異常検出を使用して、ループ反復など、頻繁に繰り返されるコードのインターバルでパフォーマンスの異常を特定します。マイクロ秒およびナノ秒単位で詳細な解析を実行します。
アプリケーションのパフォーマンスは、パフォーマンス異常によって阻害されることがあります。パフォーマンス異常とは、回復不可能な結果を引き起こす短期間の散発的な問題を示します。このような問題は、統計的には明確にならない可能性があり、ユーザー体験の低下を招き、修正するのに大きな労力がかかると考えられます。アプリケーションのパフォーマンスが、同じタスクのインスタンスに大量のワークを要求したり、ループ反復 (単一/少数) が変動する場合、そのような動作は異常であると考えられます。
異常検出解析を使用して、ほかでは切り分けが難しいアプリケーションのパフォーマンス異常を特定します。この解析タイプでは、インテル® プロセッサー・トレース (インテル® PT) テクノロジーを使用して、トレースデータを収集し詳細な時間とイベントの計測を実行します。インテル® PT は、インテル® アーキテクチャーの拡張機能であり、専用ハードウェアを使用するソフトウェアの実行情報を取得します。このハードウェアが、トレースするソフトウェアのパフォーマンスに与える影響はわずかです。
注
これは、プレビュー機能です。プレビュー機能は、正式リリースに含まれるかどうかは未定です。有用性に関する皆さんからのフィードバックが、将来の採用決定の判断に役立ちます。プレビュー機能で収集されたデータは、将来のリリースで下位互換性が保証されません。
インテル® PT の制御フロートレース機能は、各種パケットを生成して後処理ツールでプログラムのバイナリーと組み合わせることで、正確な実行トレースを作成できます。パケットには、連続するコード領域 (基本ブロック) 内の命令ポインター (IP)、間接分岐のターゲット、条件分岐の方向などのフロー情報が記録されます。インテル® PT の主要な概念については、『インテル® ソフトウェア開発者マニュアル (ボリューム 3C)』 (英語) の 35 章「システム・プログラミング・ガイド」を参照してください。
インテル® VTune™ プロファイラーを使用してソフトウェアのパフォーマンス異常を検出するには、インストルメントとトレース・テクノロジー (ITT) API (英語) を使用して、注目するコード領域を指定し異常検出解析を実行します。
典型的なパフォーマンス異常
以下は、ソフトウェア・アプリケーションにおけるパフォーマンス異常の典型例です。
- 処理に異常な時間を要する金融取引。
- ビデオゲームの UI で、ビデオフレームが遅くなったり、コマ落としになる不具合。
- SPDK/DPDK ループを持つ大規模なアプリケーションでのパケットロス。
- 処理速度が重要で、特定の反復処理がほかの処理よりも頻繁に遅くなるようなアプリケーション。
アプリケーションの動作が一部の反復で期待される動作からの逸脱が観察される状況で、異常検出解析を実行します。
パフォーマンス異常の原因
制御フローの変化: 同じタスクでもインスタンスが異なればワーク量も変わります。
一般的ではない事象: ストの高いエラー処理、またはメモリー/ストレージの再割り当て。
コンテキスト・スイッチ: 同期やプリエンプション。
予期しないカーネルのアクティビティー: 割り込みやページフォールト。
マイクロアーキテクチャーの問題: キャッシュミス、または分岐予測ミス。
周波数の低下: 低い CPU 利用率、冷却の問題、またはコードに含まれるインテル® アドバンスト・ベクトル・エクステンション (インテル® AVX) 命令。
異常検出解析のワークフロー
アプリケーションのパフォーマンスに異常が観察される場合、異常検出解析で詳細を調査してください。
- 解析するアプリケーションを準備します。
- 注目するコードを小さな領域に分割するパラメーターを定義します。それぞれの領域をシミュレートする期間を決定します。
- 異常検出解析を実行します。
- 検出された異常を詳しく確認します。
- [ボトムアップ] ビューでそれぞれの異常なプロセッサー・トレース・データをロードして、注目するコード領域を調査します。
- 特定領域の周波数情報を見るにはトレースデータを開きます。
- [ソース/アセンブリー] ビューを調べ、ループ反復回数を確認します。
解析の設定と実行
アプリケーションを準備
大規模なアプリケーションでは、プロファイルによって膨大な量のデータが生成される可能性があります。それにより、結果のファイナライズに長時間要することになります。コード中の特定の領域だけに注目したい場合もあります。そのような領域を [注目するコード領域] として定義しマークします。これには ITT API を使用します。
プロファイルするコード領域名を登録します。
__itt_pt_region region = __itt_pt_region_create("region");アプリケーション内の対象とするループに名前を付けます。
for(…;…;…) { __itt_mark_pt_region_begin(region); <タスクを処理するコード> __itt_mark_pt_region_end(region); }
解析を実行
[ようこそ] 画面で [解析の設定] をクリックします。
解析ツリーの [アルゴリズム] グループで、[異常検出] 解析タイプを選択します。
[何を] ペインで、アプリケーションとアプリケーションのパラメーターを指定します。
[どのように] ペインで、解析のパラメーターを指定します。
パラメーター
説明
範囲
推奨値
詳細を解析するコード領域の最大値 アプリケーションのコード領域数を指定します。
10-5000
ロードを高速化するため 1000 以下に設定してください。
コード領域ごとの最大解析時間 それぞれのコード領域に費やす解析時間 (ミリ秒) を指定します。
0.001-1000
1000 ミリ秒以下の値。
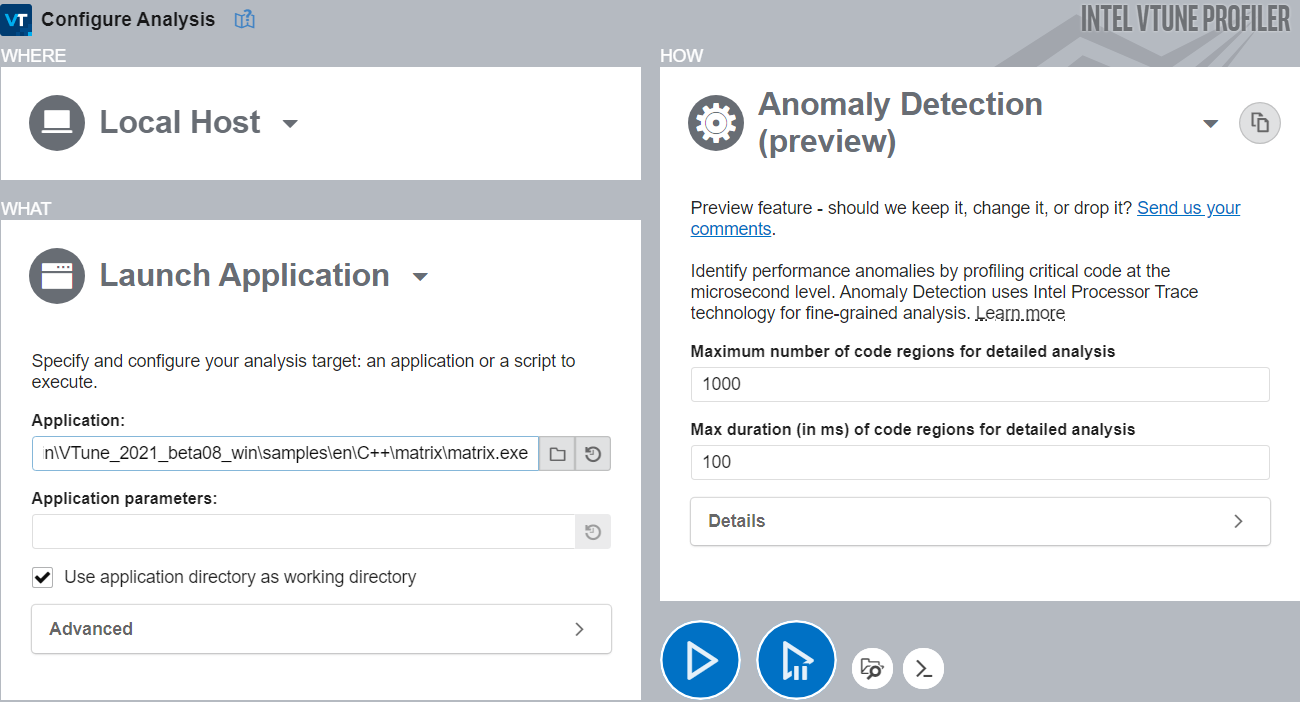
 [開始] ボタンをクリックして解析を実行します。
[開始] ボタンをクリックして解析を実行します。
注
コマンドラインから異常検出を実行するには、下部にある  コマンドライン・ボタンをクリックします。
コマンドライン・ボタンをクリックします。
データを表示
解析が完了すると、インテル® VTune™ プロファイラーは [サマリー] ウィンドウに結果を表示します。
経過時間は、注目するコード領域に費やされた合計時間を示します。
注目する存続期間のコード領域の分布図は、パフォーマンスが重要なタスクのインスタンス数を、指定する期間 (またはレイテンシー) に対して描画します。持続時間が変化した原因を理解するため、高速および低速領域のコードを参照します。
収集とプラットフォーム情報には、システムの詳細、収集プラットフォームのデータ、および結果サイズが表示されます。
上記の手順は、データを収集したシステムで解析結果を処理する際に有効です。収集したデータを別のシステムへ転送して結果を表示するには、データ収集後に必要なバイナリーを結果フォルダーにコピーしてから archive コマンドを実行します。収集した結果を別のシステムに転送して問題なくロードするには、次の手順を完了しなkればなりません。
archive コマンドを実行する手順を以下に示します。
上記のように結果を収集します。
コマンドラインから次を入力します。
vtune.exe --archive -r r001ad
ここで、r001ad は解析結果の例です。
注
別のシステムで収集されたデータを表示するには、メインのバイナリーにリンクされ、収集中にアクセスされるシステムおよびコンパイラーのランタイムを含むすべてのバイナリーをコピーする必要があります。それらのバイナリーを手動でコピーするのは容易ではないため、archive コマンドを使用します。
次のステップ
収集されたデータを解釈する方法は、[異常検出] ビューを参照してください。
[ボトムアップ] ウィンドウで、各解析のトレースの詳細をロードします。
予期しないカーネル・アクティビティーを探します。アプリケーションが、解析中にアクティブ化されるべきではないカーネルに入ったか確認します。
[ソース/アセンブリー] ビューを使用して、分布図の高速および低速領域で対象のコード領域を比較します。