PixArt-α: OpenVINO を使用したフォトリアリスティックなテキストから画像への合成の拡散トランスフォーマーの高速トレーニング#
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

この論文では、画像生成品質が最先端の画像ジェネレーターと競合し、商用アプリケーション標準に近いレベルに到達した、トランスフォーマー・ベースの T2I 拡散モデルである PIXART-α を紹介します。さらに、低いトレーニング・コストで最大 1024 ピクセルの高解像度画像合成をサポートします。この目標を達成するために、次の 3 つのコア設計が提案されています。
- トレーニング戦略の分解: ピクセル依存性、テキストと画像の配置、画像の美的品質を個別に最適化する 3 つの異なるトレーニング・ステップを考案しました。
- 効率良い T2I トランスフォーマー: クロスアテンション・モジュールを Diffusion Transformer (DiT) に組み込み、テキスト条件を挿入して計算集約型のクラス条件分岐を合理化します。
- 情報価値の高いデータ: テキストと画像のペアにおける概念密度の重要性を強調し、大規模な Vision-Language モデルを活用して、密な疑似キャプションに自動ラベルを付け、text-image の配置学習を支援します。

目次:
必要条件#
%pip install -q "diffusers>=0.14.0" sentencepiece "datasets>=2.14.6" "transformers>=4.25.1" "gradio>=4.19" "torch>=2.1" Pillow opencv-python --extra-index-url https://download.pytorch.org/whl/cpu
%pip install --pre -Uq openvino --extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightlyNote: you may need to restart the kernel to use updated packages.
エラー: pip の依存関係リゾルバーは現在、インストールされているすべてのパッケージを考慮していません。この動作が、次の依存関係の競合の原因です。openvino-dev 2024.2.0 には openvino==2024.2.0 が必要ですが、互換性のない openvino 2024.4.0.dev20240712 があります。
Note: you may need to restart the kernel to use updated packages.元のパイプラインをロードして実行#
LCM を利用する PixArt-LCM-XL-2-1024-MS を使用します。LCM は、PF-ODE's の解を潜在空間で直接予測し、少ないステップで超高速の推論を実現する拡散蒸留法です。
import torch
from diffusers import PixArtAlphaPipeline
pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", use_safetensors=True)
prompt = "A small cactus with a happy face in the Sahara desert."
generator = torch.Generator().manual_seed(42)
image = pipe(prompt, guidance_scale=0.0, num_inference_steps=4,
generator=generator).images[0]2024-07-13 01:36:32.634457: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on.You may see slightly different numerical results due to floating-point round-off errors from different computation orders.To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0. 2024-07-13 01:36:32.670663: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags. 2024-07-13 01:36:33.345290: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
Loading pipeline components...: 0%| | 0/5 [00:00<?, ?it/s]You are using the default legacy behaviour of the <class 'transformers.models.t5.tokenization_t5.T5Tokenizer'>. This is expected, and simply means that the legacy (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set legacy=False. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in huggingface/transformers#24565
Loading checkpoint shards: 0%| | 0/4 [00:00<?, ?it/s]Some weights of the model checkpoint were not used when initializing PixArtTransformer2DModel: ['caption_projection.y_embedding']
The installed version of bitsandbytes was compiled without GPU support. 8-bit optimizers, 8-bit multiplication, and GPU quantization are unavailable.0%| | 0/4 [00:00<?, ?it/s]image
モデルを OpenVINO IR に変換#
PyTorch モジュールの変換関数を定義します。ov.convert_model 関数を使用して OpenVINO 中間表現オブジェクトを取得し、ov.save_model 関数でそれを XML ファイルとして保存します。
from pathlib import Path
import numpy as np
import torch
import openvino as ov
def convert(model: torch.nn.Module, xml_path: str, example_input):
xml_path = Path(xml_path)
if not xml_path.exists():
xml_path.parent.mkdir(parents=True, exist_ok=True)
model.eval()
with torch.no_grad():
converted_model = ov.convert_model(model, example_input=example_input) ov.save_model(converted_model, xml_path)
# メモリーをクリーンアップ
torch._C._jit_clear_class_registry()
torch.jit._recursive.concrete_type_store = torch.jit._recursive.ConcreteTypeStore()
torch.jit._state._clear_class_state()PixArt-α は、潜在拡散用の純粋なトランスフォーマー・ブロックで構成されています: 単一のサンプリング・プロセス内でテキストプロンプトから 1024 ピクセルの画像を直接生成できます。
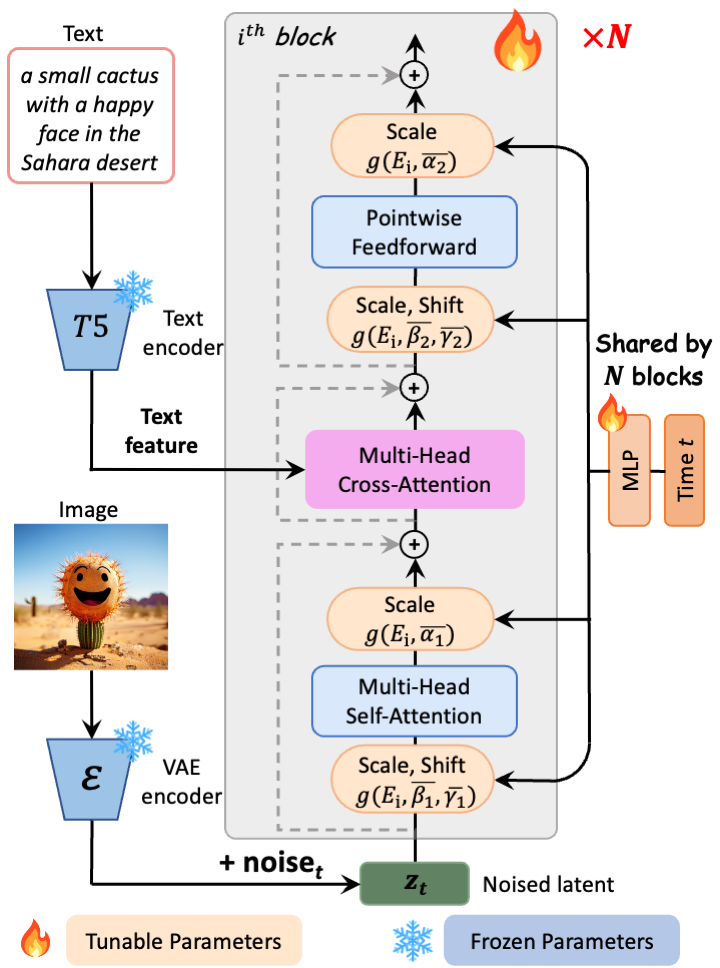 .
.
推論中は、テキスト・エンコーダー T5EncoderModel、トランスフォーマー Transformer2DModel、VAE デコーダー AutoencoderKL が使用されます。パイプラインからモデルを 1 つずつ変換します。
MODEL_DIR = Path("model")
TEXT_ENCODER_PATH = MODEL_DIR / "text_encoder.xml"
TRANSFORMER_OV_PATH = MODEL_DIR / "transformer_ir.xml"
VAE_DECODER_PATH = MODEL_DIR / "vae_decoder.xml"テキスト・エンコーダーを変換#
example_input = {
"input_ids": torch.zeros(1, 120, dtype=torch.int64),
"attention_mask": torch.zeros(1, 120, dtype=torch.int64),
}
convert(pipe.text_encoder, TEXT_ENCODER_PATH, example_input)WARNING:tensorflow:Please fix your imports.Module tensorflow.python.training.tracking.base has been moved to tensorflow.python.trackable.base.The old module will be deleted in version 2.11.[ WARNING ] Please fix your imports. Module %s has been moved to %s. The old module will be deleted in version %s. /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/transformers/modeling_utils.py:4371: FutureWarning: _is_quantized_training_enabled is going to be deprecated in transformers 4.39.0.Please use model.hf_quantizer.is_trainable instead warnings.warn(
['input_ids', 'attention_mask']トランスフォーマーを変換#
class TransformerWrapper(torch.nn.Module):
def __init__(self, transformer):
super().__init__()
self.transformer = transformer
def forward(self, hidden_states=None, timestep=None, encoder_hidden_states=None, encoder_attention_mask=None, resolution=None, aspect_ratio=None):
return self.transformer.forward(
hidden_states,
timestep=timestep,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
added_cond_kwargs={"resolution": resolution, "aspect_ratio": aspect_ratio},
)
example_input = {
"hidden_states": torch.rand([2, 4, 128, 128], dtype=torch.float32),
"timestep": torch.tensor([999, 999]),
"encoder_hidden_states": torch.rand([2, 120, 4096], dtype=torch.float32),
"encoder_attention_mask": torch.rand([2, 120], dtype=torch.float32),
"resolution": torch.tensor([[1024.0, 1024.0], [1024.0, 1024.0]]),
"aspect_ratio": torch.tensor([[1.0], [1.0]]),
}
w_transformer = TransformerWrapper(pipe.transformer)
convert(w_transformer, TRANSFORMER_OV_PATH, example_input)/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/diffusers/models/embeddings.py:219: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if self.height != height or self.width != width: /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/diffusers/models/attention_processor.py:682: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect.We can't record the data flow of Python values, so this value will be treated as a constant in the future.This means that the trace might not generalize to other inputs!
if current_length != target_length: /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/diffusers/models/attention_processor.py:697: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect.We can't record the data flow of Python values, so this value will be treated as a constant in the future.This means that the trace might not generalize to other inputs!
if attention_mask.shape[0] < batch_size * head_size:['hidden_states', 'timestep', 'encoder_hidden_states',
'encoder_attention_mask', 'resolution', 'aspect_ratio']VAE デコーダーを変換#
class VAEDecoderWrapper(torch.nn.Module):
def __init__(self, vae):
super().__init__()
self.vae = vae
def forward(self, latents):
return self.vae.decode(latents, return_dict=False)
convert(VAEDecoderWrapper(pipe.vae), VAE_DECODER_PATH, (torch.zeros((1, 4, 128, 128))))/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/diffusers/models/upsampling.py:146: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect.We can't record the data flow of Python values, so this value will be treated as a constant in the future.This means that the trace might not generalize to other inputs!
assert hidden_states.shape[1] == self.channels /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/diffusers/models/upsampling.py:162: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect.We can't record the data flow of Python values, so this value will be treated as a constant in the future.This means that the trace might not generalize to other inputs!
if hidden_states.shape[0] >= 64:['latents']モデルのコンパイル#
OpenVINO を使用して推論を実行するデバイスをドロップダウン・リストから選択します。
import ipywidgets as widgets
core = ov.Core()
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value="AUTO",
description="Device:",
disabled=False,
)
deviceDropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')compiled_model = core.compile_model(TRANSFORMER_OV_PATH)
compiled_vae = core.compile_model(VAE_DECODER_PATH)
compiled_text_encoder = core.compile_model(TEXT_ENCODER_PATH)パイプラインの構築#
元のパイプラインとの対話を可能にするため、コンパイルされたモデルの呼び出し可能なラッパークラスを作成します。すべてのラッパークラスは np.array ではなく torch.Tensor を返すことに注意してください。
from collections import namedtuple
EncoderOutput = namedtuple("EncoderOutput", "last_hidden_state")
class TextEncoderWrapper(torch.nn.Module):
def __init__(self, text_encoder, dtype):
super().__init__()
self.text_encoder = text_encoder
self.dtype = dtype
def forward(self, input_ids=None, attention_mask=None):
inputs = {
"input_ids": input_ids,
"attention_mask": attention_mask,
}
last_hidden_state = self.text_encoder(inputs)[0]
return EncoderOutput(torch.from_numpy(last_hidden_state))class TransformerWrapper(torch.nn.Module):
def __init__(self, transformer, config):
super().__init__()
self.transformer = transformer
self.config = config
def forward(
self,
hidden_states=None,
timestep=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
resolution=None,
aspect_ratio=None,
added_cond_kwargs=None,
**kwargs
):
inputs = {
"hidden_states": hidden_states,
"timestep": timestep,
"encoder_hidden_states": encoder_hidden_states,
"encoder_attention_mask": encoder_attention_mask,
}
resolution = added_cond_kwargs["resolution"]
aspect_ratio = added_cond_kwargs["aspect_ratio"]
if resolution is not None:
inputs["resolution"] = resolution
inputs["aspect_ratio"] = aspect_ratio
outputs = self.transformer(inputs)[0]
return [torch.from_numpy(outputs)]class VAEWrapper(torch.nn.Module):
def __init__(self, vae, config):
super().__init__()
self.vae = vae
self.config = config
def decode(self, latents=None, **kwargs):
inputs = {
"latents": latents,
}
outs = self.vae(inputs)
outs = namedtuple("VAE", "sample")(torch.from_numpy(outs[0]))
return outsパイプラインにラッパー・インスタンスを挿入:
pipe.__dict__["_internal_dict"]["_execution_device"] = pipe._execution_device # これはパイプラインで発生する可能性のある問題を回避
pipe.register_modules(
text_encoder=TextEncoderWrapper(compiled_text_encoder, pipe.text_encoder.dtype),
transformer=TransformerWrapper(compiled_model, pipe.transformer.config),
vae=VAEWrapper(compiled_vae, pipe.vae.config),
)generator = torch.Generator().manual_seed(42)
image = pipe(prompt=prompt, guidance_scale=0.0, num_inference_steps=4,
generator=generator).images[0]/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/diffusers/configuration_utils.py:140: FutureWarning: Accessing config attribute _execution_device directly via 'PixArtAlphaPipeline' object attribute is deprecated. Please access '_execution_device' over 'PixArtAlphaPipeline's config object instead, e.g. 'scheduler.config._execution_device'. deprecate("direct config name access", "1.0.0", deprecation_message, standard_warn=False)
0%| | 0/4 [00:00<?, ?it/s]image
インタラクティブな推論#
import gradio as gr
def generate(prompt, seed, negative_prompt, num_inference_steps):
generator = torch.Generator().manual_seed(seed)
image = pipe(prompt=prompt, negative_prompt=negative_prompt, num_inference_steps=num_inference_steps, generator=generator, guidance_scale=0.0).images[0]
return image
demo = gr.Interface(
generate,
[
gr.Textbox(label="Caption"),
gr.Slider(0, np.iinfo(np.int32).max, label="Seed"),
gr.Textbox(label="Negative prompt"),
gr.Slider(2, 20, step=1, label="Number of inference steps", value=4),
],
"image",
examples=[
["A small cactus with a happy face in the Sahara desert.", 42],
["an astronaut sitting in a diner, eating fries, cinematic, analog film", 42],
[ "Pirate ship trapped in a cosmic maelstrom nebula, rendered in cosmic beach whirlpool engine, volumetric lighting, spectacular, ambient lights, light pollution, cinematic atmosphere, art nouveau style, illustration art artwork by SenseiJaye, intricate detail.", 0,
],
["professional portrait photo of an anthropomorphic cat wearing fancy gentleman hat and jacket walking in autumn forest.", 0],
],
allow_flagging="never",
)
try:
demo.queue().launch(debug=False)
except Exception:
demo.queue().launch(debug=False, share=True)
# リモートで起動する場合は、server_name と server_port を指定
# demo.launch(server_name='your server name', server_port='server port in int')
# 詳細については、ドキュメントをご覧ください://gradio.app/docs/ローカル URL で実行中: http://127.0.0.1:7860 パブリックリンクを作成するには、launch() で share=True を設定します。