Parler-TTS と OpenVINO によるテキスト読み上げ (TTS)#
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

Parler-TTS は、特定の話者のスタイル (性別、ピッチ、話し方など) で高品質で自然な音声を生成できる軽量のテキスト読み上げ (TTS) モデルです。これは、Stability AI の Dan Lyth 氏とエディンバラ大学の Simon King 氏による論文合成注釈付きの高精度テキスト読み上げの自然言語ガイダンス (英語) からの転載です。
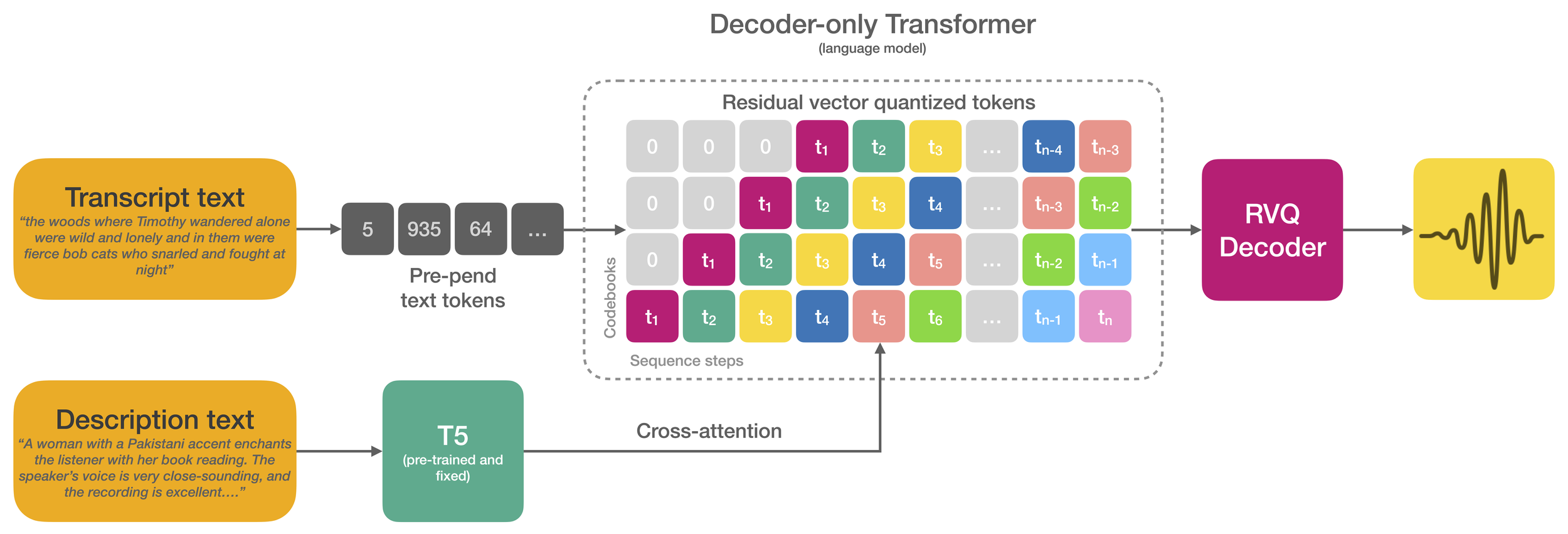
大規模データセットでトレーニングされたテキスト読み上げモデルは、優れたコンテキスト内学習機能と自然さを実証しています。しかし、このモデルで話者のアイデンティティーとスタイルを制御するには、通常、参照音声録音の調整が必要であり、創造性のあるアプリケーションは制限を受けます。また、話者のアイデンティティーとスタイルを自然言語で促すことは有望な結果を示しており、直感的な制御方法を提供します。ただし、人間がラベル付けした説明に依存すると、大規模データセットへの拡張ができなくなります。
この研究は、2 つのアプローチの間のギャップを埋めるものです。著者らは、話者のアイデンティティー、スタイル、録音条件のさまざまな面をラベル付けするためのスケーラブルな方法を提案しています。この方法は、音声言語モデルのトレーニングに使用される 45,000 時間のデータセットに適用されます。さらに、著者らは、オーディオの忠実度を高める簡単な方法を提案しており、発見されたデータに完全に依存しているにもかかわらず、最近の研究を大幅に上回っています。
目次:
必要条件#
import os
os.environ["GIT_CLONE_PROTECTION_ACTIVE"] = "false"
%pip install -q "openvino>=2024.2.0"
%pip install -q git+https://github.com/huggingface/parler-tts.git "gradio>=4.19" transformers "torch>=2.2" --extra-index-url https://download.pytorch.org/whl/cpuNote: you may need to restart the kernel to use updated packages. ERROR: pip's dependency resolver does not currently take into account all the packages that are installed.This behaviour is the source of the following dependency conflicts. googleapis-common-protos 1.63.2 requires protobuf!=3.20.0,!=3.20.1,!=4.21.1,!=4.21.2,!=4.21.3,!=4.21.4,!=4.21.5,<6.0.0.dev0,>=3.20.2, but you have protobuf 3.19.6 which is incompatible.
mobileclip 0.1.0 requires torch==1.13.1, but you have torch 2.3.1+cpu which is incompatible.
mobileclip 0.1.0 requires torchvision==0.14.1, but you have torchvision 0.18.1+cpu which is incompatible.
onnx 1.16.1 requires protobuf>=3.20.2, but you have protobuf 3.19.6 which is incompatible.
paddlepaddle 2.6.1 requires protobuf>=3.20.2; platform_system != "Windows", but you have protobuf 3.19.6 which is incompatible.
tensorflow 2.12.0 requires protobuf!=4.21.0,!=4.21.1,!=4.21.2,!=4.21.3,!=4.21.4,!=4.21.5,<5.0.0dev,>=3.20.3, but you have protobuf 3.19.6 which is incompatible.
tensorflow-datasets 4.9.2 requires protobuf>=3.20, but you have protobuf 3.19.6 which is incompatible.
tensorflow-metadata 1.14.0 requires protobuf<4.21,>=3.20.3, but you have protobuf 3.19.6 which is incompatible.
tf2onnx 1.16.1 requires protobuf~=3.20, but you have protobuf 3.19.6 which is incompatible.
visualdl 2.5.3 requires protobuf>=3.20.0, but you have protobuf 3.19.6 which is incompatible. Note: you may need to restart the kernel to use updated packages.元のモデルをロードして推論#
import torch
from parler_tts import ParlerTTSForConditionalGeneration
from transformers import AutoTokenizer
import soundfile as sf
device = "cpu"
repo_id = "parler-tts/parler_tts_mini_v0.1"
model = ParlerTTSForConditionalGeneration.from_pretrained(repo_id).to(device)
tokenizer = AutoTokenizer.from_pretrained(repo_id)
prompt = "Hey, how are you doing today?"
description = "A female speaker with a slightly low-pitched voice delivers her words quite expressively, in a very confined sounding environment with clear audio quality.She speaks very fast."
input_ids = tokenizer(description, return_tensors="pt").input_ids.to(device)
prompt_input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
generation = model.generate(input_ids=input_ids, prompt_input_ids=prompt_input_ids)
audio_arr = generation.cpu().numpy().squeeze()
sf.write("parler_tts_out.wav", audio_arr, model.config.sampling_rate)2024-07-13 01:23:01.501117: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on.You may see slightly different numerical results due to floating-point round-off errors from different computation orders.To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0.
2024-07-13 01:23:01.536383: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags./opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/huggingface_hub/file_download.py:1132: FutureWarning: resume_download is deprecated and will be removed in version 1.0.0.Downloads always resume when possible.If you want to force a new download, use force_download=True.
warnings.warn( /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/torch/nn/utils/weight_norm.py:28: UserWarning: torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.
warnings.warn("torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.") You set add_prefix_space. The tokenizer needs to be converted from the slow tokenizers Using the model-agnostic default max_length (=2580) to control the generation length. We recommend setting max_new_tokens to control the maximum length of the generation.
import IPython.display as ipd
ipd.Audio("parler_tts_out.wav")モデルを OpenVINO IR に変換#
PyTorch モジュールの変換関数を定義します。ov.convert_model 関数を使用して OpenVINO 中間表現オブジェクトを取得し、ov.save_model 関数でそれを XML ファイルとして保存します。
import openvino as ov
def convert(model: torch.nn.Module, xml_path: str, example_input):
xml_path = Path(xml_path)
if not xml_path.exists():
xml_path.parent.mkdir(parents=True, exist_ok=True)
with torch.no_grad():
converted_model = ov.convert_model(model, example_input=example_input)
ov.save_model(converted_model, xml_path)
# メモリーをクリーンアップ
torch._C._jit_clear_class_registry()
torch.jit._recursive.concrete_type_store = torch.jit._recursive.ConcreteTypeStore()
torch.jit._state._clear_class_state()パイプラインでは 2 つのモデルが使用されます: テキスト・エンコーダー (T5EncoderModel) とデコーダー (ParlerTTSDecoder)。一つずつ変換してみます。
from pathlib import Path
TEXT_ENCODER_OV_PATH = Path("models/text_encoder_ir.xml")
example_input = {
"input_ids": torch.ones((1, 39), dtype=torch.int64),
}
text_encoder_ov_model = convert(model.text_encoder, TEXT_ENCODER_OV_PATH, example_input)/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/transformers/modeling_utils.py:4371: FutureWarning: _is_quantized_training_enabled is going to be deprecated in transformers 4.39.0.Please use model.hf_quantizer.is_trainable instead warnings.warn(
デコーダーモデルは生成パイプラインで実行されますが、2 つのステージに分割されます。最初のステージで、モデルは past_key_values を第 2 ステージの出力として生成します。第 2 ステージでは、モデルは複数回の実行中にトークンを生成します。
DECODER_STAGE_1_OV_PATH = Path("models/decoder_stage_1_ir.xml")
class DecoderStage1Wrapper(torch.nn.Module):
def __init__(self, decoder):
super().__init__()
self.decoder = decoder
def forward(self, input_ids=None, encoder_hidden_states=None, encoder_attention_mask=None, prompt_hidden_states=None):
return self.decoder(
input_ids=input_ids,
return_dict=False,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
prompt_hidden_states=prompt_hidden_states,
)
example_input = {
"input_ids": torch.ones((9, 1), dtype=torch.int64),
"encoder_hidden_states": torch.ones((1, 39, 1024), dtype=torch.float32),
"encoder_attention_mask": torch.ones((1, 39), dtype=torch.int64),
"prompt_hidden_states": torch.ones((1, 9, 1024), dtype=torch.float32),
}
decoder_1_ov_model = convert(DecoderStage1Wrapper(model.decoder.model.decoder), DECODER_STAGE_1_OV_PATH, example_input)/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/transformers/modeling_attn_mask_utils.py:86: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect.We can't record the data flow of Python values, so this value will be treated as a constant in the future.This means that the trace might not generalize to other inputs!
if input_shape[-1] > 1 or self.sliding_window is not None: /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/transformers/modeling_attn_mask_utils.py:162: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect.We can't record the data flow of Python values, so this value will be treated as a constant in the future.This means that the trace might not generalize to other inputs!
if past_key_values_length > 0: /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/parler_tts/modeling_parler_tts.py:221: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect.We can't record the data flow of Python values, so this value will be treated as a constant in the future.This means that the trace might not generalize to other inputs!
if seq_len > self.weights.size(0): /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/parler_tts/modeling_parler_tts.py:328: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect.We can't record the data flow of Python values, so this value will be treated as a constant in the future.This means that the trace might not generalize to other inputs!
if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len): /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/parler_tts/modeling_parler_tts.py:335: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect.We can't record the data flow of Python values, so this value will be treated as a constant in the future.This means that the trace might not generalize to other inputs!
if attention_mask.size() != (bsz, 1, tgt_len, src_len): /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/parler_tts/modeling_parler_tts.py:367: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect.We can't record the data flow of Python values, so this value will be treated as a constant in the future.This means that the trace might not generalize to other inputs!
if attn_output.size() != (bsz * self.num_heads, tgt_len, self.head_dim):DECODER_STAGE_2_OV_PATH = Path("models/decoder_stage_2_ir.xml")
class DecoderStage2Wrapper(torch.nn.Module):
def __init__(self, decoder):
super().__init__()
self.decoder = decoder
def forward(self, input_ids=None, encoder_hidden_states=None, encoder_attention_mask=None, past_key_values=None):
past_key_values = tuple(tuple(past_key_values[i : i + 4]) for i in range(0, len(past_key_values), 4))
return self.decoder(
input_ids=input_ids,
return_dict=False,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
)
example_input = {
"input_ids": torch.ones((9, 1), dtype=torch.int64),
"encoder_hidden_states": torch.ones((1, 39, 1024), dtype=torch.float32),
"encoder_attention_mask": torch.ones((1, 39), dtype=torch.int64),
"past_key_values": (
(
torch.ones(1, 16, 10, 64, dtype=torch.float32),
torch.ones(1, 16, 10, 64, dtype=torch.float32),
torch.ones(1, 16, 39, 64, dtype=torch.float32),
torch.ones(1, 16, 39, 64, dtype=torch.float32),
)
* 24
),
}
decoder_2_ov_model = convert(DecoderStage2Wrapper(model.decoder.model.decoder), DECODER_STAGE_2_OV_PATH, example_input)/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/parler_tts/modeling_parler_tts.py:287: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect.We can't record the data flow of Python values, so this value will be treated as a constant in the future.This means that the trace might not generalize to other inputs!
if (モデルと推論のコンパイル#
OpenVINO を使用して推論を実行するデバイスをドロップダウン・リストから選択します。
import ipywidgets as widgets
core = ov.Core()
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value="AUTO",
description="Device:",
disabled=False,
)
deviceDropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')元のパイプラインとの対話を可能にするため、コンパイルされたモデルの呼び出し可能なラッパークラスを作成します。すべてのラッパークラスは np.array ではなく torch.Tensor を返すことに注意してください。DecoderWrapper では、パイプラインを 2 つのステージに分割します。
from collections import namedtuple
EncoderOutput = namedtuple("EncoderOutput", "last_hidden_state")
DecoderOutput = namedtuple("DecoderOutput", ("last_hidden_state", "past_key_values", "hidden_states", "attentions", "cross_attentions"))
class TextEncoderModelWrapper(torch.nn.Module):
def __init__(self, encoder_ir_path, config):
self.encoder = core.compile_model(encoder_ir_path, device.value)
self.config = config
self.dtype = self.config.torch_dtype
def __call__(self, input_ids, **_):
last_hidden_state = self.encoder(input_ids)[0]
return EncoderOutput(torch.from_numpy(last_hidden_state))
class DecoderWrapper(torch.nn.Module):
def __init__(self, decoder_stage_1_ir_path, decoder_stage_2_ir_path):
super().__init__()
self.decoder_stage_1 = core.compile_model(decoder_stage_1_ir_path, device.value)
self.decoder_stage_2 = core.compile_model(decoder_stage_2_ir_path, device.value)
def __call__(self, input_ids=None, encoder_hidden_states=None, encoder_attention_mask=None, past_key_values=None, prompt_hidden_states=None, **kwargs):
inputs = {}
if input_ids is not None:
inputs["input_ids"] = input_ids
if encoder_hidden_states is not None:
inputs["encoder_hidden_states"] = encoder_hidden_states
if encoder_attention_mask is not None:
inputs["encoder_attention_mask"] = encoder_attention_mask
if prompt_hidden_states is not None:
inputs["prompt_hidden_states"] = prompt_hidden_states
if past_key_values is not None:
past_key_values = tuple(past_key_value for pkv_per_layer in past_key_values for past_key_value in pkv_per_layer)
inputs["past_key_values"] = past_key_values
arguments = (
input_ids,
encoder_hidden_states,
encoder_attention_mask,
*past_key_values,
)
outs = self.decoder_stage_2(arguments)
else:
outs = self.decoder_stage_1(inputs)
outs = [torch.from_numpy(out) for out in outs.values()]
past_key_values = list(list(outs[i : i + 4]) for i in range(1, len(outs), 4))
return DecoderOutput(outs[0], past_key_values, None, None, None)これで、元のモデルをラップされた OpenVINO モデルに置き換えて推論を実行できます。
model.text_encoder = TextEncoderModelWrapper(TEXT_ENCODER_OV_PATH,
model.text_encoder.config)
model.decoder.model.decoder = DecoderWrapper(DECODER_STAGE_1_OV_PATH, DECODER_STAGE_2_OV_PATH)generation = model.generate(input_ids=input_ids, prompt_input_ids=prompt_input_ids)
audio_arr = generation.cpu().numpy().squeeze()
sf.write("parler_tts_out.wav", audio_arr, model.config.sampling_rate)Using the model-agnostic default max_length (=2580) to control the generation length.We recommend setting max_new_tokens to control the maximum length of the generation.
import IPython.display as ipd
ipd.Audio("parler_tts_out.wav")インタラクティブな推論#
import gradio as gr
import numpy as np
from transformers import AutoFeatureExtractor, set_seed
title = "Text-to-speech (TTS) with Parler-TTS and OpenVINO"
feature_extractor = AutoFeatureExtractor.from_pretrained(repo_id)
SAMPLE_RATE = feature_extractor.sampling_rate
def infer(prompt, description, seed):
set_seed(seed)
input_ids = tokenizer(description, return_tensors="pt").input_ids.to("cpu")
prompt_input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to("cpu")
generation = model.generate(input_ids=input_ids, prompt_input_ids=prompt_input_ids)
audio_arr = generation.cpu().numpy().squeeze()
sr = SAMPLE_RATE
return sr, audio_arr
demo = gr.Interface(
infer,
[
gr.Text(label="Prompt"),
gr.Text(label="Description"),
gr.Slider(
label="Seed",
value=42,
step=1,
minimum=0,
maximum=np.iinfo(np.int32).max,
),
],
gr.Audio(label="Output Audio", type="numpy"),
title=title,
description=description,
examples=[
[
"Hey, how are you doing today?",
"A female speaker with a slightly low-pitched voice delivers her words quite expressively, in a very confined sounding environment with clear audio quality.She speaks very fast.",
],
[
"'This is the best time of my life, Bartley,' she said happily.",
"A female speaker with a slightly low-pitched, quite monotone voice delivers her words at a slightly faster-than-average pace in a confined space with very clear audio.",
],
[
"Montrose also, after having experienced still more variety of good and bad fortune, threw down his arms, and retired out of the kingdom.",
"A male speaker with a slightly high-pitched voice delivering his words at a slightly slow pace in a small, confined space with a touch of background noise and a quite monotone tone.",
],
[
"montrose also after having experienced still more variety of good and bad fortune threw down his arms and retired out of the kingdom",
"A male speaker with a low-pitched voice delivering his words at a fast pace in a small, confined space with a lot of background noise and an animated tone.",
],
],
)
try:
demo.queue().launch(debug=False)
except Exception:
demo.queue().launch(share=True, debug=False)
# リモートで起動する場合は、server_name と server_port を指定
# demo.launch(server_name='your server name', server_port='server port in int')
# 詳細については、ドキュメントをご覧ください: https://gradio.app/docs//opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/huggingface_hub/file_download.py:1132: FutureWarning: resume_download is deprecated and will be removed in version 1.0.0.Downloads always resume when possible.If you want to force a new download, use force_download=True. warnings.warn(
ローカル URL で実行中: http://127.0.0.1:7860 パブリックリンクを作成するには、launch() で share=True を設定します。