TensorFlow DeepSpeech モデルの変換¶
危険
ここで説明されているコードは非推奨になりました。従来のソリューションの適用を避けるため使用しないでください。下位互換性を確保するためにしばらく保持されますが、最新のアプリケーションでは使用してはなりません。
このガイドでは、非推奨となった変換方法について説明します。新しい推奨方法に関するガイドは、Python チュートリアルに記載されています。
DeepSpeech プロジェクトは、音声からテキストへモデルをトレーニングするエンジンを提供します。
事前トレーニング済み DeepSpeech モデルをダウンロード¶
事前トレーニングされた重みを含むモデルとメタグラフを保存するディレクトリーを作成します。
mkdir deepspeech
cd deepspeech
事前トレーニングされた英語音声テキスト変換モデルは公開されています。モデルをダウンロードするには、以下の手順に従ってください。
-
UNIX のようなシステムでは、次のコマンドを実行します。
wget -O - https://github.com/mozilla/DeepSpeech/archive/v0.8.2.tar.gz | tar xvfz - wget -O - https://github.com/mozilla/DeepSpeech/releases/download/v0.8.2/deepspeech-0.8.2-checkpoint.tar.gz | tar xvfz -
-
Windows* システム:
モデルを含むアーカイブをダウンロードします。
事前トレーニングされた重みを含む TensorFlow MetaGraph をダウンロードします。
ファイルのアーカイバー・アプリケーションを使用して展開します。
モデルを *.pb ファイルにフリーズ¶
上記のアーカイブを展開した後、モデルをフリーズする必要があります。これには TensorFlow バージョン 1 が必要ですが、Python 3.8 では利用できないため、Python 3.7 以下が必要です。フリーズする前に、仮想環境をデプロイし、必要なパッケージをインストールします。
virtualenv --python=python3.7 venv-deep-speech
source venv-deep-speech/bin/activate
cd DeepSpeech-0.8.2
pip3 install -e .
次のコマンドでモデルをフリーズします。
python3 DeepSpeech.py --checkpoint_dir ../deepspeech-0.8.2-checkpoint --export_dir ../
その後、最初に作成した deepspeech ディレクトリーに、事前学習済みのフリーズされたモデルファイル output_graph.pb が取得されます。モデルには前処理と主要部分が含まれます。最初の前処理は、入力スペクトログラムを音声認識 (メル) に役立つ形式に変換します。モデルのこの部分には、サポートされていない AudioSpectrogram と Mfcc 操作が含まれているため、IR に変換できません。
モデルの主要かつ最も計算コストのかかる部分は、前処理された音声をテキストに変換します。サポートされるモデルには 2 つの特徴があります。
1 つは、モデルにシーケンス長の入力が含まれていることです。そのため、モデルは固定入力長形状で変換できるため、モデルは再形成できません。形状推論の使用ガイドを参照してください。
2 つ目は、フリーズされたモデルには、previous_state_c と previous_state_h という 2 つの変数がまだあることです。フリーズされた *.pb モデルの図を以下に示します。これは、モデルが推論されるたびにこの変数をトレーニングし続けることを意味します。
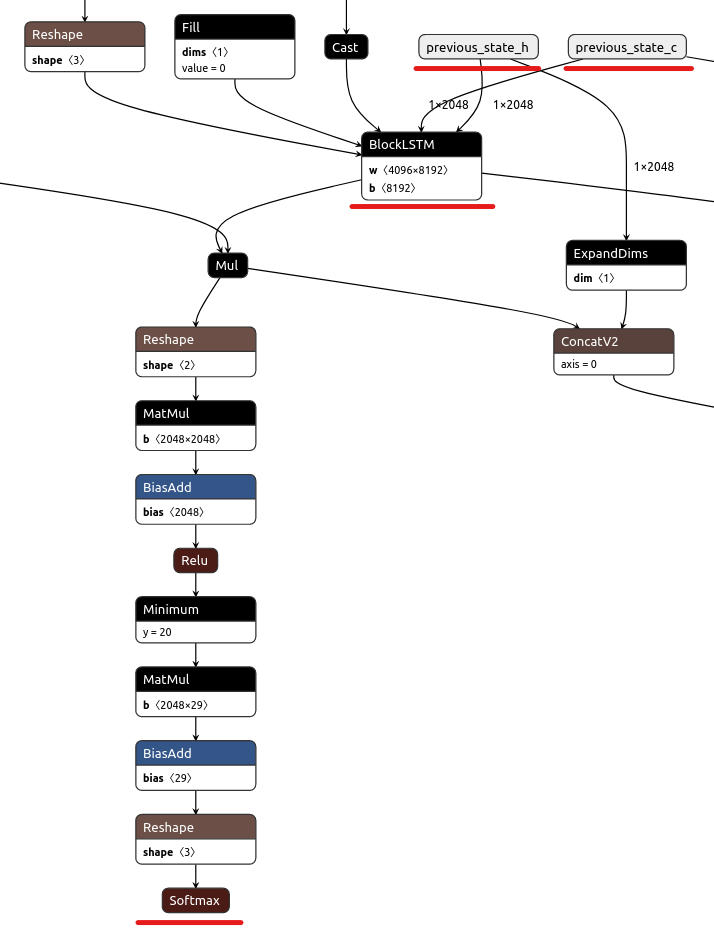
最初の推論で変数はゼロのテンソルで初期化されます。実行後、BlockLSTM の結果はセル状態と隠れ状態 (これら 2 つの変数) に割り当てられます。
DeepSpeech モデルの主要部分を OpenVINO IR に変換¶
モデル変換 API は、出力モデルが推論専用であることを前提としています。そのため、previous_state_c と previous_state_h 変数を削除し、セルと非表示の状態をアプリケーション・レベルで保持するのを解決する必要があります。
モデル変換には次のような制限があります。
時間長 (
time_len) とシーケンス長 (seq_len) は等しくなります。元のモデルは形状を変更できないため、元の形状を維持する必要があります。
IR を生成するには、次のパラメーターを使用してモデルを変換します。
mo \
--input_model output_graph.pb \
--input "input_lengths->[16],input_node[1,16,19,26],previous_state_h[1,2048],previous_state_c[1,2048]" \
--output "cudnn_lstm/rnn/multi_rnn_cell/cell_0/cudnn_compatible_lstm_cell/GatherNd_1,cudnn_lstm/rnn/multi_rnn_cell/cell_0/cudnn_compatible_lstm_cell/GatherNd,logits"
説明:
input_lengths->[16]は “input_lengths” という名前の入力ノードを、単一の整数値 16 を持つ形状 [1] の定数テンソルに置き換えます。これは、モデルが長さ 16 の入力シーケンスのみを使用できるということです。input_node[1 16 19 26],previous_state_h[1 2048],previous_state_c[1 2048]は変数をプレースホルダーに置き換えます。output ".../GatherNd_1,.../GatherNd,logits"は出力ノード名です。