有向非巡回グラフを使用した光学式文字認識#
ここでは、east-resnet50 テキスト検出モデルに基づく光学式文字認識 (OCR) パイプライン、テキスト認識とカスタムノード実装を組み合わせる方法と使用方法を説明します。
このようなパイプラインを使用すると、OVMS への 1 つの要求で複雑な操作を実行し、検出されたすべてのテキストボックスに対して認識された文字を含む応答を返すことができます。
OCR グラフ#
以下に、完全な OCR パイプラインを実装したグラフを示します。
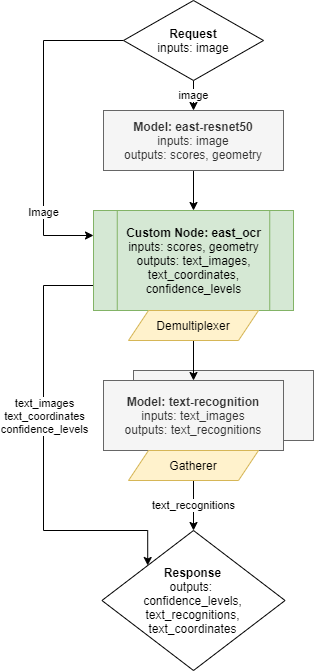
次のノードが含まれます:
モデル east-resnet50 - ユーザー画像を入力として受け取る推論実行。検出されたすべてのボックス、その位置、スコアに関する情報を含む 2 つの出力を返します。
カスタムノード east_ocr - east-resnet50 モデル結果処理の C++ 実装が含まれています。検出されたボックスの座標を分析し、設定可能なスコアレベルのしきい値に基づいて結果をフィルター処理し、非最大抑制アルゴリズムを適用して重複するボックスを削除します。最後に、カスタムノード east-ocr は、検出されたすべてのボックスを元の画像から切り取り、ターゲット解像度に合わせてサイズ変更し、動的なバッチサイズの単一の出力に結合します。出力バッチサイズは、設定された基準に従って検出されたボックス数によって決定されます。画像に対するすべての操作には、OVMS にプリインストールされている OpenCV ライブラリーが使用されます。詳細は、east_ocr カスタムノードを参照してください。
demultiplexer - カスタムノード east_ocr からの出力には可変のバッチサイズがあります。逐次テキスト検出モデルと一致させるため、データはバッチサイズ 1 の画像に分割されます。このような小さな要求は、次のモデルノードと並行して推論するために送信できます。demultiplexing についてさらに詳しく。
テキスト認識モデル - このモデルは入力画像に含まれる文字を認識します。
応答 - パイプライン全体の出力は、認識された
image_textsとそのメタデータを組み合わせます。メタデータは、text_coordinates出力とconfidence_level出力です。
モデルの準備#
East-resnet50 モデル#
east-resnet50 トポロジーの元の事前トレーニング済みモデルは、TensorFlow チェックポイント形式で https://github.com/argman/EAST に保存されています。
GitHub リポジトリーのクローンを作成:
git clone https://github.com/argman/EAST
cd EASTReadme.md ファイルの指示に従って、ファイル east_icdar2015_resnet_v1_50_rbox.zip を GitHub リポジトリーの EAST フォルダーにダウンロードして展開します。
unzip ./east_icdar2015_resnet_v1_50_rbox.zipコマンドラインから次の echo コマンドを実行して、EAST フォルダー内にファイル freeze_east_model.py を追加します:
echo "from tensorflow.python.framework import graph_util import tensorflow as tf
import model
def export_model(input_checkpoint, output_graph):
with tf.get_default_graph().as_default():
input_images = tf.placeholder(tf.float32, shape=[None, None, None, 3], name='input_images')
global_step = tf.get_variable('global_step', [], initializer=tf.constant_initializer(0), trainable=False)
f_score, f_geometry = model.model(input_images, is_training=False)
graph = tf.get_default_graph()
input_graph_def = graph.as_graph_def()
init_op = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init_op)
saver.restore(sess, input_checkpoint)
output_graph_def = graph_util.convert_variables_to_constants(sess=sess, input_graph_def=input_graph_def, output_node_names=['feature_fusion/concat_3','feature_fusion/Conv_7/Sigmoid'])
with tf.gfile.GFile(output_graph, 'wb') as f:
f.write(output_graph_def.SerializeToString())
export_model('./east_icdar2015_resnet_v1_50_rbox/model.ckpt-49491','./model.pb')" >>
freeze_east_model.py
cd ..モデルをチェックポイント形式でフリーズし、proto バッファー形式で model.pb に保存します:
docker run -u $(id -u):$(id -g) -v ${PWD}/EAST/:/EAST:rw -w /EAST tensorflow/tensorflow:1.15.5
python3 freeze_east_model.pymodel_optimizer ツールを使用して、フリーズされた TensorFlow のモデルを中間表現形式に変換します:
docker run -u $(id -u):$(id -g) -v ${PWD}/EAST/:/EAST:rw openvino/ubuntu20_dev:2022.1.0 mo \
--framework=tf --input_shape=[1,1024,1920,3] --input=input_images --output=feature_fusion/Conv_7/Sigmoid,feature_fusion/concat_3 \
--input_model /EAST/model.pb --output_dir /EAST/IR/1/${PWD}/EAST/IR/1/ フォルダーにモデルファイルが作成されます:
EAST/IR/1/
├── model.bin
├── model.mapping
└── model.xml変換された east-resnet50 モデルには、次のインターフェイスがあります:
入力名:
input_images、形状 -[1 1024 1920 3]; 精度:FP32、レイアウト:N...出力名:
feature_fusion/Conv_7/Sigmoid、形状 -[1 256 480 1]; 精度:FP32、レイアウト:N...出力名:
feature_fusion/concat_3、形状 -[1 256 480 5]; 精度:FP32、レイアウト:N...
テキスト認識モデル#
text-recognition モデルをダウンロードし、${PWD}/text-recognition/1 フォルダーに保存します。
curl -L --create-dir https://storage.openvinotoolkit.org/repositories/open_model_zoo/2022.1/models_bin/2/text-recognition-0014/FP32/text-recognition-0014.bin -o text-recognition/1/model.bin https://storage.openvinotoolkit.org/repositories/open_model_zoo/2022.1/models_bin/2/text-recognition-0014/FP32/text-recognition-0014.xml -o text-recognition/1/model.xml
chmod -R 755 text-recognition/text-recognition モデルには次のインターフェイスがあります:
入力名:
imgs、形状 -[1 1 32 128]; 精度:FP32、レイアウト:N...出力名:
logits、形状 -[16 1 37]; 精度:FP32
カスタムノード “east_ocr” ライブラリーのビルド#
カスタムノードは、custom_node_interface.h から OVMS API を実装する動的ライブラリーとして OVMS にロードされます。OVMS に含まれる OpenCV ライブラリーを使用することも、他のサードパーティー・コンポーネントを使用することもできます。
カスタムノード east_ocr は、次の手順で Docker コンテナ内に構築できます:
カスタムノードの例が含まれるディレクトリー src/custom_node に移動します
makeコマンドを実行:
git clone https://github.com/openvinotoolkit/model_server.git
cd model_server/src/custom_nodes
# UBI ベースイメージを使用する場合は 'redhat` に置き換えます
export BASE_OS=ubuntu
make NODES=east_ocr BASE_OS=${BASE_OS}
cd ../../../このコマンドは、コンパイルされたライブラリーを ./lib フォルダーにエクスポートします。この lib フォルダーを text-recognition と east_icdar2015_resnet_v1_50_rbox と同じ場所にコピーします。
mkdir -p OCR/east_fp32 OCR/lib
cp -R model_server/src/custom_nodes/lib/${BASE_OS}/libcustom_node_east_ocr.so OCR/lib/
cp -R text-recognition OCR/text-recognition
cp -R EAST/IR/1 OCR/east_fp32/1OVMS 設定ファイル#
OCR デモを実行するため構成ファイルは config.json に保存されています。以下に示すように、このファイルをモデルファイルおよびカスタム・ノード・ライブラリーとともにコピーします:
cp model_server/demos/optical_character_recognition/python/config.json OCROCR
├── config.json
├── east_fp32
│ └── 1
│ ├── model.bin
│ └── model.xml
├── lib
│ └── libcustom_node_east_ocr.so
└── text-recognition
└── 1
├── model.bin
└── model.xml注: 2022.1 以前に作成された east_fp32 モデルでは、config.json に追加のパラメーターが必要です:
layout: {"input_images": "NHWC:NCHW", "feature_fusion/Conv_7/Sigmoid": "NHWC:NCHW", "feature_fusion/concat_3": "NHWC:NCHW"}
OVMS のデプロイ#
次のコマンドを使用して、OCR デモ・パイプラインを使用して OVMS をデプロイします:
docker run -p 9000:9000 -d -v ${PWD}/OCR:/OCR openvino/model_server --config_path /OCR/config.json --port 9000サービスの要求#
optical_character_recognition ディレクトリーへ移動します
cd model_server/demos/optical_character_recognition/pythonPython の依存関係をインストールします:
pip3 install -r requirements.txtこれで、テキスト画像用のディレクトリーを作成し、クライアントを実行できるようになりました:
mkdir resultspython3 optical_character_recognition.py --grpc_port 9000 --image_input_path demo_images/input.jpg --pipeline_name detect_text_images --text_images_save_path ./results/ --image_layout NHWC
Output: name[confidence_levels]
numpy => shape[(9, 1, 1)] data[float32]
Output: name[texts]
numpy => shape[(9, 16, 1, 37)] data[float32]
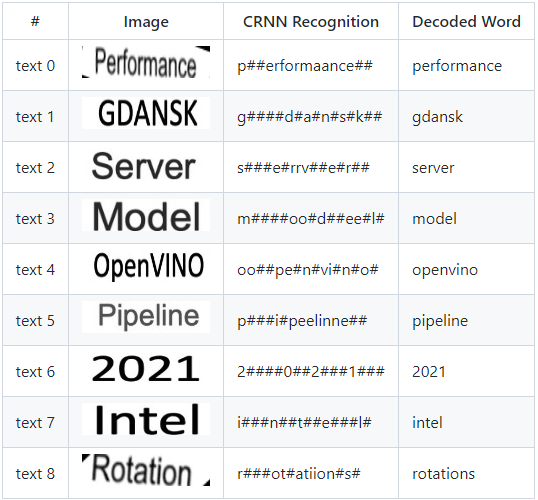
performance
gdansk
server
model
openvino
pipeline
2021
intel
rotations
Output: name[text_images]
numpy => shape[(9, 1, 32, 128, 1)] data[float32]
Output: name[text_coordinates]
numpy => shape[(9, 1, 4)] data[int32]追加パラメーター --text_images_save_path を使用すると、クライアント・スクリプトは、検出されたすべてのテキスト画像を jpeg ファイルとしてディレクトリー・パスに保存し、画像が正しく分析されたか確認します。
以下は入力画像の例です。

カスタムノードは、CRNN モデルへの元の入力から取得された次のテキストイメージを生成します:
精度#
DAG に含まれるモデルを独自のモデルと入れ替えして、さまざまなシナリオやデータセットに合わせてパイプラインの精度を調整できることに注意してください。