NNCF を使用した ImageBind モデルのトレーニング後の量子化¶
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

このチュートリアルは、NNCF (Neural Network Compression Framework) から 8 ビットのトレーニング後の量子化を適用してモデルを高速化し、OpenVINO™ ツールキットを介して量子化されたモデルを推論する方法を示します。
最適化プロセスには次の手順が含まれます。
- ノートブックから変換された OpenVINO モデルを NNCF で量子化します。
- 入力データの例について、変換されたモデルと量子化されたモデルの間で確率行列を比較します。
- 変換および量子化されたモデルのモデルサイズを比較します。
- 変換および量子化されたモデルのパフォーマンスを比較します。
注: 最初に 239-image-bind-convert ノートブックを実行して、量子化に使用される OpenVINO IR モデルを生成する必要があります。
目次¶
必要条件¶
%pip install -q datasets librosa soundfile "openvino>=2023.1.0" "nncf"
DEPRECATION: omegaconf 2.0.6 has a non-standard dependency specifier PyYAML>=5.1.*. pip 23.3 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of omegaconf or contact the author to suggest that they release a version with a conforming dependency specifiers. Discussion can be found at https://github.com/pypa/pip/issues/12063
DEPRECATION: pytorch-lightning 1.6.5 has a non-standard dependency specifier torch>=1.8.*. pip 23.3 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of pytorch-lightning or contact the author to suggest that they release a version with a conforming dependency specifiers. Discussion can be found at https://github.com/pypa/pip/issues/12063
[notice] A new release of pip is available: 23.2.1 -> 23.3.1
[notice] To update, run: pip install --upgrade pip
Note: you may need to restart the kernel to use updated packages.
from pathlib import Path
repo_dir = Path("ImageBind")
if not repo_dir.exists():
raise RuntimeError('This notebook should be run after 239-image-bind-convert notebook')
%cd {repo_dir}
/home/ea/work/openvino_notebooks/notebooks/239-image-bind/ImageBind
量子化の作成と初期化¶
NNCF は、モデルグラフに量子化レイヤーを追加し、トレーニング・データセットのサブセットを使用してこれらの追加の量子化レイヤーのパラメーターを初期化することで、トレーニング後の量子化を可能にします。このフレームワークは、元のトレーニング・コードへの変更が最小限になるように設計されています。量子化は最も単純なシナリオであり、いくつかの変更が必要です。
最適化プロセスには次の手順が含まれます。
- 量子化用のデータセットを作成します。
nncf.quantizeを実行して、量子化されたモデルを取得します。openvino.save_model関数を使用してINT8モデルをシリアル化します。
from pathlib import Path
from imagebind.models.imagebind_model import ModalityType
modalities = [ModalityType.TEXT, ModalityType.VISION, ModalityType.AUDIO]
fp_model_paths = {modality: Path(f"image-bind-{modality}") / f"image-bind-{modality}.xml" for modality in modalities}
int8_model_paths = {modality: Path(f"image-bind-{modality}") / f"image-bind-{modality}_int8.xml" for modality in modalities}
/home/ea/work/ov_venv/lib/python3.8/site-packages/torchvision/transforms/functional_tensor.py:5: UserWarning: The torchvision.transforms.functional_tensor module is deprecated in 0.15 and will be removed in 0.17. Please don't rely on it. You probably just need to use APIs in torchvision.transforms.functional or in torchvision.transforms.v2.functional. warnings.warn( /home/ea/work/ov_venv/lib/python3.8/site-packages/torchvision/transforms/_functional_video.py:6: UserWarning: The 'torchvision.transforms._functional_video' module is deprecated since 0.12 and will be removed in the future. Please use the 'torchvision.transforms.functional' module instead. warnings.warn( /home/ea/work/ov_venv/lib/python3.8/site-packages/torchvision/transforms/_transforms_video.py:22: UserWarning: The 'torchvision.transforms._transforms_video' module is deprecated since 0.12 and will be removed in the future. Please use the 'torchvision.transforms' module instead. warnings.warn(
データセットの準備¶
Conceptual Captions データセットは、キャプションの注釈が付けられた約 330 万枚の画像で構成されています。データセットは、画像およびテキストモデルを量子化するために使用されます。
import imagebind.data as data
import os
import requests
import tempfile
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
def check_text_data(data):
"""
Check if the given data is text-based.
"""
if isinstance(data, str):
return True
if isinstance(data, list):
return all(isinstance(x, str) for x in data)
return False
def collate_fn(examples, image_column="image_url", text_column="caption"):
"""
Collates examples into a batch for processing.
Preprocesses each example by loading and transforming image and text data.
Checks if the text data in the example is valid by calling the `check_text_data` function.
Downloads the image specified by the URL in the image_column of the example dictionary.
Constructs and returns a dictionary representing the collated batch with the following keys:
- "pixel_values": The pixel values of the preprocessed example.
- "input_ids": The transformed text data of the preprocessed example.
"""
assert len(examples) == 1
example = examples[0]
if not check_text_data(example[text_column]):
raise ValueError("Text data is not valid")
url = example[image_column]
with tempfile.TemporaryDirectory() as tempdir:
f_name = os.path.join(tempdir, 'image.jpg')
try:
response = requests.get(url, verify=False, timeout=20)
with open(f_name, "wb") as file:
file.write(response.content)
pixel_values = data.load_and_transform_vision_data([f_name], "cpu")
except Exception:
print(f"Can't load image from url: {url}")
return None
text = data.load_and_transform_text([example[text_column]], "cpu")
return {
"pixel_values": pixel_values,
"input_ids": text
}
from datasets import load_dataset
import itertools
import torch
from tqdm.notebook import tqdm
def collect_vision_text_data(dataloader, init_steps):
"""
This function collects vision and text data from a dataloader for a specified number of initialization steps.
It iterates over the dataloader, fetching batches and storing the relevant vision and text data.
Returns a tuple containing the collected vision_data and text_data lists.
"""
text_data = []
vision_data = []
print(f"Fetching {init_steps} for the initialization...")
counter = 0
for batch in tqdm(dataloader):
if counter == init_steps:
break
with torch.no_grad():
if batch:
counter += 1
text_data.append(batch["input_ids"].to("cpu"))
vision_data.append(batch["pixel_values"].to("cpu"))
return vision_data, text_data
def prepare_vision_text_dataset(opt_init_steps=300):
"""
Prepares a vision-text dataset for quantization by collecting vision and text data.
"""
dataset = load_dataset("conceptual_captions", streaming=True)
train_dataset = dataset["train"].shuffle(seed=0)
dataloader = torch.utils.data.DataLoader(train_dataset, collate_fn=collate_fn, batch_size=1)
vision_data, text_data = collect_vision_text_data(dataloader, opt_init_steps)
return vision_data, text_data
ESC-50 データセットは、ImageBind モデルのオーディオ・モダリティーを量子化するために使用されます。データセットは、環境音分類のベンチマーク方法に適した 2000 件の環境音声録音のラベル付きコレクションです。データセットは、50 のセマンティック・クラスに編成された 5 秒間の録音で構成されています。
import numpy as np
import torchaudio
def collect_audio_data(dataloader, init_steps=300):
"""
This function collects audio data from a dataloader for a specified number of initialization steps.
It iterates over the dataloader, fetching batches and storing them in a list.
"""
audio_data = []
for _, batch in tqdm(zip(range(init_steps), itertools.islice(dataloader, 0, init_steps))):
with torch.no_grad():
audio_data.append(batch)
return audio_data
def prepare_audio_dataset():
"""
Prepares an "ashraq/esc50" audio dataset for quantization by collecting audio data.
Collects audio data from the dataloader by calling the `collect_audio_data` function.
Returns a list containing the collected calibration audio data batches.
"""
audio_dataset = load_dataset("ashraq/esc50", streaming=True)
train_dataset = audio_dataset["train"].shuffle(seed=42, buffer_size=1000)
def collate_fn(examples):
assert len(examples) == 1
with tempfile.TemporaryDirectory() as tempdir:
f_name = os.path.join(tempdir, 'audio.wav')
audio_data = examples[0]['audio']['array']
sample_rate = examples[0]['audio']["sampling_rate"]
audio_data = torch.from_numpy(audio_data).to(torch.float32).unsqueeze(0)
torchaudio.save(f_name, audio_data, sample_rate)
return data.load_and_transform_audio_data([f_name], "cpu")
dataloader = torch.utils.data.DataLoader(train_dataset, collate_fn=collate_fn, batch_size=1)
calibration_data = collect_audio_data(dataloader)
return calibration_data
事前トレーニングされた FP16 モデルから量子化モデルを作成します。
vision_data, text_data = prepare_vision_text_dataset()
Fetching 300 for the initialization...
0it [00:00, ?it/s]
Can't load image from url: http://homeklondike.org/wp-content/uploads/2015/06/2-Bright-living-room-in-the-attic1.jpg
Can't load image from url: http://www.lovemeinitaly.com/wp-content/uploads/cache/images/2018/01/4A-e1491723576743/4A-e1491723576743-1964759082.jpg
Can't load image from url: https://i0.wp.com/childphotocompetition.com/wp-content/uploads/2016/02/Agnieszka_He%E2%80%8E_childphotocompetition.jpg
Can't load image from url: https://magankonoski.com/wp-content/uploads/2016/05/MaganKonoskiFineArtWeddingandLifestylePhotographer-25-683x1024.jpg
Can't load image from url: http://www.huahin-home-property.com/wp-content/uploads/2016/11/2immobilier-real-eatate-huahin-maison-a-vendre-condo-for-salerent-The-Autumm-Khao-takibe.jpg
Can't load image from url: http://www.americanclassichomes.com/blog/wp-content/uploads/2015/04/Alki_SB_Kitchen_internet.jpg
Can't load image from url: http://assets.nydailynews.com/polopoly_fs/1.110031.1313943805!/img/httpImage/image.jpg_gen/derivatives/article_750/alg-fencer-sara-harvey-browne-2-jpg.jpg
Can't load image from url: http://static.panoramio.com/photos/large/34107183.jpg
Can't load image from url: https://odis.homeaway.com/odis/listing/2f9f1d46-0559-4811-95ed-c97cc8608793.c10.jpg
Can't load image from url: https://odis.homeaway.com/odis/listing/75953842-3278-42a1-91ef-2bb2be2ecb05.c10.jpg
Can't load image from url: https://ak6.picdn.net/shutterstock/videos/2504486/thumb/1.jpg
Can't load image from url: http://www.buro247.my/thumb/625x960_0/galleries/2017/10/lady-dior-art-2-19.jpg
Can't load image from url: http://oneindiaonepeople.com/wp-content/uploads/2014/02/13.jpg
Can't load image from url: http://www.johnsoncitypress.com/image/2016/10/27/640x_cCM_q30/XC-Region-A-AA-JPG.jpg
Can't load image from url: http://fromthedeckchair.com/wp-content/uploads/2013/06/ftdc_norwegianpearl-0737.jpg
Can't load image from url: http://thedailyquotes.com/wp-content/uploads/2015/04/could-be-another-broken-heart-love-daily-quotes-sayings-pictures.jpg
Can't load image from url: https://www.popsci.com/sites/popsci.com/files/styles/1000_1x_/public/vizdata_map_key.jpg?itok=7myhqx2P
Can't load image from url: https://www.interlatesystems.com/img/1166/183.jpg
Can't load image from url: https://i1.wp.com/dailynexus.com/wp-content/uploads/2016/10/HalloweenWeekend_KennethSong-4-1024x671.jpg?resize=1024%2C671
Can't load image from url: https://odis.homeaway.com/odis/listing/d81ed29b-f448-444a-9048-ed9cc9fe666a.c10.jpg
Can't load image from url: http://exploresrilanka.lk/wp-content/uploads/2016/04/BTI37666.jpg
Can't load image from url: http://www.tampabay.com/storyimage/HI/20170528/ARTICLE/305289727/AR/0/AR-305289727.jpg
Can't load image from url: http://wewegombel.me/photo/558689/IMG_7994.jpg
Can't load image from url: http://www.thedonkeysanctuary.ie/sites/ireland/files/styles/large/public/press/259-1445414098.jpg?itok=dwa9kRh_
Can't load image from url: https://thumb1.shutterstock.com/display_pic_with_logo/3816881/478955293/stock-vector-abstract-pattern-in-the-memphis-style-of-large-white-spots-and-little-green-with-black-dots-on-a-478955293.jpg
Can't load image from url: http://media.santabanta.com/images/picsms/2016/sms-16401.jpg
Can't load image from url: https://lookaside.fbsbx.com/lookaside/crawler/media/?media_id=657209177718359
Can't load image from url: http://www.blogbeen.com/wp-content/uploads/2017/09/-mesmerizing-bathroom-tiles-11-jpg-bathroom-full-version-helulis-.jpg
Can't load image from url: https://6e58e2e225bb143c019e-e234a4d870c026b5f56b4446f6e62d64.ssl.cf1.rackcdn.com/a9ad7fa8-cf6c-4d2b-bbc6-591e0fd0cb2f.jpg
Can't load image from url: http://wewegombel.me/photo/487654/img_8173.jpg
Can't load image from url: http://s1.ibtimes.com/sites/www.ibtimes.com/files/styles/lg/public/2011/06/04/109074-an-african-giant-pouch-rat-is-watched-by-his-handler-at-a-laboratory-i.jpg
Can't load image from url: http://nnimgt-a.akamaihd.net/transform/v1/crop/frm/w9qsSAVumVxqyCiyw3G2iR/d9d78dda-7d5d-4420-9f3d-a1d44813c251.jpg/r0_64_960_604_w1200_h678_fmax.jpg
Can't load image from url: https://www.thenational.ae/image/policy:1.197226:1499310330/image/jpeg.jpg?f=16x9&w=1024&$p$f$w=2589da4
Can't load image from url: https://ak4.picdn.net/shutterstock/videos/14101994/thumb/1.jpg?i10c=img.resize(height:160)
Can't load image from url: http://sanpancholife.com/photos/home/2386/super/5005683111355530342.jpeg
Can't load image from url: https://media.gettyimages.com/photos/two-bottles-of-pills-one-knocked-over-with-contents-spilling-out-and-picture-id73740799?s=612x612
Can't load image from url: https://www.thestar.com/content/dam/thestar/entertainment/music/2017/04/17/prince-was-prescribed-oxycodone-under-another-name-court-document/prince-07.jpg.size.custom.crop.891x650.jpg
Can't load image from url: http://photos.mycapture.com/TWCM/1473481/41921058E.jpg
Can't load image from url: http://xboxhut.com/wp-content/uploads/2016/05/simple-bathroom-designs-grey-modern-double-sink-bathroom-vanities60-37.jpg
Can't load image from url: http://seanverret.com/wp-content/uploads/2012/07/20120710_104349.jpg
Can't load image from url: http://neveradulldayinpoland.com/wp-content/uploads/2014/04/DSC_3434-1024x682.jpg
Can't load image from url: http://wewegombel.me/photo/687156/watercolor-christmas-tree-isolated-white-background-texture-paper-new-year-christmas-card-template-62641882.jpg
Can't load image from url: http://expatedna.com/wp-content/uploads/2015/06/City-in-the-sky-by-Expat-Edna.jpg
Can't load image from url: https://lookaside.fbsbx.com/lookaside/crawler/media/?media_id=1291121264312721
Can't load image from url: https://i0.wp.com/cindi-keller.com/wp-content/uploads/2014/09/cindi-keller_2014-08-15_15.07.29_ronda-spain.jpg?w=400&h=533&crop&ssl=1
Can't load image from url: http://www.robinhoodshow.com/clients/17668/8642054_org.jpg
Can't load image from url: https://www.101india.com/sites/default/files/image-upload/blogs/TravelandFood/29NovSecretDevkundWaterfalls/Inline%204%20%3C%20Sunrise%20at%20the%20river%20behind%20the%20farmhouse%20%3E.jpg
Can't load image from url: http://www.nextavenue.org/wp-content/uploads/2017/05/image-3-w1024-750x485.jpg
Can't load image from url: http://nnimgt-a.akamaihd.net/transform/v1/crop/frm/342N54ExNnUCDyWzghgYbSC/cd538c73-466c-4e05-8202-0892dceb8a44.jpg/r401_321_5388_3369_w1200_h678_fmax.jpg
Can't load image from url: https://www.universetoday.com/wp-content/uploads/2016/05/Earth-magnetosphere-ESA-Medialab.jpg
Can't load image from url: https://c5eeb468edc90bcfda59-8477d1500ace5389b08f6bb1cc2fee82.ssl.cf5.rackcdn.com/837712-residential-x722qn-o.jpg
Can't load image from url: https://ak3.picdn.net/shutterstock/videos/7414963/thumb/1.jpg
import logging
import nncf
import openvino as ov
nncf.set_log_level(logging.ERROR)
core = ov.Core()
def quantize_openvino_model(modality, calibration_data):
model_path = fp_model_paths[modality]
if not os.path.exists(model_path):
raise RuntimeError(f"Model: {model_path} not found. \
First run 239-image-bind-convert notebook to convert model to OpenVINO IR.")
model = core.read_model(model_path)
quantized_model = nncf.quantize(
model=model,
calibration_dataset=calibration_data,
model_type=nncf.ModelType.TRANSFORMER,
# remove ignored_scope for nncf>=2.6.0 (PR with fix https://github.com/openvinotoolkit/nncf/pull/1953)
ignored_scope=nncf.IgnoredScope(types=["ReduceL2"])
)
ov.save_model(quantized_model, int8_model_paths[modality])
return quantized_model
INFO:nncf:NNCF initialized successfully. Supported frameworks detected: torch, tensorflow, onnx, openvino
視覚モダリティー用の ImageBind モデルを量子化します。
注: 量子化は時間とメモリーを消費する操作です。以下の量子化コードを実行すると、時間がかかる場合があります。
if len(vision_data) == 0:
raise RuntimeError(
'Calibration dataset is empty. Please check internet connection and try to download images manually from the URLs above.'
)
vision_dataset = nncf.Dataset(vision_data)
vision_quantized_model = quantize_openvino_model(modality=ModalityType.VISION, calibration_data=vision_dataset)
2023-10-26 13:34:25.166422: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0. 2023-10-26 13:34:25.203294: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags. 2023-10-26 13:34:26.097309: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT Statistics collection: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 300/300 [01:18<00:00, 3.81it/s] Applying Smooth Quant: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 129/129 [00:13<00:00, 9.69it/s] Statistics collection: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 300/300 [03:03<00:00, 1.64it/s] Applying Fast Bias correction: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 128/128 [00:23<00:00, 5.54it/s]
テキスト・モダリティー用の ImageBind モデルを量子化します。
text_dataset = nncf.Dataset(text_data)
text_quantized_model = quantize_openvino_model(modality=ModalityType.TEXT, calibration_data=text_dataset)
Statistics collection: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 300/300 [00:17<00:00, 16.82it/s]
Applying Smooth Quant: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 97/97 [00:06<00:00, 15.41it/s]
Statistics collection: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 300/300 [00:50<00:00, 5.97it/s]
Applying Fast Bias correction: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 120/120 [00:10<00:00, 11.06it/s]
オーディオ・モダリティー用の ImageBind モデルを量子化します。
audio_calibration_data = prepare_audio_dataset()
audio_dataset = nncf.Dataset(audio_calibration_data)
audio_quantized_model = quantize_openvino_model(modality=ModalityType.AUDIO, calibration_data=audio_dataset)
Repo card metadata block was not found. Setting CardData to empty.
0it [00:00, ?it/s]
Statistics collection: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 300/300 [01:10<00:00, 4.26it/s]
Applying Smooth Quant: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 49/49 [00:01<00:00, 27.79it/s]
Statistics collection: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 300/300 [01:21<00:00, 3.69it/s]
Applying Fast Bias correction: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48/48 [00:03<00:00, 12.18it/s]
NNCF は、量子化対応トレーニングや量子化以外のアルゴリズムもサポートしています。詳細については、NNCF リポジトリーの NNCF ドキュメントを参照してください。
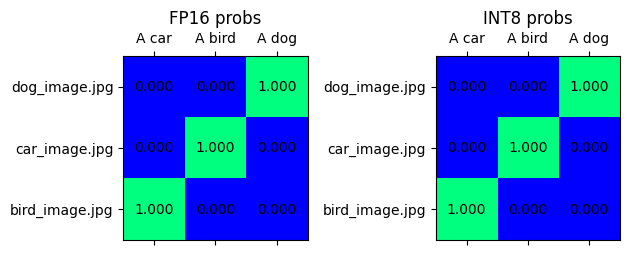
OpenVINO FP16 モデルと量子化モデルの結果を比較¶
FP16 と INT8 モデルの確率行列を比較します。確率行列の詳細については、ノートブックを参照してください。
# Prepare inputs
from imagebind.models.imagebind_model import ModalityType
text_list = ["A car", "A bird", "A dog"]
image_paths = [".assets/dog_image.jpg", ".assets/car_image.jpg", ".assets/bird_image.jpg"]
audio_paths = [".assets/dog_audio.wav", ".assets/bird_audio.wav", ".assets/car_audio.wav"]
inputs = {
ModalityType.TEXT: data.load_and_transform_text(text_list, "cpu"),
ModalityType.VISION: data.load_and_transform_vision_data(image_paths, "cpu"),
ModalityType.AUDIO: data.load_and_transform_audio_data(audio_paths, "cpu"),
}
推論デバイスの選択¶
OpenVINO を使用して推論を実行するためにドロップダウン・リストからデバイスを選択します。
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='AUTO',
description='Device:',
disabled=False,
)
device
Dropdown(description='Device:', index=2, options=('CPU', 'GPU', 'AUTO'), value='AUTO')
元のモデルの埋め込みを取得します。
embeddings = {}
for modality in modalities:
ov_model = core.compile_model(fp_model_paths[modality], device.value)
embeddings[modality] = ov_model(inputs[modality])[ov_model.output(0)]
量子化モデルの埋め込みを取得します。
quantized_embeddings = {}
for modality in modalities:
model = core.compile_model(int8_model_paths[modality], device.value)
quantized_embeddings[modality] = model(inputs[modality])[model.output(0)]
import matplotlib.pyplot as plt
from scipy.special import softmax
def visualize_prob_matrices(fp_matrix, int_matrix, x_label, y_label):
fig, ax = plt.subplots(1, 2)
for i, matrix in enumerate([fp_matrix, int_matrix]):
ax[i].matshow(matrix, cmap='winter')
for (k, j), z in np.ndenumerate(matrix):
ax[i].title.set_text('FP16 probs' if i == 0 else 'INT8 probs')
ax[i].text(j, k, '{:0.3f}'.format(z), ha='center', va='center')
ax[i].set_xticks(range(len(x_label)), x_label)
ax[i].set_yticks(range(len(y_label)), y_label)
fig.tight_layout()
image_list = [img.split('/')[-1] for img in image_paths]
audio_list = [audio.split('/')[-1] for audio in audio_paths]
fp_text_vision_scores = softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.TEXT].T, axis=-1)
int_text_vision_scores = softmax(quantized_embeddings[ModalityType.VISION] @ quantized_embeddings[ModalityType.TEXT].T, axis=-1)
visualize_prob_matrices(fp_text_vision_scores, int_text_vision_scores, text_list, image_list)

fp_text_audio_scores = softmax(embeddings[ModalityType.AUDIO] @ embeddings[ModalityType.TEXT].T, axis=-1)
int_text_audio_scores = softmax(quantized_embeddings[ModalityType.AUDIO] @ quantized_embeddings[ModalityType.TEXT].T, axis=-1)
visualize_prob_matrices(fp_text_audio_scores, int_text_audio_scores, text_list, image_list)
fp_audio_vision_scores = softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.AUDIO].T, axis=-1)
int_audio_vision_scores = softmax(quantized_embeddings[ModalityType.VISION] @ quantized_embeddings[ModalityType.AUDIO].T, axis=-1)
visualize_prob_matrices(fp_audio_vision_scores, int_audio_vision_scores, text_list, image_list)

ファイルサイズの比較¶
def calculate_compression_rate(modality):
fp16_ir_model_size = Path(fp_model_paths[modality]).with_suffix(".bin").stat().st_size / 1024
quantized_model_size = Path(int8_model_paths[modality]).with_suffix(".bin").stat().st_size / 1024
print(f'Modality: {modality}')
print(f" * FP16 IR model size: {fp16_ir_model_size:.2f} KB")
print(f" * INT8 model size: {quantized_model_size:.2f} KB")
print(f" * Model compression rate: {fp16_ir_model_size / quantized_model_size:.3f}")
for modality in modalities:
calculate_compression_rate(modality)
Modality: text
* FP16 IR model size: 691481.77 KB
* INT8 model size: 347007.35 KB
* Model compression rate: 1.993
Modality: vision
* FP16 IR model size: 1235995.26 KB
* INT8 model size: 620133.72 KB
* Model compression rate: 1.993
Modality: audio
* FP16 IR model size: 168429.22 KB
* INT8 model size: 84818.78 KB
* Model compression rate: 1.986
FP16 IR と量子化モデルの推論時間を比較¶
FP16 と INT8 モデルの推論パフォーマンスを測定するには、キャリブレーション・データセットの推論時間の中央値を使用します。したがって、動的量子化モデルの速度向上を見積もることができます。
注: 最も正確なパフォーマンス推定を行うには、他のアプリケーションを閉じた後、ターミナル/コマンドプロンプトで
benchmark_appを実行することを推奨します。
import time
def calculate_inference_time(model_path, calibration_data):
model = core.compile_model(model_path)
output_layer = model.output(0)
inference_time = []
for batch in calibration_data:
start = time.perf_counter()
_ = model(batch)[output_layer]
end = time.perf_counter()
delta = end - start
inference_time.append(delta)
return np.median(inference_time)
ビジョンモデル
fp16_latency = calculate_inference_time(fp_model_paths[ModalityType.VISION], vision_data)
int8_latency = calculate_inference_time(int8_model_paths[ModalityType.VISION], vision_data)
print(f"Performance speed up: {fp16_latency / int8_latency:.3f}")
Performance speed up: 2.040
テキストモデル
fp16_latency = calculate_inference_time(fp_model_paths[ModalityType.TEXT], text_data)
int8_latency = calculate_inference_time(int8_model_paths[ModalityType.TEXT], text_data)
print(f"Performance speed up: {fp16_latency / int8_latency:.3f}")
Performance speed up: 1.404
オーディオモデル
fp16_latency = calculate_inference_time(fp_model_paths[ModalityType.AUDIO], audio_calibration_data)
int8_latency = calculate_inference_time(int8_model_paths[ModalityType.AUDIO], audio_calibration_data)
print(f"Performance speed up: {fp16_latency / int8_latency:.3f}")
Performance speed up: 5.713