AddTransformation トランスフォーメーション#
ov::pass::low_precision::AddTransformation クラスは、Add 操作のトランスフォーメーションを表します。
この変換では、ある入力ブランチから別の入力ブランチに逆量子化減算が伝播され、加算操作を通じて同じブランチから逆量子化乗算が伝播されます。変換結果では、1 つの加算操作の入力ブランチは逆量子化演算なしで低精度になり (空のブランチ)、別の入力ブランチは更新された逆量子化演算のある元の精度になります (フルブランチ)。
空のブランチを優先順位に従って選択する基準:
ステップ 1.1 つのブランチのみが量子化されている場合、量子化されたブランチは空のブランチになります。
ステップ 2.逆量子化操作の前に 1 つのブランチのみが FakeQuantize を持つ場合、別のブランチは空のブランチになります。
ステップ 3.ある FakeQuantize に複数のコンシューマーがあり、別の FakeQuantize に 1 つしかコンシューマーがない場合、複数のコンシューマーを持つ FakeQuantize のブランチは空のブランチになります。
ステップ 4.定数ブランチは元の精度で、データブランチは空ブランチです。この場合、逆量子化操作は定数ブランチに伝播され、1 つの定数に融合されます。
ステップ 5.FakeQuantize の前に、両方のブランチに次の操作がある場合: Convolution、GroupConvolution、MatMul のいずれか、またはリストの操作がない場合、形状ボリュームが大きいブランチは空になります。
ステップ 6.FakeQuantize の前の操作でブランチに複数のコンシューマーがある場合、ブランチは空になります。
フルブランチの逆量子化オペレーションに FakeQuantize 操作の親がある場合、それらは別の低精度の変換中に FakeQuantize と融合されます。FakeQuantize 操作に次の親操作がある場合: Convolution、GroupConvolution、MatMul がある場合、推論中に親操作を使用して 1 つのプラグインカーネルで FakeQuantize を推論できます。
プラグイン命令セットに応じて、加算操作の低精度推論は、1 つのプラグインカーネル内の 2 つの論理ステップで実装できます:
推論ステップ #1: フルブランチの演算 (例えば、融合逆量子化演算を使用した Convolution と FakeQuantize、および Add) は、元の精度で推論できます。
推論ステップ #2: 推論ステップ #1 の結果は、空の分岐テンソルを低精度で追加できます。
このアプローチにより、最適な方法で加算操作を推論できます。
変換前のサブグラフ#
変換前の量子化された加算操作を含むサブグラフ:
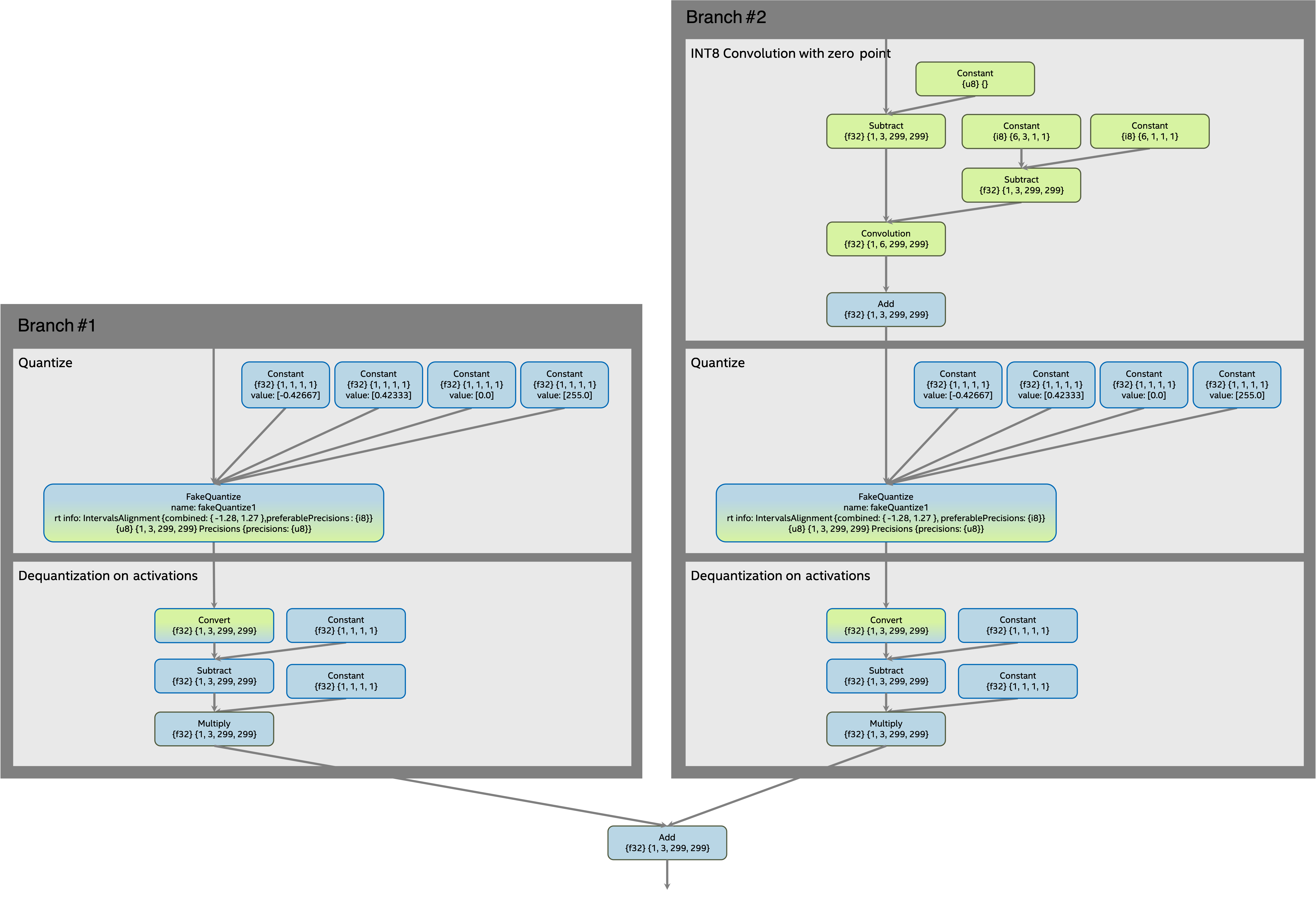
変換後のサブグラフ#
変換後の加算操作を含むサブグラフ:
説明: