action-recognition-0001 (複合)#
ユースケースと概要説明#
これは、Kinetics-400 データセットでトレーニングされた、エンコーダー部分とデコーダー部分で構成される汎用のアクション認識複合モデルです。エンコーダー・モデルは、ResNet34 エンコーダーを使用した Video Transformer アプローチを使用します。この複合モデルによって認識されるアクションのリストを確認するには、kinetics データセット仕様を参照してください。
例#
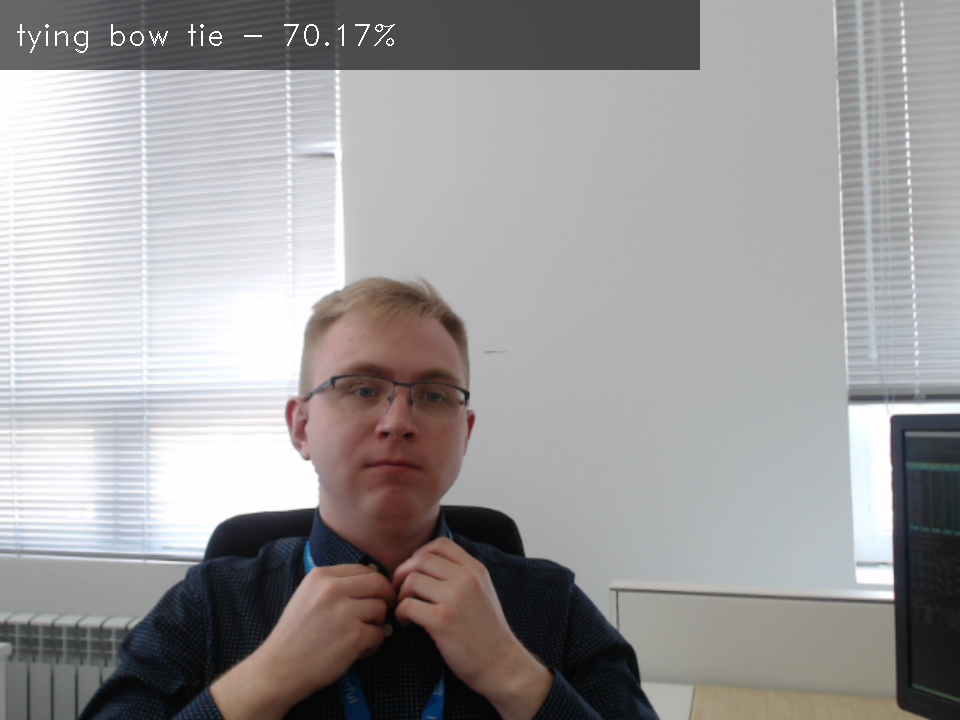
複合モデル仕様#
メトリック |
値 |
|---|---|
ソース・フレームワーク |
PyTorch* |
エンコーダー・モデル仕様#
action-recognition-0001-encoder モデルはビデオフレームを受け入れ、埋め込みを生成します。ビデオフレームは、約 1 秒のフラグメントをカバーするようにサンプリングする必要があります (つまり、30 fps ビデオでは 2 フレームごとにスキップします)。
メトリック |
値 |
|---|---|
GFlops |
7.340 |
MParams |
21.276 |
入力#
画像、名前: 0、形状: 1, 3, 224, 224、形式: B, C, H, W、ここで:
B- バッチサイズC- チャネル数H- 画像の髙さW- 画像の幅
予想される色の順序は BGR です。
出力#
モデルは、処理されたフレームの埋め込みを表す、形状 1, 512, 1, 1 のテンソルを出力します。
デコーダーモデル仕様#
action-recognition-0001-decoder モデルは、action-recognition-0001-encoder モデルによって計算されたフレーム埋め込みのスタックを受け入れます。
メトリック |
値 |
|---|---|
GFlops |
0.147 |
MParams |
4.405 |
入力#
埋め込みイメージ、名前: 0、形状: B, T, C、形式の 1, 16, 512、ここで:
B- バッチサイズT- 入力クリップの期間C- 埋め込み次元
出力#
モデルは、形状 1, 400 のテンソルを出力します。各行は、実行されたアクションのロジットベクトルです。
デモの使い方#
このモデルは、Open Model Zoo が提供する次のデモで使用して、その機能を示します:
法務上の注意書き#
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。