OpenVINO™ による自動デバイス選択¶
この Jupyter ノートブックはオンラインで起動でき、ブラウザーのウィンドウで対話型環境を開きます。ローカルにインストールすることもできます。次のオプションのいずれかを選択します。



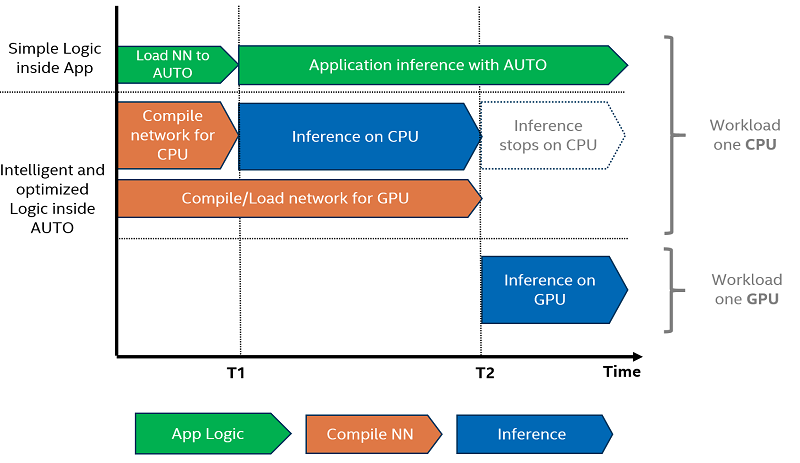
Auto デバイス (略して AUTO) は、モデルの精度、電力効率、利用可能な計算デバイスの処理能力を考慮して、推論に最適なデバイスを選択します。ネットワークを効率良く実行できないデバイスを除外するには、モデルの精度 (FP32、FP16、INT8 など) が最初に考慮されます。
次に、専用のアクセラレーターが利用可能な場合は、これらのデバイスが優先されます (例えば、統合およびディスクリート GPU)。CPU はデフォルトの “フォールバック・デバイス” として使用されます。AUTO では、モデルのロード中にこの選択が 1 回だけ行われることに注意してください。
GPU などのアクセラレーター・デバイスを使用する場合、これらのデバイスへのモデルのロードには時間がかかることがあります。高速な最初の推論応答を必要とするアプリケーションの課題に対処するため、AUTO は CPU 上で推論を直ちに開始し、準備が整うと推論を透過的に GPU に移行します。これにより、最初の推論を実行する時間が大幅に短縮されます。
auto¶
目次¶
モジュールをインポートしてコアを作成¶
# Install openvino package
%pip install -q "openvino>=2023.1.0"
Note: you may need to restart the kernel to use updated packages.
import time
import sys
import openvino as ov
from IPython.display import Markdown, display
core = ov.Core()
if "GPU" not in core.available_devices:
display(Markdown('<div class="alert alert-block alert-danger"><b>Warning: </b> A GPU device is not available. This notebook requires GPU device to have meaningful results. </div>'))
警告: GPU デバイスは使用できません。このノートブックで意味のある結果を得るには、GPU デバイスが必要です。
モデルを OpenVINO IR 形式に変換¶
このチュートリアルでは、torchvision ライブラリーの resnet50 モデルを使用します。ResNet 50 は、論文「画像認識のための深層残差学習」で説明されている ImageNet データセットで事前トレーニングされた画像分類モデルです。OpenVINO 2023.0 からは、モデル変換 API を使用してモデルを PyTorch 形式から OpenVINO IR 形式に直接変換できるようになりました。モデルを変換するには、モデル・オブジェクトのインスタンスを ov.convert_model 関数に提供する必要があります。オプションで、変換の入力形状を指定できます (デフォルトは、動的入力形状で変換された PyTorch からのモデルです)。ov.convert_model ov.compile_model を使用してデバイスにロードする準備ができている、または ov.save_model を使用して次回使用するためシリアル化する準備ができている openvino.runtime.Model オブジェクトを返します。
モデル変換 API の詳細については、このページを参照してください。
import torchvision
from pathlib import Path
base_model_dir = Path("./model")
base_model_dir.mkdir(exist_ok=True)
model_path = base_model_dir / "resnet50.xml"
if not model_path.exists():
pt_model = torchvision.models.resnet50(weights="DEFAULT")
ov_model = ov.convert_model(pt_model, input=[[1,3,224,224]])
ov.save_model(ov_model, str(model_path))
print("IR model saved to {}".format(model_path))
else:
print("Read IR model from {}".format(model_path))
ov_model = core.read_model(model_path)
IR model saved to model/resnet50.xml
(1) 選択ロジックの簡素化¶
device_name を指定しない Core::compile_model API のデフォルト動作¶
デフォルトでは、デバイスが指定されていない場合、compile_model API は device_name として AUTO を選択します。
# Set LOG_LEVEL to LOG_INFO.
core.set_property("AUTO", {"LOG_LEVEL":"LOG_INFO"})
# Load the model onto the target device.
compiled_model = core.compile_model(ov_model)
if isinstance(compiled_model, ov.CompiledModel):
print("Successfully compiled model without a device_name.")
[22:41:31.9445]I[plugin.cpp:536][AUTO] device:CPU, config:PERFORMANCE_HINT=LATENCY
[22:41:31.9445]I[plugin.cpp:536][AUTO] device:CPU, config:PERFORMANCE_HINT_NUM_REQUESTS=0
[22:41:31.9445]I[plugin.cpp:536][AUTO] device:CPU, config:PERF_COUNT=NO
[22:41:31.9445]I[plugin.cpp:541][AUTO] device:CPU, priority:0
[22:41:31.9446]I[schedule.cpp:17][AUTO] scheduler starting
[22:41:31.9446]I[auto_schedule.cpp:131][AUTO] select device:CPU
[22:41:32.0858]I[auto_schedule.cpp:109][AUTO] device:CPU compiling model finished
[22:41:32.0860]I[plugin.cpp:569][AUTO] underlying hardware does not support hardware context
Successfully compiled model without a device_name.
# Deleted model will wait until compiling on the selected device is complete.
del compiled_model
print("Deleted compiled_model")
Deleted compiled_model
[22:41:32.0982]I[schedule.cpp:303][AUTO] scheduler ending
AUTO を device_name として明示的に Core::compile_model API に渡す¶
これはオプションですが、device_name として AUTO を明示的に渡すと、コードの可読性が向上する可能性があります。
# Set LOG_LEVEL to LOG_NONE.
core.set_property("AUTO", {"LOG_LEVEL":"LOG_NONE"})
compiled_model = core.compile_model(model=ov_model, device_name="AUTO")
if isinstance(compiled_model, ov.CompiledModel):
print("Successfully compiled model using AUTO.")
Successfully compiled model using AUTO.
# Deleted model will wait until compiling on the selected device is complete.
del compiled_model
print("Deleted compiled_model")
Deleted compiled_model
(2) 最初の推論レイテンシーを改善¶
AUTO デバイス選択の利点の 1 つは、FIL (最初の推論レイテンシー) を削減することです。FIL は、モデルのコンパイル時間と最初の推論実行時間を合計した時間です。CPU デバイスを明示的に指定すると、OpenVINO グラフ表現がジャストインタイム (JIT) コンパイルを使用して CPU に迅速にロードされるため、最初の推論レイテンシーが最短になります。GPU に最適化されたカーネルへの OpenCL グラフのコンパイルには完了までに数秒かかるため、課題は GPU デバイスにあります。この初期化時間は、アプリケーションによっては許容できない場合があります。この遅延を回避するため、AUTO は GPU の準備が整うまで、最初の推論デバイスとして CPU を透過的に使用します。
画像のロード¶
torchvision ライブラリーはモデル固有の入力変換関数を提供します。これを入力データの準備に再利用します。
# Fetch `notebook_utils` module
import urllib.request
urllib.request.urlretrieve(
url='https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/main/notebooks/utils/notebook_utils.py',
filename='notebook_utils.py'
)
from notebook_utils import download_file
from PIL import Image
# Download the image from the openvino_notebooks storage
image_filename = download_file(
"https://storage.openvinotoolkit.org/repositories/openvino_notebooks/data/data/image/coco.jpg",
directory="data"
)
image = Image.open(str(image_filename))
input_transform = torchvision.models.ResNet50_Weights.DEFAULT.transforms()
input_tensor = input_transform(image)
input_tensor = input_tensor.unsqueeze(0).numpy()
image
data/coco.jpg: 0%| | 0.00/202k [00:00<?, ?B/s]

モデルを GPU デバイスにロードして推論を実行¶
if "GPU" not in core.available_devices:
print(f"A GPU device is not available. Available devices are: {core.available_devices}")
else :
# Start time.
gpu_load_start_time = time.perf_counter()
compiled_model = core.compile_model(model=ov_model, device_name="GPU") # load to GPU
# Execute the first inference.
results = compiled_model(input_tensor)[0]
# Measure time to the first inference.
gpu_fil_end_time = time.perf_counter()
gpu_fil_span = gpu_fil_end_time - gpu_load_start_time
print(f"Time to load model on GPU device and get first inference: {gpu_fil_end_time-gpu_load_start_time:.2f} seconds.")
del compiled_model
A GPU device is not available. Available devices are: ['CPU']
AUTO デバイスを使用してモデルをロードして推論を実行¶
GPU が利用可能な最良のデバイスである場合、最初のいくつかの推論は、GPU の準備ができるまで CPU 上で実行されます。
# Start time.
auto_load_start_time = time.perf_counter()
compiled_model = core.compile_model(model=ov_model) # The device_name is AUTO by default.
# Execute the first inference.
results = compiled_model(input_tensor)[0]
# Measure time to the first inference.
auto_fil_end_time = time.perf_counter()
auto_fil_span = auto_fil_end_time - auto_load_start_time
print(f"Time to load model using AUTO device and get first inference: {auto_fil_end_time-auto_load_start_time:.2f} seconds.")
Time to load model using AUTO device and get first inference: 0.16 seconds.
# Deleted model will wait for compiling on the selected device to complete.
del compiled_model
(3) 異なるターゲットに対して異なるパフォーマンスを達成¶
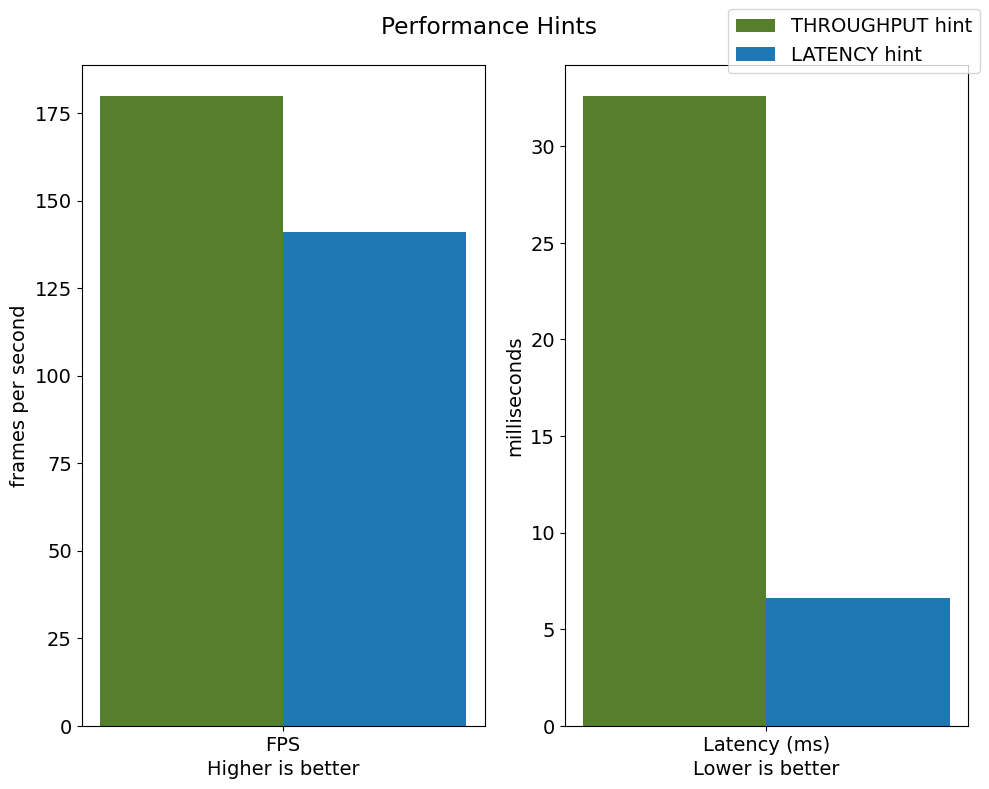
自動デバイス選択を使用する場合、パフォーマンスのヒントを定義すると利点があります。THROUGHPUT または LATENCY ヒントを指定すると、AUTO は必要なメトリックに基づいてパフォーマンスを最適化します。THROUGHPUT ヒントは、レイテンシーが低い LATENCY ヒントよりも高いフレーム/秒 (FPS) パフォーマンスを実現します。パフォーマンス・ヒントはデバイス固有の設定を必要とせず、デバイス間で完全に移行可能です。つまり、AUTO は、使用されているデバイスに関係なくパフォーマンス・ヒントを構成できます。
詳細については、自動デバイス選択の記事のパフォーマンスのヒントセクションを参照してください。
クラスとコールバックの定義¶
class PerformanceMetrics:
"""
Record the latest performance metrics (fps and latency), update the metrics in each @interval seconds
:member: fps: Frames per second, indicates the average number of inferences executed each second during the last @interval seconds.
:member: latency: Average latency of inferences executed in the last @interval seconds.
:member: start_time: Record the start timestamp of onging @interval seconds duration.
:member: latency_list: Record the latency of each inference execution over @interval seconds duration.
:member: interval: The metrics will be updated every @interval seconds
"""
def __init__(self, interval):
"""
Create and initilize one instance of class PerformanceMetrics.
:param: interval: The metrics will be updated every @interval seconds
:returns:
Instance of PerformanceMetrics
"""
self.fps = 0
self.latency = 0
self.start_time = time.perf_counter()
self.latency_list = []
self.interval = interval
def update(self, infer_request: ov.InferRequest) -> bool:
"""
Update the metrics if current ongoing @interval seconds duration is expired. Record the latency only if it is not expired.
:param: infer_request: InferRequest returned from inference callback, which includes the result of inference request.
:returns:
True, if metrics are updated.
False, if @interval seconds duration is not expired and metrics are not updated.
"""
self.latency_list.append(infer_request.latency)
exec_time = time.perf_counter() - self.start_time
if exec_time >= self.interval:
# Update the performance metrics.
self.start_time = time.perf_counter()
self.fps = len(self.latency_list) / exec_time
self.latency = sum(self.latency_list) / len(self.latency_list)
print(f"throughput: {self.fps: .2f}fps, latency: {self.latency: .2f}ms, time interval:{exec_time: .2f}s")
sys.stdout.flush()
self.latency_list = []
return True
else :
return False
class InferContext:
"""
Inference context. Record and update peforamnce metrics via @metrics, set @feed_inference to False once @remaining_update_num <=0
:member: metrics: instance of class PerformanceMetrics
:member: remaining_update_num: the remaining times for peforamnce metrics updating.
:member: feed_inference: if feed inference request is required or not.
"""
def __init__(self, update_interval, num):
"""
Create and initilize one instance of class InferContext.
:param: update_interval: The performance metrics will be updated every @update_interval seconds. This parameter will be passed to class PerformanceMetrics directly.
:param: num: The number of times performance metrics are updated.
:returns:
Instance of InferContext.
"""
self.metrics = PerformanceMetrics(update_interval)
self.remaining_update_num = num
self.feed_inference = True
def update(self, infer_request: ov.InferRequest):
"""
Update the context. Set @feed_inference to False if the number of remaining performance metric updates (@remaining_update_num) reaches 0
:param: infer_request: InferRequest returned from inference callback, which includes the result of inference request.
:returns: None
"""
if self.remaining_update_num <= 0 :
self.feed_inference = False
if self.metrics.update(infer_request) :
self.remaining_update_num = self.remaining_update_num - 1
if self.remaining_update_num <= 0 :
self.feed_inference = False
def completion_callback(infer_request: ov.InferRequest, context) -> None:
"""
callback for the inference request, pass the @infer_request to @context for updating
:param: infer_request: InferRequest returned for the callback, which includes the result of inference request.
:param: context: user data which is passed as the second parameter to AsyncInferQueue:start_async()
:returns: None
"""
context.update(infer_request)
# Performance metrics update interval (seconds) and number of times.
metrics_update_interval = 10
metrics_update_num = 6
THROUGHPUT ヒントを使用した推論¶
推論をループし、@metrics_update_interval 秒ごとに FPS/レイテンシーを更新します。
THROUGHPUT_hint_context = InferContext(metrics_update_interval, metrics_update_num)
print("Compiling Model for AUTO device with THROUGHPUT hint")
sys.stdout.flush()
compiled_model = core.compile_model(model=ov_model, config={"PERFORMANCE_HINT":"THROUGHPUT"})
infer_queue = ov.AsyncInferQueue(compiled_model, 0) # Setting to 0 will query optimal number by default.
infer_queue.set_callback(completion_callback)
print(f"Start inference, {metrics_update_num: .0f} groups of FPS/latency will be measured over {metrics_update_interval: .0f}s intervals")
sys.stdout.flush()
while THROUGHPUT_hint_context.feed_inference:
infer_queue.start_async(input_tensor, THROUGHPUT_hint_context)
infer_queue.wait_all()
# Take the FPS and latency of the latest period.
THROUGHPUT_hint_fps = THROUGHPUT_hint_context.metrics.fps
THROUGHPUT_hint_latency = THROUGHPUT_hint_context.metrics.latency
print("Done")
del compiled_model
Compiling Model for AUTO device with THROUGHPUT hint
Start inference, 6 groups of FPS/latency will be measured over 10s intervals
throughput: 179.69fps, latency: 31.58ms, time interval: 10.00s
throughput: 182.30fps, latency: 32.10ms, time interval: 10.00s
throughput: 180.62fps, latency: 32.36ms, time interval: 10.02s
throughput: 179.76fps, latency: 32.61ms, time interval: 10.00s
throughput: 180.36fps, latency: 32.36ms, time interval: 10.02s
throughput: 179.77fps, latency: 32.58ms, time interval: 10.00s
Done
LATENCY ヒントを使用した推論¶
推論をループし、@metrics_update_interval 秒ごとに FPS/レイテンシーを更新します。
LATENCY_hint_context = InferContext(metrics_update_interval, metrics_update_num)
print("Compiling Model for AUTO Device with LATENCY hint")
sys.stdout.flush()
compiled_model = core.compile_model(model=ov_model, config={"PERFORMANCE_HINT":"LATENCY"})
# Setting to 0 will query optimal number by default.
infer_queue = ov.AsyncInferQueue(compiled_model, 0)
infer_queue.set_callback(completion_callback)
print(f"Start inference, {metrics_update_num: .0f} groups fps/latency will be out with {metrics_update_interval: .0f}s interval")
sys.stdout.flush()
while LATENCY_hint_context.feed_inference:
infer_queue.start_async(input_tensor, LATENCY_hint_context)
infer_queue.wait_all()
# Take the FPS and latency of the latest period.
LATENCY_hint_fps = LATENCY_hint_context.metrics.fps
LATENCY_hint_latency = LATENCY_hint_context.metrics.latency
print("Done")
del compiled_model
Compiling Model for AUTO Device with LATENCY hint
Start inference, 6 groups fps/latency will be out with 10s interval
throughput: 139.27fps, latency: 6.65ms, time interval: 10.00s
throughput: 141.22fps, latency: 6.62ms, time interval: 10.01s
throughput: 140.71fps, latency: 6.64ms, time interval: 10.01s
throughput: 141.11fps, latency: 6.63ms, time interval: 10.01s
throughput: 141.26fps, latency: 6.62ms, time interval: 10.00s
throughput: 141.18fps, latency: 6.63ms, time interval: 10.00s
Done
FPS とレイテンシーの違い¶
import matplotlib.pyplot as plt
TPUT = 0
LAT = 1
labels = ["THROUGHPUT hint", "LATENCY hint"]
fig1, ax1 = plt.subplots(1, 1)
fig1.patch.set_visible(False)
ax1.axis('tight')
ax1.axis('off')
cell_text = []
cell_text.append(['%.2f%s' % (THROUGHPUT_hint_fps," FPS"), '%.2f%s' % (THROUGHPUT_hint_latency, " ms")])
cell_text.append(['%.2f%s' % (LATENCY_hint_fps," FPS"), '%.2f%s' % (LATENCY_hint_latency, " ms")])
table = ax1.table(cellText=cell_text, colLabels=["FPS (Higher is better)", "Latency (Lower is better)"], rowLabels=labels,
rowColours=["deepskyblue"] * 2, colColours=["deepskyblue"] * 2,
cellLoc='center', loc='upper left')
table.auto_set_font_size(False)
table.set_fontsize(18)
table.auto_set_column_width(0)
table.auto_set_column_width(1)
table.scale(1, 3)
fig1.tight_layout()
plt.show()

# Output the difference.
width = 0.4
fontsize = 14
plt.rc('font', size=fontsize)
fig, ax = plt.subplots(1,2, figsize=(10, 8))
rects1 = ax[0].bar([0], THROUGHPUT_hint_fps, width, label=labels[TPUT], color='#557f2d')
rects2 = ax[0].bar([width], LATENCY_hint_fps, width, label=labels[LAT])
ax[0].set_ylabel("frames per second")
ax[0].set_xticks([width / 2])
ax[0].set_xticklabels(["FPS"])
ax[0].set_xlabel("Higher is better")
rects1 = ax[1].bar([0], THROUGHPUT_hint_latency, width, label=labels[TPUT], color='#557f2d')
rects2 = ax[1].bar([width], LATENCY_hint_latency, width, label=labels[LAT])
ax[1].set_ylabel("milliseconds")
ax[1].set_xticks([width / 2])
ax[1].set_xticklabels(["Latency (ms)"])
ax[1].set_xlabel("Lower is better")
fig.suptitle('Performance Hints')
fig.legend(labels, fontsize=fontsize)
fig.tight_layout()
plt.show()