インテル® VTune™ プロファイラーによってアプリケーションが GPU 依存であると特定され、アプリケーションが OpenCL* ソフトウェア・テクノロジーを使用していることが判明している場合、アプリケーションが OpenCL* カーネルをどの程度効率的に利用しているか特定するためカスタム解析で [GPU プログラミング API をトレース] 設定オプションを有効にします。GPU 計算/メディア・ホットスポット解析および GPU オフロード解析では、デフォルトでこのオプションは有効になっています。OpenCL* アプリケーションのパフォーマンスを調査するには、[GPU 計算/メディア・ホットスポット] ビューポイントを使用します。
次の手順に従って、OpenCL* アプリケーションの解析でインテル® VTune™ プロファイラーによって提供されるデータを調査します。
GPU 使用率を解析します。
実行ユニット (EU) が、ストールまたはアイドルしている原因を特定します。
OpenCL* カーネルによる両方の浮動小数点ユニット (FPU) の過剰使用を特定します。
サマリー統計を調査
アプリケーション・レベルのパフォーマンス特性を提供する [サマリー] ウィンドウからデータ解析を開始します。通常、主なベースラインとして、ターゲットの合計実行時間を示す [経過時間] メトリックに注目します。

このデータは、アプリケーションの実行中に GPU エンジンによって使用された [GPU 時間] と関連付けることができます。

GPU 時間が経過時間の大部分を占めている場合 (95.6%)、アプリケーションが GPU 依存であることは明白です。ここでは、GPU 時間の 94.4% が OpenCL* カーネルの実行に費やされていることが分かります。
OpenCL* アプリケーションにおいて、GPU で最も実行時間を費やした OpenCL* カーネルの一覧が示されます。
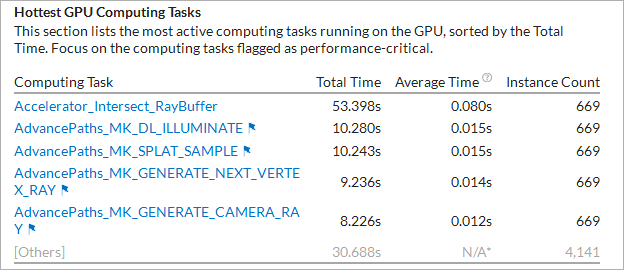
フラグ付きのカーネルにマウスをホバーすると、実行中に特定されたパフォーマンス上の問題を確認することができます。そのようなカーネル名をリストでクリックすると、計算タスクでグループ化され、合計時間でソートされ、グリッドでそのカーネルが選択された [グラフィックス] ウィンドウが表示されます。
解析設定中に使用したプリセットの GPU ハードウェア・イベントに応じて、インテル® VTune™ プロファイラーは、GPU 実行ユニットのストール/アイドルの理由を調査し、サマリーに表示します。例えば、[計算基本] プリセットでは、GPU L3 帯域幅依存の問題を解析します。

または占有の可能性を解析します。
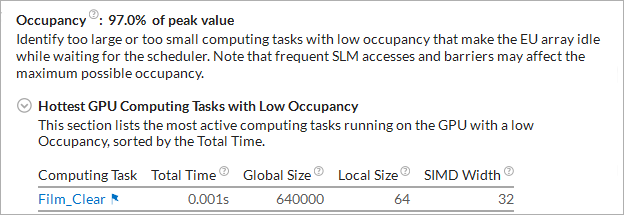
この例では、EU ストールの原因は GPU L3 の高い帯域幅です。リストにある最もホットなカーネルをクリックして、[グラフィックス] ビューに切り替え、キャッシュ再利用の可能性を特定するため、選択したカーネルの [ソース] または [アセンブリー] ビューにドリルダウンします。
アプリケーションの実行で、収集時間の 80% 以上が浮動小数点ユニットの利用に費やされている場合、インテル® VTune™ プロファイラーはそのような値を問題としてハイライト表示し、FPU を過度に利用するカーネルをリストします。
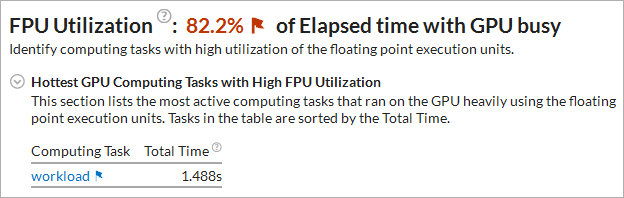
[グラフィックス] タブで [タイムライン] ペインに切り替えて、解析の実行中 FPU 使用率を示す [GPU EU 命令] メトリックの分散を調査できます。

ホットな GPU OpenCL* カーネルの解析
GPU で実行されるすべての OpenCL* カーネルの詳細情報を見るには、[グラフィックス] ウィンドウに切り替えます。デフォルトでは、グリッドデータは計算タスクのみを表示する [計算タスク/インスタンス] でグループ化されます。OpenCL* 計算タスク以外のプログラムユニットで収集されたデータは、[タスク外] エントリーに関連付けられます。
[計算タスク] カラムには、GPU でのカーネルの実行時間と 1 回の呼び出しの平均時間 (clEnqueueNDRangeKernel の 1 回の呼び出しに対応)、ワークグループのサイズ、カーネルの平均 GPU ハードウェア・メトリックが表示されます。カラムのヘッダー (メトリック) にカーソルを移動すると、メトリックの説明が表示されます。計算タスクのメトリック値が、インテルにより設定されているしきい値を超えると、値はピンク色でハイライトされ、パフォーマンス上の問題があることを示します。ハイライトされた値にカーソルを移動すると、問題の説明が表示されます。
次の例では、Accelerator_Intersect カーネルに、ほとんどの実行時間 (53.398 秒) を費やしています。このワークロードで収集された GPU メトリックは、カーネル実行時にストールで高い L3 帯域幅の使用率を示しています。計算集約型のコードでは、これはパフォーマンスがキャッシュ利用により制限されていることを示します。

最初に、実行時間が最も長いホットなカーネルを解析し最適化します。ホットなカーネルには、平均実行時間が長い、あるいは平均実行時間は短くても頻繁に呼び出されるといった特徴があります。どちらの場合も注目すべきです。
カーネル・インスタンスが、OpenCL* 2.0 共有仮想メモリー (SVM) (英語) で使用されていると、インテル® VTune™ プロファイラーはそれを識別し、ハードウェアに応じて次のように SVM の使用タイプを表示します。
粗粒度バッファー SVM: 共有は、OpenCL* バッファー・メモリー・オブジェクト領域の粒度で行われます。デバイスをまたがるアトミックはサポートされません。
細粒度バッファー SVM: 共有は、OpenCL* バッファー・メモリー・オブジェクト領域内のロードとストアの粒度で行われます。デバイスをまたがるアトミックはオプションです。
細粒度システム SVM: 共有は、ホストメモリー内で発生するロードとストアの粒度で行われます。デバイスをまたがるアトミックはオプションです。
それぞれの clCreateKernel の結果が、[計算] カテゴリーの行に含まれます。2 つの clCreateKernel 呼び出しにより同じ名前の 2 つの異なるカーネルが (同じソースからであっても) 作成されると (そして 2 つ以上の clEnqueueNDRangeKernel から起動されると)、同じカーネル名の行が 2 つ表示されます。また、それらが異なるグローバルまたはローカルサイズ、もしくは異なる SVM 引数セットとして 2 度キューに投入されると、グリッドには個別に表示されます。
OpenCL* カーネルデータと GPU メトリックを関連付け
時系列で OpenCL* カーネルの実行を解析するには、[グラフィックス] ウィンドウの [タイムライン] ペイン > [プラットフォーム] タブを調査します。
OpenCL API (例えば、clWaitForEvents ) は、[スレッド] エリアにタスクとして示されます。
![[タイムライン] ペイン: [プラットフォーム] タブ](GUID-9D30AF9F-D47B-43B5-B273-C0F236B4EB53-low.gif)
GPU メトリックと OpenCL* カーネルデータを関連付け:

注
GPU ハードウェア・メトリックは、インテル® HD グラフィックス、またはインテル® Iris® グラフィックス向けの [プロセッサー・グラフィックス・イベントを解析] オプションが有効である場合にのみ利用できます。これらのメトリックを収集するには、GPU 解析のシステム設定が適切であることを確認してください。
GPU アーキテクチャー・ブロックごとの GPU ハードウェア・メトリックを調査することで、OpenCL* アプリケーションを簡単に解析できます。これを行うには、[グラフィックス] ウィンドウで [計算タスク] グループ化レベルを選択し、注目する OpenCL* カーネルを選択して [タイムライン] ペインで [メモリー階層分布図] タブをクリックします。インテル® VTune™ プロファイラーは、選択されたカーネルが実行された時間範囲の GPU ハードウェア・メトリックごとのパフォーマンス・データで、プラットフォームのアーキテクチャー・ダイアグラムを更新します。

現在、この機能は第 4 世代インテル® Core™ プロセッサーとインテル® Core™ M プロセッサーから利用可能で、これ以降のプロセッサーではより広いスコープのメトリックが提供されます。
注
[メモリー階層分布図] を右クリックして、[データを表示] を選択し、メトリックデータの表示形式を選択できます。
合計サイズ
帯域幅 (デフォルト)
帯域幅最大値のパーセント
計算キューを調査
OpenCL* カーネル・サブミッションの詳細を表示し、サブミッションと実行の順序に注目して、キューで費やされた時間を解析するには、[タイムライン] ペインの [計算キュー] データにズームインして調べます。カーネルタスクをクリックすると、上位レイヤーに表示された実行に対応するキュー全体がハイライトされます。名前とサイズが同じカーネルは、同じ色で示されます。
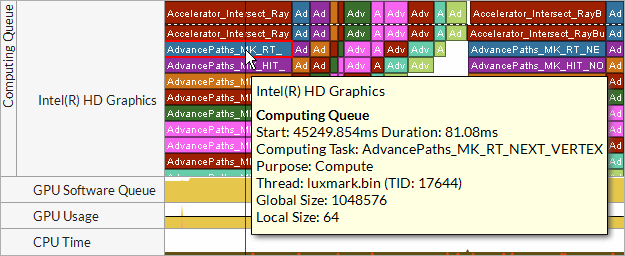
インテル® VTune™ プロファイラーは、名前とサイズが同じカーネルを同色で表示します。同期タスクは、縦縞  で表示されます。データ転送 (ホストシステムから GPU へデータを転送する OpenCL* ルーチン) は交差斜線
で表示されます。データ転送 (ホストシステムから GPU へデータを転送する OpenCL* ルーチン) は交差斜線  で表示されます。
で表示されます。
注
アタッチモードでは、計算キューが作成された後にプロセスにアタッチすると、インテル® VTune™ プロファイラーはこのキューの OpenCL* カーネルのデータを表示しません。
ソースとアセンブリー・コードの解析
グリッドビューで注目する計算タスクを選択して、計算タスクをダブルクリックして [ソース/アセンブリー] ウィンドウを開き、選択したカーネル (ソースファイルが利用可能) のコードを解析します。
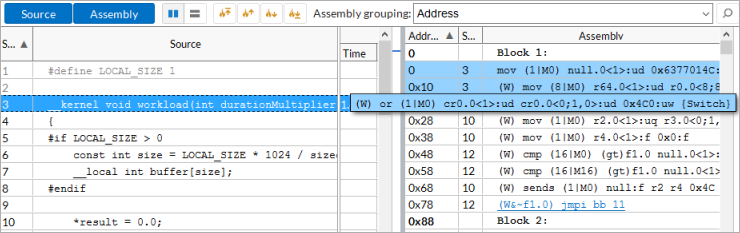
コンパイラーが生成した OpenCL* カーネルのアセンブリー・コードを解析し、複雑性を推測し、問題を特定して、クリティカルなアセンブリー行と影響のあるソースコードと一致させ、可能であれば最適化します。例えば、いくつかのコード行が多数のアセンブリー命令にコンパイルされる場合、ソースコードを単純化してアセンブリー行を減らし、コードがよりキャッシュ・フレンドリーになるようにします。
[グラフィックス] ウィンドウで、計算タスクごとの GPU メトリックデータを調査し、検出した問題に関連する命令を特定するため [ソース/アセンブリー] ビューにドリルダウンします。例えば、[グラフィックス] ウィンドウでサンプラービジーやストールの問題を特定する場合、頻繁なストールやサンプラーの過度な利用につながりやすい send 命令を [アセンブリー] ペインで検索し、その使用を解析します。それぞれの send/sends 命令は、データのリード/ライト (型あり/型なしサーフェスリードなど)、各種アーキテクチャー・ユニットへのアクセス (サンプラー、ビデオモーション予測)、スレッドの最後 (スレッド起動) など、命令の用途を示す角括弧 ([]) で注釈されます。例えば、この sends 命令は、サンプラーユニットのアクセスに使用されます。
0x408 260 sends (8|M0) r10:d r100 r8 0x82 0x24A7000 [Sampler, msg-length:1, resp-length:4, header:yes, func-control:27000]
注
ソース/アセンブリー解析は、ソースを含む OpenCL* プログラムと IL (中間言語) で作成されたカーネル (中間 SPIR-V* バイナリーが -gline-tables-only -s <cl_source_file_name> オプションを指定してビルドされている場合) で利用できます。
ソース/アセンブリー解析は、#line ディレクティブを含むソースではサポートされません。
OpenCL* カーネルがインライン関数を使用している場合、[フィルター] ツールバーの [インラインモード] オプションを有効にすると、グリッドにインライン関数を表示してソースビューで解析できます。