数式認識 Python* デモ#

このデモでは、LaTeX 数式認識モデルを実行する方法を示します。これらのモデルを使用すると、画像から LaTeX 数式マークアップを取得できます。
注: バッチサイズ 1 のみがサポートされます。
どのように動作するか#
デモ・アプリケーションでは、2 つに分割された数式認識モデルが想定されています。すべてのモデルパーツは中間表現 (IR) 形式である必要があります。
最初のモデルは、画像から特徴を抽出し、デコーダーの最初のステップを準備するエンコーダーです。
1 つの入力は入力画像の
imgsです4 つの出力があります:
行エンコード出力 (
row_enc_out) は画像から特徴を抽出しますhiddenとcontextは LSTM の中間状態ですinit_0- エンコーダーの最初の状態
2 番目のモデルは、入力として受け取るデコーダーです:
row_enc_out- エンコーダーから抽出された画像の特徴状態コンテキストのデコード (
dec_st_c) とデコード状態非表示 (
dec_st_h) - LSTM の現在の状態output_prev- デコードステップの以前の出力 (初回はエンコーダーのinit_0)ターゲット (
tgt) - 前のトークン (初回はSTART_TOKEN) 2 番目のモデルは、デコードされたトークンがEND_TOKENであるか、式の長さが--max_formula_len未満になるまで実行され、デコードステップごとに 1 つのトークンが生成されます。
デモ・アプリケーションは、-i 引数で入力を受け取ります。以下を受け取ります:
単一の画像へのパス
画像が含まれるフォルダーへのパス
この場合、非対話型モードがトリガーされます。これは、デモが入力画像に対してモデルを実行し、数式を予測することを意味します。出力はコンソールまたはファイル (指定されている場合) に出力/保存されます
デバイス (Web カメラなど) の整数識別子、通常は 0。
ビデオファイルへのパス (.avi、.mp4 など)
これにより対話型モードがトリガーされます。これについては後で詳しく説明します。
語彙ファイルは、対応するモデル構成ディレクトリー下に提供されます。
非対話モード#
非対話型モードでは、入力を順番に処理することを前提としています。非対話型モードでのデモのワークフローは次のとおりです:
デモ・アプリケーションは、単一の画像を読み取るか、指定されたフォルダー内のすべての画像を反復処理して、ネットワークの入力画像ブロブ (
imgs) に収まるようにトリミングまたはサイズ変更して入力します。フォントのサイズを維持するために、トリミングとパディングが使用されます。画像ごとに、エンコーダーが画像から特徴を抽出します
式の長さが
--max_formula_len未満であるか、現在のトークンがEND_TOKENではない場合、デコードステップで新しいトークンが生成されます。-oパラメーターが指定されていると、デコードされたテキストをファイルまたはコンソールに出力し、(オプションで) 予測された数式を画像にレンダリングします。
LaTeX 数式の画像へのレンダリング#
デモ・アプリケーションによって予測された LaTeX 式を画像にレンダリングするオプションがあります。選択されているモード (対話型または非対話型) に関係なく、数式のレンダリングのプロセスは同一です。
レンダリングの要件#
Sympy パッケージには、オペレーティング・システムに LaTeX システムがインストールされている必要があります。Windows* の場合は MiKTeX* (ダウンロードしてインストールするだけ) を使用でき、Ubuntu/macOS の場合は TeX Live* を使用できます:
Ubuntu*:
apt-get update && apt-get install texlive
macOS*:
brew install texlive
RuntimeError: dvipng is not installed エラーが発生した場合は、このライブラリーをインストールする必要があります。Linux* では、
apt-get update && apt-get install dvipng で取得できます。また、standalone.cls ファイルが見つからないという問題が発生する可能性もありますが、texlive-latex-extra パッケージをインストールすることで解決できる場合があります。Linux* では、次のコマンドで実行できます:
apt-get install texlive-latex-extra
注: 他の LaTeX システムでも動作するはずです。
対話モード#
インターフェイスの例:

-i オプションを使用してデモ・アプリケーションを実行し、ビデオまたは Web カメラデバイス番号を引数 (通常は 0) として渡すと、上記のような画像のウィンドウがポップアップ表示されます。
対話型モードの使用例:
python formula_recognition_demo.py <required args> -i 0または
python formula_recognition_demo.py <required args> -i input_video.mp4ウィンドウには 4 つのセクションがあります:
赤い四角形がウィンドウの中央に配置されます。これは入力 “ターゲット” を示し、ユーザーがカメラを動かして式をキャプチャーできるようになります。
入力ターゲットの画像は二値化され、前処理されてネットワークに供給されます。前処理され二値化された画像がウィンドウの上部 (モデル入力ラベルの近く) に配置されます。
数式が十分な信頼スコアで予測される場合、前処理された画像のすぐ下 (予測ラベルの近く) に配置されます。
レンダリングが利用可能であり (詳細については前のステージを参照)、予測された式に LaTeX 文法エラーがない場合、その式はレンダリングされ、レンダリング・ラベルの近くに配置されます。
ナビゲーション・キー:
プログラムを終了するには、
qボタンを使用します入力 (赤) ウィンドウサイズを小さくするには、
oを使用します入力ウィンドウサイズを大きくするには、
pを使用します
全体のプロセスは非対話型モードと似ていますが、非同期で実行される点が異なります。これは、モデルの推論と数式のレンダリングがメインスレッドをブロックしないことを意味し、Web カメラからの画像はスムーズに移動できます。
注: デフォルトでは、Open Model Zoo のデモは BGR チャネル順序での入力を期待します。RGB 順序で動作するようにモデルをトレーニングした場合は、サンプルまたはデモ・アプリケーションでデフォルトのチャネル順序を手動で再配置するか、
--reverse_input_channels引数を指定したモデル・オプティマイザー・ツールを使用してモデルを再変換する必要があります。引数の詳細については、[前処理計算の埋め込み](@ref openvino_docs_MO_DG_Additional_Optimization_Use_Cases) の入力チャネルを反転するセクションを参照してください。
デモには 2 つの前処理タイプがあります: ターゲットの形状に合わせて切り取ってパディングする方法と、ターゲットの形状に合わせてサイズを変更してパディングする方法です。2 つの前処理タイプは、具体的なフォントサイズでトレーニングされたモデルとして 2 つの異なるデータセットに使用されるため、より大きなフォントサイズの入力でモデルを実行したい場合 (例: 入力が 12Mpx で撮影され、モデルが ~3Mpx でスキャンを模倣するようにトレーニングされた場合)、入力のサイズを変更して、トレインセットのようなフォントサイズにする必要があります。ターゲットのフォントサイズの例:
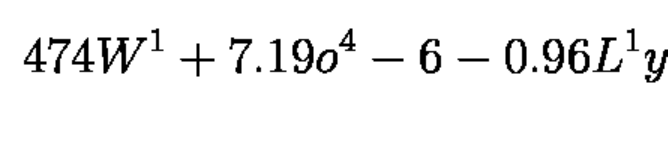
実行の準備#
デモでサポートされるモデルリストは、<omz_dir>/demos/formula_recognition_demo/python/models.lst ファイルにあります。このファイルは、モデル・ダウンローダーおよびコンバーターのパラメーターとして使用され、モデルをダウンロードし、必要に応じて OpenVINO IR 形式 (*.xml + *.bin) に変換できます。
モデル・ダウンローダーの使用例:
omz_downloader --list models.lstモデル・コンバーターの使用例:
omz_converter --list models.lstサポートされるモデル#
formula-recognition-medium-scan-0001-im2latex-decoder
formula-recognition-medium-scan-0001-im2latex-encoder
formula-recognition-polynomials-handwritten-0001-decoder
formula-recognition-polynomials-handwritten-0001-encoder
注: 各種デバイス向けのモデル推論サポートの詳細については、インテルの事前トレーニング・モデルのデバイスサポートとパブリックの事前トレーニング・モデルのデバイスサポートの表を参照してください。
実行する#
-h オプションを指定してアプリケーションを実行すると、使用方法が表示されます:
usage: formula_recognition_demo.py [-h]
-m_encoder M_ENCODER -m_decoder M_DECODER
-i INPUT [-no_show]
[-o OUTPUT_FILE] -v VOCAB_PATH [--max_formula_len MAX_FORMULA_LEN]
[-t CONF_THRESH] [-d DEVICE] [--resolution RESOLUTION RESOLUTION]
[--preprocessing_type {crop,resize}] [--imgs_layer IMGS_LAYER] [--row_enc_out_layer ROW_ENC_OUT_LAYER] [--hidden_layer HIDDEN_LAYER] [--context_layer CONTEXT_LAYER] [--init_0_layer INIT_0_LAYER]
[--dec_st_c_layer DEC_ST_C_LAYER] [--dec_st_h_layer DEC_ST_H_LAYER] [--dec_st_c_t_layer DEC_ST_C_T_LAYER] [--dec_st_h_t_layer DEC_ST_H_T_LAYER] [--output_layer OUTPUT_LAYER]
[--output_prev_layer OUTPUT_PREV_LAYER] [--logit_layer LOGIT_LAYER] [--tgt_layer TGT_LAYER]
Options:
-h, --help Show this help message and exit.
-m_encoder M_ENCODER Required. Path to an .xml file with a trained encoder part of the model
-m_decoder M_DECODER Required. Path to an .xml file with a trained decoder part of the model
-i INPUT, --input INPUT
Required. Path to a folder with images, path to an image files, integer identifier of the camera or path to the video.See README.md for details.
-no_show, --no_show Optional. Suppress pop-up window with rendered formula.
-o OUTPUT_FILE, --output_file OUTPUT_FILE
Optional. Path to file where to store output. If not mentioned, result will be stored in the console.
-v VOCAB_PATH, --vocab_path VOCAB_PATH
Required. Path to vocab file to construct meaningful phrase
--max_formula_len MAX_FORMULA_LEN
Optional.Defines maximum length of the formula (number of tokens to decode)
-t CONF_THRESH, --conf_thresh CONF_THRESH
Optional.Probability threshold to treat model prediction as meaningful
-d DEVICE, --device DEVICE
Optional.Specify a device to infer on (the list of available devices is shown below).Use '-d HETERO:<comma-separated_devices_list>' format to specify HETERO plugin.Use '-d MULTI:<comma-separated_devices_list>’
format to specify MULTI plugin.Default is CPU
--resolution RESOLUTION RESOLUTION
Optional. Resolution of the demo application window. Default: 1280 720
--preprocessing_type {crop,resize}
Optional. Type of the preprocessing
--imgs_layer IMGS_LAYER
Optional. Encoder input name for images. See README for details.
--row_enc_out_layer ROW_ENC_OUT_LAYER
Optional. Encoder output key for row_enc_out. See README for details.
--hidden_layer HIDDEN_LAYER
Optional. Encoder output key for hidden. See README for details.
--context_layer CONTEXT_LAYER
Optional. Encoder output key for context. See README for details.
--init_0_layer INIT_0_LAYER
Optional. Encoder output key for init_0. See README for details.
--dec_st_c_layer DEC_ST_C_LAYER
Optional. Decoder input key for dec_st_c. See README for details.
--dec_st_h_layer DEC_ST_H_LAYER
Optional. Decoder input key for dec_st_h. See README for details.
--dec_st_c_t_layer DEC_ST_C_T_LAYER
Optional. Decoder output key for dec_st_c_t. See README for details.
--dec_st_h_t_layer DEC_ST_H_T_LAYER
Optional. Decoder output key for dec_st_h_t. See README for details.
--output_layer OUTPUT_LAYER
Optional. Decoder output key for output. See README for details.
--output_prev_layer OUTPUT_PREV_LAYER
Optional. Decoder input key for output_prev. See README for details.
--logit_layer LOGIT_LAYER
Optional. Decoder output key for logit. See README for details.
--tgt_layer TGT_LAYER
Optional. Decoder input key for tgt. See README for details.オプションの空のリストを指定してアプリケーションを実行すると、短い使用法メッセージとエラーメッセージが表示されます。
例えば、事前トレーニングされた formula-recognition-medium-scan-0001 モデルを使用して推論を行うには、次のコマンドを実行します:
python formula_recognition_demo.py \
-i sample.png \
-m_encoder <path_to_models>/formula-recognition-medium-scan-0001-im2latex-encoder.xml \
-m_decoder <path_to_models>/formula-recognition-medium-scan-0001-im2latex-decoder.xml \
--vocab_path <models_dir>/models/intel/formula-recognition-medium-scan-0001/formula-recognition-medium-scan-0001-im2latex-decoder/vocab.json \
--preprocessing resizeformula-recognition-polynomials-handwritten-0001 モデルでデモを実行するには、次のコマンドを使用します:
python formula_recognition_demo.py \
-i sample2.png \
-m_encoder <path_to_models>/formula-recognition-polynomials-handwritten-0001-encoder.xml \
-m_decoder <path_to_models>/formula-recognition-polynomials-handwritten-0001-decoder.xml \
--vocab_path <models_dir>/models/intel/formula-recognition-polynomials-handwritten-0001/formula-recognition-polynomials-handwritten-0001-decoder/vocab.json \
--preprocessing cropデモの出力#
アプリケーションは、認識された数式をコンソールまたはファイルに出力します。