インテル® VTune™ プロファイラーのメモリーアクセス解析を使用して、NUMA の問題や帯域幅に制限されたアクセスなど、メモリー関連の問題を特定し、パフォーマンス・イベントをメモリー・オブジェクト (データ構造) に分類します。これは、メモリー割り当て/解放のインストルメントと、シンボル情報からの静的/グローバル変数の取得によって提供されます。
注
インテル® VTune™ プロファイラーは、インテル® VTune™ Amplifier の後継バージョンであり、名称が変更されました。
どのように動作するか
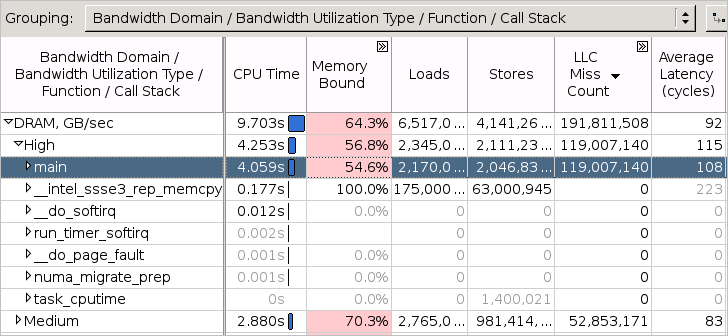
メモリーアクセス解析タイプは、ハードウェア・イベントベース・サンプリングを使用して、以下のメトリックのデータを収集します。
ロード数とストア数を示す [ロード] と [ストア] メトリック
ラスト・レベル・キャッシュのミスの合計数を示す [LLC ミスカウント] メトリック
ローカルメモリーで処理された LLC ミスの合計数を示す [ローカル DRAM アクセスカウント] メトリック
リモート・ソケット・メモリーへのアクセス数を示す [リモート DRAM アクセスカウント] メトリック
リモート・ソケット・キャッシュへのアクセス数を示す [リモート・キャッシュ・アクセス・カウント] メトリック
要求ロードまたはストア命令の待機に費やされたサイクルの割合を示す [メモリー依存] メトリック
マシンが L1 データキャッシュをミスせずにストールしている頻度を示す [L1 依存] メトリック
マシンが L2 キャッシュでストールしている頻度を示す [L2 依存] メトリック
CPU が L3 キャッシュでストールしたか、兄弟コアと競合した割合を示す [L3 依存] メトリック
負荷がないシナリオで L3 キャッシュにヒットする要求ロードアクセスのサイクルの割合 (L3 レイテンシーの制限による可能性) を示す [L3 レイテンシー] メトリック
リモート DRAM に対するメモリー要求の割合を示す [NUMA: リモートアクセスの %] メトリック (低い値が良い)
CPU がメインメモリー (DRAM) でストールしている頻度を示す [DRAM 依存] メトリック。のメトリックと次のメトリックを使用して、[DRAM 帯域幅依存]、[UPI 利用率依存]、[メモリーレイテンシー] の問題を特定できます。
ローカル DRAM ロードに対するリモート DRAM ロードの比率によって定義される [リモート / ローカル DRAM 比率] メトリック
CPU がローカルメモリーからのロードでストールしている頻度を示す [ローカル DRAM] メトリック
CPU がリモートメモリーからのロードでストールしている頻度を示す [リモート DRAM] メトリック
ほかのソケットのリモートキャッシュからのロードで CPU がストールした頻度を示す [リモートキャッシュ] メトリック
ロードの平均レイテンシーをサイクル数で示す [平均レイテンシー] メトリック
注
メトリックの一覧は、マイクロアーキテクチャーによって異なります。
UPI 利用率メトリックは、インテル® マイクロアーキテクチャー開発コード名 Skylake ベースのシステムで QPI 利用率に代わるものです。
メモリーアクセス解析で使用される多くの収集イベントはプリサイス (正確) です。これにより、データ・アクセス・パターンが分かりやすくなります。オフコアのトラフィックは、ローカル DRAM とリモート DRAM アクセスに区分されます。通常、コストが高いリモート DRAM アクセスを最小限に抑えることに集中します。
解析の設定と実行
次のようにメモリーアクセス解析のオプションを設定します。
必要条件: プロジェクトを作成します。
インテル® VTune™ プロファイラー・ツールバーの
 (スタンドアロン GUI)/
(スタンドアロン GUI)/ (Visual Studio* IDE) [解析の設定] ボタンをクリックします。
(Visual Studio* IDE) [解析の設定] ボタンをクリックします。[解析の設定] ウィンドウが表示されます。
[どのように] ペインで、
 [実行する解析タイプを選択] ボタンをクリックして、[メモリーアクセス] を選択します。
[実行する解析タイプを選択] ボタンをクリックして、[メモリーアクセス] を選択します。次のオプションを設定します。
[CPU サンプリング間隔 (ミリ秒)] フィールド
CPU サンプル間の間隔を指定します (ミリ秒)。
設定可能な値は、0.01 - 1000 です。
デフォルト値は 1 ミリ秒です。
[動的メモリー・オブジェクトを解析] チェックボックス (Linux* のみ)
動的メモリーの割り当て/解放のインストルメントとメモリー・オブジェクトのハードウェア・イベントへのマップを有効にします。このオプションは、すべてのシステムメモリーの割り当て/解放をインストルメントするため、実行時にオーバーヘッドが生じる可能性があります。
このオプションは、デフォルトで無効になっています。
[追跡する最小動的メモリー・オブジェクト・サイズ (バイト)] スピンボックス (Linux* のみ)
解析に使用する動的メモリー割り当ての最小サイズを指定します。このオプションは、インストルメントの実行時のオーバーヘッドを軽減するのに有効です。
デフォルト値は 1024 です。
[DRAM の最大帯域幅を評価] チェックボックス
収集を開始する前に、達成可能な最大 DRAM 帯域幅を評価します。このデータは、タイムライン上で帯域幅メトリックをスケールし、しきい値を計算するために使用されます。
このオプションは、デフォルトで有効になります。
[OpenMP* 領域を解析] チェックボックス
インバランス、ロック競合、またはスケジュール、リダクション、およびアトミック操作のオーバーヘッドなどの非効率性を特定するため、OpenMP* 領域をインストルメントして解析します。
このオプションは、デフォルトで無効になっています。
[詳細] ボタン
この解析タイプのデフォルトの編集不可設定のリストを展開/折りたたみます。解析の設定を変更したり、追加の設定を有効にするには、既存の事前定義設定をコピーしてカスタム設定を作成する必要があります。インテル® VTune™ プロファイラーは、解析タイプ設定の編集可能なコピーを作成します。
 [開始] ボタンをクリックして解析を実行します。
[開始] ボタンをクリックして解析を実行します。
制限:
メモリー・オブジェクト解析は、Linux* ターゲットとインテル® マイクロアーキテクチャー開発コード名 Sandy Bridge 以降のマイクロプロセッサーでのみ設定できます。
データを表示
解析では、次のウィンドウを含む [メモリー使用] ビューポイントを調査します。
[サマリー] ウィンドウには、アプリケーション・レベルの帯域幅利用率分布図を含む、アプリケーション全体の実行に関する統計が表示されます。
[ボトムアップ] ウィンドウには、各ホットスポット・オブジェクトのメトリックごとのパフォーマンス・データが表示されます。データ収集の [メモリー・オブジェクトの解析] オプションを有効にすると、[ボトムアップ] ウィンドウのグリッドと [コールスタック] ペインにメモリー割り当てのコールスタックも表示されます。割り当て呼び出しのソースの場所として、メモリー・オブジェクトを表示するには、メモリー・オブジェクトの前に関数レベルがあるグループ化レベルを使用します。
[プラットフォーム] ウィンドウは、タスク API、Ftrace/Systrace イベントタスク、OpenCL* API タスクなどを使用するコードで指定されたタスクの詳細情報を示します。対応するプラットフォームのメトリックが収集されると、[プラットフォーム] ウィンドウには、ソフトウェア・キューの GPU 利用率、CPU 時間使用量、OpenCL* カーネルデータ、そして GPU パフォーマンス・メトリックの概要グループごとの GPU ハードウェア、メモリー帯域幅、および CPU 周波数のデータを時系列で表示されます。
サポートの制限
メモリーアクセス解析は、次のプラットフォームでサポートされます。
第 2 世代インテル® Core™ プロセッサー
インテル® Xeon® プロセッサー・ファミリー以降
第 3 世代 Intel Atom® プロセッサー・ファミリー以降
古いプロセッサーを解析する場合、カスタム解析を作成してメモリーアクセスに関連するイベントを選択できます。ただし、それらのプロセッサーでサポートされるメモリー関連のイベントに制限されます。プロセッサーごとのメモリー・アクセス・イベントについては、「インテル® VTune™ プロファイラーのチューニング・ガイド」 (英語) を参照してください。
Linux* 上の動的メモリー・オブジェクト解析では、インテル® VTune™ プロファイラーは次のメモリー割り当て API をインストルメントします。
標準システムメモリー割り当て API: mmap、malloc/free、calloc、など
memkind - https://github.com/memkind/memkind (英語)
jemalloc - https://github.com/memkind/jemalloc (英語)
pmdk - https://github.com/pmem/pmdk (英語)