インテル® VTune™ プロファイラーは、特定のパフォーマンス最適化に注目する事前定義解析タイプを用意しています。
プロジェクトを作成すると、[解析の設定] ウィンドウを開き、[何を] ペインで解析ワークロード (アプリケーション、プロセス、システム全体)、[どこを] ペインで解析ターゲット、そして [どのように] ペインで解析タイプを選択します。
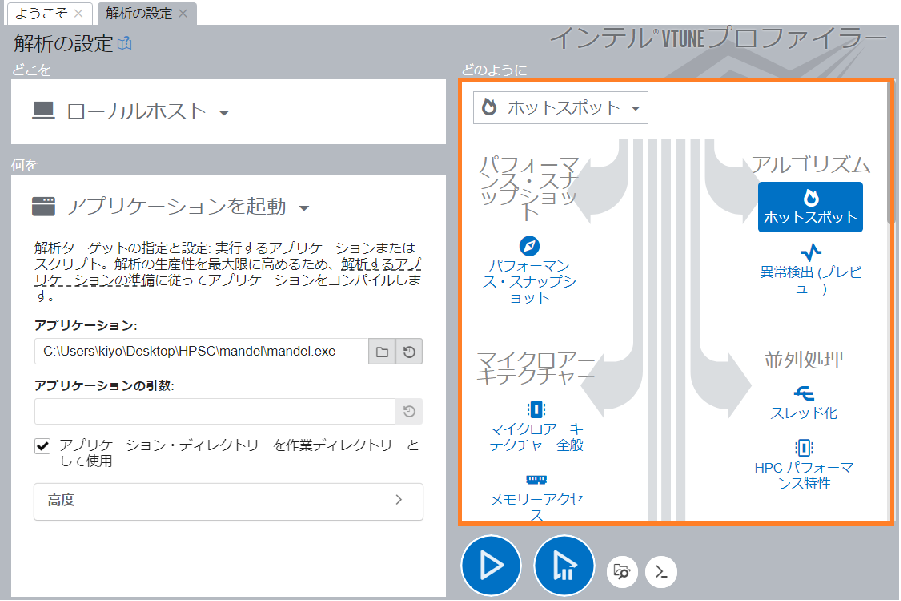
[どのように] ペインで、ヘッダーをクリックして解析ツリーを開きます。これらのグループから解析タイプを選択します。
パフォーマンス・スナップショット解析:
- パフォーマンス・スナップショットでは、システム上のアプリケーションのパフォーマンスに影響する問題の概要を把握します。この解析は、さらに詳しく調査すべき領域を理解する出発点となります。また、次に行うべき解析タイプに関するガイドを得ることもできます。
アルゴリズム解析:
ホットスポット解析タイプは、呼び出しパスを調査し、コードが最も時間を費やしている場所を検出する際に使用します。アルゴリズムのチューニングの可能性を特定します。ホットスポット検出チュートリアルを参照してください。
Linux* (英語) | Windows* (英語)。異常検出 (プレビュー) を使用して、ループ反復など、頻繁に繰り返されるコードのインターバルでパフォーマンスの異常を特定します。マイクロ秒単位で詳細な解析を実行します。
メモリー消費は、アプリケーションのメモリー消費、個別のメモリー・オブジェクトとそれらの割り当てスタックを解析するのに適しています。この解析は、Linux* ターゲットのみをサポートします。
マイクロアーキテクチャー解析:
マイクロアーキテクチャー全般 (以前の全般解析) は、CPU パイプライン・ステージ (フロントエンド、バックエンドなど) とハードウェアのボトルネックの原因となるハードウェア・ユニットを特定するのに最適です。
メモリーアクセスは、NUMA の問題を含む CPU キャッシュとメインメモリーの使用状況を確認し、パフォーマンスに影響するメモリー階層を特定するため、メモリー依存のアプリケーションに適しています。
並列処理解析:
スレッド化は、利用可能なコアでのスレッド並列性を視覚化し、並行性が低い原因を特定して、コード内のシリアル・ボトルネックを検出するのに最適です。
HPC パフォーマンス特性では、計算集約型のアプリケーションが CPU、メモリー、浮動小数点演算ユニット (FPU) のリソースをどのように利用しているか把握します。「チュートリアル: OpenMP* および MPI アプリケーション解析 (Linux* 版)」 (英語) を参照してください。
I/O 解析:
入出力解析は、I/O サブシステム、CPU およびプロセッサー・バスの使用率をモニターします。
アクセラレーター解析:
GPU オフロード (プレビュー) は、レンダリング、ビデオ処理、および計算にグラフィックス処理ユニット (GPU) を使用するアプリケーションをターゲットとします。アプリケーションが CPU 依存であるか GPU 依存であるかを特定するのに役立ちます。
GPU 計算/メディア・ホットスポット (プレビュー) は、GPU 依存のアプリケーションを対象とし、コード行ごとの GPU カーネル実行を解析し、メモリー・レイテンシーや非効率なカーネルのアルゴリズムによるパフォーマンスの問題を特定します。
CPU/FPGA 相互作用解析は、各 FPGA アクセラレーターの FPGA 利用率を調査し、最も時間を消費する FPGA 計算タスクを特定します。
プラットフォーム解析:
システム概要は、ターゲットシステムの一般的な動作を監視し、パフォーマンスを制限するプラットフォーム・レベルの要因を特定するドライバーを使用しないイベントベース・サンプリング解析です。
プラットフォーム・プロファイラー解析は、配備済みシステムを長時間にわたって完全な負荷をかけた状態で実行してデータを収集し、システム全体の構成、パフォーマンス、および動作に関する詳しい情報を提供します。収集は、インテル® VTune™ プロファイラーの外部コマンドプロンプトで実行され、結果はウェブブラウザーで表示します。
注
プレビュー機能は、正式リリースに含まれるかどうかまだ未定です。有用性に関する皆さんからのフィードバックが、将来の採用決定の判断に役立ちます。プレビュー機能で収集されたデータは、将来のリリースで下位互換性が保証されません。