OpenVINO™ を使用した YOLOv8 指向境界ボックス・オブジェクト検出#
この Jupyter ノートブックはオンラインで起動でき、ブラウザーのウィンドウで対話型環境を開きます。ローカルにインストールすることもできます。次のオプションのいずれかを選択します:


YOLOv8-OBB は Ultralytics によって導入されました。
方向指定オブジェクト検出は、オブジェクト検出よりも一歩進んで、追加の角度を導入し、画像内でオブジェクトをより正確に見つけます。
有向オブジェクト検出器の出力は、画像内のオブジェクトを正確に囲む回転した境界ボックスのセットと、各ボックスのクラスラベルおよび信頼スコアです。オブジェクト検出は、シーン内の関心のあるオブジェクトを識別する必要がありますが、オブジェクトの正確な位置や正確な形状を知る必要がない場合に適しています。
目次:
必要条件#
%pip install -q "ultralytics==8.2.24" "openvino>=2024.0.0" "nncf>=2.9.0" tqdm非推奨: torchsde 0.2.5 には、非標準の依存関係指定子 numpy>=1.19.*; python_version >= "3.7" があります。pip 24.1 では、この動作の変更が強制されます。代替案として、torchsde を新しいバージョンにアップグレードするか、開発者に連絡して、準拠する依存関係指定子を備えたバージョンをリリースするよう提案することが考えられます。ディスカッションは pypa/pip#12063 で見つかります。 注: 更新されたパッケージを使用するには、カーネルを再起動する必要がある場合があります。
必要なユーティリティー関数をインポートします。下のセルは、GitHub から notebook_utils Python モジュールをダウンロードします。
from pathlib import Path
# `notebook_utils` モジュールを取得
import requests
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py",
)
open("notebook_utils.py", "w").write(r.text)
from notebook_utils import download_filePyTorch モデルを取得#
一般に、PyTorch モデルは、モデルの重みを含む状態辞書によって初期化された torch.nn.Module クラスのインスタンスを表します。このリポジトリーで入手可能な DOTAv1 データセットで事前トレーニングされた、YOLOv8 事前トレーニング済み OBB 大規模モデル (yolov8l-obbn とも呼ばれる) を使用します。この手順は他の YOLOv8 モデルにも適用できます。
from ultralytics import YOLO model = YOLO("yolov8l-obb.pt")データセットとデータローダーを準備#
YOLOv8-obb は DOTA データセットで事前トレーニングされています。また、Ultralytics は DOTA8 データセットを提供します。これは、分割された DOTAv1 セットの最初の 8 枚の画像 (トレーニング用に 4 枚、検証用に 4 枚) で構成された小規模で多用途の指向性オブジェクト検出データセットです。このデータセットは、オブジェクト検出モデルのテストやデバッグ、または新しい検出アプローチの実験に最適です。8 枚の画像は、簡単に管理できるほど小さいですが、トレーニング・パイプラインのエラーをテストし、より大きなデータセットをトレーニングする前に健全性チェックとして機能する多様性があります。
元のモデル・リポジトリーは、精度検証パイプラインを表す Validator ラッパーを使用します。データローダーと評価メトリックを作成し、データローダーによって生成される各データバッチのメトリックを更新します。加えて、データの前処理と結果の後処理も担当します。クラスの初期化では、構成を提供する必要があります。デフォルトの設定を使用しますが、カスタムデータでテストするにはオーバーライドするいくつかのパラメーターに置き換えることができます。モデルは task_map に接続しており、これによりバリデーター・クラスのインスタンスが作成されます。
from ultralytics.cfg import get_cfg
from ultralytics.data.utils import check_det_dataset
from ultralytics.utils import DEFAULT_CFG, DATASETS_DIR
CFG_URL =
"https://raw.githubusercontent.com/ultralytics/ultralytics/main/ultralytics/cfg/datasets/dota8.yaml"
OUT_DIR = Path("./datasets")
CFG_PATH = OUT_DIR / "dota8.yaml"
download_file(CFG_URL, CFG_PATH.name, CFG_PATH.parent)
args = get_cfg(cfg=DEFAULT_CFG)
args.data = CFG_PATH
args.task = model.task
validator = model.task_map[model.task]["validator"](args=args)
validator.stride = 32
validator.data = check_det_dataset(str(args.data))
data_loader = validator.get_dataloader(DATASETS_DIR / "dota8", 1)
example_image_path = list(data_loader)[1]["im_file"][0]datasets/dota8.yaml: 0%| | 0.00/608 [00:00<?, ?B/s]Dataset 'datasets/dota8.yaml' images not found ⚠️, missing path '/home/ea/work/openvino_notebooks/notebooks/fast-segment-anything/datasets/dota8/images/val' Downloading ultralytics/yolov5 to '/home/ea/work/openvino_notebooks/notebooks/fast-segment-anything/datasets/dota8.zip'...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.24M/1.24M [00:00<00:00, 1.63MB/s]
Unzipping /home/ea/work/openvino_notebooks/notebooks/fast-segment-anything/datasets/dota8.zip to /home/ea/work/openvino_notebooks/notebooks/fast-segment-anything/datasets/dota8...: 100%|██████████| 27/27 [00:00<00:00, 644.45file/s]Dataset download success ✅ (4.1s), saved to /home/ea/work/openvino_notebooks/notebooks/fast-segment-anything/datasetsval: Scanning /home/ea/work/openvino_notebooks/notebooks/fast-segment-anything/datasets/dota8/labels/train... 8 images, 0 backgrounds, 0 corrupt: 100%|██████████| 8/8 [00:00<00:00, 266.41it/s]val: New cache created: /home/ea/work/openvino_notebooks/notebooks/fast-segment-anything/datasets/dota8/labels/train.cache推論の実行from PIL import Image
res = model(example_image_path, device="cpu")
Image.fromarray(res[0].plot()[:, :, ::-1])image 1/1 /home/ea/work/openvino_notebooks/notebooks/fast-segment-anything/datasets/dota8/images/train/P1053__1024__0___90.jpg: 1024x1024 4915.2ms Speed: 18.6ms preprocess, 4915.2ms inference, 50.9ms postprocess per image at shape (1, 3, 1024, 1024)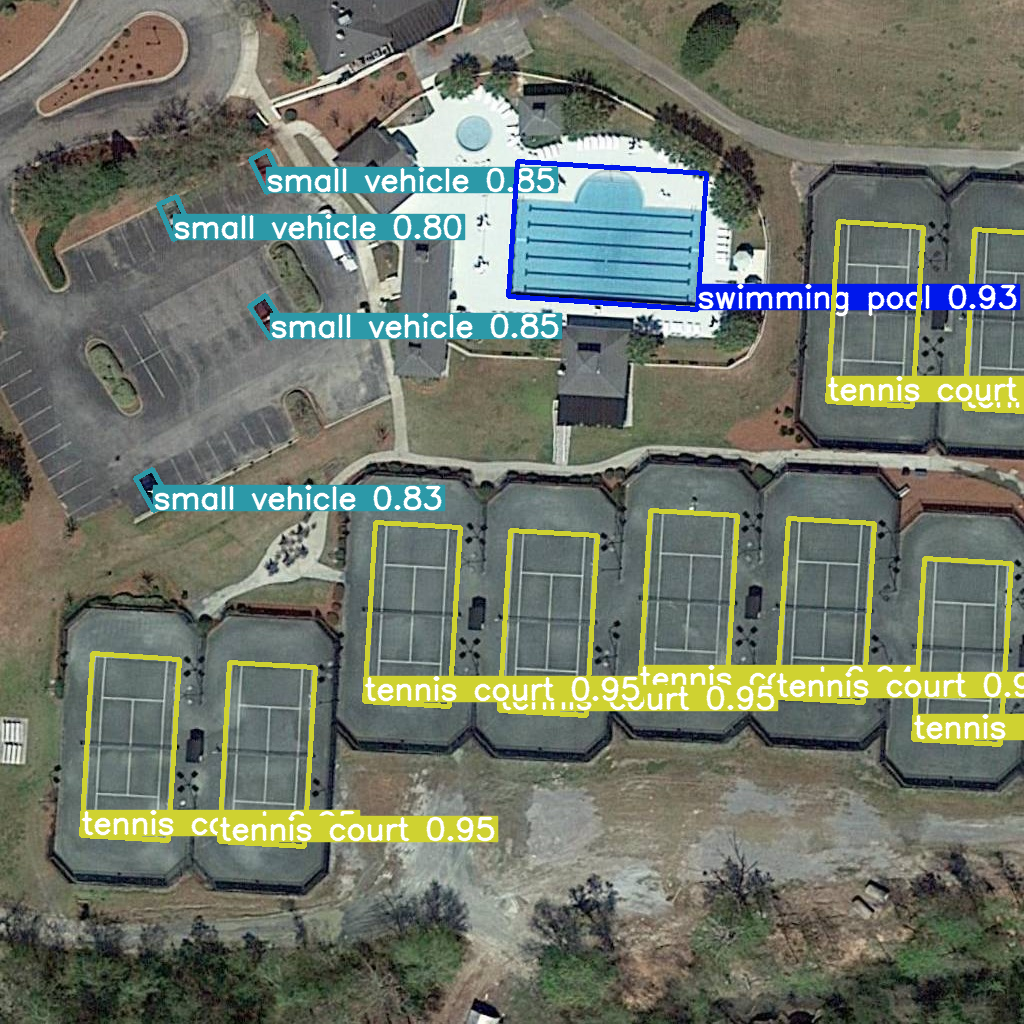
PyTorch モデルを OpenVINO IR に変換#
YOLOv8 は、OpenVINO IR を含むさまざまな形式にモデルをエクスポートする便利な API を提供します。model.export はモデルの変換を担当します。形式を指定する必要があり、さらにモデル内の動的な形状を保持することもできます。
from pathlib import Path
models_dir = Path("./models")
models_dir.mkdir(exist_ok=True)
OV_MODEL_NAME = "yolov8l-obb"
OV_MODEL_PATH = Path(f"{OV_MODEL_NAME}_openvino_model/{OV_MODEL_NAME}.xml")
if not OV_MODEL_PATH.exists():
model.export(format="openvino", dynamic=True, half=True)Ultralytics YOLOv8.1.24 🚀 Python-3.8.10 torch-2.1.2+cpu CPU (Intel Core(TM) i9-10980XE 3.00GHz)
PyTorch: starting from 'yolov8l-obb.pt' with input shape (1, 3, 1024, 1024) BCHW and output shape(s) (1, 20, 21504) (85.4 MB)
OpenVINO: starting export with openvino 2024.0.0-14509-34caeefd078-releases/2024/0...OpenVINO: export success ✅ 5.6s, saved as 'yolov8l-obb_openvino_model/' (85.4 MB)
Export complete (18.7s)
Results saved to /home/ea/work/openvino_notebooks_new_clone/openvino_notebooks/notebooks/yolov8-optimization
Predict: yolo predict task=obb model=yolov8l-obb_openvino_model imgsz=1024 half
Validate: yolo val task=obb model=yolov8l-obb_openvino_model imgsz=1024 data=runs/DOTAv1.0-ms.yaml half
Visualize: https://netron.app推論デバイスの選択#
OpenVINO を使用して推論を実行するデバイスをドロップダウン・リストから選択します。
import ipywidgets as widgets
import openvino as ov
core = ov.Core()
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value="AUTO",
description="Device:",
disabled=False,
)
deviceDropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')モデルのコンパイル#
ov_model = core.read_model(OV_MODEL_PATH)
ov_config = {}
if device.value != "CPU":
ov_model.reshape({0: [1, 3, 1024, 1024]})
if "GPU" in device.value or ("AUTO" in device.value and "GPU" in core.available_devices):
ov_config = {"GPU_DISABLE_WINOGRAD_CONVOLUTION": "YES"}
compiled_ov_model = core.compile_model(ov_model, device.value, ov_config)推論用のモデルを準備#
推論に IR モデルを使用する方法を置き換えるだけで、前処理と後処理にベース・モデル・パイプラインを再利用できます。
import torch
def infer(*args):
result = compiled_ov_model(args)[0]
return torch.from_numpy(result)
model.predictor.inference = infer推論の実行#
res = model(example_image_path, device="cpu")
Image.fromarray(res[0].plot()[:, :, ::-1])image 1/1 /home/ea/work/openvino_notebooks/notebooks/fast-segment-anything/datasets/dota8/images/train/P1053__1024__0___90.jpg: 1024x1024 338.0ms Speed: 4.7ms preprocess, 338.0ms inference, 3.7ms postprocess per image at shape (1, 3, 1024, 1024)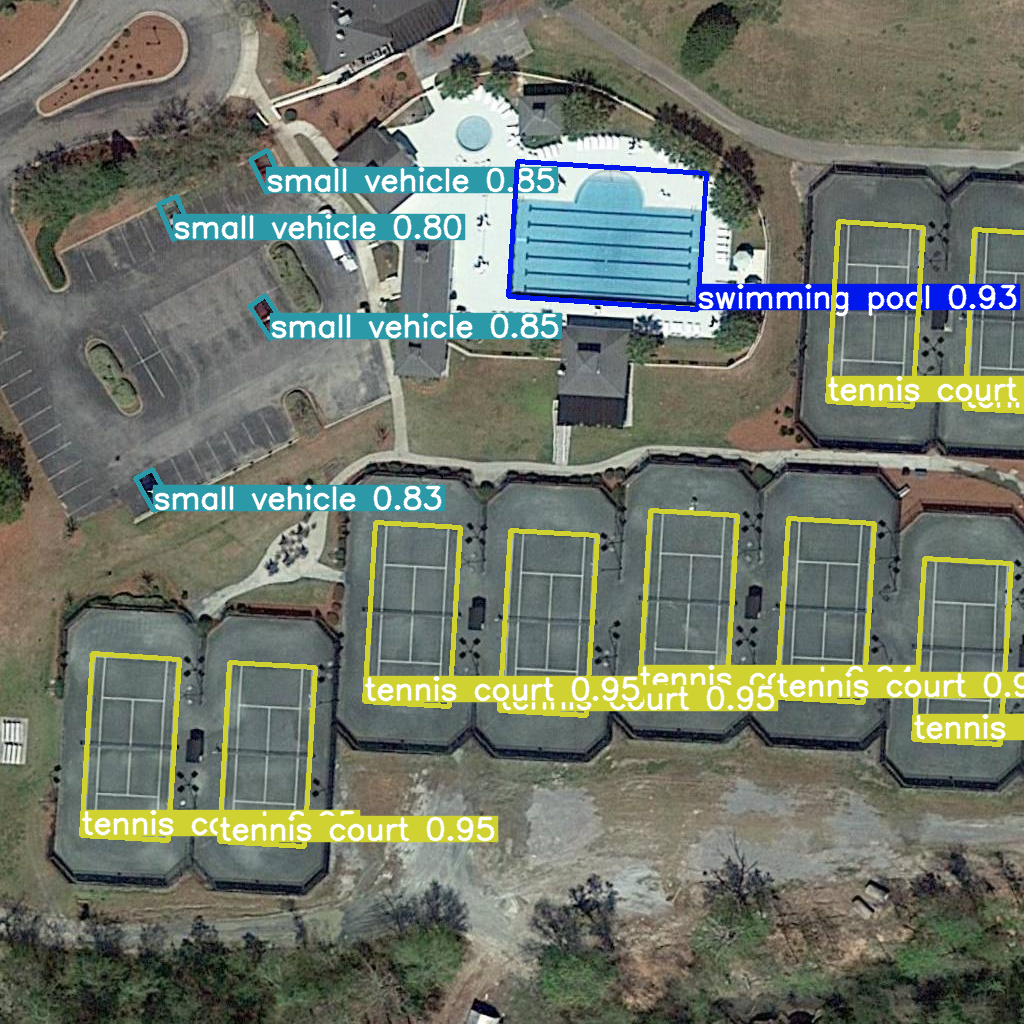
量子化#
NNCF は、量子化レイヤーをモデルグラフに追加し、トレーニング・データセットのサブセットを使用してこれらの追加の量子化レイヤーのパラメーターを初期化することで、トレーニング後の量子化を可能にします。量子化操作は FP32/FP16 ではなく INT8 で実行されるため、モデル推論が高速化されます。
最適化プロセスには次の手順が含まれます:
量子化用のキャリブレーション・データセットを作成します。
nncf.quantize()を実行して、量子化されたモデルを取得します。openvino.save_model()関数を使用してINT8モデルを保存します。
モデルの推論速度を向上させるため量子化を実行するかどうかを以下で選択してください。
import ipywidgets as widgets
INT8_OV_PATH = Path("model/int8_model.xml")
to_quantize = widgets.Checkbox(
value=True,
description="Quantization",
disabled=False,
)
to_quantizeCheckbox(value=True, description='Quantization')to_quantize が選択されていない場合に量子化をスキップする skip magic 拡張機能をロードします
# skip_kernel_extension モジュールを取得
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/skip_kernel_extension.py",
)
open("skip_kernel_extension.py", "w").write(r.text)
%load_ext skip_kernel_extension%%skip not $to_quantize.value
from typing import Dict
import nncf
def transform_fn(data_item: Dict):
input_tensor = validator.preprocess(data_item)["img"].numpy()
return input_tensor
quantization_dataset = nncf.Dataset(data_loader, transform_fn)INFO:nncf:NNCF initialized successfully.Supported frameworks detected: torch, tensorflow, onnx, openvino事前トレーニング済みの変換済み OpenVINO モデルから量子化モデルを作成します。
注: 量子化は時間とメモリーを消費する操作です。以下の量子化コードの実行には時間がかかる場合があります。
注: 小規模な DOTA8 データセットをキャリブレーション・データセットとして使用します。チュートリアルの目的には十分な結果が得られます。より良い結果を得るには、より大きなデータセットを使用してください。通常は 300 個の例で十分です。
%%skip not $to_quantize.value
if INT8_OV_PATH.exists():
print("Loading quantized model")
quantized_model = core.read_model(INT8_OV_PATH)
else:
ov_model.reshape({0: [1, 3, -1, -1]})
quantized_model = nncf.quantize(
ov_model,
quantization_dataset,
preset=nncf.QuantizationPreset.MIXED,
)
ov.save_model(quantized_model, INT8_OV_PATH)
ov_config = {}
if device.value != "CPU":
quantized_model.reshape({0: [1, 3, 1024, 1024]})
if "GPU" in device.value or ("AUTO" in device.value and "GPU" in core.available_devices):
ov_config = {"GPU_DISABLE_WINOGRAD_CONVOLUTION": "YES"}
model_optimized = core.compile_model(quantized_model, device.value, ov_config)Output()Output()IR モデルと同じように、ベース・モデル・パイプラインを再利用できます。
%%skip not $to_quantize.value
def infer(*args):
result = model_optimized(args)[0]
return torch.from_numpy(result)
model.predictor.inference = infer推論の実行
%%skip not $to_quantize.value
res = model(example_image_path, device='cpu')
Image.fromarray(res[0].plot()[:, :, ::-1])image 1/1 /home/ea/work/openvino_notebooks/notebooks/fast-segment-anything/datasets/dota8/images/train/P1053__1024__0___90.jpg: 1024x1024 240.5ms Speed: 3.2ms preprocess, 240.5ms inference, 4.2ms postprocess per image at shape (1, 3, 1024, 1024)結果はほぼ同じですが、わずかな違いがあることがわかります。1 台の小型車両が 2 台の車両として認識されています。しかし、元のモデルとは異なる大型車も 1 台確認されました。
推論時間とモデルサイズを比較#
%%skip not $to_quantize.value
fp16_ir_model_size = OV_MODEL_PATH.with_suffix(".bin").stat().st_size / 1024
quantized_model_size = INT8_OV_PATH.with_suffix(".bin").stat().st_size / 1024
print(f"FP16 model size: {fp16_ir_model_size:.2f} KB")
print(f"INT8 model size: {quantized_model_size:.2f} KB")
print(f"Model compression rate: {fp16_ir_model_size / quantized_model_size:.3f}")FP16 model size: 86849.05 KB
INT8 model size: 43494.78 KB
Model compression rate: 1.997# 推論 FP32 モデル (OpenVINO IR)
!benchmark_app -m $OV_MODEL_PATH -d $device.value -api async -shape "[1,3,640,640]"[Step 1/11] Parsing and validating input arguments [ INFO ] Parsing input parameters [Step 2/11] Loading OpenVINO Runtime [ WARNING ] Default duration 120 seconds is used for unknown device AUTO [ INFO ] OpenVINO: [ INFO ] Build .................................2024.0.0-14509-34caeefd078-releases/2024/0 [ INFO ] [ INFO ] Device info: [ INFO ] AUTO [ INFO ] Build .................................2024.0.0-14509-34caeefd078-releases/2024/0 [ INFO ] [ INFO ] [Step 3/11] Setting device configuration [ WARNING ] Performance hint was not explicitly specified in command line.Device(AUTO) performance hint will be set to PerformanceMode.THROUGHPUT. [Step 4/11] Reading model files [ INFO ] Loading model files [ INFO ] Read model took 25.07 ms [ INFO ] Original model I/O parameters: [ INFO ] Model inputs: [ INFO ] x (node: x) : f32 / [...] / [?,3,?,?] [ INFO ] Model outputs: [ INFO ] *NO_NAME* (node: __module.model.22/aten::cat/Concat_9) : f32 / [...] / [?,20,16..] [Step 5/11] Resizing model to match image sizes and given batch [ INFO ] Model batch size: 1 [ INFO ] Reshaping model: 'x': [1,3,640,640] [ INFO ] Reshape model took 10.42 ms [Step 6/11] Configuring input of the model [ INFO ] Model inputs: [ INFO ] x (node: x) : u8 / [N,C,H,W] / [1,3,640,640] [ INFO ] Model outputs: [ INFO ] *NO_NAME* (node: __module.model.22/aten::cat/Concat_9) : f32 / [...]/ [1,20,8400] [Step 7/11] Loading the model to the device [ INFO ] Compile model took 645.51 ms [Step 8/11] Querying optimal runtime parameters [ INFO ] Model: [ INFO ] NETWORK_NAME: Model0 [ INFO ] EXECUTION_DEVICES: ['CPU'] [ INFO ] PERFORMANCE_HINT: PerformanceMode.THROUGHPUT [ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 12 [ INFO ] MULTI_DEVICE_PRIORITIES: CPU [ INFO ] CPU: [ INFO ] AFFINITY: Affinity.CORE [ INFO ] CPU_DENORMALS_OPTIMIZATION: False [ INFO ] CPU_SPARSE_WEIGHTS_DECOMPRESSION_RATE: 1.0 [ INFO ] DYNAMIC_QUANTIZATION_GROUP_SIZE: 0 [ INFO ] ENABLE_CPU_PINNING: True [ INFO ] ENABLE_HYPER_THREADING: True [ INFO ] EXECUTION_DEVICES: ['CPU'] [ INFO ] EXECUTION_MODE_HINT: ExecutionMode.PERFORMANCE [ INFO ] INFERENCE_NUM_THREADS: 36 [ INFO ] INFERENCE_PRECISION_HINT: <Type: 'float32'> [ INFO ] KV_CACHE_PRECISION: <Type: 'float16'> [ INFO ] LOG_LEVEL: Level.NO [ INFO ] NETWORK_NAME: Model0 [ INFO ] NUM_STREAMS: 12 [ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 12 [ INFO ] PERFORMANCE_HINT: THROUGHPUT [ INFO ] PERFORMANCE_HINT_NUM_REQUESTS: 0 [ INFO ] PERF_COUNT: NO [ INFO ] SCHEDULING_CORE_TYPE: SchedulingCoreType.ANY_CORE [ INFO ] MODEL_PRIORITY: Priority.MEDIUM [ INFO ] LOADED_FROM_CACHE: False [Step 9/11] Creating infer requests and preparing input tensors [ WARNING ] No input files were given for input 'x'!.This input will be filled with random values! [ INFO ] Fill input 'x' with random values [Step 10/11] Measuring performance (Start inference asynchronously, 12 inference requests, limits: 120000 ms duration) [ INFO ] Benchmarking in inference only mode (inputs filling are not included in measurement loop). [ INFO ] First inference took 362.70 ms [Step 11/11] Dumping statistics report [ INFO ] Execution Devices:['CPU'] [ INFO ] Count: 1620 iterations [ INFO ] Duration: 121527.01 ms [ INFO ] Latency: [ INFO ] Median: 884.92 ms [ INFO ] Average: 897.13 ms [ INFO ] Min: 599.38 ms [ INFO ] Max: 1131.46 ms [ INFO ] Throughput: 13.33 FPS
if INT8_OV_PATH.exists(): # 推論 INT8 モデル (量子化モデル)
!benchmark_app -m $INT8_OV_PATH -d $device.value -api async -shape "[1,3,640,640]" -t 15[Step 1/11] Parsing and validating input arguments [ INFO ] Parsing input parameters [Step 2/11] Loading OpenVINO Runtime [ INFO ] OpenVINO: [ INFO ] Build .................................2024.0.0-14509-34caeefd078-releases/2024/0 [ INFO ] [ INFO ] Device info: [ INFO ] AUTO [ INFO ] Build .................................2024.0.0-14509-34caeefd078-releases/2024/0 [ INFO ] [ INFO ] [Step 3/11] Setting device configuration [ WARNING ] Performance hint was not explicitly specified in command line.Device(AUTO) performance hint will be set to PerformanceMode.THROUGHPUT. [Step 4/11] Reading model files [ INFO ] Loading model files [ INFO ] Read model took 46.47 ms [ INFO ] Original model I/O parameters: [ INFO ] Model inputs: [ INFO ] x (node: x) : f32 / [...]/ [?,3,?,?] [ INFO ] Model outputs: [ INFO ] *NO_NAME* (node: __module.model.22/aten::cat/Concat_9) : f32 / [...]/ [?,20,16..] [Step 5/11] Resizing model to match image sizes and given batch [ INFO ] Model batch size: 1 [ INFO ] Reshaping model: 'x': [1,3,640,640] [ INFO ] Reshape model took 20.10 ms [Step 6/11] Configuring input of the model [ INFO ] Model inputs: [ INFO ] x (node: x) : u8 / [N,C,H,W] / [1,3,640,640] [ INFO ] Model outputs: [ INFO ] *NO_NAME* (node: __module.model.22/aten::cat/Concat_9) : f32 / [...] / [1,20,8400] [Step 7/11] Loading the model to the device [ INFO ] Compile model took 1201.42 ms [Step 8/11] Querying optimal runtime parameters [ INFO ] Model: [ INFO ] NETWORK_NAME: Model0 [ INFO ] EXECUTION_DEVICES: ['CPU'] [ INFO ] PERFORMANCE_HINT: PerformanceMode.THROUGHPUT [ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 12 [ INFO ] MULTI_DEVICE_PRIORITIES: CPU [ INFO ] CPU: [ INFO ] AFFINITY: Affinity.CORE [ INFO ] CPU_DENORMALS_OPTIMIZATION: False [ INFO ] CPU_SPARSE_WEIGHTS_DECOMPRESSION_RATE: 1.0 [ INFO ] DYNAMIC_QUANTIZATION_GROUP_SIZE: 0 [ INFO ] ENABLE_CPU_PINNING: True [ INFO ] ENABLE_HYPER_THREADING: True [ INFO ] EXECUTION_DEVICES: ['CPU'] [ INFO ] EXECUTION_MODE_HINT: ExecutionMode.PERFORMANCE [ INFO ] INFERENCE_NUM_THREADS: 36 [ INFO ] INFERENCE_PRECISION_HINT: <Type: 'float32'> [ INFO ] KV_CACHE_PRECISION: <Type: 'float16'> [ INFO ] LOG_LEVEL: Level.NO [ INFO ] NETWORK_NAME: Model0 [ INFO ] NUM_STREAMS: 12 [ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 12 [ INFO ] PERFORMANCE_HINT: THROUGHPUT [ INFO ] PERFORMANCE_HINT_NUM_REQUESTS: 0 [ INFO ] PERF_COUNT: NO [ INFO ] SCHEDULING_CORE_TYPE: SchedulingCoreType.ANY_CORE [ INFO ] MODEL_PRIORITY: Priority.MEDIUM [ INFO ] LOADED_FROM_CACHE: False [Step 9/11] Creating infer requests and preparing input tensors [ WARNING ] No input files were given for input 'x'!.This input will be filled with random values! [ INFO ] Fill input 'x' with random values [Step 10/11] Measuring performance (Start inference asynchronously, 12 inference requests, limits: 15000 ms duration) [ INFO ] Benchmarking in inference only mode (inputs filling are not included in measurement loop). [ INFO ] First inference took 124.20 ms [Step 11/11] Dumping statistics report [ INFO ] Execution Devices:['CPU'] [ INFO ] Count: 708 iterations [ INFO ] Duration: 15216.46 ms [ INFO ] Latency: [ INFO ] Median: 252.23 ms [ INFO ] Average: 255.76 ms [ INFO ] Min: 176.97 ms [ INFO ] Max: 344.41 ms [ INFO ] Throughput: 46.53 FPS