Smartlab Python* デモ#
これは、smartlab 物体検出アルゴリズムと Smartlab アクション認識アルゴリズムを備えたデモ・アプリケーションです。このデモでは、マルチビュー・ビデオ入力を取得してオブジェクトとアクションを識別し、教師の参考としてスコアを評価します。UI は次のように表示されます:
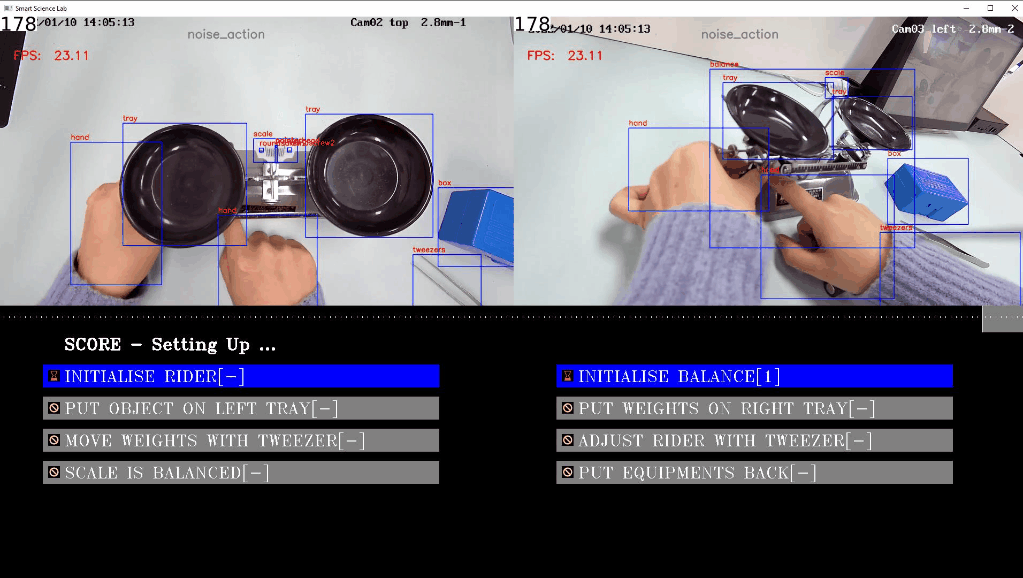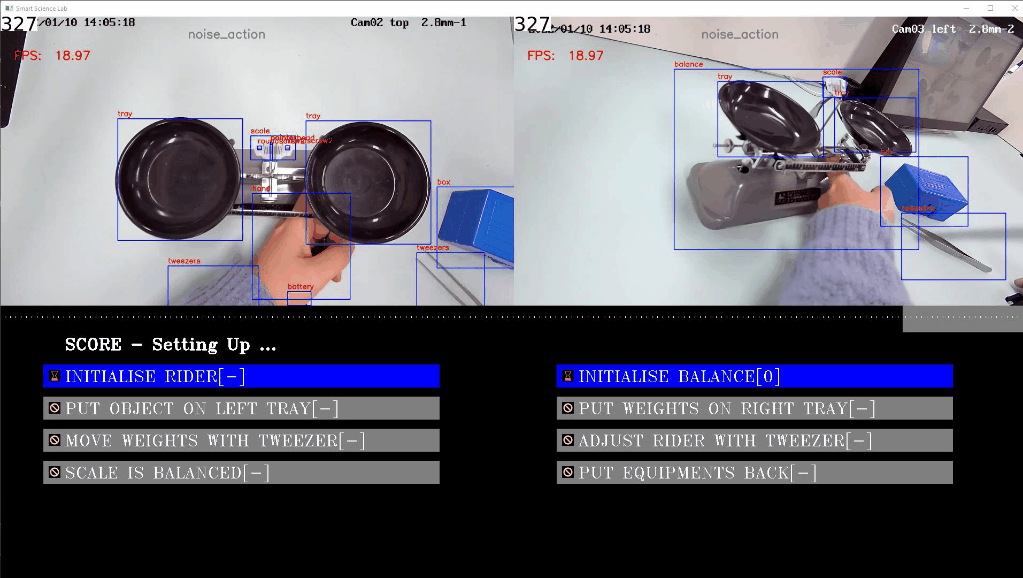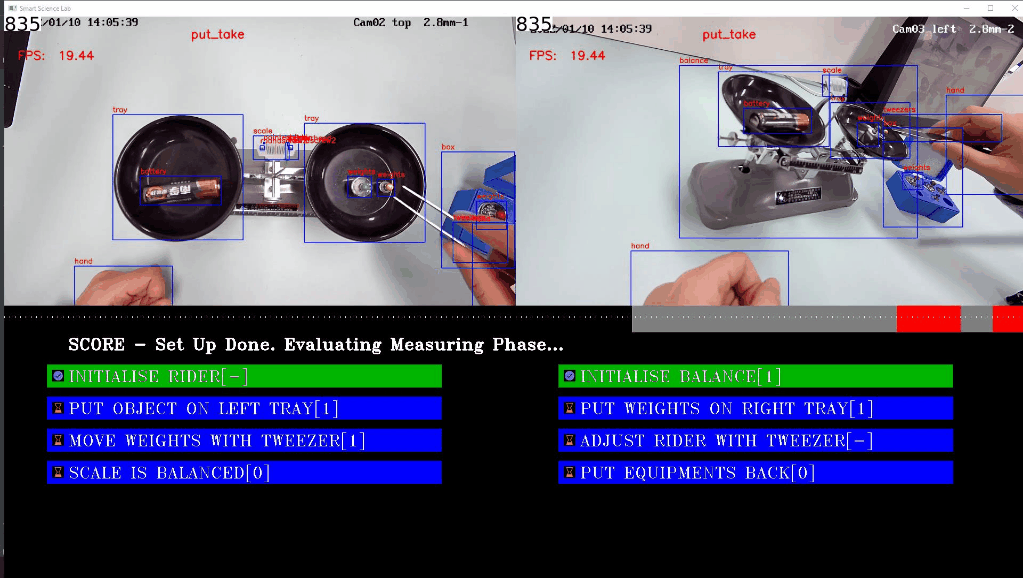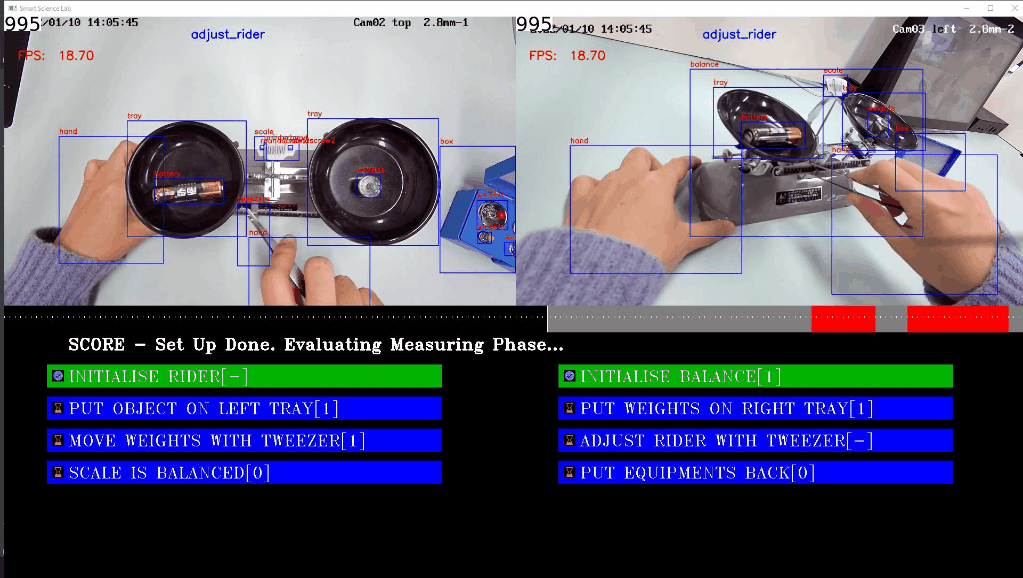 左の写真と右の写真は、それぞれテストベンチの上面図と側面図を示しています。物体検出部分では、青い境界ボックスが表示されます。この図の下には、アクションタイプの進行状況バーが表示され、アクションの色は上記のアクション名に対応しています。スコアリング部分は UI 全体の下にあり、スコアポイントは 8 つあります。
左の写真と右の写真は、それぞれテストベンチの上面図と側面図を示しています。物体検出部分では、青い境界ボックスが表示されます。この図の下には、アクションタイプの進行状況バーが表示され、アクションの色は上記のアクション名に対応しています。スコアリング部分は UI 全体の下にあり、スコアポイントは 8 つあります。[1] は生徒が 1 ポイントを獲得できることを意味し、[0] は生徒がポイントを失うことを意味します。[-] は評価中を意味します。
アルゴリズム
スマート・サイエンス・ラボのアーキテクチャーには、物体検出、アクション認識、スコアリング評価機能が含まれています。事前トレーニングされた次のモデルが製品に付属しています:
smartlab-object-detection-0001+smartlab-object-detection-0002+smartlab-object-detection-0003+smartlab-object-detection-0004は、天秤、分銅、ピンセット、箱、電池、トレイ、定規、ライダー、秤、手を含む 10 個の物体を検出するモデルです。
アクション認識には 2 つのオプションがあります:
–mode multiview:
smartlab-action-recognition-0001-encoder-top+smartlab-action-recognition-0001-encoder-side+smartlab-action-recognition-0001-decoderは、3 つのアクションタイプを識別します。–mode mstcn:
smartlab-sequence-modelling-0001+smartlab-sequence-modelling-0002は、14 のアクションタイプを識別します。
どのように動作するか#
デモのパイプラインはいくつかのステップで構成されます:
Decodeは 2 つの入力ビデオからフレームを読み取りますDetectorは物体を検出します (天秤、分銅、ピンセット、箱、バッテリー、トレイ、定規、ライダースケール、手)Segmentorはフレームのアクションタイプに基づいてビデオフレームをセグメント化して分類しますEvaluatorは現在の状態のスコアを与えますDisplayは UI 全体を表示します
実行の準備#
入力ビデオの例: https://storage.openvinotoolkit.org/data/test_data/videos/smartlab/v3。
デモでサポートされるモデルリストは、<omz_dir>/demos/smartlab_demo/python/models.lst ファイルにあります。このファイルは、モデル・ダウンローダーがダウンロードするパラメーターとして使用できます。モデル・ダウンローダーの使用例:
omz_downloader --list models.lstサポートされるモデル#
smartlab-object-detection-0001
smartlab-object-detection-0002
smartlab-object-detection-0003
smartlab-object-detection-0004
mode mtcnn
smartlab-sequence-modelling-0001
smartlab-sequence-modelling-0002
mode multiview
smartlab-action-recognition-0001-encoder-top
smartlab-action-recognition-0001-encoder-side
smartlab-action-recognition-0001-decoder
注: 各種デバイスでのモデル推論サポートの詳細については、インテルの事前トレーニング・モデルのデバイスサポートの表を参照してください。
実行する#
-h オプションを指定してデモを実行すると、ヘルプメッセージが表示されます:
usage: smartlab_demo.py [-h] [-d DEVICE] -tv TOPVIEW -sv SIDEVIEW -m_ta M_TOPALL -m_tm M_TOPMOVE -m_sa M_SIDEALL -m_sm M_SIDEMOVE [--mode MODE] [-m_en M_ENCODER] [-m_en_t M_ENCODER_TOP] [-m_en_s M_ENCODER_SIDE] -m_de M_DECODER [--no_show]
Options:
-h, --help Show this help message and exit.
-d DEVICE, --device DEVICE
Optional. Specify the target to infer on CPU or GPU.
-tv TOPVIEW, --topview TOPVIEW
Required. Topview stream to be processed. The input must be a single image, a folder of images, video file or camera id.
-sv SIDEVIEW, --sideview SIDEVIEW
Required. SideView to be processed. The input must be a single image, a folder of images, video file or camera id.
-m_ta M_TOPALL, --m_topall M_TOPALL
Required. Path to topview all class model.
-m_tm M_TOPMOVE, --m_topmove M_TOPMOVE
Required. Path to topview moving class model.
-m_sa M_SIDEALL, --m_sideall M_SIDEALL
Required. Path to sidetview all class model.
-m_sm M_SIDEMOVE, --m_sidemove M_SIDEMOVE
Required. Path to sidetview moving class model.
--mode MODE Optional.Action recognition mode: multiview or mstcn
-m_en M_ENCODER, --m_encoder M_ENCODER
Required for mstcn mode.Path to encoder model.
-m_en_t M_ENCODER_TOP, --m_encoder_top M_ENCODER_TOP
Required for multiview mode. Path to encoder model for top view.
-m_en_s M_ENCODER_SIDE, --m_encoder_side M_ENCODER_SIDE
Required for multiview mode. Path to encoder model for side view.
-m_de M_DECODER, --m_decoder M_DECODER
Required. Path to decoder model.
--no_show
Optional. Don't show output.例えば、multiview モードでデモを実行します:
python3 smartlab_demo.py
-tv stream_1_top.mp4
-sv stream_1_left.mp4
-m_ta "./intel/smartlab-object-detection-0001/FP32/smartlab-object-detection-0001.xml"
-m_tm "./intel/smartlab-object-detection-0002/FP32/smartlab-object-detection-0002.xml"
-m_sa "./intel/smartlab-object-detection-0003/FP32/smartlab-object-detection-0003.xml"
-m_sm "./intel/smartlab-object-detection-0004/FP32/smartlab-object-detection-0004.xml"
-m_en_t "./intel/smartlab-action-recognition-0001/smartlab-action-recognition-0001-encoder-top/FP32/smartlab-action-recognition-0001-encoder-top.xml"
-m_en_s "./intel/smartlab-action-recognition-0001/smartlab-action-recognition-0001-encoder-side/FP32/smartlab-action-recognition-0001-encoder-side.xml"
-m_de "./intel/smartlab-action-recognition-0001/smartlab-action-recognition-0001-decoder/FP32/smartlab-action-recognition-0001-decoder.xml"mstcn モードでデモを実行します:
python3 smartlab_demo.py
-tv stream_1_top.mp4
-sv stream_1_left.mp4
-m_ta "./intel/smartlab-object-detection-0001/FP32/smartlab-object-detection-0001.xml"
-m_tm "./intel/smartlab-object-detection-0002/FP32/smartlab-object-detection-0002.xml"
-m_sa "./intel/smartlab-object-detection-0003/FP32/smartlab-object-detection-0003.xml"
-m_sm "./intel/smartlab-object-detection-0004/FP32/smartlab-object-detection-0004.xml"
--mode mstcn
-m_en "./intel/sequence_modelling/FP32/smartlab-sequence-modelling-0001.xml"
-m_de "./intel/sequence_modelling/FP32/smartlab-sequence-modelling-0002.xml"デモの出力#
アプリケーションは OpenCV を使用してオンライン結果を表示します。