EnCodec と OpenVINO によるオーディオ圧縮#
この Jupyter ノートブックは、ローカルへのインストール後にのみ起動できます。

圧縮は、簡単に高品質の写真を共有したり、音声メッセージを聴いたり、お気に入りの番組をストリーミングしたりするため、今日のインターネットでは重要な機能です。今日の最先端の技術を使用している場合でも、豊かなマルチメディア体験を楽しむには、高速インターネット接続と十分なストレージ容量が必要です。AI はこれらの制限を克服するのに役立ちます: “接続が低いエリアで、ストールやグリッチが発生せずに友人の音声メッセージを聴くことを想像してみてください。”
このチュートリアルでは、オーディオのハイパー圧縮に OpenVINO と EnCodec アルゴリズムを使用する方法を検討します。EnCodec は、AI を活用して品質を損なうことなくオーディオファイルを圧縮する、リアルタイムの高忠実度オーディオコーデックです。高忠実度ニューラルオーディオ圧縮 で紹介された Meta AI による圧縮です。研究者らは、品質を損なうことなく約 10 倍の圧縮率を達成し、CD 品質のオーディオでも機能すると主張しています。このアプローチの詳細については、Meta AI のブログとオリジナルのリポジトリーを参照してください。
image.png#
目次:
必要条件#
ビルドに必要な依存関係をインストールします。
%pip install -q --extra-index-url https://download.pytorch.org/whl/cpu "openvino>=2023.3.0" "torch>=2.1" "torchaudio>=2.1" "encodec>=0.1.1" "gradio>=4.19" "librosa>=0.8.1" "matplotlib<=3.7" tqdmNote: you may need to restart the kernel to use updated packages.オーディオ圧縮パイプラインをインスタンス化#
データストリームのエンコーダーおよびデコーダーとして機能するコーデックは、現在オンラインで使用されているオーディオ圧縮のほとんどを強化します。一般的に使用されるコーデックには、MP3、Opus、EVS などがあります。これら古典的なコーデックは、信号を異なる周波数間で分解し、可能な限り効率的にエンコードしようとします。大部分の古典的なコーデックは、人間の聴覚の知識 (心理音響学) を活用していますが、ファイルを効率良くエンコードおよびデコードするため手作業で作成された方法のセットです。EnCodec は、入力信号を再構築するためエンドツーエンドでトレーニングされるニューラル・ネットワークであり、この制限を克服する試みとして導入されました。次の 3 つで構成されます:
エンコーダー : 非圧縮データを取り込み、それを高次元かつ低フレームレートの表現に変換します。
量子化器 : 表現をターゲットサイズに圧縮します。圧縮された表現はディスクに保存されるか、ネットワーク経由で送信されます。
デコーダーは最後のステップです。圧縮された信号を元の波形にできるだけ近い波形に戻します。可逆圧縮の鍵は、低ビットレートでは完全な再構成が不可能であるため、人間が認識できない変化を特定することです。
)
著者は、2 つのマルチ帯域幅モデルを提供しています: * encodec_model_24khz - さまざまなオーディオデータでトレーニングされたモノラルオーディオ 24 kHz で動作する因果モデル。* encodec_model_48khz - 音楽のみのデータでトレーニングされたステレオ 48 kHz で動作する非因果モデル。
このチュートリアルでは、例として encodec_model_24khz を使用しますが、encodec_model_48khz モデルにも適用できます。このモデルの使用を開始するには、EncodecModel.encodec_model_24khz() を使用してモデルクラスをインスタンス化し、使用可能な圧縮帯域幅の中から圧縮帯域幅を選択する必要があります。24 kHz モデルの場合は 1.5、3、6、12、24 kbps、48 kHz モデルの場合は 3、6、12、24 kbps。ここでは 6 kbps の帯域幅を使用します。
from encodec import compress, decompress
from encodec.utils import convert_audio, save_audio
from encodec.compress import MODELS
import torchaudio
import torch
import typing as tp
model_id = "encodec_24khz"
# 事前学習済み EnCodec モデルをインスタンス化
model = MODELS[model_id]()
model.set_target_bandwidth(6.0)/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/torch/nn/utils/weight_norm.py:28: UserWarning: torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.
warnings.warn("torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.")EnCodec パイプラインを探索#
オーディオの例でモデルの機能を調べてみましょう:
import librosa
import matplotlib.pyplot as plt
import librosa.display
import IPython.display as ipd
# `notebook_utils` モジュールを取得
import requests
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py",
)
open("notebook_utils.py", "w").write(r.text)
from notebook_utils import download_file
test_data_url = "https://github.com/facebookresearch/encodec/raw/main/test_24k.wav"
sample_file = "test_24k.wav"
download_file(test_data_url, sample_file)
audio, sr = librosa.load(sample_file)
plt.figure(figsize=(14, 5))
librosa.display.waveshow(audio, sr=sr)
ipd.Audio(sample_file)test_24k.wav: 0%| | 0.00/938k [00:00<?, ?B/s]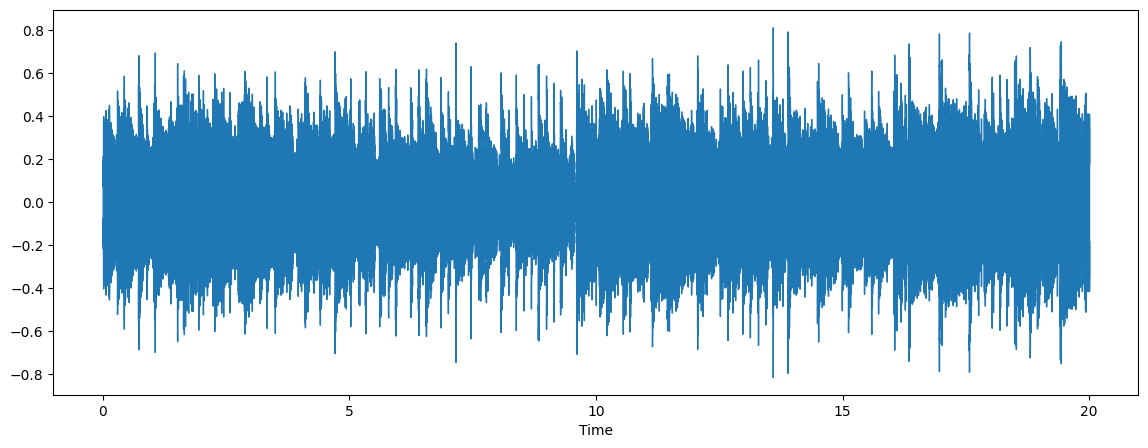
前処理#
最良の結果を達成するには、オーディオがモデルで予期されるチャネル数とサンプルレートを備えている必要があります。オーディオがこれらの要件を満たしていない場合、convert_audio 関数を使用して、要求されるサンプルレートとチャネル数に変換します。
model_sr, model_channels = model.sample_rate, model.channels
print(f"Model expected sample rate {model_sr}")
print(f"Model expected audio format {'mono' if model_channels == 1 else 'stereo'}")Model expected sample rate 24000
Model expected audio format mono# オーディオ波形を読み込み前処理
wav, sr = torchaudio.load(sample_file)
wav = convert_audio(wav, sr, model_sr, model_channels)エンコード#
オーディオ波形はチャンクごとに分割され、エンコーダー・モデルによってエンコードされ、メモリーを削減するために量子化器によって圧縮されます。圧縮後、ecdc 拡張子が付いたバイナリーファイルが生成されます。これは、EnCodec 圧縮オーディオの保存形式です。
from pathlib import Path
out_file = Path("compressed.ecdc")
b = compress(model, wav)
out_file.write_bytes(b)15067得られた圧縮結果を比較してみましょう:
import os
orig_file_stats = os.stat(sample_file)
compressed_file_stats = os.stat("compressed.ecdc")
print(f"size before compression in Bytes: {orig_file_stats.st_size}")
print(f"size after compression in Bytes: {compressed_file_stats.st_size}")
print(f"Compression file size ratio: {orig_file_stats.st_size / compressed_file_stats.st_size:.2f}")size before compression in Bytes: 960078 size after compression in Bytes: 15067 Compression file size ratio: 63.72これで完了です! ここで、ハイパー圧縮の効果がわかります。ファイルのバイナリーサイズは 60 分の 1 に小さくなり、ネットワーク経由での送信に適しています。
復元#
圧縮オーディオの送信に成功したら、受信側で復元する必要があります。デコーダーモデルは、圧縮された信号を元の波形に復元する役割を果たします。
out, out_sr = decompress(out_file.read_bytes())/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/torch/nn/utils/weight_norm.py:28: UserWarning: torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.
warnings.warn("torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.")output_file = "decopressed.wav"
save_audio(out, output_file, out_sr)復元が完了すると、展開されたオーディオは decompressed.wav ファイルに保存されます。結果は元のオーディオと比較できます。
audio, sr = librosa.load(output_file)
plt.figure(figsize=(14, 5))
librosa.display.waveshow(audio, sr=sr)
ipd.Audio(output_file)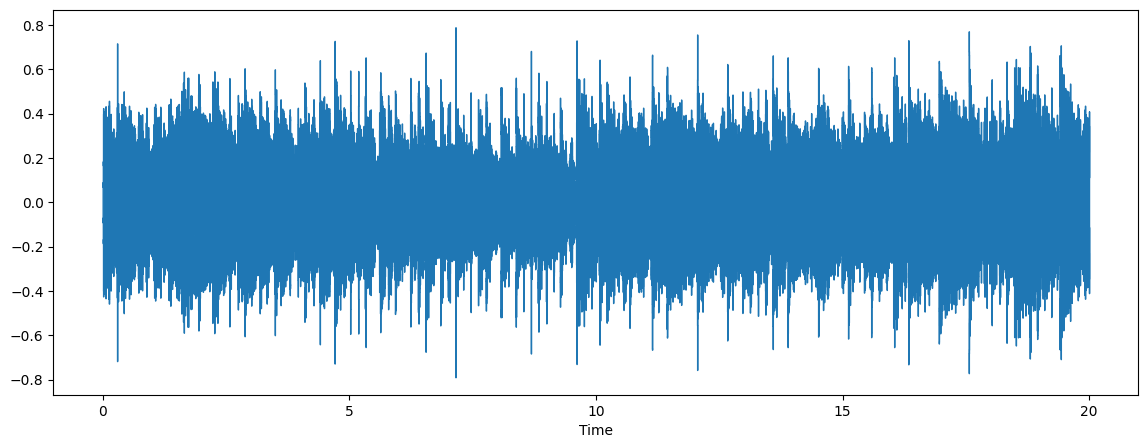
オーディオは原音に近い音になります。
モデルを OpenVINO 中間表現形式に変換#
OpenVINO で最良の結果を得るには、モデルを OpenVINO IR 形式に変換することを推奨します。OpenVINO は、OpenVINO IR 形式への変換を通じて PyTorch をサポートします。初期化されたモデルのインスタンスと、形状推論の入力例を提供する必要があります。ov.convert_model 機能を使用して PyTorch モデルを変換します。ov.convert_model 関数は、デバイスにロードして予測を開始できる状態の OpenVINO モデルを返します。ov.save_model を使用して、次回の利用のためディスクに保存できます。
class FrameEncoder(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = model
def forward(self, x: torch.Tensor):
codes, scale = self.model._encode_frame(x)
if not self.model.normalize:
return codes
return codes, scaleclass FrameDecoder(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = model
def forward(self, codes, scale=None):
return model._decode_frame((codes, scale))encoder = FrameEncoder(model)
decoder = FrameDecoder(model)import openvino as ov
core = ov.Core()
OV_ENCODER_PATH = Path("encodec_encoder.xml")
if not OV_ENCODER_PATH.exists():
encoder_ov = ov.convert_model(encoder, example_input=torch.zeros(1, 1, 480000), input=[[1, 1, 480000]])
ov.save_model(encoder_ov, OV_ENCODER_PATH)
else:
encoder_ov = core.read_model(OV_ENCODER_PATH)/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/encodec/modules/conv.py:60: TracerWarning: Converting a tensor to a Python float might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future.This means that the trace might not generalize to other inputs!
ideal_length = (math.ceil(n_frames) - 1) * stride + (kernel_size - padding_total) /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/encodec/modules/conv.py:85: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect.We can't record the data flow of Python values, so this value will be treated as a constant in the future.This means that the trace might not generalize to other inputs!
assert padding_left >= 0 and padding_right >= 0, (padding_left, padding_right) /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/encodec/modules/conv.py:87: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect.We can't record the data flow of Python values, so this value will be treated as a constant in the future.This means that the trace might not generalize to other inputs!
max_pad = max(padding_left, padding_right) /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/encodec/modules/conv.py:89: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect.We can't record the data flow of Python values, so this value will be treated as a constant in the future.This means that the trace might not generalize to other inputs!
if length <= max_pad:['x']OV_DECODER_PATH = Path("encodec_decoder.xml")
if not OV_DECODER_PATH.exists():
decoder_ov = ov.convert_model(
decoder,
example_input=torch.zeros([1, 8, 1500], dtype=torch.long),
input=[[1, 8, 1500]],
)
ov.save_model(decoder_ov, OV_DECODER_PATH)
else:
decoder_ov = core.read_model(OV_DECODER_PATH)/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/encodec/quantization/core_vq.py:358: TracerWarning: torch.tensor results are registered as constants in the trace. You can safely ignore this warning if you use this function to create tensors out of constant variables that would be the same every time you call this function. In any other case, this might cause the trace to be incorrect.
quantized_out = torch.tensor(0.0, device=q_indices.device) /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/encodec/quantization/core_vq.py:359: TracerWarning: Iterating over a tensor might cause the trace to be incorrect. Passing a tensor of different shape won't change the number of iterations executed (and might lead to errors or silently give incorrect results).
for i, indices in enumerate(q_indices): /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-727/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/encodec/modules/conv.py:103: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect.We can't record the data flow of Python values, so this value will be treated as a constant in the future.This means that the trace might not generalize to other inputs!
assert (padding_left + padding_right) <= x.shape[-1]['codes']OpenVINO を EnCodec パイプラインに統合#
OpenVINO を EnCodec パイプライン:に統合するには、次の手順が必要です:
モデルをデバイスにロードします。
オーディオフレーム処理関数を定義します。
オリジナルのフレーム処理関数を OpenVINO ベースのアルゴリズムに置き換えます。
推論デバイスの選択#
OpenVINO を使用して推論を実行するためにドロップダウン・リストからデバイスを選択します
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value="AUTO",
description="Device:",
disabled=False,
)
deviceDropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')compiled_encoder = core.compile_model(encoder_ov, device.value)
encoder_out = compiled_encoder.output(0)
compiled_decoder = core.compile_model(decoder_ov, device.value)
decoder_out = compiled_decoder.output(0)def encode_frame(x: torch.Tensor):
has_scale = len(compiled_encoder.outputs) == 2
result = compiled_encoder(x)
codes = torch.from_numpy(result[encoder_out])
if has_scale:
scale = torch.from_numpy(result[compiled_encoder.output(1)])
else:
scale = None
return codes, scaleEncodedFrame = tp.Tuple[torch.Tensor, tp.Optional[torch.Tensor]]
def decode_frame(encoded_frame: EncodedFrame):
codes, scale = encoded_frame
inputs = [codes]
if scale is not None:
inputs.append(scale)
return torch.from_numpy(compiled_decoder(inputs)[decoder_out])model._encode_frame = encode_frame
model._decode_frame = decode_frame
MODELS[model_id] = lambda: modelOpenVINO で EnCodec を実行#
OpenVINO を内部で使用して EnCodec を実行するプロセスは、元の PyTorch モデルと同様です。
b = compress(model, wav, use_lm=False)
out_file = Path("compressed_ov.ecdc")
out_file.write_bytes(b)15067out, out_sr = decompress(out_file.read_bytes())ov_output_file = "decopressed_ov.wav"
save_audio(out, ov_output_file, out_sr)audio, sr = librosa.load(ov_output_file)
plt.figure(figsize=(14, 5))
librosa.display.waveshow(audio, sr=sr)
ipd.Audio(ov_output_file)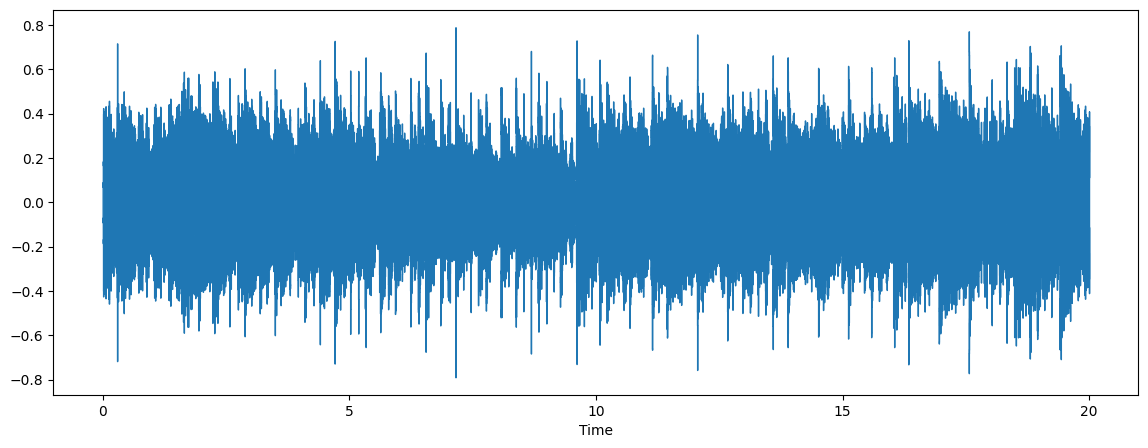
import gradio as gr
from typing import Tuple
import numpy as np
def preprocess(input, sample_rate, model_sr, model_channels):
input = torch.tensor(input, dtype=torch.float32)
input = input / 2**15 # int16 スケールに調整
input = input.unsqueeze(0)
input = convert_audio(input, sample_rate, model_sr, model_channels)
return input
def postprocess(output):
output = output.squeeze()
output = output * 2**15 # [-1, 1] スケールに調整
output = output.numpy(force=True)
output = output.astype(np.int16)
return output
def _compress(input: Tuple[int, np.ndarray]):
sample_rate, waveform = input
waveform = preprocess(waveform, sample_rate, model_sr, model_channels)
b = compress(model, waveform, use_lm=False)
out, out_sr = decompress(b)
out = postprocess(out)
return out_sr, out
demo = gr.Interface(_compress, "audio", "audio", examples=["test_24k.wav"])
try:
demo.launch(debug=False)
except Exception:
demo.launch(share=True, debug=False)
#リモートで起動する場合は、server_name と server_port を指定
# demo.launch(server_name='your server name', server_port='server port in int')
# 詳細については、ドキュメントをご覧ください: https://gradio.app/docs/ローカル URL で実行中: http://127.0.0.1:7860 パブリックリンクを作成するには、launch() で share=True を設定します。