) / 255.0
image = image.transpose(0, 3, 1, 2)
return image, pad
def randn_tensor(
shape: Union[Tuple, List],
dtype: Optional[np.dtype] = np.float32,
):
"""
Helper function for generation random values tensor with given shape and data type
Parameters:
shape (Union[Tuple, List]): shape for filling random values
dtype (np.dtype, *optiona*, np.float32): data type for result
Returns:
latents (np.ndarray): tensor with random values with given data type and shape (usually represents noise in latent space)
"""
latents = np.random.randn(*shape).astype(dtype)
return latents
class OVContrlNetStableDiffusionPipeline(DiffusionPipeline):
"""
OpenVINO inference pipeline for Stable Diffusion with ControlNet guidence
"""
def __init__(
self,
tokenizer: CLIPTokenizer,
scheduler,
core: ov.Core,
controlnet: ov.Model,
text_encoder: ov.Model,
unet: ov.Model,
vae_decoder: ov.Model,
device:str = "AUTO"
):
super().__init__()
self.tokenizer = tokenizer
self.vae_scale_factor = 8
self.scheduler = scheduler
self.load_models(core, device, controlnet, text_encoder, unet, vae_decoder)
self.set_progress_bar_config(disable=True)
def load_models(self, core: ov.Core, device: str, controlnet:ov.Model, text_encoder: ov.Model, unet: ov.Model, vae_decoder: ov.Model):
"""
Function for loading models on device using OpenVINO
Parameters:
core (Core): OpenVINO runtime Core class instance
device (str): inference device
controlnet (Model): OpenVINO Model object represents ControlNet
text_encoder (Model): OpenVINO Model object represents text encoder
unet (Model): OpenVINO Model object represents UNet
vae_decoder (Model): OpenVINO Model object represents vae decoder
Returns
None
"""
self.text_encoder = core.compile_model(text_encoder, device)
self.text_encoder_out = self.text_encoder.output(0)
self.controlnet = core.compile_model(controlnet, device)
self.unet = core.compile_model(unet, device)
self.unet_out = self.unet.output(0)
self.vae_decoder = core.compile_model(vae_decoder)
self.vae_decoder_out = self.vae_decoder.output(0)
def __call__(
self,
prompt: Union[str, List[str]],
image: Image.Image,
num_inference_steps: int = 10,
negative_prompt: Union[str, List[str]] = None,
guidance_scale: float = 7.5,
controlnet_conditioning_scale: float = 1.0,
eta: float = 0.0,
latents: Optional[np.array] = None,
output_type: Optional[str] = "pil",
):
"""
Function invoked when calling the pipeline for generation.
Parameters:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
image (`Image.Image`):
`Image`, or tensor representing an image batch which will be repainted according to `prompt`.
num_inference_steps (`int`, *optional*, defaults to 100):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
negative_prompt (`str` or `List[str]`):
negative prompt or prompts for generation
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality. This pipeline requires a value of at least `1`.
latents (`np.ndarray`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `Image.Image` or `np.array`.
Returns:
image ([List[Union[np.ndarray, Image.Image]]): generaited images
"""
# 1. Define call parameters
batch_size = 1 if isinstance(prompt, str) else len(prompt)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 2. Encode input prompt
text_embeddings = self._encode_prompt(prompt, negative_prompt=negative_prompt)
# 3. Preprocess image
orig_width, orig_height = image.size
image, pad = preprocess(image)
height, width = image.shape[-2:]
if do_classifier_free_guidance:
image = np.concatenate(([image] * 2))
# 4. set timesteps
self.scheduler.set_timesteps(num_inference_steps)
timesteps = self.scheduler.timesteps
# 6. Prepare latent variables
num_channels_latents = 4
latents = self.prepare_latents(
batch_size,
num_channels_latents,
height,
width,
text_embeddings.dtype,
latents,
)
# 7. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# Expand the latents if we are doing classifier free guidance.
# The latents are expanded 3 times because for pix2pix the guidance\
# is applied for both the text and the input image.
latent_model_input = np.concatenate(
[latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
result = self.controlnet([latent_model_input, t, text_embeddings, image])
down_and_mid_blok_samples = [sample * controlnet_conditioning_scale for _, sample in result.items()]
# predict the noise residual
noise_pred = self.unet([latent_model_input, t, text_embeddings, *down_and_mid_blok_samples])[self.unet_out]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred[0], noise_pred[1]
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(torch.from_numpy(noise_pred), t, torch.from_numpy(latents)).prev_sample.numpy()
# update progress
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
# 8. Post-processing
image = self.decode_latents(latents, pad)
# 9. Convert to PIL
if output_type == "pil":
image = self.numpy_to_pil(image)
image = [img.resize((orig_width, orig_height), Image.Resampling.LANCZOS) for img in image]
else:
image = [cv2.resize(img, (orig_width, orig_width))
for img in image]
return image
def _encode_prompt(self, prompt:Union[str, List[str]], num_images_per_prompt:int = 1, do_classifier_free_guidance:bool = True, negative_prompt:Union[str, List[str]] = None):
"""
Encodes the prompt into text encoder hidden states.
Parameters:
prompt (str or list(str)): prompt to be encoded
num_images_per_prompt (int): number of images that should be generated per prompt
do_classifier_free_guidance (bool): whether to use classifier free guidance or not
negative_prompt (str or list(str)): negative prompt to be encoded
Returns:
text_embeddings (np.ndarray): text encoder hidden states
"""
batch_size = len(prompt) if isinstance(prompt, list) else 1
# tokenize input prompts
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="np",
)
text_input_ids = text_inputs.input_ids
text_embeddings = self.text_encoder(
text_input_ids)[self.text_encoder_out]
# duplicate text embeddings for each generation per prompt
if num_images_per_prompt != 1:
bs_embed, seq_len, _ = text_embeddings.shape
text_embeddings = np.tile(
text_embeddings, (1, num_images_per_prompt, 1))
text_embeddings = np.reshape(
text_embeddings, (bs_embed * num_images_per_prompt, seq_len, -1))
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
uncond_tokens: List[str]
max_length = text_input_ids.shape[-1]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
else:
uncond_tokens = negative_prompt
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="np",
)
uncond_embeddings = self.text_encoder(uncond_input.input_ids)[self.text_encoder_out]
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = uncond_embeddings.shape[1]
uncond_embeddings = np.tile(uncond_embeddings, (1, num_images_per_prompt, 1))
uncond_embeddings = np.reshape(uncond_embeddings, (batch_size * num_images_per_prompt, seq_len, -1))
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = np.concatenate([uncond_embeddings, text_embeddings])
return text_embeddings
def prepare_latents(self, batch_size:int, num_channels_latents:int, height:int, width:int, dtype:np.dtype = np.float32, latents:np.ndarray = None):
"""
Preparing noise to image generation. If initial latents are not provided, they will be generated randomly,
then prepared latents scaled by the standard deviation required by the scheduler
Parameters:
batch_size (int): input batch size
num_channels_latents (int): number of channels for noise generation
height (int): image height
width (int): image width
dtype (np.dtype, *optional*, np.float32): dtype for latents generation
latents (np.ndarray, *optional*, None): initial latent noise tensor, if not provided will be generated
Returns:
latents (np.ndarray): scaled initial noise for diffusion
"""
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
if latents is None:
latents = randn_tensor(shape, dtype=dtype)
else:
latents = latents
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
def decode_latents(self, latents:np.array, pad:Tuple[int]):
"""
Decode predicted image from latent space using VAE Decoder and unpad image result
Parameters:
latents (np.ndarray): image encoded in diffusion latent space
pad (Tuple[int]): each side padding sizes obtained on preprocessing step
Returns:
image: decoded by VAE decoder image
"""
latents = 1 / 0.18215 * latents
image = self.vae_decoder(latents)[self.vae_decoder_out]
(_, end_h), (_, end_w) = pad[1:3]
h, w = image.shape[2:]
unpad_h = h - end_h
unpad_w = w - end_w
image = image[:, :, :unpad_h, :unpad_w]
image = np.clip(image / 2 + 0.5, 0, 1)
image = np.transpose(image, (0, 2, 3, 1))
return image
from transformers import CLIPTokenizer
from diffusers import UniPCMultistepScheduler
tokenizer = CLIPTokenizer.from_pretrained('openai/clip-vit-large-patch14')
scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
def visualize_results(orig_img:Image.Image, skeleton_img:Image.Image, result_img:Image.Image):
"""
Helper function for results visualization
Parameters:
orig_img (Image.Image): original image
skeleton_img (Image.Image): image with body pose keypoints
result_img (Image.Image): generated image
Returns:
fig (matplotlib.pyplot.Figure): matplotlib generated figure contains drawing result
"""
orig_title = "Original image"
skeleton_title = "Pose"
orig_img = orig_img.resize(result_img.size)
im_w, im_h = orig_img.size
is_horizontal = im_h <= im_w
figsize = (20, 20)
fig, axs = plt.subplots(3 if is_horizontal else 1, 1 if is_horizontal else 3, figsize=figsize, sharex='all', sharey='all')
fig.patch.set_facecolor('white')
list_axes = list(axs.flat)
for a in list_axes:
a.set_xticklabels([])
a.set_yticklabels([])
a.get_xaxis().set_visible(False)
a.get_yaxis().set_visible(False)
a.grid(False)
list_axes[0].imshow(np.array(orig_img))
list_axes[1].imshow(np.array(skeleton_img))
list_axes[2].imshow(np.array(result_img))
list_axes[0].set_title(orig_title, fontsize=15)
list_axes[1].set_title(skeleton_title, fontsize=15)
list_axes[2].set_title("Result", fontsize=15)
fig.subplots_adjust(wspace=0.01 if is_horizontal else 0.00 , hspace=0.01 if is_horizontal else 0.1)
fig.tight_layout()
fig.savefig("result.png", bbox_inches='tight')
return fig
ControlNet コンディショニングと OpenVINO を使用したテキストから画像の生成実行¶
これで、生成の準備が整いました。生成プロセスを改善するために、否定プロンプトを提供する可能性も導入します。技術的には、ポジティブなプロンプトはそれに関連付けられた画像に向かって拡散を誘導し、ネガティブなプロンプトは拡散をそこから遠ざけるように誘導します。仕組みの詳細については、この記事を参照してください。否定的なプロンプトを表示せずに画像を生成したい場合は、このフィールドを空のままにすることができます。
Stable Diffusion パイプライン用の推論デバイスの選択¶
OpenVINO を使用して推論を実行するためにドロップダウン・リストからデバイスを選択します。
import ipywidgets as widgets
core = ov.Core()
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='CPU',
description='Device:',
disabled=False,
)
device
Dropdown(description='Device:', options=('CPU', 'GPU', 'AUTO'), value='CPU')
ov_pipe = OVContrlNetStableDiffusionPipeline(tokenizer, scheduler, core, CONTROLNET_OV_PATH, TEXT_ENCODER_OV_PATH, UNET_OV_PATH, VAE_DECODER_OV_PATH, device=device.value)
np.random.seed(42)
pose = pose_estimator(img)
prompt = "Dancing Darth Vader, best quality, extremely detailed"
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
result = ov_pipe(prompt, pose, 20, negative_prompt=negative_prompt)
result[0]

import gradio as gr
from urllib.request import urlretrieve
urlretrieve(example_url, "example.jpg")
gr.close_all()
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
inp_img = gr.Image(label="Input image")
pose_btn = gr.Button("Extract pose")
examples = gr.Examples(["example.jpg"], inp_img)
with gr.Column(visible=False) as step1:
out_pose = gr.Image(label="Estimated pose", type='pil')
inp_prompt = gr.Textbox(
"Dancing Darth Vader, best quality, extremely detailed", label="Prompt"
)
inp_neg_prompt = gr.Textbox(
"monochrome, lowres, bad anatomy, worst quality, low quality",
label="Negative prompt",
)
inp_seed = gr.Slider(label="Seed", value=42, maximum=1024000000)
inp_steps = gr.Slider(label="Steps", value=20, minimum=1, maximum=50)
btn = gr.Button()
with gr.Column(visible=False) as step2:
out_result = gr.Image(label="Result")
def extract_pose(img):
if img is None:
raise gr.Error("Please upload the image or use one from the examples list")
return {step1: gr.update(visible=True), step2: gr.update(visible=True), out_pose: pose_estimator(img)}
def generate(pose, prompt, negative_prompt, seed, num_steps, progress=gr.Progress(track_tqdm=True)):
np.random.seed(seed)
result = ov_pipe(prompt, pose, num_steps, negative_prompt)[0]
return result
pose_btn.click(extract_pose, inp_img, [out_pose, step1, step2])
btn.click(generate, [out_pose, inp_prompt, inp_neg_prompt, inp_seed, inp_steps], out_result)
try:
demo.queue().launch(debug=False)
except Exception:
demo.queue().launch(share=True, debug=False)
# if you are launching remotely, specify server_name and server_port
# demo.launch(server_name='your server name', server_port='server port in int')
# Read more in the docs: https://gradio.app/docs/