Hello モデルサーバー#
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

OpenVINO™ モデルサーバー (OVMS) の紹介。
モデルサービングとは?#
モデルサーバーはモデルをホストし、標準のネットワーク・プロトコルを介してソフトウェア・コンポーネントがモデルにアクセスできるようにします。クライアントはモデルサーバーに要求を送信し、モデルサーバーは推論を実行してクライアントに応答を返します。モデルのサービングには、モデルを効率的にデプロイする多くの利点があります:
リモート推論により、エッジまたはクラウド展開への API 呼び出しを実行するのに必要な機能を備えた軽量クライアントを使用できるようになります。
アプリケーションは、モデル・フレームワーク、ハードウェア・デバイス、およびインフラストラクチャーから独立しています。
REST または gRPC 呼び出しをサポートする任意のプログラミング言語のクライアント・アプリケーションを使用して、モデルサーバー上で推論をリモートで実行できます。
クライアント・ライブラリーはほとんど変更されないため、クライアントの更新は少なくなります。
モデルのトポロジーと重みはクライアント・アプリケーションに直接公開されないため、モデルへのアクセスを制御しやすくなります。
Kubernetes や OpenShift クラスターなどのクラウド環境のマイクロサービスベースのアプリケーションおよびデプロイメントに理想的なアーキテクチャーです。
水平および垂直推論スケーリングによって効率的にリソースを利用します。
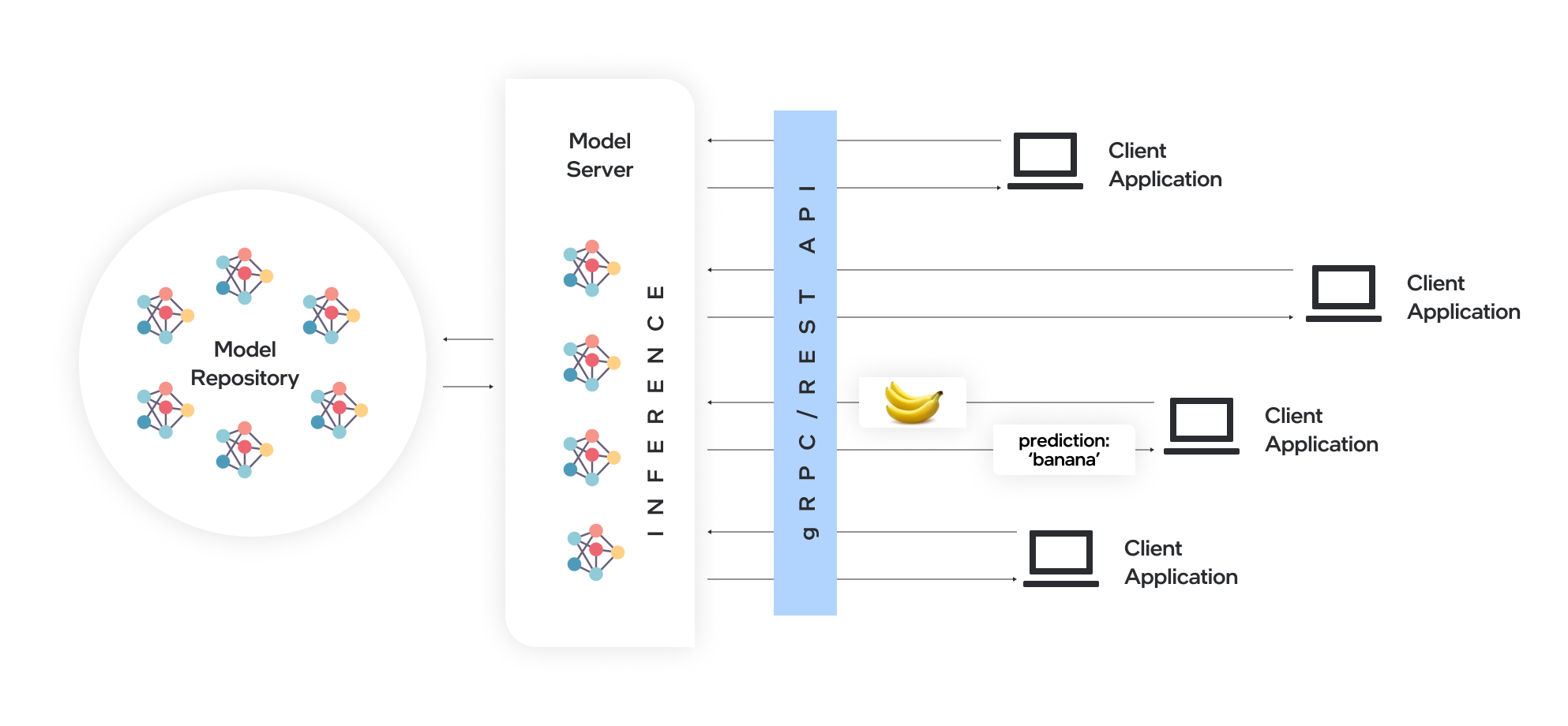
ovms_diagram#
目次:
OpenVINO モデルサーバーのサービス#
OpenVINO モデルサーバー (OVMS) は、モデルを提供する高性能システムです。スケーラビリティーを実現するため C++ で実装された、インテル® アーキテクチャーでのデプロイに最適化されたモデルサーバーは、推論の実行に OpenVINO を適用しながら、TensorFlow サービスおよび KServe と同じアーキテクチャーと API を使用します。推論サービスは gRPC または REST API を介して提供されるため、新しいアルゴリズムのデプロイや AI 実験が容易です。
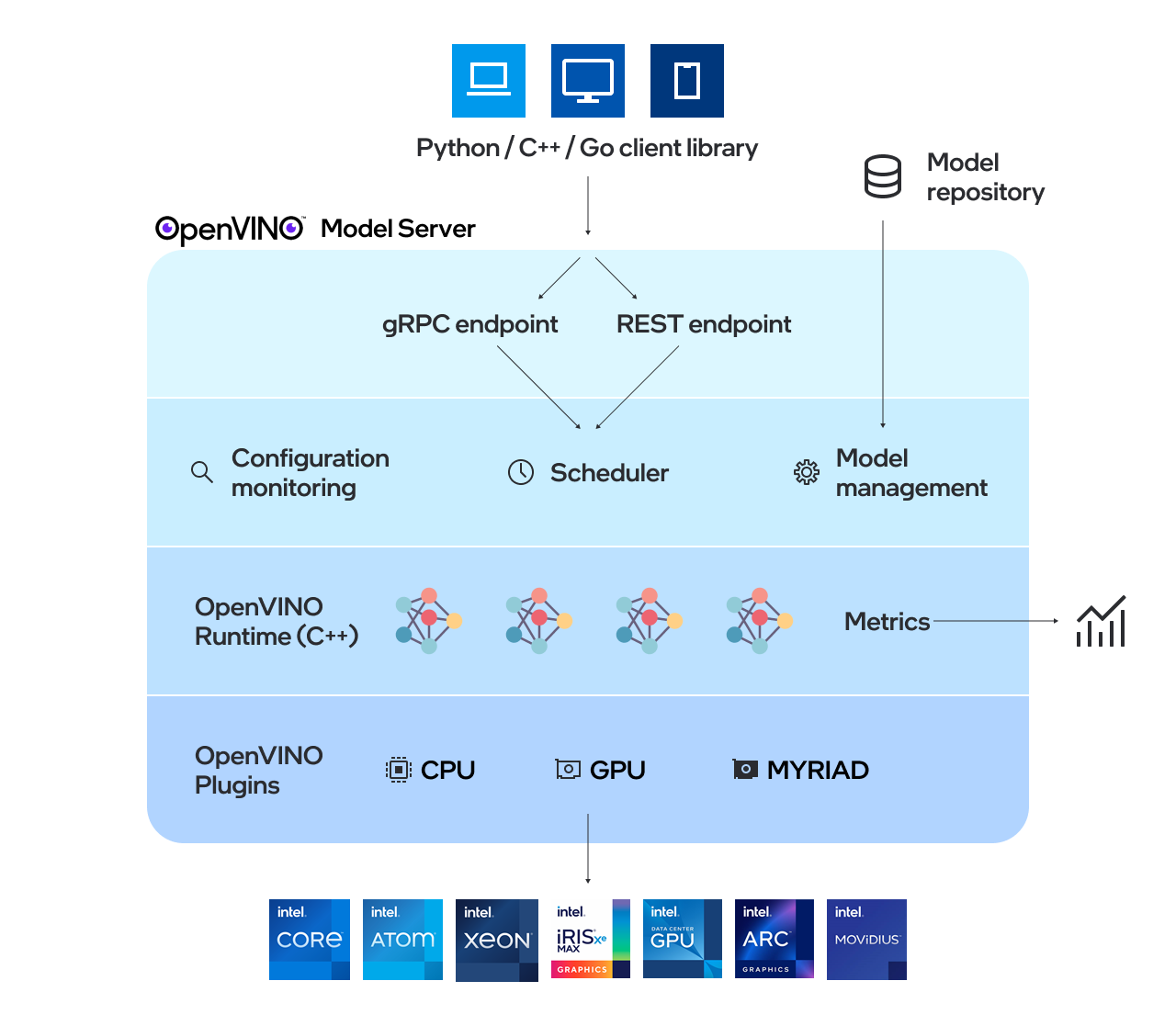
ovms_high_level#
OpenVINO™ モデルサーバーのクイックスタートには、次の手順に従います:
ステップ 1: Docker の準備#
開発システムでインストール後の手順を含む Docker エンジンをインストールします。インストールを確認するには、次のコマンドでテストします。準備が完了すると、テスト画像とメッセージが表示されます。
!docker run hello-worldHello from Docker!
このメッセージは、インストールが正常であることを示しています。このメッセージを生成するには Docker は次の手順を実行します:
1. Docker クライアントが Docker デーモンに接続しました。
2. Docker デーモンは Docker Hub から "hello-world" イメージを取得しました。(amd64)
3. Docker デーモンは、そのイメージから新しいコンテナを作成し、現在読み取っている出力を生成する実行可能ファイルを実行します。
4. Docker デーモンは出力を Docker クライアントにストリーミングし、Docker クライアントはそれをターミナルに送信しました。
もっと野心的なことに挑戦するには、次のコマンドで Ubuntu* コンテナを実行できます:
$ docker run -it ubuntu bash
無料の Docker ID を使用して、イメージを共有したり、ワークフローを自動化することができます: https://hub.docker.com/
その他の例やアイデアについては https://docs.docker.com/get-started/ をご覧ください。ステップ 2: モデル・リポジトリーの準備#
モデルは、次のルールに従って、特定のディレクトリー構造に配置およびマウントされる必要があります:
tree models/
models/
├── model1
│ ├── 1
│ │ ├── ir_model.bin
│ │ └── ir_model.xml
│ └── 2
│ ├── ir_model.bin
│ └── ir_model.xml
├── model2
│ └── 1
│ ├── ir_model.bin
│ ├── ir_model.xml
│ └── mapping_config.json
├── model3
│ └── 1
│ └── model.onnx
├── model4
│ └── 1
│ ├── model.pdiparams
│ └── model.pdmodel
└── model5
└── 1
└── TF_fronzen_model.pb
各モデルは専用のディレクトリーに保存する必要があります。例: model1 と model2 など。
各モデルのディレクトリーには、各バージョン (1、2 など) のサブフォルダーが含まれる必要があります。バージョンのフォルダー名は正の整数値である必要があります。
注: バージョンは事前定義されたバージョンポリシーに従って有効になります。クライアントがパラメーターでバージョン番号を指定しない場合、デフォルトで最新バージョンが設定されます。
すべてのバージョンフォルダーにはモデルファイル (OpenVINO IR の場合は
.binと.xml、ONNX の場合は.onnx、Paddle Paddle の場合は.pdiparamsと.pdmodel、TensorFlow の場合は.pb) が含まれている必要があります。ファイル名は任意です。
import platform
%pip install -q "openvino>=2023.1.0" opencv-python tqdm
if platform.system() != "Windows":
%pip install -q "matplotlib>=3.4"
else:
%pip install -q "matplotlib>=3.4,<3.7"import os
# `notebook_utils` モジュールを取得
import requests
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py",
)
open("notebook_utils.py", "w").write(r.text)
from notebook_utils import download_file
dedicated_dir = "models"
model_name = "detection"
model_version = "1"
MODEL_DIR = f"{dedicated_dir}/{model_name}/{model_version}"
XML_PATH = "horizontal-text-detection-0001.xml"
BIN_PATH = "horizontal-text-detection-0001.bin"
os.makedirs(MODEL_DIR, exist_ok=True)
model_xml_url = (
"https://storage.openvinotoolkit.org/repositories/open_model_zoo/2022.3/models_bin/1/horizontal-text-detection-0001/FP32/horizontal-text-detection-0001.xml"
)
model_bin_url = (
"https://storage.openvinotoolkit.org/repositories/open_model_zoo/2022.3/models_bin/1/horizontal-text-detection-0001/FP32/horizontal-text-detection-0001.bin"
)
download_file(model_xml_url, XML_PATH, MODEL_DIR)
download_file(model_bin_url, BIN_PATH, MODEL_DIR)models/detection/1/horizontal-text-detection-0001.xml: 0%| | 0.00/680k [00:00<?, ?B/s]models/detection/1/horizontal-text-detection-0001.bin: 0%| | 0.00/7.39M [00:00<?, ?B/s]PosixPath('/home/ethan/intel/openvino_notebooks/notebooks/model-server/models/detection/1/horizontal-text-detection-0001.bin')ステップ 3: モデル・サーバー・コンテナの開始#
コンテナを取得して起動します:
ローカルで利用可能なサービスポートを検索します。
import socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.bind(("localhost", 0))
sock.listen(1)
port = sock.getsockname()[1]
sock.close()
print(f"Port {port} is available")
os.environ["port"] = str(port)Port 39801 is available!docker run -d --rm --name="ovms" -v $(pwd)/models:/models -p $port:9000 openvino/model_server:latest --model_path /models/detection/ --model_name detection --port 900064aa9391ba019b3ef26ae3010e5605e38d0a12e3f93bf74b3afb938f39b86ad2OVMS コンテナが正常に実行されていることを確認します。
!docker ps | grep ovms64aa9391ba01 openvino/model_server:latest "/ovms/bin/ovms --mo…" 29 seconds ago Up 28 seconds 0.0.0.0:37581->9000/tcp, :::37581->9000/tcp ovms必要なモデルサーバーのパラメーターを以下に示します。追加の構成オプションについては、モデルサーバーのパラメーターを参照してください。
–rm | Docker コンテナを終了するときにコンテナを削除します |
-d | コンテナをバックグラウンドで実行します |
-v | Docker コンテナにモデルフォルダーをマウントする方法を定義します |
-p | モデルの提供ポートを Docker コンテナ外部に公開します |
openvino/model_server:latest | イメージ名を表します。OVMS バイナリーは Docker のエントリーポイントです。 タグとビルドプロセスによって異なります - 完全なタグリストについては、タグ: https://hub.docker.com/r/openvino/model_server/tags/ を参照してください。 |
–model_path | モデルの場所は次のようになります: 起動時にマウントされる Docker コンテナのパス Google Cloud Storage のパス gs://<bucket/<model_path> AWS S3 のパス s3://<bucket/<model_path> Azure blob のパス az://<container/<model_path> |
–model_name | model_path 内のモデル名を指定します |
–port | gRPC サーバーのポートを指定します |
–rest_port | REST サーバーのポートを指定します |
サービスポートがすでに使用されている場合は、システム上の別のポートに切り替えてください。次に例を示します: -p 9020:9000
ステップ 4: サンプル・クライアント・コンポーネントの準備#
OpenVINO™ モデルサーバーは 2 つの API セットを公開します。1 つは TensorFlow サービングと互換性があり、もう 1 つは推論で KServe API と互換性があります。どちらの API も gRPC と REST インターフェイスで動作します。2 セットの API をサポートすることで、推論でこれらの API の 1 つをすでに利用している OpenVINO モデルサーバーを既存のシステムに簡単に接続できるようになります。この例では、オブジェクト検出用の TensorFlow サービング API クライアントを作成する方法を示します。
必要条件#
必要なパッケージをインストールします。
%pip install -q ovmsclientNote: you may need to restart the kernel to use updated packages.インポート#
import cv2
import numpy as np
import matplotlib.pyplot as plt
from ovmsclient import make_grpc_clientモデルステータスの要求#
address = "localhost:" + str(port)
# grpc アドレスをクライアント・オブジェクトにバインド
client = make_grpc_client(address)
model_status = client.get_model_status(model_name=model_name)
print(model_status){1: {'state': 'AVAILABLE', 'error_code': 0, 'error_message': 'OK'}}モデルメタデータの要求#
model_metadata = client.get_model_metadata(model_name=model_name)
print(model_metadata){'model_version': 1, 'inputs': {'image': {'shape': [1, 3, 704, 704], 'dtype': 'DT_FLOAT'}}, 'outputs': {'boxes': {'shape': [-1, 5], 'dtype': 'DT_FLOAT'}, 'labels': {'shape': [-1], 'dtype': 'DT_INT64'}}}入力画像のロード#
# openvino_notebooks ストレージからイメージをダウンロード
image_filename = download_file(
"https://storage.openvinotoolkit.org/repositories/openvino_notebooks/data/data/image/intel_rnb.jpg",
directory="data",
)
# テキスト検出モデルでは、BGR 形式の画像が必要
image = cv2.imread(str(image_filename))
fp_image = image.astype("float32")
# ネットワークの予想される入力サイズに合わせて画像のサイズを変更
input_shape = model_metadata["inputs"]["image"]["shape"]
height, width = input_shape[2], input_shape[3]
resized_image = cv2.resize(fp_image, (height, width))
# ネットワーク入力の形状に合わせて形状を変更
input_image = np.expand_dims(resized_image.transpose(2, 0, 1), 0)
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))data/intel_rnb.jpg: 0%| | 0.00/288k [00:00<?, ?B/s]<matplotlib.image.AxesImage at 0x7f254faeec50>
Numpy 配列での予測を要求#
inputs = {"image": input_image}
# モデルサーバー上で推論を実行し、結果データを取得
boxes = client.predict(inputs=inputs, model_name=model_name)["boxes"]
# ゼロのみのボックスを削除
boxes = boxes[~np.all(boxes == 0, axis=1)]
print(boxes)[[4.0075238e+02 8.1240105e+01 5.6262683e+02 1.3609659e+02 5.3646392e-01]
[2.6150497e+02 6.8225861e+01 3.8433078e+02 1.2111545e+02 4.7504124e-01]
[6.1611401e+02 2.8000638e+02 6.6605963e+02 3.1116574e+02 4.5030469e-01]
[2.0762566e+02 6.2619057e+01 2.3446707e+02 1.0711832e+02 3.7426147e-01]
[5.1753296e+02 5.5611102e+02 5.4918005e+02 5.8740009e+02 3.2477754e-01]
[2.2038467e+01 4.5390991e+01 1.8856328e+02 1.0215196e+02 2.9959568e-01]]可視化#
# 各検出の説明は [x_min, y_min, x_max, y_max, conf] の形式です:
# ここで渡される画像は、幅と高さが変更された BGR 形式です。Matplotlib が期待する色で表示するには、cvtColor 関数を使用
def convert_result_to_image(bgr_image, resized_image, boxes, threshold=0.3, conf_labels=True):
# ボックスと説明の色を定義
colors = {"red": (255, 0, 0), "green": (0, 255, 0)}
# 画像の形状を取得して比率を計算(real_y, real_x), (resized_y, resized_x) = (
bgr_image.shape[:2],
resized_image.shape[:2],
)
ratio_x, ratio_y = real_x / resized_x, real_y / resized_y
# ベース画像を BGR 形式から RGB 形式に変換
rgb_image = cv2.cvtColor(bgr_image, cv2.COLOR_BGR2RGB)
# ゼロ以外のボックスを反復処理
for box in boxes:
# 配列の最後の場所から信頼係数を選択
conf = box[-1]
if conf > threshold: # loat を int に変換し、各ボックスのコーナーの位置に x と y の比率を掛ける。
# 境界ボックスが画像の上部にある場合は、
# 画像上に表示されるように上部のボックスバーを少し下に配置(x_min, y_min, x_max, y_max) = [
(int(max(corner_position * ratio_y, 10)) if idx % 2 else int(corner_position * ratio_x)) for idx, corner_position in enumerate(box[:-1])
]
# 位置に基づいてボックスを描画します。長方形関数のパラメーターは、image、start_point、end_point、color、thickness です。
rgb_image = cv2.rectangle(rgb_image, (x_min, y_min), (x_max, y_max), colors["green"], 3)
# 位置と信頼度に基づいて画像にテキストを追加します。
# テキスト関数のパラメーターは、image、text、bottom-left_corner_textfield、font、font_scale、color、thickness、line_type です。
if conf_labels:
rgb_image = cv2.putText(
rgb_image,
f"{conf:.2f}",
(x_min, y_min - 10),
cv2.FONT_HERSHEY_SIMPLEX,
0.8,
colors["red"],
1,
cv2.LINE_AA,
)
return rgb_imageplt.figure(figsize=(10, 6))
plt.axis("off")
plt.imshow(convert_result_to_image(image, resized_image, boxes, conf_labels=False))<matplotlib.image.AxesImage at 0x7f25490829b0>
モデル・サーバー・コンテナを停止して削除するには、次のコマンドを使用します:
!docker stop ovmsovms