OpenVINO™ を使用した PaddleOCR#
この Jupyter ノートブックはオンラインで起動でき、ブラウザーのウィンドウで対話型環境を開きます。ローカルにインストールすることもできます。次のオプションのいずれかを選択します:



このデモでは、OpenVINO で PP-OCR モデルをネイティブに実行する方法を示します。PaddlePaddle モデルを ONNX にエクスポートし、モデル・トランスフォーメーション API を使用して OpenVINO 中間表現 (OpenVINO IR) 形式に変換する代わりに、変換せずに PaddlePaddle モデルから直接読み取ることができるようになりました。PaddleOCR は、PaddlePaddle ディープラーニング・フレームワークでトレーニングされた超軽量 OCR モデルであり、多言語で実用的な OCR ツールを作成することを目的としています。
デモで使用した PaddleOCR の事前トレーニング済みモデルは、“中国語と英語の超軽量 PP-OCR モデル (9.4M)” です。その他のオープンソースの事前トレーニング済みモデルは、PaddleOCR GitHub または PaddleOCR Gitee からダウンロードできます。PaddleOCR の動作パイプラインは次のとおりです:
注: このノートブックをウェブカメラで使用するには、ウェブカメラを備えたコンピューター上でノートブックを実行する必要があります。サーバー上でノートブックを実行すると、ウェブカメラは機能しなくなります。ビデオファイルの推論を行うことはできます。
目次:
%pip install -q "openvino>=2023.1.0"
%pip install -q "paddlepaddle>=2.5.1"
%pip install -q "pyclipper>=1.2.1" "shapely>=1.7.1" tqdmNote: you may need to restart the kernel to use updated packages.
Note: you may need to restart the kernel to use updated packages.
Note: you may need to restart the kernel to use updated packages.インポート#
import cv2
import numpy as np
import paddle
import math
import time
import collections
from PIL import Image
from pathlib import Path
import tarfile
import openvino as ov
from IPython import display
import copy# ローカルモジュールをインポート
if not Path("./notebook_utils.py").exists():
# notebook_utils` モジュールを取得
import requests
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py",
)
open("notebook_utils.py", "w").write(r.text)
import notebook_utils as utils
import pre_post_processing as processing推論デバイスの選択#
OpenVINO を使用して推論を実行するためにドロップダウン・リストからデバイスを選択します
import ipywidgets as widgets
core = ov.Core()
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value="AUTO",
description="Device:",
disabled=False,
)
deviceDropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')PaddleOCR 用モデル#
PaddleOCR には、テキスト検出とテキスト認識という 2 つのディープラーニング・モデルが含まれています。デモで使用される事前トレーニング済みモデルはダウンロードされ、“model” フォルダーに保存されます。
モデルを実行するには、数行のコードで済みます。まず、推論用にランタイムを初期化します。次に、.pdmodel および .pdiparams ファイルからネットワーク・アーキテクチャーとモデルの重みを読み取り、CPU/GPU にロードします。
# PaddleOCR リソースからテキスト検出および認識モデルをダウンロードする関数を定義
def run_model_download(model_url: str, model_file_path: Path) -> None:
"""
Download pre-trained models from PaddleOCR resources
Parameters:
model_url: url link to pre-trained models
model_file_path: file path to store the downloaded model
"""
archive_path = model_file_path.absolute().parent.parent / model_url.split("/")[-1]
if model_file_path.is_file():
print("Model already exists")
else:
# サーバーからモデルをダウンロードして展開
print("Downloading the pre-trained model...May take a while...")
# ディレクトリーを作成
utils.download_file(model_url, archive_path.name, archive_path.parent)
print("Model Downloaded")
file = tarfile.open(archive_path)
res = file.extractall(archive_path.parent)
file.close()
if not res:
print(f"Model Extracted to {model_file_path}.")
else:
print("Error Extracting the model.Please check the network.")テキスト検出用のモデルをダウンロード#
# モデルがダウンロードされるディレクトリー
det_model_url =
"https://storage.openvinotoolkit.org/repositories/openvino_notebooks/models/paddle-ocr/ch_PP-OCRv3_det_infer.tar"
det_model_file_path = Path("model/ch_PP-OCRv3_det_infer/inference.pdmodel")
run_model_download(det_model_url, det_model_file_path)Downloading the pre-trained model... May take a while.../opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/notebooks/paddle-o…Model Downloaded
Model Extracted to model/ch_PP-OCRv3_det_infer/inference.pdmodel.テキスト検出用のモデルをロード#
# テキスト検出用に OpenVINO ランタイムを初期化
core = ov.Core()
det_model = core.read_model(model=det_model_file_path)
det_compiled_model = core.compile_model(model=det_model, device_name=device.value)
# テキスト検出用の入力ノードと出力ノードを取得
det_input_layer = det_compiled_model.input(0)
det_output_layer = det_compiled_model.output(0)テキスト認識用のモデルをダウンロード#
rec_model_url =
"https://storage.openvinotoolkit.org/repositories/openvino_notebooks/models/paddle-ocr/ch_PP-OCRv3_rec_infer.tar"
rec_model_file_path = Path("model/ch_PP-OCRv3_rec_infer/inference.pdmodel")
run_model_download(rec_model_url, rec_model_file_path)Downloading the pre-trained model...May take a while.../opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/notebooks/paddle-o…Model Downloaded
Model Extracted to model/ch_PP-OCRv3_rec_infer/inference.pdmodel.動的形状を使用したテキスト認識用のモデルをロード#
テキスト認識モデルへの入力は、動的入力形状など、さまざまな画像サイズを持つ検出された境界ボックスを指します。したがって、次のようになります:
動的入力形状の入力次元は、テキスト認識モデルをロードする前に指定する必要があります。
動的形状は、入力次元に -1 を割り当てるか、
Dimension(1, 512)のように入力次元の上限を設定することによって指定されます。
# ファイルからモデルと対応する重みを読み取ります
rec_model = core.read_model(model=rec_model_file_path)
# 最後の次元のすべての入力レイヤーに動的形状を割り当て
for input_layer in rec_model.inputs:
input_shape = input_layer.partial_shape
input_shape[3] = -1
rec_model.reshape({input_layer: input_shape})
rec_compiled_model = core.compile_model(model=rec_model, device_name="AUTO")
# 入力ノードと出力ノードを取得
rec_input_layer = rec_compiled_model.input(0)
rec_output_layer = rec_compiled_model.output(0)テキストの検出と認識のための画像関数の前処理#
テキストの検出と認識のための前処理関数を定義します。
- テキスト検出の前処理: 入力画像のサイズ変更と正規化します。
- テキスト認識の前処理: 推論でのバッチ処理を容易にするために、検出されたボックス画像を同じサイズ (例えば、中国語のテキストを含む画像の場合は
(3, 32, 320)) にサイズ変更および正規化します。
# テキスト検出のための前処理
def image_preprocess(input_image, size):
"""
Preprocess input image for text detection
Parameters:
input_image: input image
size: value for the image to be resized for text detection model
"""
img = cv2.resize(input_image, (size, size))
img = np.transpose(img, [2, 0, 1]) / 255
img = np.expand_dims(img, 0)
# NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True}
img_mean = np.array([0.485, 0.456, 0.406]).reshape((3, 1, 1))
img_std = np.array([0.229, 0.224, 0.225]).reshape((3, 1, 1))
img -= img_mean
img /= img_std
return img.astype(np.float32)# テキスト認識のための前処理
def resize_norm_img(img, max_wh_ratio):
"""
Resize input image for text recognition
Parameters:
img: bounding box image from text detection
max_wh_ratio: value for the resizing for text recognition model
"""
rec_image_shape = [3, 48, 320]
imgC, imgH, imgW = rec_image_shape
assert imgC == img.shape[2]
character_type = "ch"
if character_type == "ch":
imgW = int((32 * max_wh_ratio))
h, w = img.shape[:2]
ratio = w / float(h)
if math.ceil(imgH * ratio) > imgW:
resized_w = imgW
else:
resized_w = int(math.ceil(imgH * ratio))
resized_image = cv2.resize(img, (resized_w, imgH))
resized_image = resized_image.astype("float32")
resized_image = resized_image.transpose((2, 0, 1)) / 255
resized_image -= 0.5
resized_image /= 0.5
padding_im = np.zeros((imgC, imgH, imgW), dtype=np.float32)
padding_im[:, :, 0:resized_w] = resized_image
return padding_im
def prep_for_rec(dt_boxes, frame):
"""
Preprocessing of the detected bounding boxes for text recognition
Parameters:
dt_boxes: detected bounding boxes from text detection
frame: original input frame
"""
ori_im = frame.copy()
img_crop_list = []
for bno in range(len(dt_boxes)):
tmp_box = copy.deepcopy(dt_boxes[bno])
img_crop = processing.get_rotate_crop_image(ori_im, tmp_box)
img_crop_list.append(img_crop)
img_num = len(img_crop_list)
# すべてのテキストバーのアスペクト比を計算
width_list = []
for img in img_crop_list:
width_list.append(img.shape[1] / float(img.shape[0]))
# ソートすると認識プロセスを高速化
indices = np.argsort(np.array(width_list))
return img_crop_list, img_num, indices
def batch_text_box(img_crop_list, img_num, indices, beg_img_no, batch_num):
"""
Batch for text recognition
Parameters:
img_crop_list: processed detected bounding box images
img_num: number of bounding boxes from text detection
indices: sorting for bounding boxes to speed up text recognition
beg_img_no: the beginning number of bounding boxes for each batch of text recognition inference
batch_num: number of images for each batch
"""
norm_img_batch = []
max_wh_ratio = 0
end_img_no = min(img_num, beg_img_no + batch_num)
for ino in range(beg_img_no, end_img_no):
h, w = img_crop_list[indices[ino]].shape[0:2]
wh_ratio = w * 1.0 / h
max_wh_ratio = max(max_wh_ratio, wh_ratio)
for ino in range(beg_img_no, end_img_no):
norm_img = resize_norm_img(img_crop_list[indices[ino]], max_wh_ratio)
norm_img = norm_img[np.newaxis, :]
norm_img_batch.append(norm_img)
norm_img_batch = np.concatenate(norm_img_batch)
norm_img_batch = norm_img_batch.copy()
return norm_img_batchテキスト検出のための画像の後処理#
def post_processing_detection(frame, det_results):
"""
Postprocess the results from text detection into bounding boxes
Parameters:
frame: input image
det_results: inference results from text detection model
"""
ori_im = frame.copy()
data = {"image": frame}
data_resize = processing.DetResizeForTest(data)
data_list = []
keep_keys = ["image", "shape"]
for key in keep_keys:
data_list.append(data_resize[key])
img, shape_list = data_list
shape_list = np.expand_dims(shape_list, axis=0)
pred = det_results[0]
if isinstance(pred, paddle.Tensor):
pred = pred.numpy()
segmentation = pred > 0.3
boxes_batch = []
for batch_index in range(pred.shape[0]):
src_h, src_w, ratio_h, ratio_w = shape_list[batch_index]
mask = segmentation[batch_index]
boxes, scores = processing.boxes_from_bitmap(pred[batch_index], mask, src_w, src_h)
boxes_batch.append({"points": boxes})
post_result = boxes_batch
dt_boxes = post_result[0]["points"]
dt_boxes = processing.filter_tag_det_res(dt_boxes, ori_im.shape)
return dt_boxesPaddleOCR の主な処理機能#
Web カメラまたはビデオファイルのいずれかで、paddleOCR 機能をさまざまな操作で実行します。以下の手順のリストを参照してください:
ターゲット fps で再生するビデオプレーヤーを作成します (
utils.VideoPlayer)。テキストの検出と認識用に一連のフレームを準備します。
テキストの検出と認識の両方に AI 推論を実行します。
結果を視覚化します。
# OCR 結果を印刷するフォントと文字辞書をダウンロード
font_path = utils.download_file(
url="https://raw.githubusercontent.com/Halfish/lstm-ctc-ocr/master/fonts/simfang.ttf",
directory="fonts",
)
character_dictionary_path = utils.download_file(
url="https://raw.githubusercontent.com/WenmuZhou/PytorchOCR/master/torchocr/datasets/alphabets/ppocr_keys_v1.txt",
directory="fonts",
)fonts/simfang.ttf: 0%| | 0.00/10.1M [00:00<?, ?B/s]fonts/ppocr_keys_v1.txt: 0%| | 0.00/17.3k [00:00<?, ?B/s]def run_paddle_ocr(source=0, flip=False, use_popup=False, skip_first_frames=0):
"""
Main function to run the paddleOCR inference:
1. Create a video player to play with target fps (utils.VideoPlayer).
2. Prepare a set of frames for text detection and recognition.
3. Run AI inference for both text detection and recognition.
4. Visualize the results.
Parameters:
source: The webcam number to feed the video stream with primary webcam set to "0", or the video path.
flip: To be used by VideoPlayer function for flipping capture image.
use_popup: False for showing encoded frames over this notebook, True for creating a popup window.
skip_first_frames: Number of frames to skip at the beginning of the video.
"""
# ターゲット fps で再生するビデオプレーヤーを作成
player = None
try:
player = utils.VideoPlayer(source=source, flip=flip, fps=30, skip_first_frames=skip_first_frames)
# ビデオ・キャプチャーを開始
Player.start().start()
if use_popup:
title = "Press ESC to Exit"
cv2.namedWindow(winname=title, flags=cv2.WINDOW_GUI_NORMAL | cv2.WINDOW_AUTOSIZE)
processing_times = collections.deque()
while True:
# フレームをグラブ
frame = player.next()
if frame is None:
print("Source ended")
break
# フレームがフル HD より大きい場合は、サイズを縮小してパフォーマンスを向上
scale = 1280 / max(frame.shape)
if scale < 1:
frame = cv2.resize(
src=frame,
dsize=None,
fx=scale,
fy=scale,
interpolation=cv2.INTER_AREA,
)
# テキスト検出のため画像を前処理
test_image = image_preprocess(frame, 640)
# テキスト検出の処理時間を測定
start_time = time.time()
# 推論ステップを実行
det_results = det_compiled_model([test_image])[det_output_layer]
stop_time = time.time()
# パドル検出の後処理
dt_boxes = post_processing_detection(frame, det_results)
processing_times.append(stop_time - start_time)
# 最後の 200 フレームの処理時間を使用
if len(processing_times) > 200:
processing_times.popleft()
processing_time_det = np.mean(processing_times) * 1000
# 認識のために検出結果を前処理
dt_boxes = processing.sorted_boxes(dt_boxes)
batch_num = 6
img_crop_list, img_num, indices = prep_for_rec(dt_boxes, frame)
# 認識結果を保存するには、次の 2 つの部分を含めます:
# txt は認識されたテキストの結果であり、スコアは認識の信頼レベルです
rec_res = [["", 0.0]] * img_num
txts = []
scores = []
for beg_img_no in range(0, img_num, batch_num):
# 認識はここから始まります
norm_img_batch = batch_text_box(img_crop_list, img_num, indices, beg_img_no, batch_num)
# テキスト認識の推論を実行
rec_results = rec_compiled_model([norm_img_batch])[rec_output_layer]
# 認識結果を後処理
postprocess_op = processing.build_post_process(processing.postprocess_params)
rec_result = postprocess_op(rec_results)
for rno in range(len(rec_result)):
rec_res[indices[beg_img_no + rno]] = rec_result[rno]
if rec_res:
txts = [rec_res[i][0] for i in range(len(rec_res))]
scores = [rec_res[i][1] for i in range(len(rec_res))]
image = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
boxes = dt_boxes
# 画像の横にテキスト認識結果を描画
draw_img = processing.draw_ocr_box_txt(image, boxes, txts, scores, drop_score=0.5, font_path=str(font_path))
# PaddleOCR の結果を視覚化
f_height, f_width = draw_img.shape[:2]
fps = 1000 / processing_time_det
cv2.putText(
img=draw_img,
text=f"Inference time: {processing_time_det:.1f}ms ({fps:.1f} FPS)",
org=(20, 40),
fontFace=cv2.FONT_HERSHEY_COMPLEX,
fontScale=f_width / 1000,
color=(0, 0, 255),
thickness=1,
lineType=cv2.LINE_AA,
)
# ちらつきがある場合は、この回避策を使用
if use_popup:
draw_img = cv2.cvtColor(draw_img,
cv2.COLOR_RGB2BGR) cv2.imshow(winname=title, mat=draw_img)
key = cv2.waitKey(1)
# escape = 27
if key == 27:
break
else:
# numpy 配列を jpg にエンコード
draw_img = cv2.cvtColor(draw_img, cv2.COLOR_RGB2BGR)
_, encoded_img = cv2.imencode(ext=".jpg", img=draw_img, params=[cv2.IMWRITE_JPEG_QUALITY, 100])
# Create an IPython image.
i = display.Image(data=encoded_img)
# このノートブックに画像を表示
display.clear_output(wait=True)
display.display(i)
# ctrl-c
except KeyboardInterrupt:
print("Interrupted")
# 異なるエラー
except RuntimeError as e:
print(e)
finally:
if player is not None:
# キャプチャーを停止
Player.stop().stop()
if use_popup:
cv2.destroyAllWindows()OpenVINO でライブ PaddleOCR を実行#
Web カメラをビデオ入力として使用します。デフォルトでは、プライマリー Web カメラは source=0 に設定されます。複数のウェブカメラがある場合、0 から始まる連続した番号が割り当てられます。前面カメラを使用する場合は、flip=True を設定します。一部のウェブブラウザー、特に Mozilla Firefox ではちらつきが発生する場合があります。ちらつきが発生する場合、use_popup=True を設定してください。
注: このノートブックをリモート・コンピューターで実行すると、ポップアップ・モードが機能しない可能性があります。
ウェブカメラがない場合でも、ビデオファイルを使用してこのデモを実行できます。OpenCV でサポートされている形式であればどれでも機能します。
ライブ PaddleOCR を実行します:
USE_WEBCAM = False
cam_id = 0
video_file =
"https://raw.githubusercontent.com/yoyowz/classification/master/images/test.mp4"
source = cam_id if USE_WEBCAM else video_file
run_paddle_ocr(source, flip=False, use_popup=False)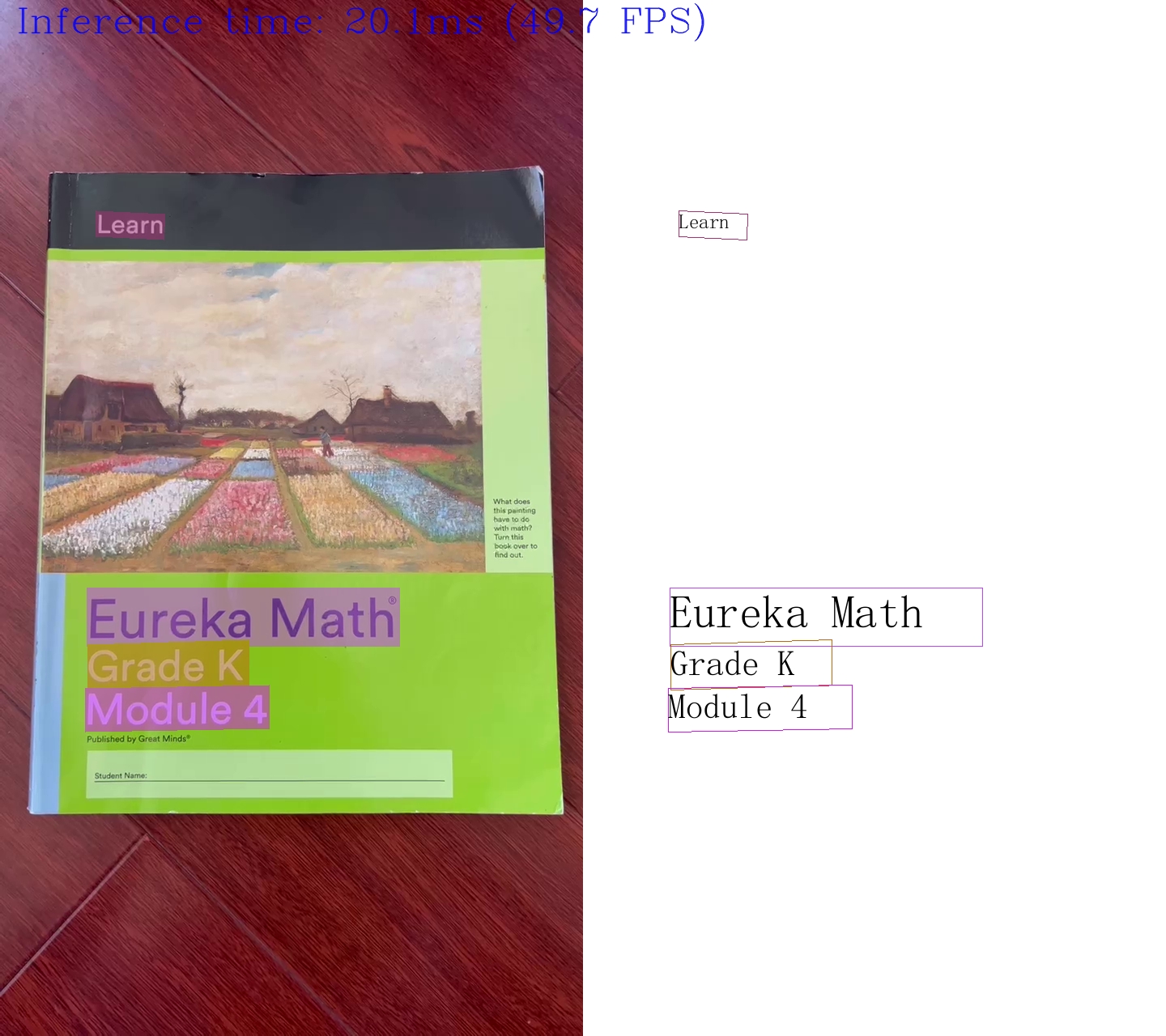
ソースの終わり