formula-recognition-medium-scan-0001 (複合)#
ユースケースと概要説明#
これは、Latex 式を認識する im2latex 複合モデルです。このモデルは語彙ファイル vocab.json を使用して、Latex トークンのシーケンスを予測します。このモデルは、追加のアテンション・ベースのテキスト認識ヘッドを備えた ResNeXt-50 バックボーン上に構築されています。
語彙ファイルは、対応するモデル・ディレクトリー、<models_dir>/models/intel/formula-recognition-medium-scan-0001/formula-recognition-medium-scan-0001-im2latex-decoder/vocab.json にダウンロードされます。モデルは、大小文字、数字、一部のギリシャ文字、三角関数 (cos、sin、coth など)、対数関数、sqrt、および上付き文字を予測できます。
入力データの例#
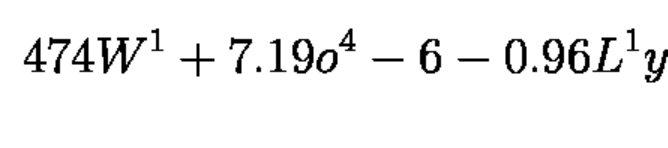
出力の例#
4 7 4 W ^ { 1 } + 7 . 1 9 o ^ { 4 } - 6 - 0 . 9 6 L ^ { 1 } y
複合モデル仕様#
メトリック |
値 |
|---|---|
im2latex_medium_photographed データセット、im2latex-match-images メトリック |
81.5% |
im2latex_medium_rendered データセット、im2latex-match-images メトリック |
95.7% |
ソース・フレームワーク |
PyTorch* |
Im2latex-match-images メトリックは <omz_dir>/tools/accuracy_checker/accuracy_checker/metrics/im2latex_images_match.py によって計算されます
エンコーダー・モデル仕様#
Formula-recognition-medium-scan-0001-encoder モデルは、デコーダー用の初期化レイヤーを備えた ResNeXt-50 に類似したバックボーンです。
メトリック |
値 |
|---|---|
GFlops |
16.56 |
MParams |
1.69 |
入力#
画像、名前: imgs、形状: 1, 3, 160, 1400、形式: 1, C, H, W、ここで:
C- チャネル数H- 画像の髙さW- 画像の幅
予想されるチャネルの順序は BGR です。
出力#
名前:
hidden、形状:1, 512。LSTM セルの初期コンテキスト状態。名前:
context、形状:1, 512。LSTM セルの初期の非表示状態。名前:
init_0、形状:1, 256。デコーダーの初期状態。名前:
row_enc_out、形状:1, 20, 75, 512。デコーダーに供給されるエンコーダーからの特徴。
デコーダーモデル仕様#
Formula-recognition-medium-scan-0001-decoder モデルは、アテンション・モジュールを備えた LSTM ベースのデコーダーです。
メトリック |
値 |
|---|---|
GFlops |
1.86 |
MParams |
2.56 |
入力#
名前:
dec_st_c、形状:1, 512。LSTM セルの現在のコンテキスト状態。名前:
dec_st_h、形状:1, 512。LSTM セルの現在の非表示状態。名前:
output_prev、形状:1, 256。デコーダーの現在の状態。名前:
row_enc_out、形状:1, 20, 175, 512。エンコードされた機能。名前:
tgt、形状:1, 1。前のシンボルのインデックス。
出力#
名前:
dec_st_c、形状:1, 512。LSTM セルの現在のコンテキスト状態。名前:
dec_st_h、形状:1, 512。LSTM セルの現在の非表示状態。名前:
output、形状:1, 256。デコーダーの現在の状態。名前:
logit、形状:1, Vocab_Size。すべてのトークンの分類信頼スコアは [0, 1] の範囲です。
デモの使い方#
このモデルは、Open Model Zoo が提供する次のデモで使用して、その機能を示します:
法務上の注意書き#
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。