量子化モデルの計算と制限#
OpenVINO の機能の 1 つは、さまざまな精度の量子化モデルのサポートです: INT8、INT4 など。ただし、特定の HW でサポートされる正確な精度を定義するのはプラグイン次第です。
実行時の FakeQuantize の解釈#
モデルのロード中に、各プラグインは FakeQuantize 操作で表現された量子化ルールを解釈できます:
FakeQuantize 操作の定義に基づいて独立して実行されます。
低精度変換 (LPT) 向けの特別なライブラリーを使用して、畳み込み、完全接続、Eltwise などの一般的な操作に共通ルールを適用し、“疑似量子化” モデルを低精度操作のモデルに変換します。
ここでは、FakeQuantize に対する解釈ルールの概要のみを提供します。実行時に、各 FakeQuantize は 量子化 と 逆量子化 の 2 つの独立した操作に分割できます。前者は入力データをターゲット精度に変換することを目的としており、後者は結果の値を元の範囲と精度に戻すことを目的としています。実際には、逆量子化操作は、畳み込みや完全接続などの線形操作を通じて前方に伝播することができ、場合によっては、次のレイヤーの量子化操作と融合して、いわゆる再量子化操作を行うことができます (図 1 を参照)。
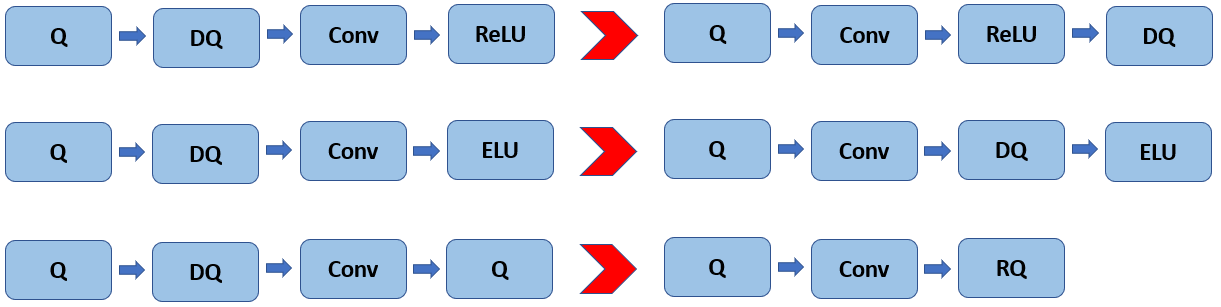
図 1. 実行時の量子化操作の伝播。Q、DQ、RQ は、それぞれ、量子化 (Quantize)、逆量子化 (Dequantize)、再量子化 (Requantize) を表します。
計算の観点から、FakeQuantize の式も 2 つの部分に分割されます:
output = round((x - input_low) / (input_high - input_low) * (levels-1)) / (levels-1) * (output_high - output_low) + output_low
この式の最初の部分は、量子化操作を表します:
q = round((x - input_low) / (input_high - input_low) * (levels-1))
2 番目は逆量子化を担当します:
r = q / (levels-1) * (output_high - output_low) + output_low
スケール/ゼロ点表記の観点から、後者の式は次のように書くことができます:
r = (output_high - output_low) / (levels-1) * (q + output_low / (output_high - output_low) * (levels-1))
したがって、次のように定義できます:
スケール は
(output_high - output_low) / (levels-1)ですゼロポイントは
-output_low / (output_high - output_low) * (levels-1)です
注
量子化プロセス中に、浮動小数点のゼロを整数値 (ゼロ点) に正確にマップしたり、その逆を行う、値 input_low、input_high、output_low、output_high が選択されます。
量子化の詳細と制限事項#
一般に、OpenVINO は、さまざまなソースからの量子化モデルを表現して実行できます。ただし、ニューラル・ネットワーク圧縮フレームワーク (NNCF) は、最適化されたモデルを取得するデフォルトの方法とみなされます。NNCF は HW 対応の量子化をサポートしているため、特定の HW に対して特定のルールを実装できることを意味します。ただし、CPU や GPU などの汎用 HW と互換性があり、その量子化方式をサポートするのは合理的です。これらのルールを次のように定義します:
一部のレイヤーを浮動小数点精度に維持できる混合精度モデルのサポート。
畳み込みレイヤーと全結合レイヤーの重みをチャネルごとに量子化します。
チャネルごと、および要素ごとの操作の活性化チャネルごとの量子化。例: Depthwise Convolution、Eltwise Add/Mul、ScaleShift など。
チャネルごとのスケールとゼロポイントのサポートによる、重みと活性化の対称および非対称の量子化。
Eltwise および Concat 操作の非統合量子化パラメーター。
量子化されていないネットワーク出力。つまり、量子化パラメーターがありません。