セグメント化モデルを量子化してリアルタイムの推論を表示¶
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

PyTorch Lightning と OpenVINO™ による腎臓のセグメント化 - パート 3¶
このチュートリアルは、医療セグメント化モデルのトレーニング、最適化、量子化、リアルタイムの推論の表示方法に関するシリーズの一部です。目標は、腎臓のセグメント化モデルの推論を加速することです。UNet モデルはスクラッチからトレーニングされており、データは Kits19 から取得されています。
シリーズの 3 番目のチュートリアルでは、次の方法を説明します。
モデル変換 API を使用して元のモデルを OpenVINO IR に変換します。
NNCF を使用して PyTorch モデルを量子化します。
元のモデルと量子化されたモデルの F1 スコアメトリックを評価します。
FP32 モデルと INT8 量子化モデルのベンチマーク・パフォーマンスを測定します。
OpenVINO の非同期 API を使用したリアルタイムの推論を表示します。
このシリーズのすべてのノートブック。
セグメント化モデルを変換および量子化してリアルタイムの推論を表示 (このノートブック)
説明¶
このノートブックではトレーニングされた UNet モデルが必要です。完全な Kits-19 フレーム・データセットを使用して 20 エポックでトレーニングされた事前トレーニング済みモデルを提供します。このモデルの検証セットでの F1 スコアは 0.9 です。トレーニング・コードはこのノートブックで入手できます。
PyTorch モデルの NNCF には C++ コンパイラーが必要です。Windows* では、Microsoft Visual Studio* 2019 をインストールします。インストール中に、[ワークロード] タブで [C++ によるデスクトップ開発] を選択します。macOS* では、ターミナルから xcode-select –install を実行します。Linux* の場合は、gcc をインストールします。
完全なデータセットを使用してこのノートブックを実行すると、時間がかかります。デモでは、変換された CT スキャンを 1 つダウンロードし、そのスキャンを量子化と推論に使用します。運用では、モデルの定量化に代表的なデータセットを使用します。
目次¶
%pip install -q "openvino>=2023.1.0" "monai>=0.9.1,<1.0.0" "torchmetrics>=0.11.0" "nncf>=2.6.0" --extra-index-url https://download.pytorch.org/whl/cpu
Note: you may need to restart the kernel to use updated packages.
インポート¶
# On Windows, try to find the directory that contains x64 cl.exe and add it to the PATH to enable PyTorch
# to find the required C++ tools. This code assumes that Visual Studio is installed in the default
# directory. If you have a different C++ compiler, please add the correct path to os.environ["PATH"]
# directly. Note that the C++ Redistributable is not enough to run this notebook.
# Adding the path to os.environ["LIB"] is not always required - it depends on the system's configuration
import sys
if sys.platform == "win32":
import distutils.command.build_ext
import os
from pathlib import Path
if sys.getwindowsversion().build >= 20000: # Windows 11
search_path = "**/Hostx64/x64/cl.exe"
else:
search_path = "**/Hostx86/x64/cl.exe"
VS_INSTALL_DIR_2019 = r"C:/Program Files (x86)/Microsoft Visual Studio"
VS_INSTALL_DIR_2022 = r"C:/Program Files/Microsoft Visual Studio"
cl_paths_2019 = sorted(list(Path(VS_INSTALL_DIR_2019).glob(search_path)))
cl_paths_2022 = sorted(list(Path(VS_INSTALL_DIR_2022).glob(search_path)))
cl_paths = cl_paths_2019 + cl_paths_2022
if len(cl_paths) == 0:
raise ValueError(
"Cannot find Visual Studio. This notebook requires an x64 C++ compiler. If you installed "
"a C++ compiler, please add the directory that contains cl.exe to `os.environ['PATH']`."
)
else:
# If multiple versions of MSVC are installed, get the most recent version
cl_path = cl_paths[-1]
vs_dir = str(cl_path.parent)
os.environ["PATH"] += f"{os.pathsep}{vs_dir}"
# Code for finding the library dirs from
# https://stackoverflow.com/questions/47423246/get-pythons-lib-path
d = distutils.core.Distribution()
b = distutils.command.build_ext.build_ext(d)
b.finalize_options()
os.environ["LIB"] = os.pathsep.join(b.library_dirs)
print(f"Added {vs_dir} to PATH")
import logging
import os
import random
import sys
import time
import warnings
import zipfile
from pathlib import Path
from typing import Union
warnings.filterwarnings("ignore", category=UserWarning)
import cv2
import matplotlib.pyplot as plt
import monai
import numpy as np
import torch
import nncf
import openvino as ov
from monai.transforms import LoadImage
from nncf.common.logging.logger import set_log_level
from torchmetrics import F1Score as F1
set_log_level(logging.ERROR) # Disables all NNCF info and warning messages
from custom_segmentation import SegmentationModel
from async_pipeline import show_live_inference
sys.path.append("../utils")
from notebook_utils import download_file
2024-02-09 22:51:11.599112: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0. 2024-02-09 22:51:11.634091: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-02-09 22:51:12.223414: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
INFO:nncf:NNCF initialized successfully. Supported frameworks detected: torch, tensorflow, onnx, openvino
設定¶
デフォルトでは、このノートブックは量子化に使用される CT スキャンを KITS19 データセットからダウンロードします。完全なデータセットを使用するには、データ準備ノートブックで準備したように、BASEDIR をデータセットのパスに設定します。
BASEDIR = Path("kits19_frames_1")
# Uncomment the line below to use the full dataset, as prepared in the data preparation notebook
# BASEDIR = Path("~/kits19/kits19_frames").expanduser()
MODEL_DIR = Path("model")
MODEL_DIR.mkdir(exist_ok=True)
PyTorch モデルのロード¶
事前トレーニングされたモデルの重みをダウンロードし、PyTorch モデルとトレーニング後に保存された state_dict をロードします。このノートブックで使用されているモデルは、MONAI の BasicUNet モデルです。事前トレーニングされたチェックポイントを提供します。このモデルがどのように実行されるか確認するには、トレーニング・ノートブックを参照してください。
state_dict_url = "https://storage.openvinotoolkit.org/repositories/openvino_notebooks/models/kidney-segmentation-kits19/unet_kits19_state_dict.pth"
state_dict_file = download_file(state_dict_url, directory="pretrained_model")
state_dict = torch.load(state_dict_file, map_location=torch.device("cpu"))
new_state_dict = {}
for k, v in state_dict.items():
new_key = k.replace("_model.", "")
new_state_dict[new_key] = v
new_state_dict.pop("loss_function.pos_weight")
model = monai.networks.nets.BasicUNet(spatial_dims=2, in_channels=1, out_channels=1).eval()
model.load_state_dict(new_state_dict)
pretrained_model/unet_kits19_state_dict.pth: 0%| | 0.00/7.58M [00:00<?, ?B/s]
BasicUNet features: (32, 32, 64, 128, 256, 32).
<All keys matched successfully>
CT スキャンデータのダウンロード¶
# The CT scan case number. For example: 2 for data from the case_00002 directory
# Currently only 117 is supported
CASE = 117
if not (BASEDIR / f"case_{CASE:05d}").exists():
BASEDIR.mkdir(exist_ok=True)
filename = download_file(
f"https://storage.openvinotoolkit.org/data/test_data/openvino_notebooks/kits19/case_{CASE:05d}.zip"
)
with zipfile.ZipFile(filename, "r") as zip_ref:
zip_ref.extractall(path=BASEDIR)
os.remove(filename) # remove zipfile
print(f"Downloaded and extracted data for case_{CASE:05d}")
else:
print(f"Data for case_{CASE:05d} exists")
Data for case_00117 exists
構成¶
次のセルの KitsDataset クラスは、画像とマスクが患者ごとのフォルダー以下の ``basedir`` ディレクトリーにあると想定しています。これは、トレーニング・ノートブックの Dataset クラスの簡易バージョンです。
画像は、トレーニング・ノートブックの画像読み込み方法に合わせて、MONAI の LoadImage を使用して読み込まれます。このメソッドは画像を回転および反転します。画像を予想される向きで表示するため、rotate_and_flip メソッドを定義します。
def rotate_and_flip(image):
"""Rotate `image` by 90 degrees and flip horizontally"""
return cv2.flip(cv2.rotate(image, rotateCode=cv2.ROTATE_90_CLOCKWISE), flipCode=1)
class KitsDataset:
def __init__(self, basedir: str):
"""
Dataset class for prepared Kits19 data, for binary segmentation (background/kidney)
Source data should exist in basedir, in subdirectories case_00000 until case_00210,
with each subdirectory containing directories imaging_frames, with jpg images, and
segmentation_frames with segmentation masks as png files.
See https://github.com/openvinotoolkit/openvino_notebooks/blob/main/notebooks/110-ct-segmentation-quantize/data-preparation-ct-scan.ipynb
:param basedir: Directory that contains the prepared CT scans
"""
masks = sorted(BASEDIR.glob("case_*/segmentation_frames/*png"))
self.basedir = basedir
self.dataset = masks
print(
f"Created dataset with {len(self.dataset)} items. "
f"Base directory for data: {basedir}"
)
def __getitem__(self, index):
"""
Get an item from the dataset at the specified index.
:return: (image, segmentation_mask)
"""
mask_path = self.dataset[index]
image_path = str(mask_path.with_suffix(".jpg")).replace(
"segmentation_frames", "imaging_frames"
)
# Load images with MONAI's LoadImage to match data loading in training notebook
mask = LoadImage(image_only=True, dtype=np.uint8)(str(mask_path)).numpy()
img = LoadImage(image_only=True, dtype=np.float32)(str(image_path)).numpy()
if img.shape[:2] != (512, 512):
img = cv2.resize(img.astype(np.uint8), (512, 512)).astype(np.float32)
mask = cv2.resize(mask, (512, 512))
input_image = np.expand_dims(img, axis=0)
return input_image, mask
def __len__(self):
return len(self.dataset)
データローダーが予期した出力を返すかテストするため、イメージとマスクを表示します。画像とマスクは、サイズ変更と前処理の後、データローダーによって返されます。このデータセットには腎臓のないスライスが多数含まれているため、少なくとも 5000 の腎臓ピクセルを含むスライスを選択して、アノテーションが正しく見えることを確認します。
dataset = KitsDataset(BASEDIR)
# Find a slice that contains kidney annotations
# item[0] is the annotation: (id, annotation_data)
image_data, mask = next(item for item in dataset if np.count_nonzero(item[1]) > 5000)
# Remove extra image dimension and rotate and flip the image for visualization
image = rotate_and_flip(image_data.squeeze())
# The data loader returns annotations as (index, mask) and mask in shape (H,W)
mask = rotate_and_flip(mask)
fig, ax = plt.subplots(1, 2, figsize=(12, 6))
ax[0].imshow(image, cmap="gray")
ax[1].imshow(mask, cmap="gray");
Created dataset with 69 items. Base directory for data: kits19_frames_1
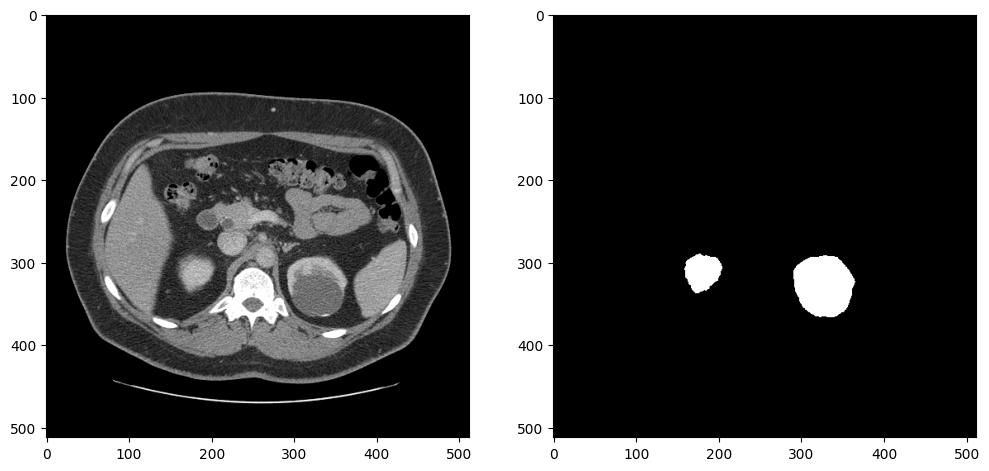
モデルのパフォーマンスを判断するメトリックを定義します。
このデモでは、TorchMetrics ライブラリーの F1 スコア、またはサイコロ係数を使用します。
def compute_f1(model: Union[torch.nn.Module, ov.CompiledModel], dataset: KitsDataset):
"""
Compute binary F1 score of `model` on `dataset`
F1 score metric is provided by the torchmetrics library
`model` is expected to be a binary segmentation model, images in the
dataset are expected in (N,C,H,W) format where N==C==1
"""
metric = F1(ignore_index=0, task="binary", average="macro")
with torch.no_grad():
for image, target in dataset:
input_image = torch.as_tensor(image).unsqueeze(0)
if isinstance(model, ov.CompiledModel):
output_layer = model.output(0)
output = model(input_image)[output_layer]
output = torch.from_numpy(output)
else:
output = model(input_image)
label = torch.as_tensor(target.squeeze()).long()
prediction = torch.sigmoid(output.squeeze()).round().long()
metric.update(label.flatten(), prediction.flatten())
return metric.compute()
量子化¶
モデルを定量化する前に、比較のため FP32 モデルの F1 スコアを計算します。
fp32_f1 = compute_f1(model, dataset)
print(f"FP32 F1: {fp32_f1:.3f}")
FP32 F1: 0.999
PyTorch モデルを OpenVINO IR に変換し、このノートブックの後半で FP32 モデルと INT8 モデルのパフォーマンスを比較するためシリアル化します。
fp32_ir_path = MODEL_DIR / Path('unet_kits19_fp32.xml')
fp32_ir_model = ov.convert_model(model, example_input=torch.ones(1, 1, 512, 512, dtype=torch.float32))
ov.save_model(fp32_ir_model, str(fp32_ir_path))
WARNING:tensorflow:Please fix your imports. Module tensorflow.python.training.tracking.base has been moved to tensorflow.python.trackable.base. The old module will be deleted in version 2.11.
[ WARNING ] Please fix your imports. Module %s has been moved to %s. The old module will be deleted in version %s.
No CUDA runtime is found, using CUDA_HOME='/usr/local/cuda'
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/monai/networks/nets/basic_unet.py:179: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if x_e.shape[-i - 1] != x_0.shape[-i - 1]:
NNCF は、精度の低下を最小限に抑えながら、OpenVINO でニューラル・ネットワーク推論を最適化する一連の高度なアルゴリズムを提供します。
注: NNCF トレーニング後の量子化は、OpenVINO 2023.0 リリースで利用可能です。
事前トレーニングされた FP32 モデルとキャリブレーション・データセットから量子化モデルを作成します。最適化プロセスには次の手順が含まれます。
1. Create a Dataset for quantization.
2. Run `nncf.quantize` for getting an optimized model.
3. Export the quantized model to ONNX and then convert to OpenVINO IR model.
4. Serialize the INT8 model using `ov.save_model` function for benchmarking.
def transform_fn(data_item):
"""
Extract the model's input from the data item.
The data item here is the data item that is returned from the data source per iteration.
This function should be passed when the data item cannot be used as model's input.
"""
images, _ = data_item
return images
data_loader = torch.utils.data.DataLoader(dataset)
calibration_dataset = nncf.Dataset(data_loader, transform_fn)
quantized_model = nncf.quantize(
model,
calibration_dataset,
# Do not quantize LeakyReLU activations to allow the INT8 model to run on Intel GPU
ignored_scope=nncf.IgnoredScope(patterns=[".*LeakyReLU.*"])
)
Output()
Output()
量子化モデルを ONNX にエクスポートし、OpenVINO IR モデルに変換して保存します。
dummy_input = torch.randn(1, 1, 512, 512)
int8_onnx_path = MODEL_DIR / "unet_kits19_int8.onnx"
int8_ir_path = Path(int8_onnx_path).with_suffix(".xml")
torch.onnx.export(quantized_model, dummy_input, int8_onnx_path)
int8_ir_model = ov.convert_model(int8_onnx_path)
ov.save_model(int8_ir_model, str(int8_ir_path))
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/nncf/torch/quantization/layers.py:334: TracerWarning: Converting a tensor to a Python number might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
return self._level_low.item()
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/nncf/torch/quantization/layers.py:342: TracerWarning: Converting a tensor to a Python number might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
return self._level_high.item()
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/monai/networks/nets/basic_unet.py:179: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if x_e.shape[-i - 1] != x_0.shape[-i - 1]:
このノートブックは、NNCF を使用したトレーニング後の量子化を示します。
NNCF は、量子化対応トレーニングや量子化以外のアルゴリズムもサポートしています。詳細については、NNCF リポジトリーの NNCF ドキュメントを参照してください。
FP32 モデルと INT8 モデルの比較¶
fp32_ir_model_size = fp32_ir_path.with_suffix(".bin").stat().st_size / 1024
quantized_model_size = int8_ir_path.with_suffix(".bin").stat().st_size / 1024
print(f"FP32 IR model size: {fp32_ir_model_size:.2f} KB")
print(f"INT8 model size: {quantized_model_size:.2f} KB")
FP32 IR model size: 3864.14 KB
INT8 model size: 1940.41 KB
core = ov.Core()
int8_compiled_model = core.compile_model(int8_ir_model)
int8_f1 = compute_f1(int8_compiled_model, dataset)
print(f"FP32 F1: {fp32_f1:.3f}")
print(f"INT8 F1: {int8_f1:.3f}")
FP32 F1: 0.999
INT8 F1: 0.999
FP32 モデルと INT8 モデルの推論パフォーマンスを測定するには、ベンチマーク・ツールを使用します。
- OpenVINOの推論性能測定ツール。ベンチマーク・ツールは、OpenVINO 開発ツールの一部であるコマンドライン・アプリケーションであり、! benchmark_app または %sx benchmark_app を使用してノートブックで実行できます。
注: 最も正確なパフォーマンス推定を行うには、他のアプリケーションを閉じた後、ターミナル/コマンドプロンプトで
benchmark_appを実行することを推奨します。benchmark_app -m model.xml -d CPUを実行して、CPU で非同期推論のベンチマークを 1 分間実行します。GPU でベンチマークを行うには、CPUをGPUに変更します。benchmark_app --helpを実行すると、すべてのコマンドライン・オプションが表示されます。
# ! benchmark_app --help
device = "CPU"
# Benchmark FP32 model
! benchmark_app -m $fp32_ir_path -d $device -t 15 -api sync
[Step 1/11] Parsing and validating input arguments
[ INFO ] Parsing input parameters
[Step 2/11] Loading OpenVINO Runtime
[ INFO ] OpenVINO:
[ INFO ] Build ................................. 2023.3.0-13775-ceeafaf64f3-releases/2023/3
[ INFO ]
[ INFO ] Device info:
[ INFO ] CPU [ INFO ] Build ................................. 2023.3.0-13775-ceeafaf64f3-releases/2023/3 [ INFO ] [ INFO ] [Step 3/11] Setting device configuration [ WARNING ] Performance hint was not explicitly specified in command line. Device(CPU) performance hint will be set to PerformanceMode.LATENCY. [Step 4/11] Reading model files [ INFO ] Loading model files [ INFO ] Read model took 26.51 ms [ INFO ] Original model I/O parameters: [ INFO ] Model inputs: [ INFO ] x (node: x) : f32 / [...] / [?,?,?,?] [ INFO ] Model outputs: [ INFO ] *NO_NAME* (node: __module.final_conv/aten::_convolution/Add) : f32 / [...] / [?,1,16..,16..] [Step 5/11] Resizing model to match image sizes and given batch [ INFO ] Model batch size: 1 [Step 6/11] Configuring input of the model [ INFO ] Model inputs: [ INFO ] x (node: x) : f32 / [...] / [?,?,?,?] [ INFO ] Model outputs: [ INFO ] *NO_NAME* (node: __module.final_conv/aten::_convolution/Add) : f32 / [...] / [?,1,16..,16..] [Step 7/11] Loading the model to the device
[ INFO ] Compile model took 87.61 ms
[Step 8/11] Querying optimal runtime parameters
[ INFO ] Model:
[ INFO ] NETWORK_NAME: Model0
[ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 1
[ INFO ] NUM_STREAMS: 1
[ INFO ] AFFINITY: Affinity.CORE
[ INFO ] INFERENCE_NUM_THREADS: 12
[ INFO ] PERF_COUNT: NO
[ INFO ] INFERENCE_PRECISION_HINT: <Type: 'float32'>
[ INFO ] PERFORMANCE_HINT: LATENCY
[ INFO ] EXECUTION_MODE_HINT: ExecutionMode.PERFORMANCE
[ INFO ] PERFORMANCE_HINT_NUM_REQUESTS: 0
[ INFO ] ENABLE_CPU_PINNING: True
[ INFO ] SCHEDULING_CORE_TYPE: SchedulingCoreType.ANY_CORE
[ INFO ] ENABLE_HYPER_THREADING: False
[ INFO ] EXECUTION_DEVICES: ['CPU']
[ INFO ] CPU_DENORMALS_OPTIMIZATION: False
[ INFO ] CPU_SPARSE_WEIGHTS_DECOMPRESSION_RATE: 1.0
[Step 9/11] Creating infer requests and preparing input tensors
[ ERROR ] Input x is dynamic. Provide data shapes!
Traceback (most recent call last):
File "/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/openvino/tools/benchmark/main.py", line 486, in main
data_queue = get_input_data(paths_to_input, app_inputs_info)
File "/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/openvino/tools/benchmark/utils/inputs_filling.py", line 123, in get_input_data
raise Exception(f"Input {info.name} is dynamic. Provide data shapes!")
Exception: Input x is dynamic. Provide data shapes!
# Benchmark INT8 model
! benchmark_app -m $int8_ir_path -d $device -t 15 -api sync
[Step 1/11] Parsing and validating input arguments
[ INFO ] Parsing input parameters
[Step 2/11] Loading OpenVINO Runtime
[ INFO ] OpenVINO:
[ INFO ] Build ................................. 2023.3.0-13775-ceeafaf64f3-releases/2023/3
[ INFO ]
[ INFO ] Device info:
[ INFO ] CPU
[ INFO ] Build ................................. 2023.3.0-13775-ceeafaf64f3-releases/2023/3
[ INFO ]
[ INFO ]
[Step 3/11] Setting device configuration
[ WARNING ] Performance hint was not explicitly specified in command line. Device(CPU) performance hint will be set to PerformanceMode.LATENCY.
[Step 4/11] Reading model files
[ INFO ] Loading model files
[ INFO ] Read model took 13.17 ms
[ INFO ] Original model I/O parameters:
[ INFO ] Model inputs:
[ INFO ] x.1 (node: x.1) : f32 / [...] / [1,1,512,512]
[ INFO ] Model outputs:
[ INFO ] 571 (node: 571) : f32 / [...] / [1,1,512,512]
[Step 5/11] Resizing model to match image sizes and given batch
[ INFO ] Model batch size: 1
[Step 6/11] Configuring input of the model
[ INFO ] Model inputs:
[ INFO ] x.1 (node: x.1) : f32 / [N,C,H,W] / [1,1,512,512]
[ INFO ] Model outputs:
[ INFO ] 571 (node: 571) : f32 / [...] / [1,1,512,512]
[Step 7/11] Loading the model to the device
[ INFO ] Compile model took 190.56 ms
[Step 8/11] Querying optimal runtime parameters
[ INFO ] Model:
[ INFO ] NETWORK_NAME: main_graph
[ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 1
[ INFO ] NUM_STREAMS: 1
[ INFO ] AFFINITY: Affinity.CORE
[ INFO ] INFERENCE_NUM_THREADS: 12
[ INFO ] PERF_COUNT: NO
[ INFO ] INFERENCE_PRECISION_HINT: <Type: 'float32'>
[ INFO ] PERFORMANCE_HINT: LATENCY
[ INFO ] EXECUTION_MODE_HINT: ExecutionMode.PERFORMANCE
[ INFO ] PERFORMANCE_HINT_NUM_REQUESTS: 0
[ INFO ] ENABLE_CPU_PINNING: True
[ INFO ] SCHEDULING_CORE_TYPE: SchedulingCoreType.ANY_CORE
[ INFO ] ENABLE_HYPER_THREADING: False
[ INFO ] EXECUTION_DEVICES: ['CPU']
[ INFO ] CPU_DENORMALS_OPTIMIZATION: False
[ INFO ] CPU_SPARSE_WEIGHTS_DECOMPRESSION_RATE: 1.0
[Step 9/11] Creating infer requests and preparing input tensors
[ WARNING ] No input files were given for input 'x.1'!. This input will be filled with random values!
[ INFO ] Fill input 'x.1' with random values
[Step 10/11] Measuring performance (Start inference synchronously, limits: 15000 ms duration)
[ INFO ] Benchmarking in inference only mode (inputs filling are not included in measurement loop).
[ INFO ] First inference took 30.25 ms
[Step 11/11] Dumping statistics report
[ INFO ] Execution Devices:['CPU']
[ INFO ] Count: 973 iterations
[ INFO ] Duration: 15006.05 ms
[ INFO ] Latency:
[ INFO ] Median: 15.16 ms
[ INFO ] Average: 15.22 ms
[ INFO ] Min: 14.87 ms
[ INFO ] Max: 17.88 ms
[ INFO ] Throughput: 64.84 FPS
検証セットの 4 つのスライスでモデルの結果を視覚化します。FP32 IR モデルの結果を、量子化された INT8 モデルおよびリファレンス・セグメント化アノテーションの結果と比較します。
医療画像データセットは不均衡になる傾向があります。CT スキャンのスライスのほとんどには腎臓データが含まれていません。セグメント化モデルは、腎臓が存在する場所で腎臓を見つけるのに優れている (医学用語: 感度が良い) 必要がありますが、存在しない偽の腎臓は見つけない (特異度が良い) 必要があります。次のセルには 4 つのスライスがあります。2 つのスライスには腎臓のデータがなく、2 つのスライスには腎臓のデータが含まれています。この例では、スライス内の少なくとも 50 ピクセルに腎臓としてアノテーションが付けられている場合、スライスに腎臓データがあります。
このセルを再度実行すると、別のサブセットの結果が表示されます。ランダムシードは、このセルの特定の実行を再現できるように表示されています。
注: 画像はオプションで拡大およびサイズ変更を行った後に表示されます。Kits19 データセットでは、1 つを除くすべてのケースの入力形状が
(512, 512)です。
# The sigmoid function is used to transform the result of the network
# to binary segmentation masks
def sigmoid(x):
return np.exp(-np.logaddexp(0, -x))
num_images = 4
colormap = "gray"
# Load FP32 and INT8 models
core = ov.Core()
fp_model = core.read_model(fp32_ir_path)
int8_model = core.read_model(int8_ir_path)
compiled_model_fp = core.compile_model(fp_model, device_name="CPU")
compiled_model_int8 = core.compile_model(int8_model, device_name="CPU")
output_layer_fp = compiled_model_fp.output(0)
output_layer_int8 = compiled_model_int8.output(0)
# Create subset of dataset
background_slices = (item for item in dataset if np.count_nonzero(item[1]) == 0)
kidney_slices = (item for item in dataset if np.count_nonzero(item[1]) > 50)
data_subset = random.sample(list(background_slices), 2) + random.sample(list(kidney_slices), 2)
# Set seed to current time. To reproduce specific results, copy the printed seed
# and manually set `seed` to that value.
seed = int(time.time())
random.seed(seed)
print(f"Visualizing results with seed {seed}")
fig, ax = plt.subplots(nrows=num_images, ncols=4, figsize=(24, num_images * 4))
for i, (image, mask) in enumerate(data_subset):
display_image = rotate_and_flip(image.squeeze())
target_mask = rotate_and_flip(mask).astype(np.uint8)
# Add batch dimension to image and do inference on FP and INT8 models
input_image = np.expand_dims(image, 0)
res_fp = compiled_model_fp([input_image])
res_int8 = compiled_model_int8([input_image])
# Process inference outputs and convert to binary segementation masks
result_mask_fp = sigmoid(res_fp[output_layer_fp]).squeeze().round().astype(np.uint8)
result_mask_int8 = sigmoid(res_int8[output_layer_int8]).squeeze().round().astype(np.uint8)
result_mask_fp = rotate_and_flip(result_mask_fp)
result_mask_int8 = rotate_and_flip(result_mask_int8)
# Display images, annotations, FP32 result and INT8 result
ax[i, 0].imshow(display_image, cmap=colormap)
ax[i, 1].imshow(target_mask, cmap=colormap)
ax[i, 2].imshow(result_mask_fp, cmap=colormap)
ax[i, 3].imshow(result_mask_int8, cmap=colormap)
ax[i, 2].set_title("Prediction on FP32 model")
ax[i, 3].set_title("Prediction on INT8 model")
Visualizing results with seed 1707515536

リアルタイムの推論を表示¶
ノートブック内のモデルに関するリアルタイムの推論を表示するには、OpenVINO の非同期処理機能を使用します。
Notebook Utils の show_live_inference 関数を使用してリアルタイムの推論を表示します。この関数は、Open Model Zoo の非同期パイプラインとモデル API を使用して、非同期推論を実行します。指定した CT スキャンの推論が完了すると、前処理と表示を含む合計時間とスループット (fps) が出力されます。
注: Firefox でちらつきが発生する場合は、Chrome または Edge を使用してこのノートブックを実行してください。
Open Model Zoo モデル API に基づいて、SegmentationModel を使用してセグメント化モデルを OpenVINO ランタイムにロードします。このモデルの実装には、モデルの前処理と後処理が含まれます。SegmentationModel の場合、これには元の画像/フレームにセグメント化マスクのオーバーレイを作成するコードが含まれます。
CASE = 117
segmentation_model = SegmentationModel(
ie=core, model_path=int8_ir_path, sigmoid=True, rotate_and_flip=True
)
case_path = BASEDIR / f"case_{CASE:05d}"
image_paths = sorted(case_path.glob("imaging_frames/*jpg"))
print(f"{case_path.name}, {len(image_paths)} images")
case_00117, 69 images
次のセルでは、show_live_inference 関数を実行します。この関数は、segmentation_model を指定されたデバイスにロードし (GPU デバイスでのモデルのロードを高速化するためのキャッシュを使用)、画像をロードして推論を実行し、実際の画像にロードされたフレームに結果をリアルタイムで表示します。
# Possible options for device include "CPU", "GPU", "AUTO", "MULTI:CPU,GPU"
device = "CPU"
reader = LoadImage(image_only=True, dtype=np.uint8)
show_live_inference(
ie=core, image_paths=image_paths, model=segmentation_model, device=device, reader=reader
)
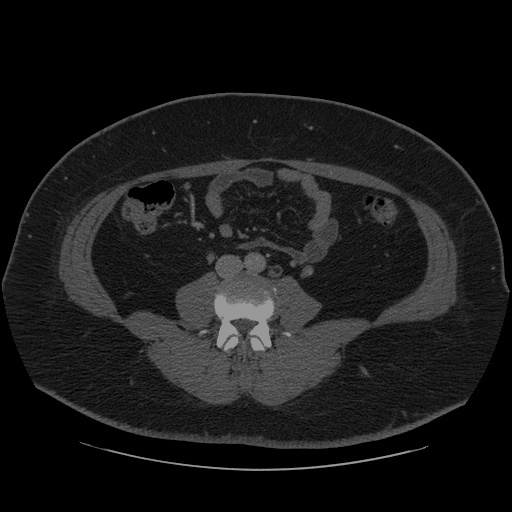
Loaded model to CPU in 0.18 seconds.
Total time for 68 frames: 2.68 seconds, fps:25.70