OpenVINO を使用して LLM によるチャットボットを作成¶
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

急速に進化する人工知能 (AI) の世界では、チャットボットが顧客との対話を強化し、業務を合理化するための強力なツールとして企業に登場しました。大規模言語モデル (LLM) は、人間の言語を理解して生成できる人工知能システムです。ディープラーニング・アルゴリズムと大量のデータを使用して言語のニュアンスを学習し、一貫性のある適切な応答を生成します。適切なインテントベースのチャットボットは注文管理、FAQ、ポリシーに関する質問などの基本的なワンタッチの質問に答えることができますが、LLM チャットボットはより複雑なマルチタッチの質問に対処できます。LLM を使用すると、チャットボットがコンテキスト記憶を通じて、人間と同様の会話形式でサポートを提供できるようになります。言語モデルの機能を活用することで、チャットボットはますますインテリジェントになり、驚くべき正確さで人間の言語を理解して応答できるようになりました。
以前、OpenVINO と Optimum Intel を使用して指示追従パイプラインを構築する方法について説明しました。参考までに Dolly の例を確認してください。このチュートリアルでは、チャット向けの大規模言語モデルを実行するため OpenVINO の機能を使用する方法を検討します。Hugging Face Transformers ライブラリーの事前トレーニング済みモデルを使用します。ユーザー・エクスペリエンスを簡素化するために、Hugging Face Optimum Intel ライブラリーを使用してモデルを OpenVINO™ IR 形式に変換します。
このチュートリアルは次のステップで構成されます。
前提条件をインストールします。
OpenVINO と Hugging Face Optimum の統合を使用して、パブリックソースからモデルをダウンロードして変換します。
NNCF を使用してモデルの重みを 4 ビットまたは 8 ビットのデータタイプに圧縮します。
チャット推論パイプラインを作成します。
チャット・パイプラインを実行します。
目次¶
必要条件¶
必要な依存関係をインストールします。
%pip uninstall -q -y openvino-dev openvino openvino-nightly optimum optimum-intel
%pip install -q --extra-index-url https://download.pytorch.org/whl/cpu\
"git+https://github.com/huggingface/optimum-intel.git"\
"nncf>=2.8.0"\
"datasets" \
"accelerate"\
"openvino-nightly"\
"gradio"\
"onnx" "einops" "transformers_stream_generator" "tiktoken" "transformers>=4.36.0"
推論用のモデルを選択¶
このチュートリアルではさまざまなモデルがサポートされており、提供されたオプションから 1 つを選択して、オープンソース LLM ソリューションの品質を比較できます。
注: 一部のモデルの変換には、ユーザーによる追加アクションが必要になる場合があり、変換には少なくとも 64GB RAM が必要です。
利用可能なオプションには以下があります。
-
tiny-llama-1b-chat - これは、TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T をベースに微調整されたチャットモデルです。TinyLlama プロジェクトは、Llama 2 と同じアーキテクチャーとトークナイザーを採用し、3 兆個のトークンで 11 億個の Llama モデルを事前トレーニングすることを目的としています。これは、TinyLlama を、Llama 上に構築された多くのオープンソース・プロジェクトにプラグインできることを意味します。さらに、TinyLlama はコンパクトで、パラメーターは 1.1B のみです。このコンパクトさにより、制限された計算量とメモリー使用量を要求する多くのアプリケーションに対応できます。モデルの詳細については、モデルカードをご覧ください。
-
red-pajama-3b-chat - GPT-NEOX アーキテクチャーに基づいた 2.8B パラメーターの事前トレーニング済み言語モデル。これは、Togetter Computer とオープンソース AI コミュニティーのリーダーによって開発されました。このモデルは、チャット機能を強化するため OASST1 および Dolly2 データセットに基づいて微調整されています。モデルの詳細については、Hugging Face モデルカードを参照してください。
-
llama-2-7b-chat - LLama 2 は、Meta によって開発された LLama モデルの第 2 世代です。Llama 2 は、事前トレーニングされ、微調整された生成テキストモデルのコレクションであり、その規模は 70 億から 700 億のパラメーターに及びます。 llama-2-7b-chat は、対話の使用例向けに微調整および最適化された LLama 2 の 70 億パラメーターのバージョンです。モデルの詳細については、論文、リポジトリーおよび Hugging Face モデルカードを参照してください。
注: デモでモデルを実行するには、ライセンス契約に同意する必要があります。Hugging Face Hub の登録ユーザーである必要があります。Hugging Face モデルカードにアクセスし、利用規約をよく読み、同意ボタンをクリックしてください。以下のコードを実行するには、アクセストークンを使用する必要があります。アクセストークンの詳細については、ドキュメントのこのセクションを参照してください。次のコードを使用して、ノートブック環境の Hugging Face Hub にログインできます。
## login to huggingfacehub to get access to pretrained model from huggingface_hub import notebook_login, whoami try: whoami() print('Authorization token already provided') except OSError: notebook_login()
mpt-7b-chat - MPT-7B は MosaicPretrainedTransformer (MPT) モデルファミリーの一部であり、効率的なトレーニングと推論のために最適化された修正されたトランスフォーマー・アーキテクチャーを使用します。これらのアーキテクチャー変更には、パフォーマンスが最適化されたレイヤーの実装と、位置埋め込みを線形バイアスによるアテンション (ALiBi) に置き換えることによるコンテキストの長さの制限の排除が含まれます。これらの変更により、MPT モデルは高いスループット効率と安定した収束でトレーニングできます。MPT-7B-chat は、対話生成のためのチャットボットのようなモデルです。これは、ShareGPT-Vicuna、HC3、Alpaca、HH-RLHF、 および Evol-Instruct データセット上で MPT-7B を微調整することによって構築されました。モデルの詳細については、ブログの投稿、リポジトリーおよび Hugging Face モデルカードを参照してください。
qwen-7b-chat - Qwen-7B は、Alibaba Cloud が提案する大規模言語モデルシリーズ Qwen (略称 Tongyi Qianwen) の 7B パラメーター・バ―ションです。Qwen-7B は、ウェブテキスト、書籍、コードなどを含む大量のデータで事前トレーニングされた Transformer ベースの大規模言語モデルです。Qwen の詳細については、GitHub コード・リポジトリーを参照してください。
chatglm3-6b - ChatGLM3-6B は、ChatGLM シリーズの最新のオープンソース・モデルです。hatGLM3-6B は、前の 2 世代のスムーズな対話や低い導入しきい値など多くの優れた機能を維持しながら、多様なトレーニング・データセット、十分なトレーニング・ステップ、合理的なトレーニング戦略を採用しています。ChatGLM3-6Bでは、通常のマルチターン・ダイアログに加え、新たに設計されたプロンプト形式を採用しています。モデルの詳細については、モデルカードを参照してください。
mistral-7b - Mistral-7B-v0.1 大規模言語モデル (LLM) は、70 億のパラメーターを備えた事前トレーニング済みの生成テキストモデルです。モデルの詳細については、モデルカード、論文およびリリースに関するブログの投稿を参照してください。
zephyr-7b-beta - Zephyr は、有用なアシスタントとして機能するように訓練された一連の言語モデルです。Zephyr-7B-beta はシリーズの 2 番目のモデルであり、直接優先最適化 (DPO) を使用して公開されている合成データセットの組み合わせでトレーニングされた、mistralai/Mistral-7B-v0.1 の微調整されたバージョンです。モデルの詳細については、技術レポートおよび Hugging Face モデルカードを参照してください。
neural-chat-7b-v3-1 - インテル Gaudi を使用して微調整された Mistral-7b モデル。モデルはオープンソース・データセット Open-Orca/SlimOrca に基づいて微調整され、直接優先最適化 (DPO) アルゴリズムに合わせて調整されています。詳細については、モデルカードとブログの投稿をご覧ください。
notus-7b-v1 - Notus は、直接優先最適化 (DPO) および関連する RLHF 技術を使用して微調整されたモデルのコレクションです。このモデルは、zephyr-7b-sft を DPO で微調整した最初のバージョンです。データファーストのアプローチに従って、Notus-7B-v1 と Zephyr-7B-beta の唯一の違いは、dDPO に使用される優先データセットです。データセットの作成に提案されたアプローチは、AlpacaEval 上の Zephyr-7B-beta や Claude 2 を超える Notus-7b を効果的に微調整するのに役立ちます。モデルの詳細については、モデルカードをご覧ください。
youri-7b-chat - Youri-7b-chat は Llama2 ベースのモデルです。Rinna Co., Ltd. は、日本語のタスク能力を向上させるために、英語と日本語のデータセットを混合した Llama2 モデルの事前トレーニングをさらに行いました。モデルは Hugging Face Hub で公開されています。詳しい情報は rinna/youri-7b-chat プロジェクトのページでご覧いただけます。
from config import SUPPORTED_LLM_MODELS
import ipywidgets as widgets
model_ids = list(SUPPORTED_LLM_MODELS)
model_id = widgets.Dropdown(
options=model_ids,
value=model_ids[0],
description="Model:",
disabled=False,
)
model_id
Dropdown(description='Model:', options=('tiny-llama-1b-chat', 'red-pajama-3b-chat', 'llama-2-chat-7b', 'mpt-7b…
model_configuration = SUPPORTED_LLM_MODELS[model_id.value]
print(f"Selected model {model_id.value}")
Selected model tiny-llama-1b-chat
Optimum Intel を使用してモデルをインスタンス化¶
Optimum Intel を使用すると、Hugging Face Hub から最適化されたモデルをロードし、Hugging Face API を使用して OpenVINO ランタイムで推論を実行するパイプラインを作成できます。Optimum 推論モデルは、Hugging Face Transformers モデルと API の互換性があります。つまり、AutoModelForXxx クラスを対応する OVModelForXxx クラスに置き換えるだけで済みます。
以下は RedPajama モデルの例です。
-from transformers import AutoModelForCausalLM
+from optimum.intel.openvino import OVModelForCausalLM
from transformers import AutoTokenizer, pipeline
model_id = "togethercomputer/RedPajama-INCITE-Chat-3B-v1"
-model = AutoModelForCausalLM.from_pretrained(model_id)
+model = OVModelForCausalLM.from_pretrained(model_id, export=True)
モデルクラスの初期化は、from_pretrained メソッドの呼び出しから始まります。Transformers モデルをダウンロードして変換する場合は、パラメーター export=True を追加する必要があります。save_pretrained メソッドを使用して、変換されたモデルを次回に使用するため保存できます。トークナイザー・クラスとパイプライン API は Optimum モデルと互換性があります。
生成プロセスを最適化し、メモリーをより効率的に使用するには、use_cache=True オプションを有効にします。出力側は自動回帰であるため、出力トークンの非表示状態は、その後の生成ステップごとに計算されると同じままになります。したがって、新しいトークンを生成するたびに再計算するのは無駄であるように思えます。キャッシュを使用すると、モデルは計算後に非表示の状態を保存します。モデルは各タイムステップで最後に生成された出力トークンのみを計算し、保存された出力トークンを非表示のトークンに再利用します。これにより、変圧器モデルの生成の複雑さが \(O(n^3)\) to \(O(n^2)\) に軽減されます。仕組みの詳細については、この記事を参照してください。このオプションを使用すると、モデルは前のステップの非表示状態 (キャッシュされたアテンション・キーと値) を入力として取得し、さらに現在のステップの非表示状態を出力として提供します。これは、次のすべての反復では、前のステップから取得した新しいトークンと、次のトークン予測を取得するためのキャッシュされたキー値のみを提供するだけで十分であることを意味します。
ここでは、MPT、Qwen、ChatGLM モデルは現在 Optimum Intel の対象になっていないため、手動で変換して Optimum Intel と互換性のあるラッパーを作成します。
from transformers import AutoModelForCausalLM, AutoConfig
from optimum.intel import OVQuantizer
from optimum.intel.openvino import OVModelForCausalLM
import openvino as ov
from pathlib import Path
import shutil
import torch
import logging
import nncf
import gc
from converter import converters
INFO:nncf:NNCF initialized successfully. Supported frameworks detected: torch, onnx, openvino
/home/ea/work/my_optimum_intel/optimum_env/lib/python3.8/site-packages/torch/cuda/__init__.py:138: UserWarning: CUDA initialization: The NVIDIA driver on your system is too old (found version 11080). Please update your GPU driver by downloading and installing a new version from the URL: http://www.nvidia.com/Download/index.aspx Alternatively, go to: https://pytorch.org to install a PyTorch version that has been compiled with your version of the CUDA driver. (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:108.)
return torch._C._cuda_getDeviceCount() > 0
No CUDA runtime is found, using CUDA_HOME='/usr/local/cuda'
モデルの重みを圧縮¶
重み圧縮アルゴリズムは、モデルの重みを圧縮することを目的としており、大規模言語モデル (LLM) など、重みのサイズがアクティベーションのサイズよりも相対的に大きい大規模モデルのモデル・フットプリントとパフォーマンスを最適化するために使用できます。INT8 圧縮と比較して、INT4 圧縮はパフォーマンスをさらに向上させますが、予測品質は若干低下します。
Optimum Intel を使用した重み圧縮¶
Optimum Intel の OVQuantizer クラスでサポートされるモデルの NNCF を介した重み圧縮を有効にするには、OVModelForCausalLM モデルに使用する必要があります。OVQuantizer.quantize(save_directory=save_dir, weights_only=True) 重みの圧縮を有効にします。RedPajama、LLAMA、Zephyr の例で行う方法を検討します。
注: 現在、Optimum Intel 適用を使用した重み圧縮は INT8 圧縮のみをサポートしています。以下で説明する NNCF API を使用して、これらのモデルに INT4 圧縮を適用します。
注: dGPU 上の INT4/INT8 圧縮モデルではスピードアップされない可能性があります。
NNCF を使用した重み圧縮¶
NNCF を直接使用して、OpenVINO モデルの重み圧縮を実行することもできます。nncf.compress_weights 関数は、OpenVINO モデル・インスタンスを受け入れ、線形レイヤーと埋め込みレイヤーの重みを圧縮します。MPT モデルに基づいてこのバリアントを検討します。
注: このチュートリアルには、FP16 および INT4/INT8 重み圧縮シナリオの変換モデルが含まれます。最初の実行ではメモリーを消費し時間がかかる可能性があります。以下で圧縮精度を手動で制御できます。
from IPython.display import display
prepare_int4_model = widgets.Checkbox(
value=True,
description="Prepare INT4 model",
disabled=False,
)
prepare_int8_model = widgets.Checkbox(
value=False,
description="Prepare INT8 model",
disabled=False,
)
prepare_fp16_model = widgets.Checkbox(
value=False,
description="Prepare FP16 model",
disabled=False,
)
display(prepare_int4_model)
display(prepare_int8_model)
display(prepare_fp16_model)
Checkbox(value=True, description='Prepare INT4 model')
Checkbox(value=False, description='Prepare INT8 model')
Checkbox(value=False, description='Prepare FP16 model')
浮動小数点と圧縮モデルのバリアントを保存できるようになりました。
nncf.set_log_level(logging.ERROR)
pt_model_id = model_configuration["model_id"]
pt_model_name = model_id.value.split("-")[0]
model_type = AutoConfig.from_pretrained(pt_model_id, trust_remote_code=True).model_type
fp16_model_dir = Path(model_id.value) / "FP16"
int8_model_dir = Path(model_id.value) / "INT8_compressed_weights"
int4_model_dir = Path(model_id.value) / "INT4_compressed_weights"
def convert_to_fp16():
if (fp16_model_dir / "openvino_model.xml").exists():
return
if not model_configuration["remote"]:
ov_model = OVModelForCausalLM.from_pretrained(
pt_model_id, export=True, compile=False, load_in_8bit=False
)
ov_model.half()
ov_model.save_pretrained(fp16_model_dir)
del ov_model
else:
model_kwargs = {}
if "revision" in model_configuration:
model_kwargs["revision"] = model_configuration["revision"]
model = AutoModelForCausalLM.from_pretrained(
model_configuration["model_id"],
torch_dtype=torch.float32,
trust_remote_code=True,
**model_kwargs
)
converters[pt_model_name](model, fp16_model_dir)
del model
gc.collect()
def convert_to_int8():
if (int8_model_dir / "openvino_model.xml").exists():
return
int8_model_dir.mkdir(parents=True, exist_ok=True)
if not model_configuration["remote"]:
if fp16_model_dir.exists():
ov_model = OVModelForCausalLM.from_pretrained(fp16_model_dir, compile=False)
else:
ov_model = OVModelForCausalLM.from_pretrained(
pt_model_id, export=True, compile=False, load_in_8bit=False
)
ov_model.half()
quantizer = OVQuantizer.from_pretrained(ov_model)
quantizer.quantize(save_directory=int8_model_dir, weights_only=True)
del quantizer
del ov_model
else:
convert_to_fp16()
ov_model = ov.Core().read_model(fp16_model_dir / "openvino_model.xml")
shutil.copy(fp16_model_dir / "config.json", int8_model_dir / "config.json")
configuration_file = fp16_model_dir / f"configuration_{model_type}.py"
if configuration_file.exists():
shutil.copy(
configuration_file, int8_model_dir / f"configuration_{model_type}.py"
)
compressed_model = nncf.compress_weights(ov_model)
ov.save_model(compressed_model, int8_model_dir / "openvino_model.xml")
del ov_model
del compressed_model
gc.collect()
def convert_to_int4():
compression_configs = {
"zephyr-7b-beta": {
"mode": nncf.CompressWeightsMode.INT4_SYM,
"group_size": 64,
"ratio": 0.6,
},
"mistral-7b": {
"mode": nncf.CompressWeightsMode.INT4_SYM,
"group_size": 64,
"ratio": 0.6,
},
"notus-7b-v1": {
"mode": nncf.CompressWeightsMode.INT4_SYM,
"group_size": 64,
"ratio": 0.6,
},
"neural-chat-7b-v3-1": {
"mode": nncf.CompressWeightsMode.INT4_SYM,
"group_size": 64,
"ratio": 0.6,
},
"llama-2-chat-7b": {
"mode": nncf.CompressWeightsMode.INT4_SYM,
"group_size": 128,
"ratio": 0.8,
},
"chatglm2-6b": {
"mode": nncf.CompressWeightsMode.INT4_SYM,
"group_size": 128,
"ratio": 0.72,
},
"qwen-7b-chat": {
"mode": nncf.CompressWeightsMode.INT4_SYM,
"group_size": 128,
"ratio": 0.6
},
'red-pajama-3b-chat': {
"mode": nncf.CompressWeightsMode.INT4_ASYM,
"group_size": 128,
"ratio": 0.5,
},
"default": {
"mode": nncf.CompressWeightsMode.INT4_ASYM,
"group_size": 128,
"ratio": 0.8,
},
}
model_compression_params = compression_configs.get(
model_id.value, compression_configs["default"]
)
if (int4_model_dir / "openvino_model.xml").exists():
return
int4_model_dir.mkdir(parents=True, exist_ok=True)
if not model_configuration["remote"]:
if not fp16_model_dir.exists():
model = OVModelForCausalLM.from_pretrained(
pt_model_id, export=True, compile=False, load_in_8bit=False
).half()
model.config.save_pretrained(int4_model_dir)
ov_model = model._original_model
del model
gc.collect()
else:
ov_model = ov.Core().read_model(fp16_model_dir / "openvino_model.xml")
shutil.copy(fp16_model_dir / "config.json", int4_model_dir / "config.json")
else:
convert_to_fp16()
ov_model = ov.Core().read_model(fp16_model_dir / "openvino_model.xml")
shutil.copy(fp16_model_dir / "config.json", int4_model_dir / "config.json")
configuration_file = fp16_model_dir / f"configuration_{model_type}.py"
if configuration_file.exists():
shutil.copy(
configuration_file, int4_model_dir / f"configuration_{model_type}.py"
)
compressed_model = nncf.compress_weights(ov_model, **model_compression_params)
ov.save_model(compressed_model, int4_model_dir / "openvino_model.xml")
del ov_model
del compressed_model
gc.collect()
if prepare_fp16_model.value:
convert_to_fp16()
if prepare_int8_model.value:
convert_to_int8()
if prepare_int4_model.value:
convert_to_int4()
さまざまな圧縮タイプのモデルサイズを比較してみましょう。
fp16_weights = fp16_model_dir / "openvino_model.bin"
int8_weights = int8_model_dir / "openvino_model.bin"
int4_weights = int4_model_dir / "openvino_model.bin"
if fp16_weights.exists():
print(f"Size of FP16 model is {fp16_weights.stat().st_size / 1024 / 1024:.2f} MB")
for precision, compressed_weights in zip([8, 4], [int8_weights, int4_weights]):
if compressed_weights.exists():
print(
f"Size of model with INT{precision} compressed weights is {compressed_weights.stat().st_size / 1024 / 1024:.2f} MB"
)
if compressed_weights.exists() and fp16_weights.exists():
print(
f"Compression rate for INT{precision} model: {fp16_weights.stat().st_size / compressed_weights.stat().st_size:.3f}"
)
Size of FP16 model is 2098.68 MB
Size of model with INT8 compressed weights is 1050.99 MB
Compression rate for INT8 model: 1.997
Size of model with INT4 compressed weights is 696.99 MB
Compression rate for INT4 model: 3.011
推論用のデバイスとモデルバリアントを選択¶
注: dGPU 上の INT4/INT8 圧縮モデルではスピードアップされない可能性があります。
core = ov.Core()
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value="CPU",
description="Device:",
disabled=False,
)
device
Dropdown(description='Device:', options=('CPU', 'GPU.0', 'GPU.1', 'AUTO'), value='CPU')
以下のセルは、OVModelForCausalLM モデルに基づいて OVMPTModel、OVQWENModel、および OVCHATGLM2Model ラッパーを作成します。
from ov_llm_model import model_classes
以下のセルは、モデルの重みと推論デバイスの選択されたバリアントに基づいてモデルをインスタンス化する方法を示しています。
available_models = []
if int4_model_dir.exists():
available_models.append("INT4")
if int8_model_dir.exists():
available_models.append("INT8")
if fp16_model_dir.exists():
available_models.append("FP16")
model_to_run = widgets.Dropdown(
options=available_models,
value=available_models[0],
description="Model to run:",
disabled=False,
)
model_to_run
Dropdown(description='Model to run:', options=('INT4', 'INT8', 'FP16'), value='INT4')
from transformers import AutoTokenizer
if model_to_run.value == "INT4":
model_dir = int4_model_dir
elif model_to_run.value == "INT8":
model_dir = int8_model_dir
else:
model_dir = fp16_model_dir
print(f"Loading model from {model_dir}")
ov_config = {"PERFORMANCE_HINT": "LATENCY", "NUM_STREAMS": "1", "CACHE_DIR": ""}
# On a GPU device a model is executed in FP16 precision. For red-pajama-3b-chat model there known accuracy
# issues caused by this, which we avoid by setting precision hint to "f32".
if model_id.value == "red-pajama-3b-chat" and "GPU" in core.available_devices and device.value in ["GPU", "AUTO"]:
ov_config["INFERENCE_PRECISION_HINT"] = "f32"
model_name = model_configuration["model_id"]
class_key = model_id.value.split("-")[0]
tok = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model_class = (
OVModelForCausalLM
if not model_configuration["remote"]
else model_classes[class_key]
)
ov_model = model_class.from_pretrained(
model_dir,
device=device.value,
ov_config=ov_config,
config=AutoConfig.from_pretrained(model_dir, trust_remote_code=True),
trust_remote_code=True,
)
Loading model from tiny-llama-1b-chat/INT4_compressed_weights
The argument trust_remote_code is to be used along with export=True. It will be ignored. Compiling the model to CPU ...
tokenizer_kwargs = model_configuration.get("tokenizer_kwargs", {})
test_string = "2 + 2 ="
input_tokens = tok(test_string, return_tensors="pt", **tokenizer_kwargs)
answer = ov_model.generate(**input_tokens, max_new_tokens=2)
print(tok.batch_decode(answer, skip_special_tokens=True)[0])
Setting pad_token_id to eos_token_id:2 for open-end generation.
2 + 2 = 4
チャットボットを実行¶
モデルが作成されたら、Gradio を使用してチャットボット・インターフェイスをセットアップできます。以下の図は、チャットボット・パイプラインがどのように機能するかを示しています。
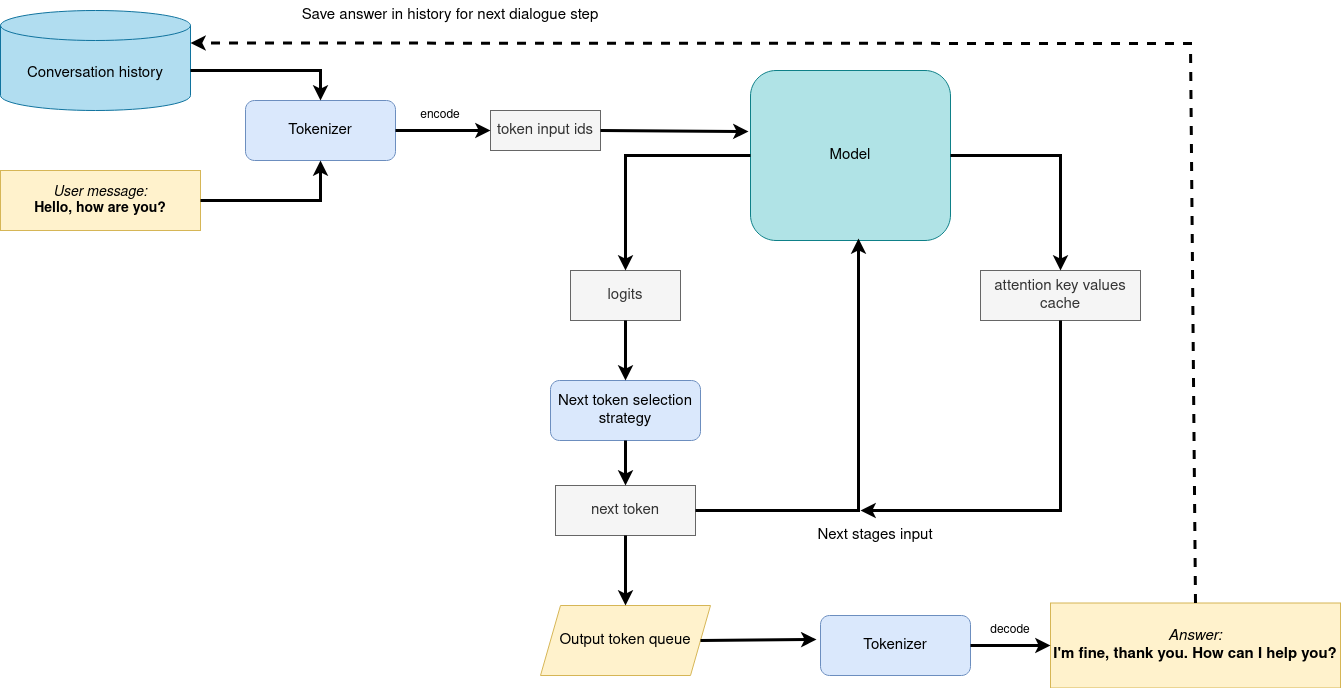
生成パイプライン¶
パイプラインは指示追従に非常によく似ていますが、より幅広い入力コンテキストを取得するために、以前の会話履歴が次のユーザーの質問で入力としてさらに渡されることが変更されただけです。最初の反復では、ユーザーが提供した指示が会話履歴 (存在する場合) に結合され、トークナイザーを使用してトークン ID に変換され、モデルに提供される準備入力が行われました。モデルは、すべてのトークンの確率をロジット形式で生成します。予測された確率に基づいて次のトークンが選択される方法は、選択されたデコード方法によって決まります。最も一般的なデコード方法の詳細については、このブログをご覧ください。結果の生成により、次の会話ステップの会話履歴が更新されます。 これにより、次の質問と以前に提供された質問との結びつきがより強くなり、以前に提供された回答について説明できるようになります。
テキスト生成の品質を制御できるパラメーターがいくつかあります。
-
テキスト生成の品質を制御できるいくつかのパラメーターがあります。
Temperatureは、AI が生成したテキストの創造性のレベルを制御するために使用されるパラメーターです。temperatureを調整することで、AI モデルの確率分布に影響を与え、テキストの焦点を絞ったり、多様にしたりできます。次の例を考えてみましょう。AI モデルは次のトークンの確率で “猫は ____ です” という文を完成させる必要があります。遊んでいる: 0.5眠っている: 0.25食べている: 0.15ドライブしている: 0.05飛んでいる: 0.05低温 (例: 0.2): AI モデルはより集中的かつ決定的になり、最も高い確率のトークン (“遊んでいる”など) を選択します。
中温 (例: 1.0): AI モデルは創造性と集中力のバランスを維持し、大きな偏りのない確率に基づいてトークン (“遊んでいる”、“眠っている”、“食べている”など) を選択します。
高温 (例: 2.0): AI モデルはより冒険的になり、確率の低いトークン (“ドライブしている” や “飛んでいる”など) を選択する可能性が高くなります。
-
Top-p(核サンプリングとも呼ばれる) は、累積確率に基づいて AI モデルによって考慮される、トークンの範囲を制御するために使用されるパラメーターです。top-p値を調整することで、AI モデルのトークン選択に影響を与え、焦点を絞ったり、多様性を持たせることができます。猫と同じ例を使用して、次の top_p 設定を検討してください。低 top_p (例: 0.5): AI モデルは、累積確率が最も高いトークン (“遊んでいる”など) のみを考慮します。
中 top_p (例: 0.8): AI モデルは、累積確率がより高いトークン (“遊んでいる”、“眠っている”、“食べている”など) を考慮します。
高 top_p (例: 1.0): I モデルは、確率の低いトークン (“ドライブしている” や “飛んでいる”) を含むすべてのトークンを考慮します。
Top-kは、人気のあるサンプリング戦略です。累積確率が確率 P を超える最小の単語のセットから選択する Top-p と比較して、Top-k サンプリングでは、確率の最も高い K 個の単語がフィルタリングされ、確率の集合が K 個の次の単語のみに再分配されます。猫の例では、k=3 の場合、“遊んでいる”、“眠っている”、および“食べている”だけが次の単語として考慮されます。-
Repetition Penaltyは、入力プロンプトを含むテキスト内でのトークンの出現頻度に基づいてトークンにペナルティーを与えるのに役立ちます。5 回出現したトークンは、1 回しか出現しなかったトークンよりも重いペナルティーが課されます。値 1 はペナルティーがないことを意味し、値が 1 より大きい場合、トークンの反復が妨げられます。
from threading import Event, Thread
from uuid import uuid4
from typing import List, Tuple
import gradio as gr
from transformers import (
AutoTokenizer,
StoppingCriteria,
StoppingCriteriaList,
TextIteratorStreamer,
)
model_name = model_configuration["model_id"]
start_message = model_configuration["start_message"]
history_template = model_configuration.get("history_template")
current_message_template = model_configuration.get("current_message_template")
stop_tokens = model_configuration.get("stop_tokens")
roles = model_configuration.get("roles")
tokenizer_kwargs = model_configuration.get("tokenizer_kwargs", {})
chinese_examples = [
["你好!"],
["你是谁?"],
["请介绍一下上海"],
["请介绍一下英特尔公司"],
["晚上睡不着怎么办?"],
["给我讲一个年轻人奋斗创业最终取得成功的故事。"],
["给这个故事起一个标题。"],
]
english_examples = [
["Hello there! How are you doing?"],
["What is OpenVINO?"],
["Who are you?"],
["Can you explain to me briefly what is Python programming language?"],
["Explain the plot of Cinderella in a sentence."],
["What are some common mistakes to avoid when writing code?"],
[
"Write a 100-word blog post on “Benefits of Artificial Intelligence and OpenVINO“"
],
]
japanese_examples = [
["こんにちは!調子はどうですか?"],
["OpenVINO とは何ですか?"],
["あなたは誰ですか?"],
["Python プログラミング言語とは何か簡単に説明してもらえますか?"],
["シンデレラのあらすじを一文で説明してください。"],
["コードを書くときに避けるべきよくある間違いは何ですか?"],
["人工知能と「OpenVINO の利点」について 100 語程度のブログ記事を書いてください。"],
]
examples = (
chinese_examples
if ("qwen" in model_id.value or "chatglm" in model_id.value)
else japanese_examples
if ("youri" in model_id.value)
else english_examples
)
max_new_tokens = 256
class StopOnTokens(StoppingCriteria):
def __init__(self, token_ids):
self.token_ids = token_ids
def __call__(
self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs
) -> bool:
for stop_id in self.token_ids:
if input_ids[0][-1] == stop_id:
return True
return False
if stop_tokens is not None:
if isinstance(stop_tokens[0], str):
stop_tokens = tok.convert_tokens_to_ids(stop_tokens)
stop_tokens = [StopOnTokens(stop_tokens)]
def default_partial_text_processor(partial_text: str, new_text: str):
"""
helper for updating partially generated answer, used by default
Params:
partial_text: text buffer for storing previosly generated text
new_text: text update for the current step
Returns:
updated text string
"""
partial_text += new_text
return partial_text
text_processor = model_configuration.get(
"partial_text_processor", default_partial_text_processor
)
def convert_history_to_token(history: List[Tuple[str, str]], roles=None):
"""
function for conversion history stored as list pairs of user and assistant messages to tokens according to model expected conversation template
Params:
history: dialogue history
Returns:
history in token format
"""
if roles is None:
text = start_message + "".join(
[
"".join(
[
history_template.format(
num=round, user=item[0], assistant=item[1]
)
]
)
for round, item in enumerate(history[:-1])
]
)
text += "".join(
[
"".join(
[
current_message_template.format(
num=len(history) + 1,
user=history[-1][0],
assistant=history[-1][1],
)
]
)
]
)
input_token = tok(text, return_tensors="pt", **tokenizer_kwargs).input_ids
else:
input_ids = []
input_ids.extend(tok.build_single_message(roles[0], "", start_message))
for old_query, response in history[:-1]:
input_ids.extend(tok.build_single_message(roles[1], "", old_query))
input_ids.extend(tok.build_single_message(roles[2], "", response))
input_ids.extend(tok.build_single_message(roles[1], "", history[-1][0]))
input_ids.extend([tok.get_command(f"<|{roles[2]}|>")])
input_token = tok.batch_encode_plus(
[input_ids], return_tensors="pt", is_split_into_words=True
).input_ids
return input_token
def user(message, history):
"""
callback function for updating user messages in interface on submit button click
Params:
message: current message
history: conversation history
Returns:
None
"""
# Append the user's message to the conversation history
return "", history + [[message, ""]]
def bot(history, temperature, top_p, top_k, repetition_penalty, conversation_id):
"""
callback function for running chatbot on submit button click
Params:
history: conversation history
temperature: parameter for control the level of creativity in AI-generated text.
By adjusting the `temperature`, you can influence the AI model's probability distribution, making the text more focused or diverse.
top_p: parameter for control the range of tokens considered by the AI model based on their cumulative probability.
top_k: parameter for control the range of tokens considered by the AI model based on their cumulative probability, selecting number of tokens with highest probability.
repetition_penalty: parameter for penalizing tokens based on how frequently they occur in the text.
conversation_id: unique conversation identifier.
"""
# Construct the input message string for the model by concatenating the current system message and conversation history
# Tokenize the messages string
input_ids = convert_history_to_token(history, roles)
if input_ids.shape[1] > 2000:
history = [history[-1]]
input_ids = convert_history_to_token(history, roles)
streamer = TextIteratorStreamer(
tok, timeout=30.0, skip_prompt=True, skip_special_tokens=True
)
generate_kwargs = dict(
input_ids=input_ids,
max_new_tokens=max_new_tokens,
temperature=temperature,
do_sample=temperature > 0.0,
top_p=top_p,
top_k=top_k,
repetition_penalty=repetition_penalty,
streamer=streamer,
)
if stop_tokens is not None:
generate_kwargs["stopping_criteria"] = StoppingCriteriaList(stop_tokens)
stream_complete = Event()
def generate_and_signal_complete():
"""
genration function for single thread
"""
global start_time
ov_model.generate(**generate_kwargs)
stream_complete.set()
t1 = Thread(target=generate_and_signal_complete)
t1.start()
# Initialize an empty string to store the generated text
partial_text = ""
for new_text in streamer:
partial_text = text_processor(partial_text, new_text)
history[-1][1] = partial_text
yield history
def get_uuid():
"""
universal unique identifier for thread
"""
return str(uuid4())
with gr.Blocks(
theme=gr.themes.Soft(),
css=".disclaimer {font-variant-caps: all-small-caps;}",
) as demo:
conversation_id = gr.State(get_uuid)
gr.Markdown(f"""<h1><center>OpenVINO {model_id.value} Chatbot</center></h1>""")
chatbot = gr.Chatbot(height=500)
with gr.Row():
with gr.Column():
msg = gr.Textbox(
label="Chat Message Box",
placeholder="Chat Message Box",
show_label=False,
container=False,
)
with gr.Column():
with gr.Row():
submit = gr.Button("Submit")
stop = gr.Button("Stop")
clear = gr.Button("Clear")
with gr.Row():
with gr.Accordion("Advanced Options:", open=False):
with gr.Row():
with gr.Column():
with gr.Row():
temperature = gr.Slider(
label="Temperature",
value=0.1,
minimum=0.0,
maximum=1.0,
step=0.1,
interactive=True,
info="Higher values produce more diverse outputs",
)
with gr.Column():
with gr.Row():
top_p = gr.Slider(
label="Top-p (nucleus sampling)",
value=1.0,
minimum=0.0,
maximum=1,
step=0.01,
interactive=True,
info=(
"Sample from the smallest possible set of tokens whose cumulative probability "
"exceeds top_p. Set to 1 to disable and sample from all tokens."
),
)
with gr.Column():
with gr.Row():
top_k = gr.Slider(
label="Top-k",
value=50,
minimum=0.0,
maximum=200,
step=1,
interactive=True,
info="Sample from a shortlist of top-k tokens — 0 to disable and sample from all tokens.",
)
with gr.Column():
with gr.Row():
repetition_penalty = gr.Slider(
label="Repetition Penalty",
value=1.1,
minimum=1.0,
maximum=2.0,
step=0.1,
interactive=True,
info="Penalize repetition — 1.0 to disable.",
)
gr.Examples(
examples, inputs=msg, label="Click on any example and press the 'Submit' button"
)
submit_event = msg.submit(
fn=user,
inputs=[msg, chatbot],
outputs=[msg, chatbot],
queue=False,
).then(
fn=bot,
inputs=[
chatbot,
temperature,
top_p,
top_k,
repetition_penalty,
conversation_id,
],
outputs=chatbot,
queue=True,
)
submit_click_event = submit.click(
fn=user,
inputs=[msg, chatbot],
outputs=[msg, chatbot],
queue=False,
).then(
fn=bot,
inputs=[
chatbot,
temperature,
top_p,
top_k,
repetition_penalty,
conversation_id,
],
outputs=chatbot,
queue=True,
)
stop.click(
fn=None,
inputs=None,
outputs=None,
cancels=[submit_event, submit_click_event],
queue=False,
)
clear.click(lambda: None, None, chatbot, queue=False)
demo.queue(max_size=2)
# if you are launching remotely, specify server_name and server_port
# demo.launch(server_name='your server name', server_port='server port in int')
# if you have any issue to launch on your platform, you can pass share=True to launch method:
# demo.launch(share=True)
# it creates a publicly shareable link for the interface. Read more in the docs: https://gradio.app/docs/
demo.launch()
# please run this cell for stopping gradio interface
demo.close()