インテル® VTune™ プロファイラーを使用して、キャッシュミス (L1/L2/LLC)、メモリーロード/ストア、メモリー帯域幅、およびシステムメモリーの割り当て/解放を解析し、メモリー使用量の多いアプリケーションの高帯域幅と NUMA の問題を特定します。
次の解析タイプを実行してメモリー使用データを解析できます。
メモリーアクセス解析
[メモリー帯域幅を解析] オプションを有効にしたマイクロアーキテクチャー全般解析
[メモリー帯域幅を解析] オプションを有効にした HPC パフォーマンス特性解析
解析が完了すると、インテル® VTune™ プロファイラーは [メモリー使用] ビューポイントを開きます。このビューポイントでは、メモリーアクセスに関連するイベントベースのメトリックごとのデータが表示されます。それぞれのメトリックは、インテル® アーキテクチャーで定義されているイベント比率と事前定義された固有のしきい値を持っています。インテル® VTune™ プロファイラーは、それぞれのプログラム単位 (関数など) で収集された比率値を解析します。この値がしきい値を超え、プログラム単位の CPU 時間が収集された CPU 時間全体の 5% を上回ると、潜在的なパフォーマンスの問題を示すため、その値はピンク色で強調表示されます。
解析で示されるパフォーマンス・データを解釈するには、次のステップに従います。
トポロジー、メモリー、およびソケット間の帯域幅を解析します
[メモリー使用] ビューポイントの [サマリー] ウィンドウで、パフォーマンス解析を開始します。ここで、[プラットフォーム分布図] は、DRAM、インテル® UPI リンク、および物理コアのシステムトポロジーと利用率のメトリックを示します。
アプリケーションのトポロジーが最適でない場合、DRAM とインテル® QuickPath インターコネクト (インテル® QPI) またはインテル® Ultra Path インターコネクト (インテル® UPI) のソケット間でトラフィックが発生する可能性があります。これらはパフォーマンスを制限する可能性があります。

注
プラットフォーム分布図は以下で利用できます。
- すべてのクライアント・プラットフォーム
- インテル® マイクロアーキテクチャー開発コード名 Skylake ベースのサーバー・プラットフォーム (最大 4 ソケットまで)。
- インテル® マイクロアーキテクチャー 開発コード名 Sapphire Rapids ベースのサーバー・プラットフォーム。
フォーム分布図の高帯域幅メモリーデータ
インテル マイクロアーキテクチャー 開発コード名 Sapphire Rapids ベースのサーバー・プラットフォームでは、フォーム分布図に高帯域幅メモリー (HBM) に関する情報が含まれます。この情報で DRAM 固有の利用状況を区別することができます。
例えば、この図はシステムに DRAM が搭載されていない HBM モードの利用率に関する情報を示しています。

HBM と DRAM の両方を備えるシステムのフォーム分布図データの例を示します。

[解析の設定]で [DRAM の最大帯域幅を評価] オプションを選択した場合、プラットフォーム分布図は [最大 DRAM 利用率] を示します。それ以外は、[平均 DRAM 利用率] を示します。
平均 UPI 利用率メトリックは、送信の観点から UPI 利用率を表示します。パッケージペアを接続する UPI リンク数に関わりなく、プラットフォーム分布図は単一のソケット接続を示します。複数のリンクがある場合、分布図には最大値が表示されます。
それぞれのソケットの上部には、解析中のアプリケーションの計算による物理コアの利用率を示す平均物理コア利用率メトリックが表示されます。
分布図のトポロジーと利用率に関する情報を確認したら、[サマリー] ウィンドウの別のセクションに移動し、[ボトムアップ] と [プラットフォーム] ウィンドウに切り替えます。
メモリー・オブジェクトでパフォーマンス・メトリックを表示 (Linux* ターゲットのみ)
メモリーアクセス解析で [動的メモリー・オブジェクトを解析] 設定オプションを有効にすると、[メモリー使用] ビューポイントでメモリー・オブジェクト (変数、データ構造体、配列) ごとのパフォーマンス・メトリックを表示できます。
注
メモリー・オブジェクトの識別は、Linux* ターゲットとインテル® マイクロアーキテクチャー開発コード名 Sandy Bridge 以降のマイクロプロセッサーでサポートされます。Windows* では、キャッシュラインでグループ化して、コードに関連するメトリックを確認し、アクセスするデータ構造を理解できます。
メモリー・オブジェクトにはいくつかのタイプがあります。
動的メモリー・オブジェクトは、malloc、new、および類似した関数を使用してヒープ上に割り当てられます。このようなオブジェクトは、割り当てが行われた行単位 (例えば、malloc 関数が呼び出された行) で識別されます。
グローバルオブジェクトは、グローバルもしくは静的変数です。このようなオブジェクトは、モジュールと変数名によって識別されます。例えば、libiomp5.sp!_kmp_avail_proc (4B)。ここで 4B は割り当てサイズです。
スタックオブジェクトは、ローカル変数です。インテル® VTune™ プロファイラーは個別の変数を認識しないため、すべてのスタックメモリー参照は 1 つのオブジェクト名 [スタック] に関連付けられます。
メモリー・オブジェクト・データでは、[ボトムアップ] タブをクリックして [メモリー・オブジェクト] または [メモリー・オブジェクト割り当てソース] を含むグループ化レベルを選択します。[メモリー・オブジェクト] 粒度は、個々の割り当て (呼び出しサイトとサイズ) によってデータをグループ化し、[メモリー・オブジェクト割り当てソース] は割り当てが行われた場所によってグループ化します。
DLA 対応のハードウェア・イベントベースのメトリックのみが、メモリー・オブジェクト解析に適用されます。例えば、CPU 時間メトリックは、DLA 非対応のクロックティックをベースとするため、メモリー・オブジェクトには適用できません。適用可能なメトリックは、ロード、ストア、LLC ミスカウント、および平均レイテンシーです。
帯域幅を高めるコード領域とメモリー・オブジェクトを特定
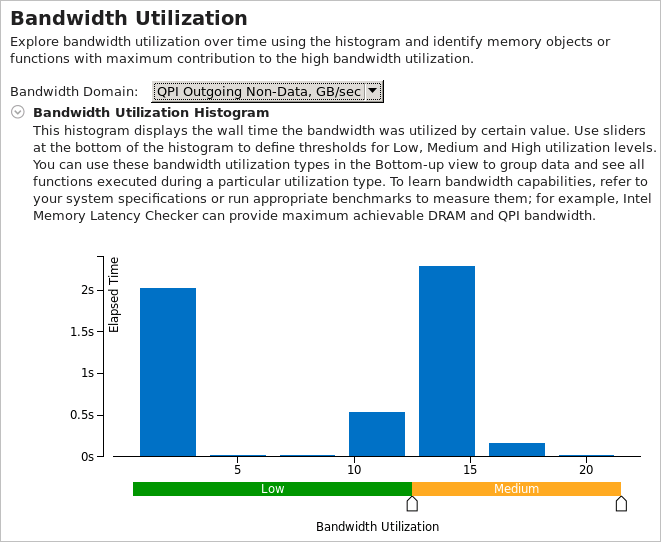
[サマリー] ウィンドウの [帯域幅利用率] では、帯域幅ドメイン (DRAM やインターコネクト) を選択して、分布図に表示される帯域幅利用率を時系列で解析できます。

この分布図は、システム帯域幅が特定の値 (帯域幅ドメイン) で使用された時間を表し、帯域幅利用率を、高、中、低、に分類するしきい値を提供します。デフォルトでは、メモリー解析結果のしきい値は、収集を開始する前にインテル® VTune™ プロファイラーによって測定された達成可能な最大 DRAM 帯域幅に基づいて計算され、[サマリー] ウィンドウの [システム帯域幅] に表示されます。カスタム解析結果でこの機能を有効にするには、[DRAM の最大帯域幅を評価] オプションを選択します。このオプションが無効な場合、しきい値はこの結果で収集された最大帯域幅から計算されます。しきい値を変更するには、下部のスライドバーを使用します。変更した値は、プロジェクトの以降のすべての結果に適用されます。
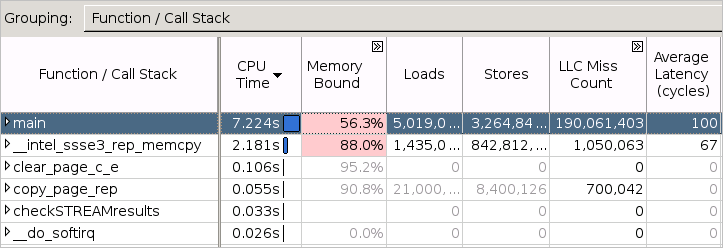
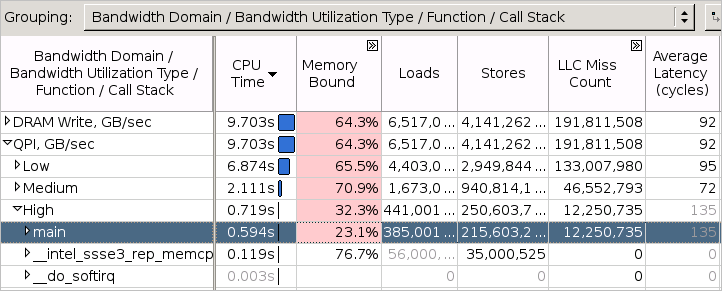
分布図の下の表を調べて、選択したドメインの帯域幅利用率が高いときにどの関数が頻繁にアクセスされたか特定します。リストの関数をクリックすると [ボトムアップ] ウィンドウが開き、[帯域幅ドメイン/帯域幅利用率タイプ/関数/コールスタック] で自動的にグループ化されたグリッドでその関数がハイライト表示されます。[DRAM、GB/秒] > [高い] 利用率タイプの下に、システム DRAM 帯域幅利用率が高いときに実行されたすべての関数が表示されます。[LLC ミスカウント] でグリッドをソートすると、高い DRAM 帯域幅利用率に最も関連する関数が表示されます。
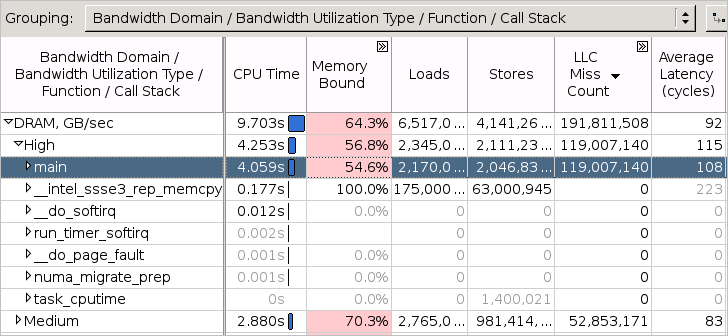
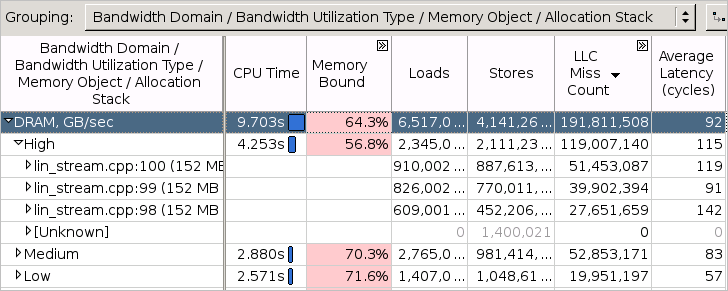
帯域幅が制限されたコードの特定に加えて、インテル® VTune™ プロファイラーは高い帯域幅利用率に影響する頻繁にアクセスされるメモリー・オブジェクト (変数、データ構造体、配列) を確認するワークフローを提供します。そのため、ターゲットのメモリー・オブジェクト解析を有効にすると、[帯域幅利用率] には選択したドメインで帯域幅利用率が高いときに頻繁にアクセスされた上位のメモリー・オブジェクトの表が示されます。リストのオブジェクトをクリックして [ボトムアップ] ウィンドウに切り替えると、[帯域幅ドメイン/帯域幅利用率タイプ/メモリー・オブジェクト/割り当てスタック] で自動的にグループ化されたグリッドでそのオブジェクトがハイライト表示されます。[DRAM] > [高] 利用率タイプの下に、システム DRAM 帯域幅利用率が高いときにアクセスされたすべてのメモリー・オブジェクトが表示されます。[LLC ミスカウント] でグリッドをソートすると、高い DRAM 帯域幅利用率に最も関連するメモリー・オブジェクトが表示されます。
帯域幅の問題を時間経過で解析
時間経過におけるアプリケーションの帯域幅の問題を特定するには、[ボトムアップ] ウィンドウの上の [タイムライン] ペインに注目します。メモリー解析結果の DRAM 帯域幅グラフは、収集開始前にインテル® VTune™ プロファイラーが測定した達成可能な最大 DRAM 帯域幅に応じてスケールされます。カスタム解析結果でこの機能を有効にするには、[DRAM の最大帯域幅を評価] オプションを選択します。このオプションが無効な場合、しきい値はこの結果で収集された最大帯域幅から計算されます。
帯域幅イベントはコアではなく、アンコア (iMC、統合メモリー・コントローラー) に関連付けられます。アンコアイベントは、パッケージ内のすべての CPU 間で共有される構造 (例えば、単一パッケージ内の 10 個のコア) で発生します。そのため、1 つのアンコアイベントを特定のコード・コンテキストに関連付けることができません。インテル® VTune™ プロファイラーは、帯域幅のアンコアイベントのカウントを、アンコアイベントが発生したソケット (パッケージ) と時間にのみ関連付けます。
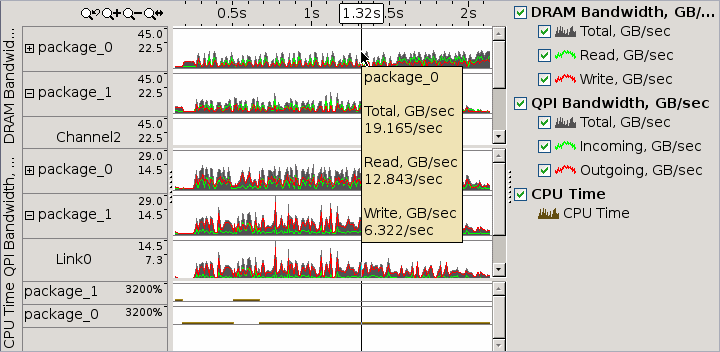
高い帯域幅のバーにカーソルを移動すると、オンチップのメモリー・コントローラーを介して DRAM を読み書きしたデータ量が分かります。[時間フィルター] コンテキスト・メニュー・オプションを使用して、帯域幅が目立つ特定の時間範囲でフィルター処理します。次に、下のグリッドで帯域幅と関連するコアベースのイベントに切り替えて、帯域幅に影響するコード領域を特定します。
NUMA の問題があるコードとメモリー・オブジェクトを特定
現代の多くのマルチソケット・システムは、ホーム (ローカル) CPU ソケットで割り当てられたメモリーへのアクセスが、リモートシステムのメモリーへのアクセスよりも優れたレイテンシー/帯域幅を持つ NUMA (Non-Uniform Memory Access - 不均一メモリーアクセス) に基づいています。NUMA の問題を特定するには、[ボトムアップ] ビューで階層的に組織された次のメトリックに注目します。
[メモリー依存] > [DRAM 依存] > [ローカル DRAM] メトリックは、ローカルメモリーからのメモリーロードを待機する CPU ストールのサイクルの割合を示します。
[メモリー依存] > [DRAM 依存] > [リモート DRAM] メトリックは、リモートメモリーからのメモリーロードを待機する CPU ストールのサイクルの割合を示します。
[メモリー依存] > [DRAM 依存] > [リモートキャッシュ] メトリックは、リモートソケットのキャッシュからのメモリーロードを待機する CPU ストールのサイクルの割合を示します。
[LLC ミスカウント] > [ローカル DRAM アクセスカウント]、[LLC ミスカウント] > [リモート DRAM アクセスカウント]、[LLC ミスカウント] > [リモート・キャッシュ・アクセス・カウント] メトリックは、ローカルメモリー、リモートメモリー、およびリモートキャッシュへのアクセス数をそれぞれ示します。
アプリケーションのパフォーマンスは、インターコネクト・リンク (ソケット間接続) の帯域幅によって制限される可能性があります。インテル® VTune™ プロファイラーは、DRAM 帯域幅の問題を特定する方法と同様に、このタイプの帯域幅の問題を引き起こすコードおよびメモリー・オブジェクトを識別するメカニズムを提供します。[サマリー] ウィンドウで、[帯域幅利用率分布図] を使用して [帯域幅ドメイン] ドロップダウン・メニューから [インターコネクト] を選択します。
[帯域幅ドメイン] ドロップダウン・メニューで、[非データカテゴリーのインターコネクト受信/送信] を選択した場合、分布図にはハードウェアによって利用される帯域幅、およびプロトコル・パケット・ヘッダー、スヌープ要求と応答などのシステム・トラフィックが示されます。
注
インターコネクト帯域幅解析は、インテル® マイクロアーキテクチャー開発コード名 Ivy Bridge EP 以降で使用できます。
[ボトムアップ] タブに切り替えて、[帯域幅ドメイン/帯域幅利用率タイプ/関数/コールスタック] グループ化レベルを選択します。[インターコネクト] ドメイングリッド行を展開し、[高] 利用率の行を展開して、システム・インターコネクトの帯域幅利用率が高いときに実行されるすべての関数を表示します。
[タイムライン] ビューでインターコネクト帯域幅利用率が高い領域を選択し、この領域をフィルターアウトすることもできます。
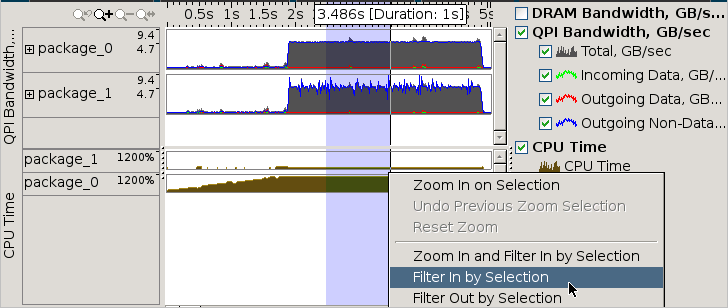
フィルターが適用されると、[タイムライン] ペインの下の [グリッド] ビューに、新しい範囲で実行されたデータが表示されます。
ソースを解析する
クリティカルな関数をダブルクリックして [ソース/アセンブリー] ウィンドウを開き、ソースコードを解析します。[ソース/アセンブリー] ウィンドウには、選択した関数のコード行ごとにハードウェア・メトリックが表示されます。
メモリー・オブジェクトの [ソース/アセンブリー] データを表示するには、次の操作を行います。
[ボトムアップ] ウィンドウで、[../関数/メモリー・オブジェクト/..] グループ化レベル (関数のほうがメモリー・オブジェクトよりも優先される) を選択します。
関数を展開して、関数の下にあるメモリー・オブジェクトをダブルクリックします。
[ソース/アセンブリー] ウィンドウが開き、選択したメモリー・オブジェクトへのアクセスが行われた関数のソース行ごとにメトリックが表示されます。
注
プロセッサーのイベントに関する情報は、「インテル® プロセッサー・イベントのリファレンス」を参照してください。
ハードウェア・イベントベース・サンプリング収集を使用した HPC 計算のパフォーマンス・チューニングの詳細については、https://www.isus.jp/products/vtune/processor-specific-performance-analysis-papers/ を参照してください。
NUMA ハードウェアのパフォーマンス向上の可能性については、https://www.isus.jp/hpc/performance-improvement-opportunities-with-numa-hardware/ を参照してください。