3D 人物の姿勢推定 Python* デモ#

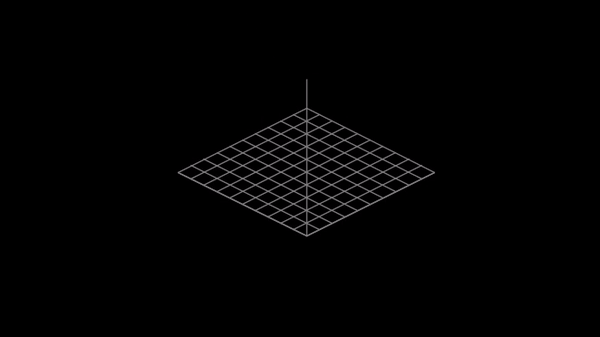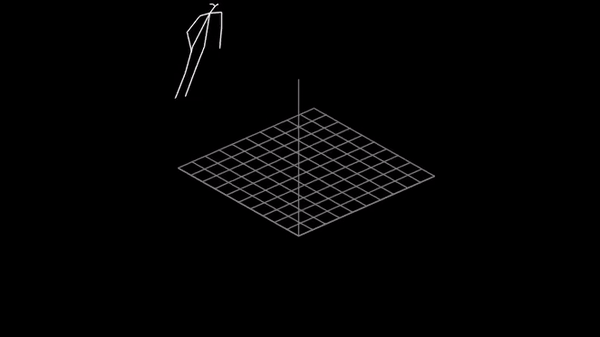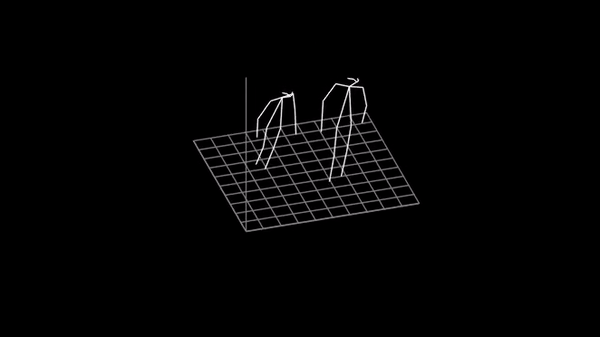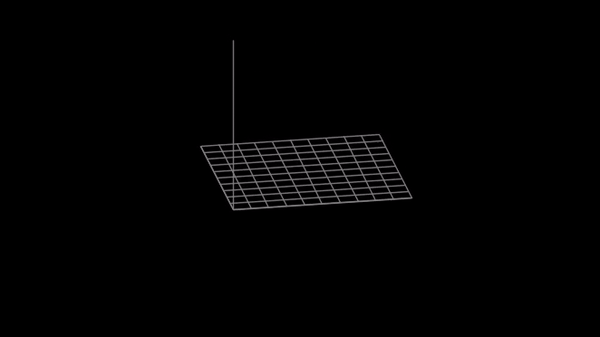
このデモでは、OpenVINO™ を使用して 3D 人物の姿勢推定モデルを実行する方法を示します。
注: バッチサイズ 1 のみがサポートされます。
どのように動作するか#
デモ・アプリケーションは、中間表現 (IR) 形式の 3D 人物の姿勢推定モデルを想定しています。
デモ・アプリケーションは入力として次を受け取ります:
ビデオファイルまたは Web カメラのデバイスノードへのパス。
画像パスのリスト。
デモのワークフローを次に示します:
デモ・アプリケーションはビデオフレームを 1 枚ずつ読み取り、指定されたフレーム内の 3D 人物のポーズを推定します。
このアプリケーションは、ワークの結果を入力画像にオーバーレイされた 2D ポーズを含むグラフィカル・ウィンドウとして視覚化し、対応する 3D ポーズを含むキャンバスを表示します。
注: デフォルトでは、Open Model Zoo のデモは BGR チャネル順序での入力を期待します。RGB 順序で動作するようにモデルをトレーニングした場合は、サンプルまたはデモ・アプリケーションでデフォルトのチャネル順序を手動で再配置するか、
--reverse_input_channels引数を指定したモデル・オプティマイザー・ツールを使用してモデルを再変換する必要があります。引数の詳細については、[前処理計算の埋め込み](@ref openvino_docs_MO_DG_Additional_Optimization_Use_Cases) の入力チャネルを反転するセクションを参照してください。
実行の準備#
デモの入力画像またはビデオファイルについては、Open Model Zoo デモの概要のデモに使用できるメディアファイルのセクションを参照してください。デモでサポートされるモデルリストは、<omz_dir>/demos/human_pose_estimation_3d_demo/python/models.lst ファイルにあります。このファイルは、モデル・ダウンローダーおよびコンバーターのパラメーターとして使用され、モデルをダウンロードし、必要に応じて OpenVINO IR 形式 (*.xml + *.bin) に変換できます。
モデル・ダウンローダーの使用例:
omz_downloader --list models.lstモデル・コンバーターの使用例:
omz_converter --list models.lstサポートされるモデル#
human-pose-estimation-3d-0001
注: 各種デバイス向けのモデル推論サポートの詳細については、インテルの事前トレーニング・モデルのデバイスサポートとパブリックの事前トレーニング・モデルのデバイスサポートの表を参照してください。
必要条件#
このデモ・アプリケーションを実行するには、ネイティブ Python 拡張モジュールをビルドする必要があります。デモをビルドし、実行する環境を準備する方法については、Open Model Zoo のデモを参照してください。Python 拡張モジュールを使用してデモをビルドしたら、デモのビルドフォルダーのパスを PYTHONPATH 環境変数に追加します。
実行する#
-h オプションを指定してアプリケーションを実行すると、使用方法が表示されます:
usage: human_pose_estimation_3d_demo.py [-h] -m MODEL -i INPUT [--loop]
[-o OUTPUT] [-limit OUTPUT_LIMIT]
[-d DEVICE] [--height_size HEIGHT_SIZE]
[--extrinsics_path EXTRINSICS_PATH]
[--fx FX] [--no_show]
[-u UTILIZATION_MONITORS]
Lightweight 3D human pose estimation demo.Press esc to exit, "p" to (un)pause video or process next image.
Options:
-h, --help Show this help message and exit.
-m MODEL, --model MODEL
Required.Path to an .xml file with a trained model.
-i INPUT, --input INPUT
Required.An input to process.The input must be a single image,
a folder of images, video file or camera id.
--looploop
Optional.Enable reading the input in a loop.
-o OUTPUT, --output OUTPUT
Optional.Name of the output file(s) to save.Frames of odd width or height
can be truncated.See https://github.com/opencv/opencv/pull/24086
-limit OUTPUT_LIMIT, --output_limit OUTPUT_LIMIT
Optional.Number of frames to store in output.If 0 is set, all frames are stored.
-d DEVICE, --device DEVICE
Optional.Specify the target device to infer on:
CPU or GPU.The demo will look for a suitable plugin for device specified
(by default, it is CPU).
--height_size HEIGHT_SIZE
Optional. Network input layer height size.
--extrinsics_path EXTRINSICS_PATH
Optional. Path to file with camera extrinsics.
--fx FX
Optional. Camera focal length.
--no_showno_show
Optional. Do not display output.
-u UTILIZATION_MONITORS, --utilization_monitors UTILIZATION_MONITORS
Optional.List of monitors to show initially.オプションの空のリストを指定してアプリケーションを実行すると、短い使用法メッセージとエラーメッセージが表示されます。
デモを実行するには、IR 形式のモデルと入力ビデオまたは画像へのパスを指定します。
python human_pose_estimation_3d_demo.py \
-m <path_to_model>/human-pose-estimation-3d-0001.xml \
-i <path_to_video>/video_name.mp4注: 単一の画像を入力として指定すると、デモはすぐに処理してレンダリングし終了します。推論結果を画面上で継続的に視覚化するには、
loopオプションを適用します。これにより、単一の画像がループで処理されます。
-o オプションを使用すると、処理結果を Motion JPEG AVI ファイル、または別の JPEG または PNG ファイルに保存できます:
処理結果を AVI ファイルに保存するには、
avi拡張子を付けた出力ファイル名を指定します (例:-o output.avi)。処理結果を画像として保存するには、出力画像ファイルのテンプレート名を拡張子
jpgまたはpngで指定します (例:-o output_%03d.jpg)。実際のファイル名は、実行時に正規表現%03dをフレーム番号に置き換えることによってテンプレートから構築され、output_000.jpg、output_001.jpgなどになります。カメラなど連続入力ストリームでディスク領域のオーバーランを避けるため、limitオプションを使用して出力ファイルに保存されるデータの量を制限できます。デフォルト値は 1000 です。これを変更するには、-limit Nオプションを適用します。ここで、Nは保存するフレームの数です。
注: Windows* システムには、デフォルトでは Motion JPEG コーデックがインストールされていない場合があります。この場合、OpenVINO ™ インストール・パッケージに付属する、
<INSTALL_DIR>/opencv/ffmpeg-download.ps1にある PowerShell スクリプトを使用して OpenCV FFMPEG バックエンドをダウンロードできます。OpenVINO ™ がシステムで保護されたフォルダーにインストールされている場合 (一般的なケース)、スクリプトは管理者権限で実行する必要があります。あるいは、結果を画像として保存することもできます。
デモの出力#
このアプリケーションは OpenCV を使用して推定されたポーズを表示します。デモレポート
FPS: ビデオフレーム処理の平均レート (1 秒あたりのフレーム数)。
レイテンシー: 1 フレームの処理 (フレームの読み取りから結果の表示まで) に必要な平均時間。これらのメトリックの両方を使用して、アプリケーション・レベルのパフォーマンスを測定できます。