TensorFlow インスタンス・セグメント化モデルを OpenVINO™ に変換#
この Jupyter ノートブックはオンラインで起動でき、ブラウザーのウィンドウで対話型環境を開きます。ローカルにインストールすることもできます。次のオプションのいずれかを選択します:



TensorFlow (略して TF) は、マシンラーニング向けのオープンソース・フレームワークです。
TensorFlow オブジェクト検出 API は、TensorFlow 上に構築されたオープンソースのコンピューター・ビジョン・フレームワークです。これは、同じ画像内の複数のオブジェクトを特定できるオブジェクト検出、およびインスタンスのセグメント化モデルの構築に使用されます。TensorFlow オブジェクト検出 API はさまざまなアーキテクチャーとモデルをサポートしており、TensorFlow ハブからダウンロードできます。
このチュートリアルでは、モデル・トランスフォーメーション API を使用して、TensorFlow Mask R-CNN with Inception ResNet V2 インスタンス・セグメント化モデルを OpenVINO 中間表現 (OpenVINO IR) 形式に変換する方法を説明します。OpenVINO IR を作成した後、OpenVINO ランタイムにモデルをロードし、サンプルイメージを使用して推論を実行します。
目次:
必要条件#
必要なパッケージをインストール:
import platform
%pip install -q "openvino>=2023.1.0" "numpy>=1.21.0" "opencv-python" "tqdm"
if platform.system() != "Windows":
%pip install -q "matplotlib>=3.4"
else:
%pip install -q "matplotlib>=3.4,<3.7"
%pip install -q "tensorflow-macos>=2.5; sys_platform == 'darwin' and platform_machine == 'arm64' and python_version > '3.8'" # macOS M1 and M2
%pip install -q "tensorflow-macos>=2.5,<=2.12.0; sys_platform == 'darwin' and platform_machine == 'arm64' and python_version <= '3.8'" # macOS M1 and M2
%pip install -q "tensorflow>=2.5; sys_platform == 'darwin' and platform_machine != 'arm64' and python_version > '3.8'" # macOS x86
%pip install -q "tensorflow>=2.5,<=2.12.0; sys_platform == 'darwin' and platform_machine != 'arm64' and python_version <= '3.8'" # macOS x86
%pip install -q "tensorflow>=2.5; sys_platform != 'darwin' and python_version > '3.8'"
%pip install -q "tensorflow>=2.5,<=2.12.0; sys_platform != 'darwin' and python_version <= '3.8'"Note: you may need to restart the kernel to use updated packages.
Note: you may need to restart the kernel to use updated packages.
Note: you may need to restart the kernel to use updated packages.
Note: you may need to restart the kernel to use updated packages.
Note: you may need to restart the kernel to use updated packages.
Note: you may need to restart the kernel to use updated packages.
Note: you may need to restart the kernel to use updated packages.
Note: you may need to restart the kernel to use updated packages. ノートブックはユーティリティー関数を使用します。以下のセルは、GitHub から notebook_utils Python モジュールをダウンロードします。
# openvino_notebooks リポジトリーからノートブック・ユーティリティー・スクリプトを取得
import requests
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py",
)
open("notebook_utils.py", "w").write(r.text)23215インポート#
# 標準の Python モジュール
from pathlib import Path
# 外部モジュールと依存関係
import cv2
import matplotlib.pyplot as plt
import numpy as np
# ノートブック・ユーティリティー・モジュール
from notebook_utils import download_file
# OpenVINO モジュール
import openvino as ov設定#
モデル関連の変数を定義し、対応するディレクトリーを作成します:
# モデルファイル用のディレクトリーを作成
model_dir = Path("model")
model_dir.mkdir(exist_ok=True)
# TensorFlow モデル用のディレクトリーを作成
tf_model_dir = model_dir / "tf"
tf_model_dir.mkdir(exist_ok=True)
# OpenVINO IR モデル用のディレクトリーを作成
ir_model_dir = model_dir / "ir"
ir_model_dir.mkdir(exist_ok=True)
model_name = "mask_rcnn_inception_resnet_v2_1024x1024"
openvino_ir_path = ir_model_dir / f"{model_name}.xml"
tf_model_url = (
"https://www.kaggle.com/models/tensorflow/mask-rcnn-inception-resnet-v2/frameworks/tensorFlow2/variations/1024x1024/versions/1?tf-hub-format=compressed"
)
tf_model_archive_filename = f"{model_name}.tar.gz"TensorFlow ハブからモデルをダウンロード#
TensorFlow インスタンス・セグメント化モデル (mask_rcnn_inception_resnet_v2_1024x1024) を含むアーカイブを TensorFlow ハブからダウンロードします:
download_file(url=tf_model_url, filename=tf_model_archive_filename, directory=tf_model_dir);model/tf/mask_rcnn_inception_resnet_v2_1024x1024.tar.gz: 0%| | 0.00/232M [00:00<?, ?B/s]ダウンロードしたアーカイブから TensorFlow インスタンス・セグメント化モデルを抽出します:
import tarfile
with tarfile.open(tf_model_dir / tf_model_archive_filename) as file:
file.extractall(path=tf_model_dir)モデルを OpenVINO IR に変換#
OpenVINO モデル・オプティマイザー Python API を使用して、TensorFlow モデルを OpenVINO IR に変換できます。
Mo.convert_model 関数は TensorFlow モデルへのパスを受け入れ、このモデルを表す OpenVINO モデルクラスのインスタンスを返します。また、TensorFlow ハブのモデル概要ページに記載されているモデル入力形状 (input_shape) を提供する必要があります。オプションとして、compress_to_fp16=True オプションを使用して FP16 モデルの重みに圧縮を適用し、このアプローチを使用して前処理を統合できます。
変換されたモデルは、compile_model を使用してデバイスにロードする準備ができており、また、serialize 関数を使用してディスクに保存して、将来モデルを実行する際にロード時間を短縮することもできます。
ov_model = ov.convert_model(tf_model_dir)
# 変換した OpenVINO IR モデルを対応するディレクトリーに保存
ov.save_model(ov_model, openvino_ir_path)変換されたモデルの推論テスト#
推論デバイスの選択#
OpenVINO を使用して推論を実行するためにドロップダウン・リストからデバイスを選択します
import ipywidgets as widgets
core = ov.Core()
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value="AUTO",
description="Device:",
disabled=False,
)
deviceDropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')モデルのロード#
openvino_ir_model = core.read_model(openvino_ir_path)
compiled_model = core.compile_model(model=openvino_ir_model, device_name=device.value)モデルの情報を取得#
Inception ResNet V2 インスタンス・セグメント化モデルを使用した Mask R-CNN には、可変サイズの 3 チャネルイメージ入力が 1 つあります。入力テンソルの形状は [1, height, width, 3] で、値は [0, 255] です。
モデルの出力辞書には多くのテンソルが含まれていますが、そのうち 5 つだけを使用します: - num_detections: 検出数 [N] の 1 つの値のみを持つ tf.int テンソル。- detection_boxes: 境界ボックスの座標を次の順序で含む形状 [N, 4] の tf.float32 テンソル: [ymin, xmin, ymax, xmax]。- detection_classes: - ラベルファイルからの検出クラス・インデックスを含む形状 [N] の tf.int テンソル。- detection_scores: 検出スコアを含む形状 [N] の tf.float32 テンソル。- detection_masks: [batch, max_detections, mask_height, mask_width] テンソル。検出マスクにはピクセル単位のシグモイド・スコア・コンバーターが適用されていることに注意してください。
モデルの入力、出力、およびその形式の詳細については、TensorFlow ハブのモデルの概要ページを参照してください。
重要な点として、detection_boxes、detection_classes、detection_scores、detection_masks の値は互いに対応しており、最高の検出スコアの順に並べられています:
最初の検出マスクは、最初の検出クラスと最初の (そして最高の) 検出スコアに対応します。
model_inputs = compiled_model.inputs
model_outputs = compiled_model.outputs
print("Model inputs count:", len(model_inputs))
print("Model inputs:")
for _input in model_inputs:
print(" ", _input)
print("Model outputs count:", len(model_outputs))
print("Model outputs:")
for output in model_outputs:
print(" ", output)Model inputs count: 1
Model inputs:
<ConstOutput: names[input_tensor] shape[1,?,?,3] type: u8>
Model outputs count: 23
Model outputs:
<ConstOutput: names[] shape[49152,4] type: f32>
<ConstOutput: names[box_classifier_features] shape[300,9,9,1536] type: f32>
<ConstOutput: names[] shape[4] type: f32>
<ConstOutput: names[mask_predictions] shape[100,90,33,33] type: f32>
<ConstOutput: names[num_detections] shape[1] type: f32>
<ConstOutput: names[num_proposals] shape[1] type: f32>
<ConstOutput: names[proposal_boxes] shape[1,?,..8] type: f32>
<ConstOutput: names[proposal_boxes_normalized, final_anchors] shape[1,?,..8] type: f32>
<ConstOutput: names[raw_detection_boxes] shape[1,300,4] type: f32>
<ConstOutput: names[raw_detection_scores] shape[1,300,91] type: f32>
<ConstOutput: names[refined_box_encodings] shape[300,90,4] type: f32>
<ConstOutput: names[rpn_box_encodings] shape[1,49152,4] type: f32>
<ConstOutput: names[class_predictions_with_background] shape[300,91] type: f32>
<ConstOutput: names[rpn_box_predictor_features] shape[1,64,64,512] type: f32>
<ConstOutput: names[rpn_features_to_crop] shape[1,64,64,1088] type: f32>
<ConstOutput: names[rpn_objectness_predictions_with_background] shape[1,49152,2] type: f32>
<ConstOutput: names[detection_anchor_indices] shape[1,?] type: f32>
<ConstOutput: names[detection_boxes] shape[1,?,..8] type: f32>
<ConstOutput: names[detection_classes] shape[1,?] type: f32>
<ConstOutput: names[detection_masks] shape[1,100,33,33] type: f32>
<ConstOutput: names[detection_multiclass_scores] shape[1,?,..182] type: f32>
<ConstOutput: names[detection_scores] shape[1,?] type: f32>
<ConstOutput: names[proposal_boxes_normalized, final_anchors] shape[1,?,..8] type: f32>テスト推論用の画像を取得#
画像を読み込んで保存します:
image_path = Path("./data/coco_bike.jpg")
download_file(
url="https://storage.openvinotoolkit.org/repositories/openvino_notebooks/data/data/image/coco_bike.jpg",
filename=image_path.name,
directory=image_path.parent,
);data/coco_bike.jpg: 0%| | 0.00/182k [00:00<?, ?B/s]画像を読み取り、サイズを変更して、ネットワークの入力形状に変換します:
# 画像を読み込み
image = cv2.imread(filename=str(image_path))
# ネットワークは RGB 形式の画像を想定
image = cv2.cvtColor(image, code=cv2.COLOR_BGR2RGB)
# ネットワーク入力の形状に合わせて画像のサイズを変更
resized_image = cv2.resize(src=image, dsize=(255, 255))
# 画像にバッチ次元を追加
network_input_image = np.expand_dims(resized_image, 0)
# 画像を表示
plt.imshow(image)<matplotlib.image.AxesImage at 0x7f9df57e55b0>
推論を実行#
inference_result = compiled_model(network_input_image)テスト画像に対するモデル推論の後、結果からインスタンス・セグメント化データを抽出できます。モデル結果のさらなる視覚化には、detection_boxes、detection_masks、detection_classes および detection_scores 出力が使用されます。
detection_boxes = compiled_model.output("detection_boxes")
image_detection_boxes = inference_result[detection_boxes]
print("image_detection_boxes:", image_detection_boxes.shape)
detection_masks = compiled_model.output("detection_masks")
image_detection_masks = inference_result[detection_masks]
print("image_detection_masks:", image_detection_masks.shape)
detection_classes = compiled_model.output("detection_classes")
image_detection_classes = inference_result[detection_classes]
print("image_detection_classes:", image_detection_classes.shape)
detection_scores = compiled_model.output("detection_scores")
image_detection_scores = inference_result[detection_scores]
print("image_detection_scores:", image_detection_scores.shape)
num_detections = compiled_model.output("num_detections")
image_num_detections = inference_result[num_detections]
print("image_detections_num:", image_num_detections)
# あるいは、`.get()` メソッドを使用してモデル出力名で推論結果データを抽出することもできます。
assert (inference_result[detection_boxes] == inference_result.get("detection_boxes")).all(), "extracted inference result data should be equal"image_detection_boxes: (1, 100, 4)
image_detection_masks: (1, 100, 33, 33)
image_detection_classes: (1, 100)
image_detection_scores: (1, 100)
image_detections_num: [100.]推論結果の可視化#
推論結果を視覚化するためのユーティリティー関数を定義します
import random
from typing import Optional
def add_detection_box(box: np.ndarray, image: np.ndarray, mask: np.ndarray, label: Optional[str] = None) -> np.ndarray:
"""
Helper function for adding single bounding box to the image
Parameters
----------
box : np.ndarray
Bounding box coordinates in format [ymin, xmin, ymax, xmax]
image : np.ndarray
The image to which detection box is added
mask: np.ndarray
Segmentation mask in format (H, W)
label : str, optional
Detection box label string, if not provided will not be added to result image (default is None)
Returns
-------
np.ndarray
NumPy array including image, detection box, and segmentation mask
"""
ymin, xmin, ymax, xmax = box
point1, point2 = (int(xmin), int(ymin)), (int(xmax), int(ymax))
box_color = [random.randint(0, 255) for _ in range(3)]
line_thickness = round(0.002 * (image.shape[0] + image.shape[1]) / 2) + 1
result = cv2.rectangle(
img=image,
pt1=point1,
pt2=point2,
color=box_color,
thickness=line_thickness,
lineType=cv2.LINE_AA,
)
if label:
font_thickness = max(line_thickness - 1, 1)
font_face = 0
font_scale = line_thickness / 3
font_color = (255, 255, 255)
text_size = cv2.getTextSize(
text=label,
fontFace=font_face,
fontScale=font_scale,
thickness=font_thickness,
)[0]
# 長方形の座標を計算
rectangle_point1 = point1
rectangle_point2 = (point1[0] + text_size[0], point1[1] - text_size[1] - 3)
# 塗りつぶされた四角形を追加
result = cv2.rectangle(
img=result,
pt1=rectangle_point1,
pt2=rectangle_point2,
color=box_color,
thickness=-1,
lineType=cv2.LINE_AA,
)
# テキストの位置を計算
text_position = point1[0], point1[1] - 3
# 塗りつぶされた四角形にラベル付きのテキストを追加
result = cv2.putText(
img=result,
text=label,
org=text_position,
fontFace=font_face,
fontScale=font_scale,
color=font_color,
thickness=font_thickness,
lineType=cv2.LINE_AA,
)
mask_img = mask[:, :, np.newaxis] * box_color
result = cv2.addWeighted(result, 1, mask_img.astype(np.uint8), 0.6, 0)
return resultdef get_mask_frame(box, frame, mask):
"""
Transform a binary mask to fit within a specified bounding box in a frame using perspective transformation.
Args:
box (tuple): A bounding box represented as a tuple (y_min, x_min, y_max, x_max).
frame (numpy.ndarray): The larger frame or image where the mask will be placed.
mask (numpy.ndarray): A binary mask image to be transformed.
Returns:
numpy.ndarray: A transformed mask image that fits within the specified bounding box in the frame.
"""
x_min = frame.shape[1] * box[1]
y_min = frame.shape[0] * box[0]
x_max = frame.shape[1] * box[3]
y_max = frame.shape[0] * box[2]
rect_src = np.array(
[
[0, 0],
[mask.shape[1], 0],
[mask.shape[1], mask.shape[0]],
[0, mask.shape[0]],
],
dtype=np.float32,
)
rect_dst = np.array(
[[x_min, y_min], [x_max, y_min], [x_max, y_max], [x_min, y_max]],
dtype=np.float32,
)
M = cv2.getPerspectiveTransform(rect_src[:, :], rect_dst[:, :])
mask_frame = cv2.warpPerspective(mask, M, (frame.shape[1], frame.shape[0]), flags=cv2.INTER_CUBIC)
return mask_framefrom typing import Dict
from openvino.runtime.utils.data_helpers import OVDict
def visualize_inference_result(
inference_result: OVDict,
image: np.ndarray,
labels_map: Dict,
detections_limit: Optional[int] = None,
):
"""
Helper function for visualizing inference result on the image
Parameters
----------
inference_result : OVDict
Result of the compiled model inference on the test image
image : np.ndarray
Original image to use for visualization
labels_map : Dict
Dictionary with mappings of detection classes numbers and its names
detections_limit : int, optional
Number of detections to show on the image, if not provided all detections will be shown (default is None)
"""
detection_boxes = inference_result.get("detection_boxes")
detection_classes = inference_result.get("detection_classes")
detection_scores = inference_result.get("detection_scores")
num_detections = inference_result.get("num_detections")
detection_masks = inference_result.get("detection_masks")
detections_limit = int(min(detections_limit, num_detections[0]) if detections_limit is not None else num_detections[0])
# 検出ボックスの座標を元の画像サイズに正規化
original_image_height, original_image_width, _ = image.shape
normalized_detection_boxes = detection_boxes[0, :detections_limit] * [
original_image_height,
original_image_width,
original_image_height,
original_image_width,
]
result = np.copy(image)
for i in range(detections_limit):
detected_class_name = labels_map[int(detection_classes[0, i])]
score = detection_scores[0, i]
mask = detection_masks[0, i]
mask_reframed = get_mask_frame(detection_boxes[0, i], image, mask)
mask_reframed = (mask_reframed > 0.5).astype(np.uint8)
label = f"{detected_class_name} {score:.2f}"
result = add_detection_box(
box=normalized_detection_boxes[i],
image=result,
mask=mask_reframed, label=label,
)
plt.imshow(result)このノートブックで使用されている TensorFlow インスタンス・セグメント化モデル (mask_rcnn_inception_resnet_v2_1024x1024) は、91 クラスの COCO 2017 データセットでトレーニングされました。視覚化エクスペリエンスを向上させるため、クラス番号やインデックスの代わりに、人間が判読できるクラス名を持つ COCO データセット・ラベルを使用できます。
COCO データセットのクラスラベルは、Open Model Zoo からダウンロードできます:
coco_labels_file_path = Path("./data/coco_91cl.txt")
download_file(
url="https://raw.githubusercontent.com/openvinotoolkit/open_model_zoo/master/data/dataset_classes/coco_91cl.txt",
filename=coco_labels_file_path.name,
directory=coco_labels_file_path.parent,
);data/coco_91cl.txt: 0%| | 0.00/421 [00:00<?, ?B/s]次に、ダウンロードしたファイルから検出クラスの番号とその名前のマッピングを含む辞書 coco_labels_map を作成する必要があります:
with open(coco_labels_file_path, "r") as file:
coco_labels = file.read().strip().split("\n")
coco_labels_map = dict(enumerate(coco_labels, 1))
print(coco_labels_map){1: 'person', 2: 'bicycle', 3: 'car', 4: 'motorcycle', 5: 'airplan', 6: 'bus', 7: 'train', 8: 'truck', 9: 'boat', 10: 'traffic light', 11: 'fire hydrant', 12: 'street sign', 13: 'stop sign', 14: 'parking meter', 15: 'bench', 16: 'bird', 17: 'cat', 18: 'dog', 19: 'horse', 20: 'sheep', 21: 'cow', 22: 'elephant', 23: 'bear', 24: 'zebra', 25: 'giraffe', 26: 'hat', 27: 'backpack', 28: 'umbrella', 29: 'shoe', 30: 'eye glasses', 31: 'handbag', 32: 'tie', 33: 'suitcase', 34: 'frisbee', 35: 'skis', 36: 'snowboard', 37: 'sports ball', 38: 'kite', 39: 'baseball bat', 40: 'baseball glove', 41: 'skateboard', 42: 'surfboard', 43: 'tennis racket', 44: 'bottle', 45: 'plate', 46: 'wine glass', 47: 'cup', 48: 'fork', 49: 'knife', 50: 'spoon', 51: 'bowl', 52: 'banana', 53: 'apple', 54: 'sandwich', 55: 'orange', 56: 'broccoli', 57: 'carrot', 58: 'hot dog', 59: 'pizza', 60: 'donut', 61: 'cake', 62: 'chair', 63: 'couch', 64: 'potted plant', 65: 'bed', 66: 'mirror', 67: 'dining table', 68: 'window', 69: 'desk', 70: 'toilet', 71: 'door', 72: 'tv', 73: 'laptop', 74: 'mouse', 75: 'remote', 76: 'keyboard', 77: 'cell phone', 78: 'microwave', 79: 'oven', 80: 'toaster', 81: 'sink', 82: 'refrigerator', 83: 'blender', 84: 'book', 85: 'clock', 86: 'vase', 87: 'scissors', 88: 'teddy bear', 89: 'hair drier', 90: 'toothbrush', 91: 'hair brush'}最後に、元のテスト画像でモデル推論結果を視覚化する準備が整いました:
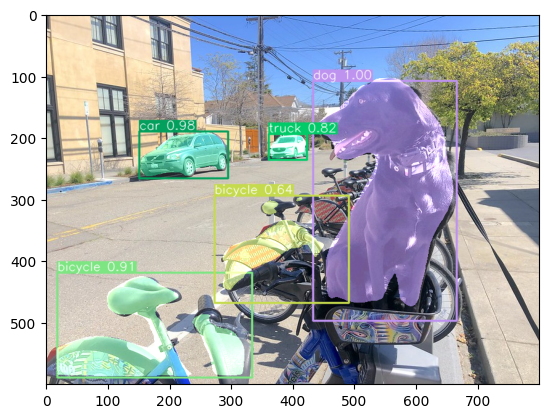
visualize_inference_result(
inference_result=inference_result,
image=image,
labels_map=coco_labels_map,
detections_limit=5,
)
次のステップ#
このセクションでは、OpenVINO を使用してアプリケーションのパフォーマンスをさらに向上させる方法に関する提案を示します。
非同期推論パイプライン#
非同期 API の主な利点は、デバイスが推論でビジー状態のときに、アプリケーションが現在の推論が完了するのを待つのではなく、他のタスク (例えば、入力の入力や他の要求のスケジュール設定) を並行して実行できることです。openvino を使用して非同期推論を実行する方法を理解するには、非同期 API のチュートリアルを参照してください。
モデルへの統合前処理#
前処理 API を使用すると、前処理をモデルの一部にすることができ、アプリケーション・コードと追加の画像処理ライブラリーへの依存関係が削減されます。前処理 API の主な利点は、前処理手順が実行グラフに統合され、アプリケーションの一部として常に CPU 上で実行されるのではなく、選択したデバイス (CPU/GPU など) 上で実行されることです。これにより、選択したデバイスの使用率が向上します。
詳細については、前処理の最適化チュートリアルと前処理 API の概要を参照してください。