次の図は、インテル® VTune™ プロファイラーを使用して、インテル® メニー・インテグレーテッド・コア (インテル® MIC) アーキテクチャー・ベースのインテル® Xeon Phi™ プロセッサー (開発コード名 Knights Landing と Knights Mill) で実行されるアプリケーションの解析とシステム全体の解析に必要な基本的な手順を示します。解析は、インテル® Xeon Phi™ プロセッサーのセルフブート版を搭載した Linux* ターゲットでサポートされます。事前定義解析タイプの HPC パフォーマンス特性、メモリーアクセス、マイクロアーキテクチャー全般、ホットスポットを実行するか、カスタム解析タイプを作成できます。
注
ユーザーモード・サンプリング・モードのホットスポットやスレッド化解析などのインストルメント・ベースの収集では、ワーカースレッド数が多いとオーバーヘッドが大きくなることがあります。代わりに、ハードウェア・イベントベース・サンプリング・モードのホットスポット解析や HPC パフォーマンス特性解析を使用して、アプリケーションのスケーラビリティーを調査します。
注
このワークフローは、解析処理を高速に行う推奨される手順です。インテル® Xeon Phi™ プロセッサー上でインテル® VTune™ プロファイラーの完全な収集を行うことは可能ですが、ファイナライズと視覚化に時間がかかる場合があります。ターゲットのインテル® Xeon Phi™ プロセッサー上で、通常の解析フローを直接実行できます。
必要条件
HPC パフォーマンス特性、メモリーアクセス、マイクロアーキテクチャー全般、またはホットスポット (ハードウェア・イベントベース・サンプリング・モード) などのハードウェア・イベントベース・サンプリング収集タイプでは、サンプリング・ドライバーをインストールすることを推奨します。サンプリング・ドライバーがインストールされていない場合、インテル® VTune™ プロファイラーは Linux* Perf* を使用して動作します。次のシステム構成の設定に注意してください。
メモリーアクセス解析と HPC パフォーマンス特性解析タイプの一部である DRAM と MCDRAM メモリー帯域幅の測定を可能にする、システム全体の収集とアンコアイベント収集を有効にするには、root または sudo で /proc/sys/kernel/perf_event_paranoid を 0 に設定します。
echo 0>/proc/sys/kernel/perf_event_paranoidマイクロアーキテクチャー全般解析タイプの収集を有効にするには、オープンファイル記述子のデフォルトの最大数を増やします。root または sudo で /etc/security/limits.conf のデフォルト値を 100*<number_of_logical_CPU_cores> に増やします。
<user> hard nofile <100 * number_of_logic_CPU_cores>
<user> soft nofile <100 * number_of_logic_CPU_cores>
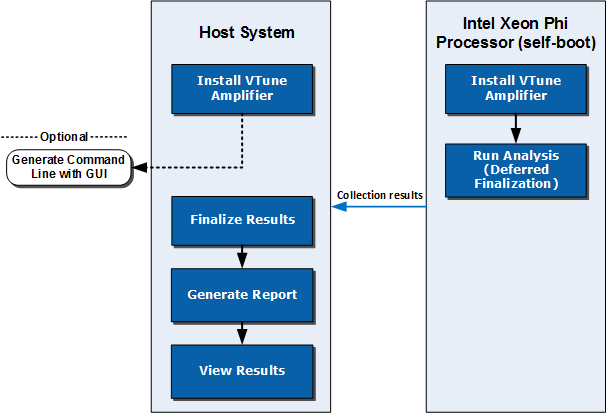
1.インテル® Xeon Phi™ プロセッサーを搭載するターゲットシステムで解析を設定して実行
ターゲットシステムで解析を設定して実行するには、次の 2 つの方法があります。
ホスト上でファイナライズ (推奨): コマンドラインを使用して、ファイナライズを行わずにインテル® Xeon Phi™ プロセッサーを搭載したシステムで解析を実行します。このオプションは高速に実行できます。
コマンドプロンプトから、ファイナライズ遅延オプションで収集を実行します。このオプションは、ホストシステムでシンボル解決を適切に行えるようにバイナリーのチェックサムのみを計算します。メモリーアクセス解析を実行する前に、次の操作を行います。
vtune -collect memory-access -finalization-mode=deferred -r <my_result_dir> ./my_app詳細については、vtune コマンド構文と finalization-mode を参照してください。
ヒント
また、次のようにインテル® VTune™ プロファイラーの GUI からコマンドを生成することもできます。コマンドを生成した後に、-finalization-mode=deferred オプションをコマンドに追加してファイナライズを遅延させます。
ターゲットシステムでファイナライズ。ホストシステムでインテル® VTune™ プロファイラーの GUI を使用して、インテル® Xeon Phi™ プロセッサーを搭載したターゲットシステム向けのコマンドを生成します。ターゲットシステムで解析を実行およびファイナライズします。この方法では高速に結果を得られない可能性があります。
[どこを] ペインで、[任意のホスト] ボタンを選択し、ハードウェア・プラットフォームに [インテル® Xeon Phi™ プロセッサー開発コード名 Knights Landing] を設定して、オペレーティング・システムのタイプを指定します。
[何を] ペインで [アプリケーションを起動] を選択して解析を設定します。
アプリケーション名と引数を入力します。
[MPI ランチャーを使用] チェックボックスをオンにして、使用するランチャー、ランク数、プロファイルするランク、および結果を格納する場所を指定します。
[どのように] ペインで、解析タイプを選択および設定します。
ウィンドウの下部の [コマンドライン] ボタンをクリックしてコマンドを生成します。
生成されたコマンドをターゲットシステムのコマンドプロンプトにコピーして解析を実行します。解析が終了するとファイナライズが始まります。ファイナライズには時間がかかります。
2.ホストシステム上で結果を開く
結果をホストシステムにコピーします (ターゲットシステムで収集された結果がホストと共有されていない場合)。コマンドでファイナライズの遅延を指定した場合、ファイナライズを行います。
SSH などを使用して結果をホストシステムにコピーします。
[オプション] モジュールへのパスがターゲットシステムと異なる場合、結果ファイルと検索ディレクトリーを適切なバイナリーに指定して結果をファイナライズします。次に例を示します。
vtune -finalize -r <my_result_dir> -search-dir <my_binary_dir>
3.解析結果を開いて解釈する
結果を表示する方法は 2 つあります。
収集したデータを基にレポート作成コマンドを実行して、コマンドラインで結果を参照します。例えば、次のコマンドはホットスポット・レポートを作成します。
vtune -report hotspots -r <my_result_dir>ホストシステムでインテル® VTune™ プロファイラーを起動して結果ファイルを表示します。
インテル® VTune™ プロファイラーのヘルプを開きます。
結果ファイルを参照するには、ツールバーやメニューボタンから [結果を開く] アクションを選択します。
結果を解析してアプリケーションを最適化してください。