SAM および OpenVINO を使用したプロンプトからのオブジェクト・マスク¶
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

目次¶
セグメント化 (どの画像ピクセルがオブジェクトに属しているかを識別すること) は、コンピューター・ビジョンの中核となるタスクであり、科学画像の分析から写真の編集まで、幅広いアプリケーションで使用されます。しかし、特定のタスク向けに正確なセグメント化モデルを作成するには、通常、AI トレーニング・インフラストラクチャーと慎重にアノテーションが付けられた大量のドメイン内データにアクセスできる技術者による、高度に専門化された作業が必要です。タスク固有のモデリングの専門知識、トレーニング・コンピューティング、および画像セグメント化のためのカスタム・データ・アノテーションの必要性を軽減することが、Segment Anything プロジェクトの主な目標です。
Segment Anything Model (SAM) は、目的のオブジェクトを示すプロンプトが与えられた場合に、オブジェクト・マスクを予測します。SAM は、オブジェクトとは何かについて一般的な概念を学習しており、トレーニング中に遭遇しなかったオブジェクトや画像タイプも含めて、あらゆる画像またはビデオ内のあらゆるオブジェクトのマスクを生成できます。SAM は幅広いユースケースをカバーするには十分一般的であり、追加のトレーニングを必要とせずに、新しい画像 “ドメイン” (水中写真、MRI、細胞顕微鏡など) ですぐに使用できます (ゼロショット移行と呼ばれる機能)。このノートブックでは、Segment Anything Model を OpenVINO 形式に変換して使用し、OpenVINO をサポートするさまざまなプラットフォームで実行する方法の例を示します。
背景¶
以前は、あらゆる種類のセグメント化の問題を解決するには、2 つのクラスのアプローチがありました。1 つ目のインタラクティブ・セグメント化では、任意のクラスのオブジェクトをセグメント化できましたが、マスクを繰り返し調整してメソッドをガイドする必要がありました。2 番目の自動セグメント化では、事前に定義された特定のオブジェクト・カテゴリー (例: 猫や椅子) のセグメント化が可能でしたが、トレーニングするにはかなりの量の手動アノテーションによるオブジェクト (例: セグメント化された数千または数万の猫の例) が必要でした。 セグメント化モデルをトレーニングするためのコンピューティング・リソースと技術的専門知識も必要です。どちらのアプローチも、セグメント化に対する一般的で完全に自動化されたアプローチを提供していませんでした。
Segment Anything Model は、これら 2 つのクラスのアプローチを一般化したものです。インタラクティブなセグメント化と自動セグメント化の両方を簡単に実行できる単一のモデルです。Segment Anything Model (SAM) は、ポイントやボックスなどの入力プロンプトから高品質のオブジェクト・マスク生成、画像内のすべてのオブジェクトのマスクを生成するために使用できます。1,100 万枚の画像と 11 億枚のマスクのデータセットでトレーニングされており、さまざまなセグメント化タスクで強力なゼロショット・パフォーマンスを発揮します。モデルは 3 つのパーツで構成されます。
画像エンコーダー - 画像を埋め込み空間にエンコードするためマスクド・オートエンコーダー・アプローチ (MAE) を使用して事前トレーニングされたビジョン・トランスフォーマー・モデル (VIT)。画像エンコーダーは画像ごとに 1 回実行され、モデルにプロンプトを表示する前に適用できます。
-
プロンプト・エンコーダー - セグメント化条件のエンコーダー。条件としては次のように使用できます。
ポイント - セグメント化する必要があるオブジェクトに関連するポイントのセット。プロンプト・エンコーダーは、位置エンコーディングを使用してポイントを埋め込みに変換します。
-
ボックス - セグメント化オブジェクトが配置される境界ボックス。ポイントと同様に、位置エンコードによってエンコードされた境界ボックスの座標。
セグメント化マスク - ユーザーのセグメント化マスクによって提供されるマスクは、畳み込みを使用して埋め込まれ、画像の埋め込みと要素ごとに合計されます。
テキスト - CLIP モデルのテキスト表現によってエンコード。
マスクデコーダー - マスクデコーダは、画像の埋め込み、プロンプトの埋め込み、および出力トークンをマスクに効率的にマッピングします。
以下の図は、SAM を使用したマスク生成のプロセスを示しています。
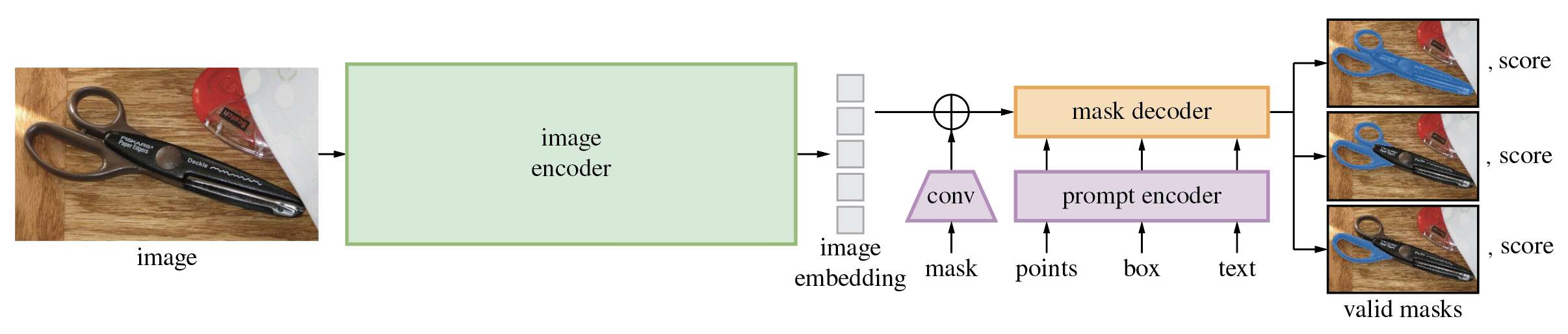
モデルは最初に画像を画像埋め込みに変換し、プロンプトから高品質のマスクを効率的に生成できるようにします。モデルは、指定されたプロンプトとそのスコアに適合する複数のマスクを返します。提供されたマスクは、図に示されているように重複領域にすることができ、プロンプトをさまざまな方法で解釈する複雑な場合に役立ちます。 オブジェクト全体またはその特定の部分のみをセグメント化するか、複数のオブジェクトの交差点にポイントを指定した場合にセグメント化します。モデルのプロンプト可能なインターフェイスにより、モデルの適切なプロンプト (クリック、ボックス、テキストなど) を設計するだけで、幅広いセグメント化タスクを可能にする柔軟な方法でモデルを使用できます。
アプローチの詳細については、論文、オリジナルのリポジトリー、および Meta AI のブログ投稿を参照してください。
必要条件¶
%pip install -q "segment_anything" "gradio>=4.13" "openvino>=2023.1.0" "nncf>=2.5.0" "torch>=2.1" "torchvision>=0.16" --extra-index-url https://download.pytorch.org/whl/cpu
モデルを OpenVINO 中間表現に変換¶
モデル・チェックポイントをダウンロードして PyTorch モデルを作成¶
ダウンロード可能な Segment Anything Model のチェックポイントがいくつかあります。このチュートリアルでは、vit_b に基づくモデルを使用しますが、実証されたアプローチは非常に一般的で、他の SAM モデルにも適用できます。モデル URL、チェックポイントを保存するパス、および以下のモデルタイプを SAM モデルのチェックポイントに設定し、sam_model_registry を使用してモデルをロードします。
import sys
sys.path.append("../utils")
from notebook_utils import download_file
checkpoint = "sam_vit_b_01ec64.pth"
model_url = "https://dl.fbaipublicfiles.com/segment_anything/sam_vit_b_01ec64.pth"
model_type = "vit_b"
download_file(model_url)
'sam_vit_b_01ec64.pth' already exists.
PosixPath('/home/ea/work/openvino_notebooks/notebooks/237-segment-anything/sam_vit_b_01ec64.pth')
from segment_anything import sam_model_registry
sam = sam_model_registry[model_type](checkpoint=checkpoint)
すでに説明したように、イメージ・エンコーダー・パーツはイメージごとに 1 回使用でき、その後、変更プロンプト、プロンプト・エンコーダー、およびマスクデコーダーを複数回実行して、同じイメージから異なるオブジェクトを取得できます。この事実を考慮して、モデルを 2 つの独立したパーツに分割します: image_encoder と Mask_predictor (プロンプト・エンコーダーとマスクデコーダーの組み合わせ)。
画像エンコーダー¶
イメージ・エンコーダーの入力は、NCHW 形式の 1x3x1024x1024 形状のテンソルで、セグメント化用のイメージが含まれています。画像エンコーダーの出力は画像埋め込み、形状 1x256x64x64 を含むテンソルです。
import warnings
from pathlib import Path
import torch
import openvino as ov
core = ov.Core()
ov_encoder_path = Path("sam_image_encoder.xml")
if not ov_encoder_path.exists():
with warnings.catch_warnings():
warnings.filterwarnings("ignore", category=torch.jit.TracerWarning)
warnings.filterwarnings("ignore", category=UserWarning)
ov_encoder_model = ov.convert_model(sam.image_encoder, example_input=torch.zeros(1,3,1024,1024), input=([1,3,1024,1024],))
ov.save_model(ov_encoder_model, ov_encoder_path)
else:
ov_encoder_model = core.read_model(ov_encoder_path)
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='AUTO',
description='Device:',
disabled=False,
)
device
Dropdown(description='Device:', index=2, options=('CPU', 'GPU', 'AUTO'), value='AUTO')
ov_encoder = core.compile_model(ov_encoder_model, device.value)
マスク予測子¶
このノートブックでは、モデルが return_single_mask=True パラメーターでエクスポートされたことを想定しています。これは、モデルが複数のマスクを返すのではなく、最適なマスクのみを返すことを意味します。高解像度画像の場合、マスクのアップスケールにコストがかかる場合、これにより実行時間が改善されます。
プロンプト・エンコーダーとマスクデコーダーを組み合わせたモデルには、次の入力リストがあります。
image_embeddings:image_encoderから埋め込まれた画像。長さ 1 のバッチ・インデックスがあります。-
point_coords: ポイント入力とボックス入力の両方に対応する、スパース入力プロンプトの座標。ボックスは、左上隅と右下隅の 2 つのポイントを使用してエンコードされます。座標は長辺 1024 に変換されている必要があります。長さ 1 のバッチ・インデックスがあります。 point_labels: スパース入力プロンプトのラベル。0 は負の入力ポイント、1 は正の入力ポイント、2 は左上のボックスの隅、3 は右下のボックスの隅、-1 はパディングポイントです。
*ボックス入力がない場合は、ラベル -1 と座標 (0.0, 0.0) を持つ単一のパディングポイントを連結する必要があります。
モデルの出力:
masks- バイナリーマスクを取得するには、元の画像サイズにサイズ変更された予測マスクをしきい値 (通常は 0.0) と比較する必要があります。iou_predictions- 和集合予測上の交差。low_res_masks- 後処理前の予測マスクは、モデルのマスク入力として使用できます。
from typing import Tuple
class SamExportableModel(torch.nn.Module):
def __init__(
self,
model,
return_single_mask: bool,
use_stability_score: bool = False,
return_extra_metrics: bool = False,
) -> None:
super().__init__()
self.mask_decoder = model.mask_decoder
self.model = model
self.img_size = model.image_encoder.img_size
self.return_single_mask = return_single_mask
self.use_stability_score = use_stability_score
self.stability_score_offset = 1.0
self.return_extra_metrics = return_extra_metrics
def _embed_points(self, point_coords: torch.Tensor, point_labels: torch.Tensor) -> torch.Tensor:
point_coords = point_coords + 0.5
point_coords = point_coords / self.img_size
point_embedding = self.model.prompt_encoder.pe_layer._pe_encoding(point_coords)
point_labels = point_labels.unsqueeze(-1).expand_as(point_embedding)
point_embedding = point_embedding * (point_labels != -1).to(torch.float32)
point_embedding = point_embedding + self.model.prompt_encoder.not_a_point_embed.weight * (
point_labels == -1
).to(torch.float32)
for i in range(self.model.prompt_encoder.num_point_embeddings):
point_embedding = point_embedding + self.model.prompt_encoder.point_embeddings[
i
].weight * (point_labels == i).to(torch.float32)
return point_embedding
def t_embed_masks(self, input_mask: torch.Tensor) -> torch.Tensor:
mask_embedding = self.model.prompt_encoder.mask_downscaling(input_mask)
return mask_embedding
def mask_postprocessing(self, masks: torch.Tensor) -> torch.Tensor:
masks = torch.nn.functional.interpolate(
masks,
size=(self.img_size, self.img_size),
mode="bilinear",
align_corners=False,
)
return masks
def select_masks(
self, masks: torch.Tensor, iou_preds: torch.Tensor, num_points: int
) -> Tuple[torch.Tensor, torch.Tensor]:
# Determine if we should return the multiclick mask or not from the number of points.
# The reweighting is used to avoid control flow.
score_reweight = torch.tensor(
[[1000] + [0] * (self.model.mask_decoder.num_mask_tokens - 1)]
).to(iou_preds.device)
score = iou_preds + (num_points - 2.5) * score_reweight
best_idx = torch.argmax(score, dim=1)
masks = masks[torch.arange(masks.shape[0]), best_idx, :, :].unsqueeze(1)
iou_preds = iou_preds[torch.arange(masks.shape[0]), best_idx].unsqueeze(1)
return masks, iou_preds
@torch.no_grad()
def forward(
self,
image_embeddings: torch.Tensor,
point_coords: torch.Tensor,
point_labels: torch.Tensor,
mask_input: torch.Tensor = None,
):
sparse_embedding = self._embed_points(point_coords, point_labels)
if mask_input is None:
dense_embedding = self.model.prompt_encoder.no_mask_embed.weight.reshape(1, -1, 1, 1).expand(
point_coords.shape[0], -1, image_embeddings.shape[0], 64
)
else:
dense_embedding = self._embed_masks(mask_input)
masks, scores = self.model.mask_decoder.predict_masks(
image_embeddings=image_embeddings,
image_pe=self.model.prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_embedding,
dense_prompt_embeddings=dense_embedding,
)
if self.use_stability_score:
scores = calculate_stability_score(
masks, self.model.mask_threshold, self.stability_score_offset
)
if self.return_single_mask:
masks, scores = self.select_masks(masks, scores, point_coords.shape[1])
upscaled_masks = self.mask_postprocessing(masks)
if self.return_extra_metrics:
stability_scores = calculate_stability_score(
upscaled_masks, self.model.mask_threshold, self.stability_score_offset
)
areas = (upscaled_masks > self.model.mask_threshold).sum(-1).sum(-1)
return upscaled_masks, scores, stability_scores, areas, masks
return upscaled_masks, scores
ov_model_path = Path("sam_mask_predictor.xml")
if not ov_model_path.exists():
exportable_model = SamExportableModel(sam, return_single_mask=True)
embed_dim = sam.prompt_encoder.embed_dim
embed_size = sam.prompt_encoder.image_embedding_size
dummy_inputs = {
"image_embeddings": torch.randn(1, embed_dim, *embed_size, dtype=torch.float),
"point_coords": torch.randint(low=0, high=1024, size=(1, 5, 2), dtype=torch.float),
"point_labels": torch.randint(low=0, high=4, size=(1, 5), dtype=torch.float),
}
with warnings.catch_warnings():
warnings.filterwarnings("ignore", category=torch.jit.TracerWarning)
warnings.filterwarnings("ignore", category=UserWarning)
ov_model = ov.convert_model(exportable_model, example_input=dummy_inputs)
ov.save_model(ov_model, ov_model_path)
else:
ov_model = core.read_model(ov_model_path)
device
Dropdown(description='Device:', index=2, options=('CPU', 'GPU', 'AUTO'), value='AUTO')
ov_predictor = core.compile_model(ov_model, device.value)
インタラクティブ・セグメント化モードで OpenVINO モデルを実行¶
画像例¶
import numpy as np
import cv2
import matplotlib.pyplot as plt
download_file("https://raw.githubusercontent.com/facebookresearch/segment-anything/main/notebooks/images/truck.jpg")
image = cv2.imread('truck.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
'truck.jpg' already exists.
plt.figure(figsize=(10,10))
plt.imshow(image)
plt.axis('off')
plt.show()

前処理および視覚化ユーティリティー¶
画像エンコーダーの入力を準備するには、以下を行う必要があります。
BGR 画像を RGB に変換します。
最長サイズが画像エンコーダーの入力サイズ - 1024 に等しいアスペクト比を保存して画像のサイズを変更します。
画像を正規化して平均値 (123.675、116.28、103.53) を減算し、std (58.395、57.12、57.375) で除算します。
HWC データレイアウトを CHW に転置し、バッチ次元を追加します。
画像エンコーダーが予期する入力形状に従って、高さまたは幅 (アスペクト比に応じて) によって入力テンソルにゼロパディングを追加します。
これらの手順は、利用可能なすべてのモデルに適用されます。
from copy import deepcopy
from typing import Tuple
from torchvision.transforms.functional import resize, to_pil_image
class ResizeLongestSide:
"""
Resizes images to longest side 'target_length', as well as provides
methods for resizing coordinates and boxes. Provides methods for
transforming numpy arrays.
"""
def __init__(self, target_length: int) -> None:
self.target_length = target_length
def apply_image(self, image: np.ndarray) -> np.ndarray:
"""
Expects a numpy array with shape HxWxC in uint8 format.
"""
target_size = self.get_preprocess_shape(image.shape[0], image.shape[1], self.target_length)
return np.array(resize(to_pil_image(image), target_size))
def apply_coords(self, coords: np.ndarray, original_size: Tuple[int, ...]) -> np.ndarray:
"""
Expects a numpy array of length 2 in the final dimension. Requires the
original image size in (H, W) format.
"""
old_h, old_w = original_size
new_h, new_w = self.get_preprocess_shape(
original_size[0], original_size[1], self.target_length
)
coords = deepcopy(coords).astype(float)
coords[..., 0] = coords[..., 0] * (new_w / old_w)
coords[..., 1] = coords[..., 1] * (new_h / old_h)
return coords
def apply_boxes(self, boxes: np.ndarray, original_size: Tuple[int, ...]) -> np.ndarray:
"""
Expects a numpy array shape Bx4. Requires the original image size
in (H, W) format.
"""
boxes = self.apply_coords(boxes.reshape(-1, 2, 2), original_size)
return boxes.reshape(-1, 4)
@staticmethod
def get_preprocess_shape(oldh: int, oldw: int, long_side_length: int) -> Tuple[int, int]:
"""
Compute the output size given input size and target long side length.
"""
scale = long_side_length * 1.0 / max(oldh, oldw)
newh, neww = oldh * scale, oldw * scale
neww = int(neww + 0.5)
newh = int(newh + 0.5)
return (newh, neww)
resizer = ResizeLongestSide(1024)
def preprocess_image(image: np.ndarray):
resized_image = resizer.apply_image(image)
resized_image = (resized_image.astype(np.float32) - [123.675, 116.28, 103.53]) / [58.395, 57.12, 57.375]
resized_image = np.expand_dims(np.transpose(resized_image, (2, 0, 1)).astype(np.float32), 0)
# Pad
h, w = resized_image.shape[-2:]
padh = 1024 - h
padw = 1024 - w
x = np.pad(resized_image, ((0, 0), (0, 0), (0, padh), (0, padw)))
return x
def postprocess_masks(masks: np.ndarray, orig_size):
size_before_pad = resizer.get_preprocess_shape(orig_size[0], orig_size[1], masks.shape[-1])
masks = masks[..., :int(size_before_pad[0]), :int(size_before_pad[1])]
masks = torch.nn.functional.interpolate(torch.from_numpy(masks), size=orig_size, mode="bilinear", align_corners=False).numpy()
return masks
def show_mask(mask, ax):
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels == 1]
neg_points = coords[labels == 0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white', linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white', linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0, 0, 0, 0), lw=2))
画像エンコード¶
画像の処理を開始するには、画像を前処理し、ov_encoder を使用して画像の埋め込みを取得する必要があります。すべての実験で同じ画像を使用するため、画像埋め込みを一度生成して再利用できます。
preprocessed_image = preprocess_image(image)
encoding_results = ov_encoder(preprocessed_image)
image_embeddings = encoding_results[ov_encoder.output(0)]
ここで、マスク生成のためのさまざまなプロンプトの提供を試みることができます。
ポイント入力例¶
この例では、1 つのポイントを選択します。緑色の星印は、下の画像上のその位置を示しています。
input_point = np.array([[500, 375]])
input_label = np.array([1])
plt.figure(figsize=(10,10))
plt.imshow(image)
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()

バッチ・インデックスを追加し、パディングポイントを連結して、入力テンソル座標系に変換します。
coord = np.concatenate([input_point, np.array([[0.0, 0.0]])], axis=0)[None, :, :]
label = np.concatenate([input_label, np.array([-1])], axis=0)[None, :].astype(np.float32)
coord = resizer.apply_coords(coord, image.shape[:2]).astype(np.float32)
マスク予測器で実行する入力をパッケージ化します。
inputs = {
"image_embeddings": image_embeddings,
"point_coords": coord,
"point_labels": label,
}
マスクを予測してしきい値にしバイナリーマスク (0 - オブジェクトなし、1 - オブジェクトあり) を取得します。
results = ov_predictor(inputs)
masks = results[ov_predictor.output(0)]
masks = postprocess_masks(masks, image.shape[:-1])
masks = masks > 0.0
plt.figure(figsize=(10,10))
plt.imshow(image)
show_mask(masks, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()

複数のポイントを含む例¶
この例では、より広いオブジェクト領域をカバーするため追加のポイントを提供します。
input_point = np.array([[500, 375], [1125, 625], [575, 750], [1405, 575]])
input_label = np.array([1, 1, 1, 1])
これにより、モデルのプロンプトは次の画像のようになります。
plt.figure(figsize=(10,10))
plt.imshow(image)
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()

前の例と同様にポイントを変換します。
coord = np.concatenate([input_point, np.array([[0.0, 0.0]])], axis=0)[None, :, :]
label = np.concatenate([input_label, np.array([-1])], axis=0)[None, :].astype(np.float32)
coord = resizer.apply_coords(coord, image.shape[:2]).astype(np.float32)
入力をパッケージ化し、マスクを予測してしきい値に設定します。
inputs = {
"image_embeddings": image_embeddings,
"point_coords": coord,
"point_labels": label,
}
results = ov_predictor(inputs)
masks = results[ov_predictor.output(0)]
masks = postprocess_masks(masks, image.shape[:-1])
masks = masks > 0.0
plt.figure(figsize=(10,10))
plt.imshow(image)
show_mask(masks, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()

これで完了です! 今は、マスクがトラック全体を覆うことが予測されています。
負のラベルが付いたボックスとポイントの入力例¶
この例では、境界ボックスとその内部のポイントから入力プロンプトを定義します。境界ボックスは、その左上隅と右下隅の点のセットとして表されます。ポイントラベル 0 は、このポイントをマスクから除外する必要があることを示します。
input_box = np.array([425, 600, 700, 875])
input_point = np.array([[575, 750]])
input_label = np.array([0])
plt.figure(figsize=(10, 10))
plt.imshow(image)
show_box(input_box, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()

バッチ・インデックスを追加し、ボックスとポイント入力を連結し、ボックスの角に適切なラベルを追加して変換します。入力にはボックス入力が含まれるため、パディングポイントはありません。
box_coords = input_box.reshape(2, 2)
box_labels = np.array([2,3])
coord = np.concatenate([input_point, box_coords], axis=0)[None, :, :]
label = np.concatenate([input_label, box_labels], axis=0)[None, :].astype(np.float32)
coord = resizer.apply_coords(coord, image.shape[:2]).astype(np.float32)
入力をパッケージ化し、マスクを予測してしきい値に設定します。
inputs = {
"image_embeddings": image_embeddings,
"point_coords": coord,
"point_labels": label,
}
results = ov_predictor(inputs)
masks = results[ov_predictor.output(0)]
masks = postprocess_masks(masks, image.shape[:-1])
masks = masks > 0.0
plt.figure(figsize=(10, 10))
plt.imshow(image)
show_mask(masks[0], plt.gca())
show_box(input_box, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()

インタラクティブなセグメント化¶
これで、独自のイメージで SAM を試すことができます。画像を入力ウィンドウにアップロードし、目的のポイントをクリックして、画像とポイントに基づいてモデルがセグメントを予測します。
import gradio as gr
class Segmenter:
def __init__(self, ov_encoder, ov_predictor):
self.encoder = ov_encoder
self.predictor = ov_predictor
self._img_embeddings = None
def set_image(self, img:np.ndarray):
if self._img_embeddings is not None:
del self._img_embeddings
preprocessed_image = preprocess_image(img)
encoding_results = self.encoder(preprocessed_image)
image_embeddings = encoding_results[ov_encoder.output(0)]
self._img_embeddings = image_embeddings
return img
def get_mask(self, points, img):
coord = np.array(points)
coord = np.concatenate([coord, np.array([[0,0]])], axis=0)
coord = coord[None, :, :]
label = np.concatenate([np.ones(len(points)), np.array([-1])], axis=0)[None, :].astype(np.float32)
coord = resizer.apply_coords(coord, img.shape[:2]).astype(np.float32)
if self._img_embeddings is None:
self.set_image(img)
inputs = {
"image_embeddings": self._img_embeddings,
"point_coords": coord,
"point_labels": label,
}
results = self.predictor(inputs)
masks = results[ov_predictor.output(0)]
masks = postprocess_masks(masks, img.shape[:-1])
masks = masks > 0.0
mask = masks[0]
mask = np.transpose(mask, (1, 2, 0))
return mask
segmenter = Segmenter(ov_encoder, ov_predictor)
with gr.Blocks() as demo:
with gr.Row():
input_img = gr.Image(label="Input", type="numpy", height=480, width=480)
output_img = gr.Image(label="Selected Segment", type="numpy", height=480, width=480)
def on_image_change(img):
segmenter.set_image(img)
return img
def get_select_coords(img, evt: gr.SelectData):
pixels_in_queue = set()
h, w = img.shape[:2]
pixels_in_queue.add((evt.index[0], evt.index[1]))
out = img.copy()
while len(pixels_in_queue) > 0:
pixels = list(pixels_in_queue)
pixels_in_queue = set()
color = np.random.randint(0, 255, size=(1, 1, 3))
mask = segmenter.get_mask(pixels, img)
mask_image = out.copy()
mask_image[mask.squeeze(-1)] = color
out = cv2.addWeighted(out.astype(np.float32), 0.7, mask_image.astype(np.float32), 0.3, 0.0)
out = out.astype(np.uint8)
return out
input_img.select(get_select_coords, [input_img], output_img)
input_img.upload(on_image_change, [input_img], [input_img])
if __name__ == "__main__":
try:
demo.launch()
except Exception:
demo.launch(share=True)
Running on local URL: http://127.0.0.1:7860 To create a public link, set share=True in launch().
OpenVINO モデルを自動マスク生成モードで実行¶
SAM はプロンプトを効率的に処理できるため、画像上で多数のプロンプトをサンプリングすることで画像全体のマスクを生成できます。automatic_mask_generation 関数はこの機能を実装します。これは、画像上のグリッド内の単一ポイントの入力プロンプトをサンプリングすることによって機能し、SAM はそれぞれのプロンプトから複数のマスクを予測できます。次に、マスクは品質のためにフィルター処理され、非最大抑制により重複が排除されます。追加のオプションにより、画像の複数クロップに対して予測を実行したり、マスクの後処理を行って小さくカットされた領域や穴を除去したりするなど、マスクの品質と量をさらに向上させることができます。
from segment_anything.utils.amg import (
MaskData,
generate_crop_boxes,
uncrop_boxes_xyxy,
uncrop_masks,
uncrop_points,
calculate_stability_score,
rle_to_mask,
batched_mask_to_box,
mask_to_rle_pytorch,
is_box_near_crop_edge,
batch_iterator,
remove_small_regions,
build_all_layer_point_grids,
box_xyxy_to_xywh,
area_from_rle
)
from torchvision.ops.boxes import batched_nms, box_area
from typing import Tuple, List, Dict, Any
def process_batch(
image_embedding: np.ndarray,
points: np.ndarray,
im_size: Tuple[int, ...],
crop_box: List[int],
orig_size: Tuple[int, ...],
iou_thresh,
mask_threshold,
stability_score_offset,
stability_score_thresh
) -> MaskData:
orig_h, orig_w = orig_size
# Run model on this batch
transformed_points = resizer.apply_coords(points, im_size)
in_points = transformed_points
in_labels = np.ones(in_points.shape[0], dtype=int)
inputs = {
"image_embeddings": image_embedding,
"point_coords": in_points[:, None, :],
"point_labels": in_labels[:, None],
}
res = ov_predictor(inputs)
masks = postprocess_masks(res[ov_predictor.output(0)], orig_size)
masks = torch.from_numpy(masks)
iou_preds = torch.from_numpy(res[ov_predictor.output(1)])
# Serialize predictions and store in MaskData
data = MaskData(
masks=masks.flatten(0, 1),
iou_preds=iou_preds.flatten(0, 1),
points=torch.as_tensor(points.repeat(masks.shape[1], axis=0)),
)
del masks
# Filter by predicted IoU
if iou_thresh > 0.0:
keep_mask = data["iou_preds"] > iou_thresh
data.filter(keep_mask)
# Calculate stability score
data["stability_score"] = calculate_stability_score(
data["masks"], mask_threshold, stability_score_offset
)
if stability_score_thresh > 0.0:
keep_mask = data["stability_score"] >= stability_score_thresh
data.filter(keep_mask)
# Threshold masks and calculate boxes
data["masks"] = data["masks"] > mask_threshold
data["boxes"] = batched_mask_to_box(data["masks"])
# Filter boxes that touch crop boundaries
keep_mask = ~is_box_near_crop_edge(data["boxes"], crop_box, [0, 0, orig_w, orig_h])
if not torch.all(keep_mask):
data.filter(keep_mask)
# Compress to RLE
data["masks"] = uncrop_masks(data["masks"], crop_box, orig_h, orig_w)
data["rles"] = mask_to_rle_pytorch(data["masks"])
del data["masks"]
return data
def process_crop(
image: np.ndarray,
point_grids,
crop_box: List[int],
crop_layer_idx: int,
orig_size: Tuple[int, ...],
box_nms_thresh:float = 0.7,
mask_threshold:float = 0.0,
points_per_batch: int = 64,
pred_iou_thresh: float = 0.88,
stability_score_thresh: float = 0.95,
stability_score_offset: float = 1.0,
) -> MaskData:
# Crop the image and calculate embeddings
x0, y0, x1, y1 = crop_box
cropped_im = image[y0:y1, x0:x1, :]
cropped_im_size = cropped_im.shape[:2]
preprocessed_cropped_im = preprocess_image(cropped_im)
crop_embeddings = ov_encoder(preprocessed_cropped_im)[ov_encoder.output(0)]
# Get points for this crop
points_scale = np.array(cropped_im_size)[None, ::-1]
points_for_image = point_grids[crop_layer_idx] * points_scale
# Generate masks for this crop in batches
data = MaskData()
for (points,) in batch_iterator(points_per_batch, points_for_image):
batch_data = process_batch(crop_embeddings, points, cropped_im_size, crop_box, orig_size, pred_iou_thresh, mask_threshold, stability_score_offset, stability_score_thresh)
data.cat(batch_data)
del batch_data
# Remove duplicates within this crop.
keep_by_nms = batched_nms(
data["boxes"].float(),
data["iou_preds"],
torch.zeros(len(data["boxes"])), # categories
iou_threshold=box_nms_thresh,
)
data.filter(keep_by_nms)
# Return to the original image frame
data["boxes"] = uncrop_boxes_xyxy(data["boxes"], crop_box)
data["points"] = uncrop_points(data["points"], crop_box)
data["crop_boxes"] = torch.tensor([crop_box for _ in range(len(data["rles"]))])
return data
def generate_masks(image: np.ndarray, point_grids, crop_n_layers, crop_overlap_ratio, crop_nms_thresh) -> MaskData:
orig_size = image.shape[:2]
crop_boxes, layer_idxs = generate_crop_boxes(
orig_size, crop_n_layers, crop_overlap_ratio
)
# Iterate over image crops
data = MaskData()
for crop_box, layer_idx in zip(crop_boxes, layer_idxs):
crop_data = process_crop(image, point_grids, crop_box, layer_idx, orig_size)
data.cat(crop_data)
# Remove duplicate masks between crops
if len(crop_boxes) > 1:
# Prefer masks from smaller crops
scores = 1 / box_area(data["crop_boxes"])
scores = scores.to(data["boxes"].device)
keep_by_nms = batched_nms(
data["boxes"].float(),
scores,
torch.zeros(len(data["boxes"])), # categories
iou_threshold=crop_nms_thresh,
)
data.filter(keep_by_nms)
data.to_numpy()
return data
def postprocess_small_regions(mask_data: MaskData, min_area: int, nms_thresh: float) -> MaskData:
"""
Removes small disconnected regions and holes in masks, then reruns
box NMS to remove any new duplicates.
Edits mask_data in place.
Requires open-cv as a dependency.
"""
if len(mask_data["rles"]) == 0:
return mask_data
# Filter small disconnected regions and holes
new_masks = []
scores = []
for rle in mask_data["rles"]:
mask = rle_to_mask(rle)
mask, changed = remove_small_regions(mask, min_area, mode="holes")
unchanged = not changed
mask, changed = remove_small_regions(mask, min_area, mode="islands")
unchanged = unchanged and not changed
new_masks.append(torch.as_tensor(mask).unsqueeze(0))
# Give score=0 to changed masks and score=1 to unchanged masks
# so NMS will prefer ones that didn't need postprocessing
scores.append(float(unchanged))
# Recalculate boxes and remove any new duplicates
masks = torch.cat(new_masks, dim=0)
boxes = batched_mask_to_box(masks)
keep_by_nms = batched_nms(
boxes.float(),
torch.as_tensor(scores),
torch.zeros(len(boxes)), # categories
iou_threshold=nms_thresh,
)
# Only recalculate RLEs for masks that have changed
for i_mask in keep_by_nms:
if scores[i_mask] == 0.0:
mask_torch = masks[i_mask].unsqueeze(0)
mask_data["rles"][i_mask] = mask_to_rle_pytorch(mask_torch)[0]
# update res directly
mask_data["boxes"][i_mask] = boxes[i_mask]
mask_data.filter(keep_by_nms)
return mask_data
自動マスク生成には、ポイントのサンプリング密度と、低品質または重複したマスクを削除するしきい値制御のため調整可能なパラメーターがいくつかあります。さらに、画像の切り抜きに対して生成を自動的に実行して、小さなオブジェクトのパフォーマンスを向上させることができ、後処理により、浮遊ピクセルや穴を除去できます。
def automatic_mask_generation(
image: np.ndarray, min_mask_region_area: int = 0, points_per_side: int = 32, crop_n_layers: int = 0, crop_n_points_downscale_factor: int = 1, crop_overlap_ratio: float = 512 / 1500, box_nms_thresh: float = 0.7, crop_nms_thresh: float = 0.7
) -> List[Dict[str, Any]]:
"""
Generates masks for the given image.
Arguments:
image (np.ndarray): The image to generate masks for, in HWC uint8 format.
Returns:
list(dict(str, any)): A list over records for masks. Each record is
a dict containing the following keys:
segmentation (dict(str, any) or np.ndarray): The mask. If
output_mode='binary_mask', is an array of shape HW. Otherwise,
is a dictionary containing the RLE.
bbox (list(float)): The box around the mask, in XYWH format.
area (int): The area in pixels of the mask.
predicted_iou (float): The model's own prediction of the mask's
quality. This is filtered by the pred_iou_thresh parameter.
point_coords (list(list(float))): The point coordinates input
to the model to generate this mask.
stability_score (float): A measure of the mask's quality. This
is filtered on using the stability_score_thresh parameter.
crop_box (list(float)): The crop of the image used to generate
the mask, given in XYWH format.
"""
point_grids = build_all_layer_point_grids(
points_per_side,
crop_n_layers,
crop_n_points_downscale_factor,
)
mask_data = generate_masks(
image, point_grids, crop_n_layers, crop_overlap_ratio, crop_nms_thresh)
# Filter small disconnected regions and holes in masks
if min_mask_region_area > 0:
mask_data = postprocess_small_regions(
mask_data,
min_mask_region_area,
max(box_nms_thresh, crop_nms_thresh),
)
mask_data["segmentations"] = [
rle_to_mask(rle) for rle in mask_data["rles"]]
# Write mask records
curr_anns = []
for idx in range(len(mask_data["segmentations"])):
ann = {
"segmentation": mask_data["segmentations"][idx],
"area": area_from_rle(mask_data["rles"][idx]),
"bbox": box_xyxy_to_xywh(mask_data["boxes"][idx]).tolist(),
"predicted_iou": mask_data["iou_preds"][idx].item(),
"point_coords": [mask_data["points"][idx].tolist()],
"stability_score": mask_data["stability_score"][idx].item(),
"crop_box": box_xyxy_to_xywh(mask_data["crop_boxes"][idx]).tolist(),
}
curr_anns.append(ann)
return curr_anns
prediction = automatic_mask_generation(image)
automatic_mask_generation はマスクに関するリストを返します。各マスクは、マスクに関するさまざまなデータを含む辞書です。これらのキーは次のとおりです。
segmentation: マスクarea: マスクの面積 (ピクセル単位)bbox: XYWH 形式のマスクの境界ボックスpredicted_iou: マスクの品質に関するモデル自身の予測point_coords: このマスクを生成したサンプリングされた入力ポイントstability_score: マスク品質の追加の尺度crop_box: XYWH 形式でこのマスクを生成するために使用される画像のトリミング
print(f"Number of detected masks: {len(prediction)}")
print(f"Annotation keys: {prediction[0].keys()}")
Number of detected masks: 48
Annotation keys: dict_keys(['segmentation', 'area', 'bbox', 'predicted_iou', 'point_coords', 'stability_score', 'crop_box'])
from tqdm.notebook import tqdm
def draw_anns(image, anns):
if len(anns) == 0:
return
segments_image = image.copy()
sorted_anns = sorted(anns, key=(lambda x: x['area']), reverse=True)
for ann in tqdm(sorted_anns):
mask = ann["segmentation"]
mask_color = np.random.randint(0, 255, size=(1, 1, 3)).astype(np.uint8)
segments_image[mask] = mask_color
return cv2.addWeighted(image.astype(np.float32), 0.7, segments_image.astype(np.float32), 0.3, 0.0)
import PIL
out = draw_anns(image, prediction)
cv2.imwrite("result.png", out[:, :, ::-1])
PIL.Image.open("result.png")
0%| | 0/48 [00:00<?, ?it/s]

NNCF トレーニング後の量子化 API を使用してエンコーダーを最適化¶
NNCF は、精度の低下を最小限に抑えながら、OpenVINO でニューラル・ネットワーク推論を最適化する一連の高度なアルゴリズムを提供します。
エンコーダーは SAM 推論パイプラインの他のパーツよりもはるかに多くの時間を費やすため、トレーニング後のモード (微調整パイプラインなし) で 8 ビット量子化により SAM のエンコーダを最適化します。
最適化プロセスには次の手順が含まれます。
量子化用のデータセットを作成します。
nncf.quantizeを実行して、最適化されたモデルを取得します。openvino.save_model関数を使用して、OpenVINO IR モデルをシリアル化します。
キャリブレーション・データセットを準備¶
COCO データセットをダウンロードします。データセットはモデルのパラメーターを微調整ではなく調整するために使用されるため、ラベルファイルをダウンロードする必要はありません。
from zipfile import ZipFile
DATA_URL = "https://ultralytics.com/assets/coco128.zip"
OUT_DIR = Path('.')
download_file(DATA_URL, directory=OUT_DIR, show_progress=True)
if not (OUT_DIR / "coco128/images/train2017").exists():
with ZipFile('coco128.zip' , "r") as zip_ref:
zip_ref.extractall(OUT_DIR)
'coco128.zip' already exists.
キャリブレーション・データセットを表す nncf.Dataset クラスのインスタンスを作成します。PyTorch の場合、torch.utils.data.DataLoader オブジェクトのインスタンスを渡すことができます。
import torch.utils.data as data
class COCOLoader(data.Dataset):
def __init__(self, images_path):
self.images = list(Path(images_path).iterdir())
def __getitem__(self, index):
image_path = self.images[index]
image = cv2.imread(str(image_path))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
return image
def __len__(self):
return len(self.images)
coco_dataset = COCOLoader(OUT_DIR / 'coco128/images/train2017')
calibration_loader = torch.utils.data.DataLoader(coco_dataset)
変換関数は、データセットからサンプルを取得し、推論のためにモデルに渡すことが可能なデータを返す関数です。
import nncf
def transform_fn(image_data):
"""
Quantization transform function. Extracts and preprocess input data from dataloader item for quantization.
Parameters:
image_data: image data produced by DataLoader during iteration
Returns:
input_tensor: input data in Dict format for model quantization
"""
image = image_data.numpy()
processed_image = preprocess_image(np.squeeze(image))
return processed_image
calibration_dataset = nncf.Dataset(calibration_loader, transform_fn)
INFO:nncf:NNCF initialized successfully. Supported frameworks detected: torch, tensorflow, onnx, openvino
量子化を実行し OpenVINO IR モデルをシリアル化¶
nncf.quantize 関数は、モデルの量子化のインターフェイスを提供します。OpenVINO モデルのインスタンスと量子化データセットが必要です。これは、PyTorch、TensorFlow 2.x、ONNX、および OpenVINO IR のフレームワークのモデルで利用できます。
オプションで、構成量子化プロセスの追加パラメーター (量子化のサンプル数、プリセット、モデルタイプなど) を指定できます。model_type を使用して、特定のタイプのモデルに必要な量子化スキームを指定できます。例えば、SAM などの Transformer モデルでは、量子化後に精度を維持するため特別な量子化スキームが必要です。さらに良い結果を得るため、混合量子化プリセットを使用します。これは、重みの対称量子化とアクティベーションの非対称量子化を提供します。
注: モデルのトレーニング後の量子化は時間のかかるプロセスです。ハードウェアによっては数分かかる場合があります。
model = core.read_model(ov_encoder_path)
quantized_model = nncf.quantize(model,
calibration_dataset,
model_type=nncf.parameters.ModelType.TRANSFORMER,
preset=nncf.common.quantization.structs.QuantizationPreset.MIXED, subset_size=128)
print("model quantization finished")
2023-09-11 20:39:36.145499: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0. 2023-09-11 20:39:36.181406: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags. 2023-09-11 20:39:36.769588: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT Statistics collection: 100%|██████████████████| 128/128 [02:12<00:00, 1.03s/it] Applying Smooth Quant: 100%|████████████████████| 48/48 [00:01<00:00, 32.29it/s]
INFO:nncf:36 ignored nodes was found by name in the NNCFGraph
Statistics collection: 100%|██████████████████| 128/128 [04:36<00:00, 2.16s/it]
Applying Fast Bias correction: 100%|████████████| 49/49 [00:28<00:00, 1.72it/s]
model quantization finished
ov_encoder_path_int8 = "sam_image_encoder_int8.xml"
ov.save_model(quantized_model, ov_encoder_path_int8)
量子化モデル推論の検証¶
前のコードを再利用して、INT8 モデルの出力を検証できます。
# Load INT8 model and run pipeline again
ov_encoder_model_int8 = core.read_model(ov_encoder_path_int8)
ov_encoder_int8 = core.compile_model(ov_encoder_model_int8, device.value)
encoding_results = ov_encoder_int8(preprocessed_image)
image_embeddings = encoding_results[ov_encoder_int8.output(0)]
input_point = np.array([[500, 375]])
input_label = np.array([1])
coord = np.concatenate([input_point, np.array([[0.0, 0.0]])], axis=0)[None, :, :]
label = np.concatenate([input_label, np.array([-1])], axis=0)[None, :].astype(np.float32)
coord = resizer.apply_coords(coord, image.shape[:2]).astype(np.float32)
inputs = {
"image_embeddings": image_embeddings,
"point_coords": coord,
"point_labels": label,
}
results = ov_predictor(inputs)
masks = results[ov_predictor.output(0)]
masks = postprocess_masks(masks, image.shape[:-1])
masks = masks > 0.0
plt.figure(figsize=(10,10))
plt.imshow(image)
show_mask(masks, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()

INT8 モデルを自動マスク生成モードで実行します
ov_encoder = ov_encoder_int8
prediction = automatic_mask_generation(image)
out = draw_anns(image, prediction)
cv2.imwrite("result_int8.png", out[:, :, ::-1])
PIL.Image.open("result_int8.png")
0%| | 0/47 [00:00<?, ?it/s]

元のモデルと量子化モデルのパフォーマンスを比較¶
最後に、OpenVINO Benchmark ツールを使用して、FP32 と INT8 モデルの推論パフォーマンスを測定します。
# Inference FP32 model (OpenVINO IR)
!benchmark_app -m $ov_encoder_path -d $device.value
[Step 1/11] Parsing and validating input arguments [ INFO ] Parsing input parameters [Step 2/11] Loading OpenVINO Runtime [ WARNING ] Default duration 120 seconds is used for unknown device AUTO [ INFO ] OpenVINO: [ INFO ] Build ................................. 2023.1.0-12050-e33de350633 [ INFO ] [ INFO ] Device info: [ INFO ] AUTO [ INFO ] Build ................................. 2023.1.0-12050-e33de350633 [ INFO ] [ INFO ] [Step 3/11] Setting device configuration [ WARNING ] Performance hint was not explicitly specified in command line. Device(AUTO) performance hint will be set to PerformanceMode.THROUGHPUT. [Step 4/11] Reading model files [ INFO ] Loading model files [ INFO ] Read model took 31.21 ms [ INFO ] Original model I/O parameters: [ INFO ] Model inputs: [ INFO ] x (node: x) : f32 / [...] / [1,3,1024,1024] [ INFO ] Model outputs: [ INFO ] *NO_NAME* (node: __module.neck.3/aten::add/Add_2933) : f32 / [...] / [1,256,64,64] [Step 5/11] Resizing model to match image sizes and given batch [ INFO ] Model batch size: 1 [Step 6/11] Configuring input of the model [ INFO ] Model inputs: [ INFO ] x (node: x) : u8 / [N,C,H,W] / [1,3,1024,1024] [ INFO ] Model outputs: [ INFO ] *NO_NAME* (node: __module.neck.3/aten::add/Add_2933) : f32 / [...] / [1,256,64,64] [Step 7/11] Loading the model to the device [ INFO ] Compile model took 956.62 ms [Step 8/11] Querying optimal runtime parameters [ INFO ] Model: [ INFO ] NETWORK_NAME: Model474 [ INFO ] EXECUTION_DEVICES: ['CPU'] [ INFO ] PERFORMANCE_HINT: PerformanceMode.THROUGHPUT [ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 12 [ INFO ] MULTI_DEVICE_PRIORITIES: CPU [ INFO ] CPU: [ INFO ] AFFINITY: Affinity.CORE [ INFO ] CPU_DENORMALS_OPTIMIZATION: False [ INFO ] CPU_SPARSE_WEIGHTS_DECOMPRESSION_RATE: 1.0 [ INFO ] ENABLE_CPU_PINNING: True [ INFO ] ENABLE_HYPER_THREADING: True [ INFO ] EXECUTION_DEVICES: ['CPU'] [ INFO ] EXECUTION_MODE_HINT: ExecutionMode.PERFORMANCE [ INFO ] INFERENCE_NUM_THREADS: 36 [ INFO ] INFERENCE_PRECISION_HINT: <Type: 'float32'> [ INFO ] NETWORK_NAME: Model474 [ INFO ] NUM_STREAMS: 12 [ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 12 [ INFO ] PERFORMANCE_HINT: PerformanceMode.THROUGHPUT [ INFO ] PERFORMANCE_HINT_NUM_REQUESTS: 0 [ INFO ] PERF_COUNT: False [ INFO ] SCHEDULING_CORE_TYPE: SchedulingCoreType.ANY_CORE [ INFO ] MODEL_PRIORITY: Priority.MEDIUM [ INFO ] LOADED_FROM_CACHE: False [Step 9/11] Creating infer requests and preparing input tensors [ WARNING ] No input files were given for input 'x'!. This input will be filled with random values! [ INFO ] Fill input 'x' with random values [Step 10/11] Measuring performance (Start inference asynchronously, 12 inference requests, limits: 120000 ms duration) [ INFO ] Benchmarking in inference only mode (inputs filling are not included in measurement loop). [ INFO ] First inference took 3347.39 ms [Step 11/11] Dumping statistics report [ INFO ] Execution Devices:['CPU'] [ INFO ] Count: 132 iterations [ INFO ] Duration: 135907.17 ms [ INFO ] Latency: [ INFO ] Median: 12159.63 ms [ INFO ] Average: 12098.43 ms [ INFO ] Min: 7652.77 ms [ INFO ] Max: 13027.98 ms [ INFO ] Throughput: 0.97 FPS
# Inference INT8 model (OpenVINO IR)
!benchmark_app -m $ov_encoder_path_int8 -d $device.value
[Step 1/11] Parsing and validating input arguments [ INFO ] Parsing input parameters [Step 2/11] Loading OpenVINO Runtime [ WARNING ] Default duration 120 seconds is used for unknown device AUTO [ INFO ] OpenVINO: [ INFO ] Build ................................. 2023.1.0-12050-e33de350633 [ INFO ] [ INFO ] Device info: [ INFO ] AUTO [ INFO ] Build ................................. 2023.1.0-12050-e33de350633 [ INFO ] [ INFO ] [Step 3/11] Setting device configuration [ WARNING ] Performance hint was not explicitly specified in command line. Device(AUTO) performance hint will be set to PerformanceMode.THROUGHPUT. [Step 4/11] Reading model files [ INFO ] Loading model files [ INFO ] Read model took 40.67 ms [ INFO ] Original model I/O parameters: [ INFO ] Model inputs: [ INFO ] x (node: x) : f32 / [...] / [1,3,1024,1024] [ INFO ] Model outputs: [ INFO ] *NO_NAME* (node: __module.neck.3/aten::add/Add_2933) : f32 / [...] / [1,256,64,64] [Step 5/11] Resizing model to match image sizes and given batch [ INFO ] Model batch size: 1 [Step 6/11] Configuring input of the model [ INFO ] Model inputs: [ INFO ] x (node: x) : u8 / [N,C,H,W] / [1,3,1024,1024] [ INFO ] Model outputs: [ INFO ] *NO_NAME* (node: __module.neck.3/aten::add/Add_2933) : f32 / [...] / [1,256,64,64] [Step 7/11] Loading the model to the device [ INFO ] Compile model took 1151.47 ms [Step 8/11] Querying optimal runtime parameters [ INFO ] Model: [ INFO ] NETWORK_NAME: Model474 [ INFO ] EXECUTION_DEVICES: ['CPU'] [ INFO ] PERFORMANCE_HINT: PerformanceMode.THROUGHPUT [ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 12 [ INFO ] MULTI_DEVICE_PRIORITIES: CPU [ INFO ] CPU: [ INFO ] AFFINITY: Affinity.CORE [ INFO ] CPU_DENORMALS_OPTIMIZATION: False [ INFO ] CPU_SPARSE_WEIGHTS_DECOMPRESSION_RATE: 1.0 [ INFO ] ENABLE_CPU_PINNING: True [ INFO ] ENABLE_HYPER_THREADING: True [ INFO ] EXECUTION_DEVICES: ['CPU'] [ INFO ] EXECUTION_MODE_HINT: ExecutionMode.PERFORMANCE [ INFO ] INFERENCE_NUM_THREADS: 36 [ INFO ] INFERENCE_PRECISION_HINT: <Type: 'float32'> [ INFO ] NETWORK_NAME: Model474 [ INFO ] NUM_STREAMS: 12 [ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 12 [ INFO ] PERFORMANCE_HINT: PerformanceMode.THROUGHPUT [ INFO ] PERFORMANCE_HINT_NUM_REQUESTS: 0 [ INFO ] PERF_COUNT: False [ INFO ] SCHEDULING_CORE_TYPE: SchedulingCoreType.ANY_CORE [ INFO ] MODEL_PRIORITY: Priority.MEDIUM [ INFO ] LOADED_FROM_CACHE: False [Step 9/11] Creating infer requests and preparing input tensors [ WARNING ] No input files were given for input 'x'!. This input will be filled with random values! [ INFO ] Fill input 'x' with random values [Step 10/11] Measuring performance (Start inference asynchronously, 12 inference requests, limits: 120000 ms duration) [ INFO ] Benchmarking in inference only mode (inputs filling are not included in measurement loop). [ INFO ] First inference took 1951.78 ms [Step 11/11] Dumping statistics report [ INFO ] Execution Devices:['CPU'] [ INFO ] Count: 216 iterations [ INFO ] Duration: 130123.96 ms [ INFO ] Latency: [ INFO ] Median: 7192.03 ms [ INFO ] Average: 7197.18 ms [ INFO ] Min: 6134.35 ms [ INFO ] Max: 7888.28 ms [ INFO ] Throughput: 1.66 FPS