handwritten-english-recognition-0001#
ユースケースと概要説明#
これは、手書き英語文字認識シナリオ用のネットワークです。これは、CNN と、それに続く Bi-LSTM、再形成レイヤー、および全結合レイヤーで構成されます。ネットワークは、GNHKT データセット内の文字で構成される英語テキストを認識できます。
例#
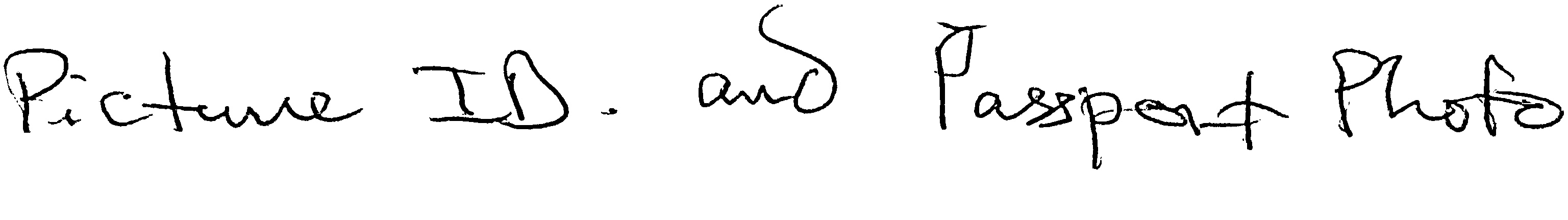 - >‘写真付き身分証明書とパスポート写真’
- >‘写真付き身分証明書とパスポート写真’
仕様#
メトリック |
値 |
|---|---|
GFlops |
1.3182 |
MParams |
0.1413 |
GNHK テストサブセットの精度 (アスペクト比で高さ 96px にサイズ変更した後の幅 2000px を超える画像を除く) |
82.0% |
ソース・フレームワーク |
PyTorch* |
注: 精度を達成するには、GNHK テストセットの画像をしきい値適応処理を使用して 2 値化し、GNHK データセット内の JSON アノテーション・ファイルの座標を使用して単一行のテキスト画像に前処理する必要があります。
<omz_dir>/models/intel/handwritten-english-recognition-0001/preprocess_gnhk.pyを参照。
このモデルは、精度のメトリックとしてラベル誤り率を採用します。
入力#
グレースケール・イメージ、名前 - actual_input、形状 - 1, 1, 96, 2000、形式 - B, C, H, W、ここで:
B- バッチサイズC- チャネル数H- 画像の髙さW- 画像の幅
注: ソース画像はアスペクト比を維持しながら特定の高さ (96 など) にサイズ変更する必要があり、変更後の幅は 2000 以下で、その後幅の右下をエッジ値で 2000 までパディングする必要があります。
出力#
名前 - output、形状 - 250, 1, 95、形式 - W, B, L、ここで:
W- 出力シーケンス長B- バッチサイズL- GNHK でサポートされているシンボル全体の信頼度分布。
ネットワーク出力は、CTC グリーディー・デコーダーでデコードできます。
ネットワークは、形状 2, 1, 256 の 10 個の LSTM 隠れ状態も出力しますが、これらは単純に無視できます。
デモの使い方#
このモデルは、Open Model Zoo が提供する次のデモで使用して、その機能を示します:
法務上の注意書き#
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。