MusicGen と OpenVINO による制御可能な音楽生成#
この Jupyter ノートブックはオンラインで起動でき、ブラウザーのウィンドウで対話型環境を開きます。ローカルにインストールすることもできます。次のオプションのいずれかを選択します:



MusicGen は、テキストの説明や音声プロンプトに基づいて高品質の音楽サンプルを生成できる、単一ステージの自己回帰トランスフォーマー・モデルです。テキストプロンプトはテキスト・エンコーダー・モデル (T5) に渡され、一連の隠し状態表現が取得されます。これらの隠し状態は MusicGen に送られ、個別のオーディオトークン (オーディオコード) を予測します。最後に、オーディオトークンはオーディオ圧縮モデル (EnCodec) を使用してデコードされ、オーディオ波形が復元されます。
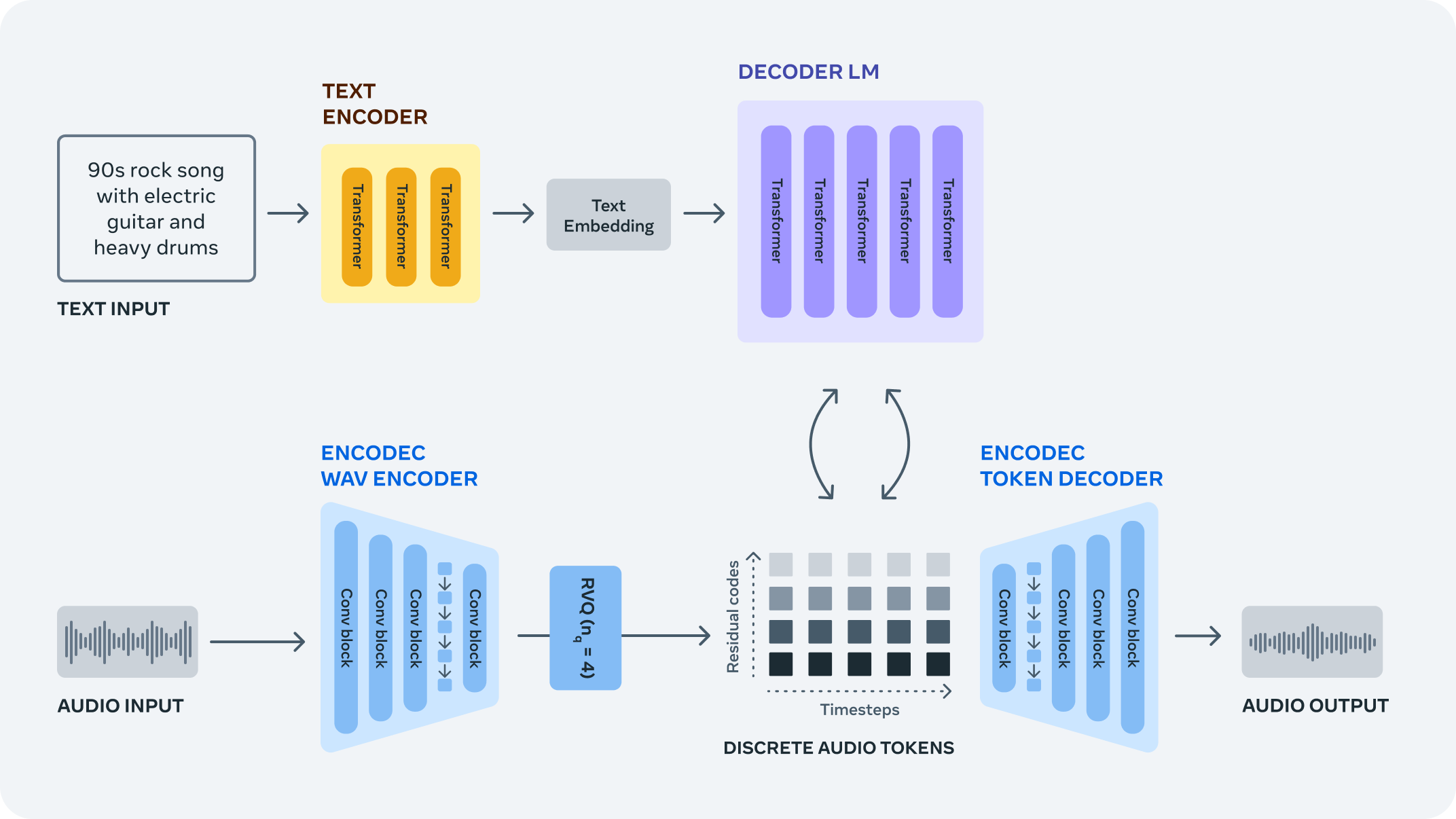
パイプライン#
MusicGen モデルは、テキスト/オーディオプロンプトの自己教師付きセマンティック表現を必要としません。効率的なトークン・インターリーブ・パターンを使用して、圧縮された個別の音楽表現の複数のストリームに対して動作するため、コードブックのセットを予測するのに複数のモデルをカスケードする必要がありません (階層的またはアップサンプリングなど)。音楽生成を扱う従来のモデルとは異なり、単一のフォワードパスですべてのコードブックを生成できます。
このチュートリアルでは、OpenVINO を使用して MusicGen モデルを実行する方法について説明します。
Hugging Face トランスフォーマー・ライブラリーのモデル実装を使用します。
目次:
必要条件#
要件をインストール#
%pip install -q "openvino>=2023.3.0"
%pip install -q "torch>=2.1" "gradio>=4.19" "transformers" packaging --extra-index-url https://download.pytorch.org/whl/cpuNote: you may need to restart the kernel to use updated packages.
Note: you may need to restart the kernel to use updated packages.インポート#
from collections import namedtuple
from functools import partial
import gc
from pathlib import Path
from typing import Optional, Tuple
import warnings
from IPython.display import Audio
import openvino as ov
import numpy as np
import torch
from torch.jit import TracerWarning
from transformers import AutoProcessor, MusicgenForConditionalGeneration
from transformers.modeling_outputs import (
BaseModelOutputWithPastAndCrossAttentions,
CausalLMOutputWithCrossAttentions,
)
# トレース警告を無視
warnings.filterwarnings("ignore", category=TracerWarning)2024-07-13 01:10:20.411100: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on.You may see slightly different numerical results due to floating-point round-off errors from different computation orders.To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0. 2024-07-13 01:10:20.446165: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.2024-07-13 01:10:21.046633: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/transformers/utils/generic.py:311: UserWarning: torch.utils._pytree._register_pytree_node is deprecated.Please use torch.utils._pytree.register_pytree_node instead. torch.utils._pytree._register_pytree_node( /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/transformers/utils/generic.py:311: UserWarning: torch.utils._pytree._register_pytree_node is deprecated.Please use torch.utils._pytree.register_pytree_node instead. torch.utils._pytree._register_pytree_node(
HF トランスフォーマーの MusicGen#
Meta AI の MusicGen を利用するには、Hugging Face Transformers パッケージを使用します。Transformers パッケージは MusicgenForConditionalGeneration クラスを公開し、モデルのインスタンス化と重みの読み込みを簡素化します。以下のコードは、MusicgenForConditionalGeneration を作成し、テキスト条件付きの音楽サンプルを生成する方法を示しています。
import sys
from packaging.version import parse
if sys.version_info < (3, 8):
import importlib_metadata
else:
import importlib.metadata as importlib_metadata
loading_kwargs = {}
if parse(importlib_metadata.version("transformers")) >= parse("4.40.0"):
loading_kwargs["attn_implementation"] = "eager"
# パイプラインをロード
model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small", torchscript=True,
return_dict=False, **loading_kwargs)/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/huggingface_hub/file_download.py:1132: FutureWarning: resume_download is deprecated and will be removed in version 1.0.0.Downloads always resume when possible.If you want to force a new download, use force_download=True.
warnings.warn(
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/transformers/utils/generic.py:311: UserWarning: torch.utils._pytree._register_pytree_node is deprecated.Please use torch.utils._pytree.register_pytree_node instead.
torch.utils._pytree._register_pytree_node(
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/torch/nn/utils/weight_norm.py:28: UserWarning: torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.
warnings.warn("torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.")
下のセルでは、ユーザーは希望する希望する音楽サンプルの長さを自由に変更できます。
sample_length = 8 # 秒
n_tokens = sample_length * model.config.audio_encoder.frame_rate + 3
sampling_rate = model.config.audio_encoder.sampling_rate
print("Sampling rate is", sampling_rate, "Hz")
model.to("cpu")
model.eval();Sampling rate is 32000 Hz元のパイプライン推論#
テキスト前処理は、モデルに入力するテキストプロンプトを準備し、processor オブジェクトがこのステップを抽象化します。テキストのトークン化は内部で実行され、単語にトークンまたは ID が割り当てられます。つまり、トークン ID はモデル語彙内の単語のインデックスにすぎません。これは、モデルが文のコンテキストを理解するのに役立ちます。
processor = AutoProcessor.from_pretrained("facebook/musicgen-small")
inputs = processor(
text=["80s pop track with bassy drums and synth"],
return_tensors="pt",
)
audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=n_tokens)
Audio(audio_values[0].cpu().numpy(), rate=sampling_rate)モデルを OpenVINO 中間表現 (IR) 形式に変換#
モデル・トランスフォーメーション API を使用すると、PyTorch モデルを直接変換できます。openvino.convert_model メソッドを使用して、モデルの OpenVINO IR バージョンを取得します。このメソッドには、モデルトレース用のモデル・オブジェクトとサンプル入力が必要です。内部的には、コンバーターは PyTorch JIT コンパイラーを使用して、凍結されたモデルグラフを構築します。
パイプラインは次の 3 つの重要な部分で構成されます:
ユーザーのプロンプトを、次のモデルである MusicGen デコーダーが利用できる潜在空間内のベクトルに変換する T5 テキスト・エンコーダー。
オーディオトークン (コード) を自動回帰的に生成する MusicGen 言語モデル。
EnCodec モデル (ここではデコーダー部分のみを使用) は、MusicGen 言語モデルによって予測されたオーディオトークンからオーディオ波形をデコードするために使用されます。
各モデルを段階的に変換してみましょう。
0. 変数を設定#
models_dir = Path("./models")
t5_ir_path = models_dir / "t5.xml"
musicgen_0_ir_path = models_dir / "mg_0.xml"
musicgen_ir_path = models_dir / "mg.xml"
audio_decoder_ir_path = models_dir / "encodec.xml"1. テキスト・エンコーダーを変換#
テキスト・エンコーダーは、“大音量のギターと激しいドラムが特徴の 90 年代のロックソング” などの入力プロンプトを、次のモデルに渡すことができる埋め込み空間に変換する役割を担います。通常、これは、入力トークンのシーケンスをテキスト埋め込みのシーケンスにマッピングするトランスフォーマー・ベースのエンコーダーです。
テキスト・エンコーダーの入力は、トークナイザーによって処理されたテキストからのトークン・インデックスを含むテンソル input_ids と、一度に 1 つのプロンプトを処理するため無視される attention_mask で構成され、このベクトルは 1 つのみで構成されます。
以下の OpenVINO コンバーター (OVC) を使用して、PyTorch モデルを OpenVINO 中間表現形式 (IR) に変換します。これは、後で OpenVINO ランタイムで推論できます。
if not t5_ir_path.exists():
t5_ov = ov.convert_model(model.text_encoder, example_input={"input_ids": inputs["input_ids"]})
ov.save_model(t5_ov, t5_ir_path)
del t5_ov
gc.collect()WARNING:tensorflow:Please fix your imports.Module tensorflow.python.training.tracking.base has been moved to tensorflow.python.trackable.base.The old module will be deleted in version 2.11.[ WARNING ] Please fix your imports.Module %s has been moved to %s.The old module will be deleted in version %s.['input_ids']2. MusicGen 言語モデルの変換#
このモデルはパイプライン全体の中核であり、埋め込まれたテキスト表現を受け取り、実際の音楽にデコードできるオーディオコードを生成します。このモデルは、低いフレームレートで音楽を効率的に表現する、事前トレーニング済みのコードブックからサンプリングされたトークンであるオーディオコードのストリームをいくつか出力します。このモデルは、革新的なコード・インターリーブ戦略を採用しており、単一ステージでの生成を可能にします。
0 番目の生成ステップでは、モデルは、テキスト・エンコーダーによって提供されたオーディオコードのインデックスを表す input_ids、encoder_hidden_states、および encoder_attention_mask を受け入れます。
# モデル設定 `torchscript` を True に設定すると、モデルは出力としてタプルを返します。
model.decoder.config.torchscript = True
if not musicgen_0_ir_path.exists():
decoder_input = {
"input_ids": torch.ones(8, 1, dtype=torch.int64),
"encoder_hidden_states": torch.ones(2, 12, 1024, dtype=torch.float32),
"encoder_attention_mask": torch.ones(2, 12, dtype=torch.int64),
}
mg_ov_0_step = ov.convert_model(model.decoder, example_input=decoder_input)
ov.save_model(mg_ov_0_step, musicgen_0_ir_path)
del mg_ov_0_step
gc.collect()['input_ids', 'encoder_hidden_states', 'encoder_attention_mask']以降の反復では、モデルには注意ブロックの以前の出力を含む past_key_values 引数も提供され、計算を節約できます。しかし、これは、モデルの forward メソッドのシグネチャーが変更されたことを意味します。OpenVINO IR のモデルでは計算グラフが固定されており、オプションの引数が許可されていないため、MusicGen モデルは入力数を増やしてもう一度変換する必要があります。
# example_input 辞書に引数を追加
if not musicgen_ir_path.exists():
# 変換されたモデル署名に `past_key_values` を追加
decoder_input["past_key_values"] = tuple(
[
(
torch.ones(2, 16, 1, 64, dtype=torch.float32),
torch.ones(2, 16, 1, 64, dtype=torch.float32),
torch.ones(2, 16, 12, 64, dtype=torch.float32),
torch.ones(2, 16, 12, 64, dtype=torch.float32),
)
]
* 24
)
mg_ov = ov.convert_model(model.decoder, example_input=decoder_input)
for input in mg_ov.inputs[3:]:
input.get_node().set_partial_shape(ov.PartialShape([-1, 16, -1, 64]))
input.get_node().set_element_type(ov.Type.f32)
mg_ov.validate_nodes_and_infer_types()
ov.save_model(mg_ov, musicgen_ir_path)
del mg_ov
gc.collect()['input_ids', 'encoder_hidden_states', 'encoder_attention_mask', 'past_key_values']3. オーディオデコーダーの変換#
EnCodec モデルの一部であるオーディオデコーダーは、MusicGen デコーダーによって予測されたオーディオトークンからオーディオ波形を復元するのに使用されます。モデルの詳細については、対応する OpenVINO の例を参照してください。
if not audio_decoder_ir_path.exists():
class AudioDecoder(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = model
def forward(self, output_ids):
return self.model.decode(output_ids, [None])
audio_decoder_input = {"output_ids": torch.ones((1, 1, 4, n_tokens - 3), dtype=torch.int64)}
with torch.no_grad():
audio_decoder_ov = ov.convert_model(AudioDecoder(model.audio_encoder), example_input=audio_decoder_input)
ov.save_model(audio_decoder_ov, audio_decoder_ir_path)
del audio_decoder_ov
gc.collect()['output_ids']変換したモデルを元のパイプラインに埋め込み#
OpenVINO™ ランタイム Python API は、モデルを OpenVINO IR 形式でコンパイルするために使用されます。Core クラスは、OpenVINO ランタイム API へのアクセスを提供します。Core クラスのインスタンスである core オブジェクトは API を表し、モデルをコンパイルするために使用されます。
core = ov.Core()OpenVINO を使用してモデル推論に使用されるデバイスをドロップダウン・リストから選択します:
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value="AUTO",
description="Device:",
disabled=False,
)
deviceDropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')OpenVINO モデルを元のパイプラインに適合#
ここでは、元の推論パイプラインに埋め込む 3 つの OpenVINO モデルすべてに対してラッパークラスを作成します。OV モデルを適応させる際に考慮すべき事項をいくつか示します: - 元のパイプラインから渡されたパラメーターがコンパイルされた OV モデルに適切に転送されることを確認します。OV モデルでは入力引数の一部のみが使用され、一部は無視される場合があり、引数を別のデータタイプに変換したり、タプルや辞書などの一部のデータ構造をアンラップしたりする必要がある場合があります。- ラッパークラスが期待どおりの形式でパイプラインに結果を返すことを保証します。以下の例では、OV モデルの出力を HF リポジトリーで宣言された特別なクラスにパックする方法がわかります。- モデルを呼び出すため元のパイプラインで使用されるモデルメソッドに注意してください。これは forward メソッドではない可能性があります。OV モデル推論を decode メソッドにラップする方法は、AudioDecoderWrapper を参照してください。
class TextEncoderWrapper(torch.nn.Module):
def __init__(self, encoder_ir, config):
super().__init__()
self.encoder = core.compile_model(encoder_ir, device.value)
self.config = config
def forward(self, input_ids, **kwargs):
last_hidden_state = self.encoder(input_ids)[self.encoder.outputs[0]]
last_hidden_state = torch.tensor(last_hidden_state)
return BaseModelOutputWithPastAndCrossAttentions(last_hidden_state=last_hidden_state)
class MusicGenWrapper(torch.nn.Module):
def __init__(
self,
music_gen_lm_0_ir,
music_gen_lm_ir,
config,
num_codebooks,
build_delay_pattern_mask,
apply_delay_pattern_mask,
):
super().__init__()
self.music_gen_lm_0 = core.compile_model(music_gen_lm_0_ir, device.value)
self.music_gen_lm = core.compile_model(music_gen_lm_ir, device.value)
self.config = config self.num_codebooks = num_codebooks
self.build_delay_pattern_mask = build_delay_pattern_mask
self.apply_delay_pattern_mask = apply_delay_pattern_mask
def forward(
self,
input_ids: torch.LongTensor = None,
encoder_hidden_states: torch.FloatTensor = None,
encoder_attention_mask: torch.LongTensor = None,
past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
**kwargs
):
if past_key_values is None:
model = self.music_gen_lm_0
arguments = (input_ids, encoder_hidden_states, encoder_attention_mask)
else:
model = self.music_gen_lm
arguments = (
input_ids,
encoder_hidden_states,
encoder_attention_mask,
*past_key_values,
)
output = model(arguments)
return CausalLMOutputWithCrossAttentions(
logits=torch.tensor(output[model.outputs[0]]),
past_key_values=tuple([output[model.outputs[i]] for i in range(1, 97)]),
)
class AudioDecoderWrapper(torch.nn.Module):
def __init__(self, decoder_ir, config):
super().__init__()
self.decoder = core.compile_model(decoder_ir, device.value)
self.config = config
self.output_type = namedtuple("AudioDecoderOutput", ["audio_values"])
def decode(self, output_ids, audio_scales):
output = self.decoder(output_ids)[self.decoder.outputs[0]]
return self.output_type(audio_values=torch.tensor(output))ラッパー・オブジェクトを初期化し、HF パイプラインにロードします。
text_encode_ov = TextEncoderWrapper(t5_ir_path, model.text_encoder.config)
musicgen_decoder_ov = MusicGenWrapper(
musicgen_0_ir_path,
musicgen_ir_path,
model.decoder.config,
model.decoder.num_codebooks,
model.decoder.build_delay_pattern_mask,
model.decoder.apply_delay_pattern_mask,
)
audio_encoder_ov = AudioDecoderWrapper(audio_decoder_ir_path, model.audio_encoder.config)
del model.text_encoder
del model.decoder
del model.audio_encoder
gc.collect()
model.text_encoder = text_encode_ov
model.decoder = musicgen_decoder_ov
model.audio_encoder = audio_encoder_ov
def prepare_inputs_for_generation(
self,
decoder_input_ids,
past_key_values=None,
attention_mask=None,
head_mask=None,
decoder_attention_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
use_cache=None,
encoder_outputs=None, decoder_delay_pattern_mask=None,
guidance_scale=None,
**kwargs,
):
if decoder_delay_pattern_mask is None: (
decoder_input_ids,
decoder_delay_pattern_mask,
) = self.decoder.build_delay_pattern_mask(
decoder_input_ids,
self.generation_config.pad_token_id,
max_length=self.generation_config.max_length,
)
# 遅延パターンマスクを適用
decoder_input_ids = self.decoder.apply_delay_pattern_mask(decoder_input_ids, decoder_delay_pattern_mask)
if guidance_scale is not None and guidance_scale > 1:
# 分類器フリーのガイダンスのため、デコーダー引数をバッチ dim 全体に複製する必要があります
# (サンプリング前にこれらを分割します)
decoder_input_ids = decoder_input_ids.repeat((2, 1))
if decoder_attention_mask is not None:
decoder_attention_mask = decoder_attention_mask.repeat((2, 1))
if past_key_values is not None:
# past が使用されている場合は decoder_input_ids をカット
decoder_input_ids = decoder_input_ids[:, -1:]
return { "input_ids": None, # エンコーダー出力が定義されています。input_ids は必要ありません
"encoder_outputs": encoder_outputs,
"past_key_values": past_key_values,
"decoder_input_ids": decoder_input_ids,
"attention_mask": attention_mask,
"decoder_attention_mask": decoder_attention_mask,
"head_mask": head_mask,
"decoder_head_mask": decoder_head_mask,
"cross_attn_head_mask": cross_attn_head_mask,
"use_cache": use_cache,
}
model.prepare_inputs_for_generation = partial(prepare_inputs_for_generation, model)OpenVINO モデルを基にパイプラインを推測できるようになりました。
processor = AutoProcessor.from_pretrained("facebook/musicgen-small")
inputs = processor(
text=["80s pop track with bassy drums and synth"],
return_tensors="pt",
)
audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=n_tokens)
Audio(audio_values[0].cpu().numpy(), rate=sampling_rate)変換されたパイプラインを試す#
以下のデモアプリは Gradio パッケージを使用して作成されています
def _generate(prompt):
inputs = processor(
text=[
prompt,
],
padding=True,
return_tensors="pt",
)
audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=n_tokens)
waveform = audio_values[0].cpu().squeeze() * 2**15
return (sampling_rate, waveform.numpy().astype(np.int16))import gradio as gr
demo = gr.Interface(
_generate,
inputs=[
gr.Textbox(label="Text Prompt"),
],
outputs=["audio"],
examples=[
["80s pop track with bassy drums and synth"],
["Earthy tones, environmentally conscious, ukulele-infused, harmonic, breezy, easygoing, organic instrumentation, gentle grooves"],
["90s rock song with loud guitars and heavy drums"],
["Heartful EDM with beautiful synths and chords"],
],
allow_flagging="never",
)
try:
demo.launch(debug=False)
except Exception:
demo.launch(share=True, debug=False)
# リモートで起動する場合は、server_name と server_port を指定
# 例: `demo.launch(server_name='your server name', server_port='server port in int')`
# 詳細については、Gradio のドキュメントを参照してください: https://gradio.app/docs/ローカル URL で実行中: http://127.0.0.1:7860 パブリックリンクを作成するには、launch() で share=True を設定します。